Author: Denis Avetisyan
A new framework, Attention-MoA, boosts collaborative problem-solving in large language models by enabling agents to dynamically focus on each other’s strengths.
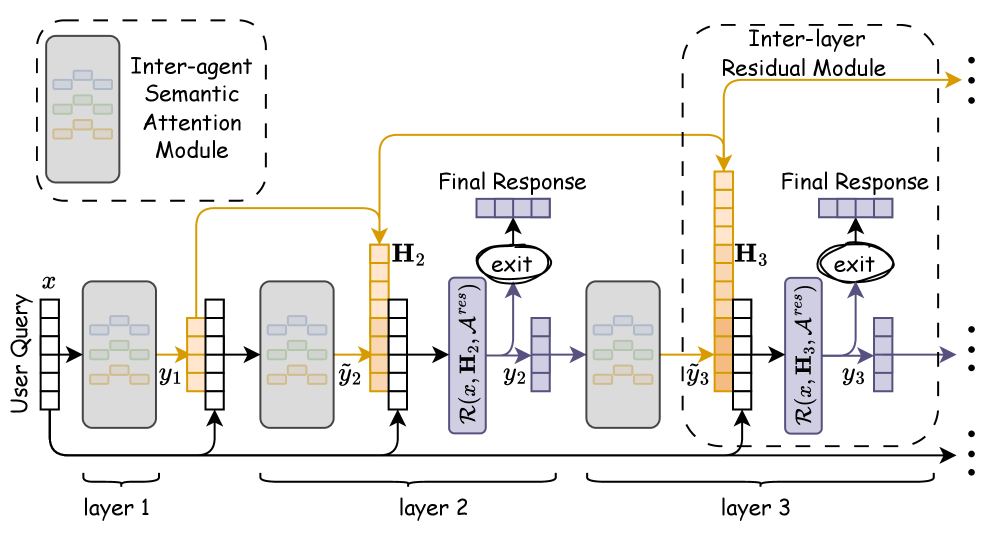
Attention-MoA utilizes inter-agent semantic attention and deep residual synthesis to enhance model performance and scalability, even with reduced model sizes.
While scaling large language models has driven recent progress, achieving true collective intelligence requires effective inference-time collaboration. This paper introduces ‘Attention-MoA: Enhancing Mixture-of-Agents via Inter-Agent Semantic Attention and Deep Residual Synthesis’, a novel framework that redefines multi-agent collaboration through inter-agent semantic attention and an adaptive residual synthesis mechanism. Our approach significantly enhances reasoning capabilities and achieves state-of-the-art performance, even allowing ensembles of smaller open-source models to outperform massive proprietary counterparts. Could this represent a paradigm shift towards more scalable and efficient large language model systems, prioritizing collaboration over sheer parameter count?
The Limits of Reasoning: Scaling Beyond Superficial Fluency
Despite the impressive ability of Large Language Models to generate human-quality text and perform various linguistic tasks, consistently achieving robust performance on complex, multi-step reasoning remains a significant challenge. These models often demonstrate difficulties when faced with problems requiring the integration of information across numerous steps, or the application of abstract rules in novel situations. While proficient at identifying patterns within training data, LLMs frequently falter when extrapolating beyond these patterns or when confronted with ambiguities demanding nuanced understanding. This limitation isn’t necessarily a matter of knowledge gaps, but rather a struggle with the process of reasoning itself – effectively chaining together individual inferences to arrive at a logically sound conclusion. Consequently, even the largest and most sophisticated models can produce seemingly plausible but ultimately incorrect answers, highlighting a fundamental need for advancements in reasoning architectures beyond simple scale.
The pursuit of increasingly larger language models has yielded impressive gains in many areas, yet recent research demonstrates diminishing returns when addressing tasks requiring sustained reasoning over extended contexts. Simply increasing the number of parameters does not inherently equip a model to effectively process and retain information from lengthy input sequences. This limitation stems from architectural constraints and the inherent challenges of maintaining coherence and relevance across numerous tokens; models often struggle with ‘lost in the middle’ phenomena, where information presented earlier in a sequence is overshadowed by more recent input. Consequently, even the most powerful LLMs exhibit difficulties in tasks like summarizing long documents, following intricate instructions spanning multiple steps, or accurately answering questions requiring synthesis of information dispersed throughout a substantial text. The focus is now shifting towards more efficient architectures and training methodologies designed to specifically address these long-context limitations, rather than relying solely on brute-force scaling.
The pursuit of increasingly complex reasoning in Large Language Models is revealing substantial inefficiencies in current methodologies. As models attempt to process lengthy chains of thought – necessary for tasks like intricate problem-solving or detailed document analysis – token usage escalates dramatically, often requiring disproportionately more computational resources. This isn’t simply a matter of needing more processing power; the current architecture frequently duplicates information or generates redundant tokens while tracing reasoning steps. Consequently, the computational cost grows non-linearly with the length of the reasoning chain, creating a practical barrier to solving more complex problems and hindering the scalability of these models. Researchers are actively exploring techniques such as selective token retention and more efficient attention mechanisms to mitigate these issues and unlock the full potential of LLMs for sophisticated reasoning tasks.
Beyond Singular Minds: The Promise of Distributed Reasoning
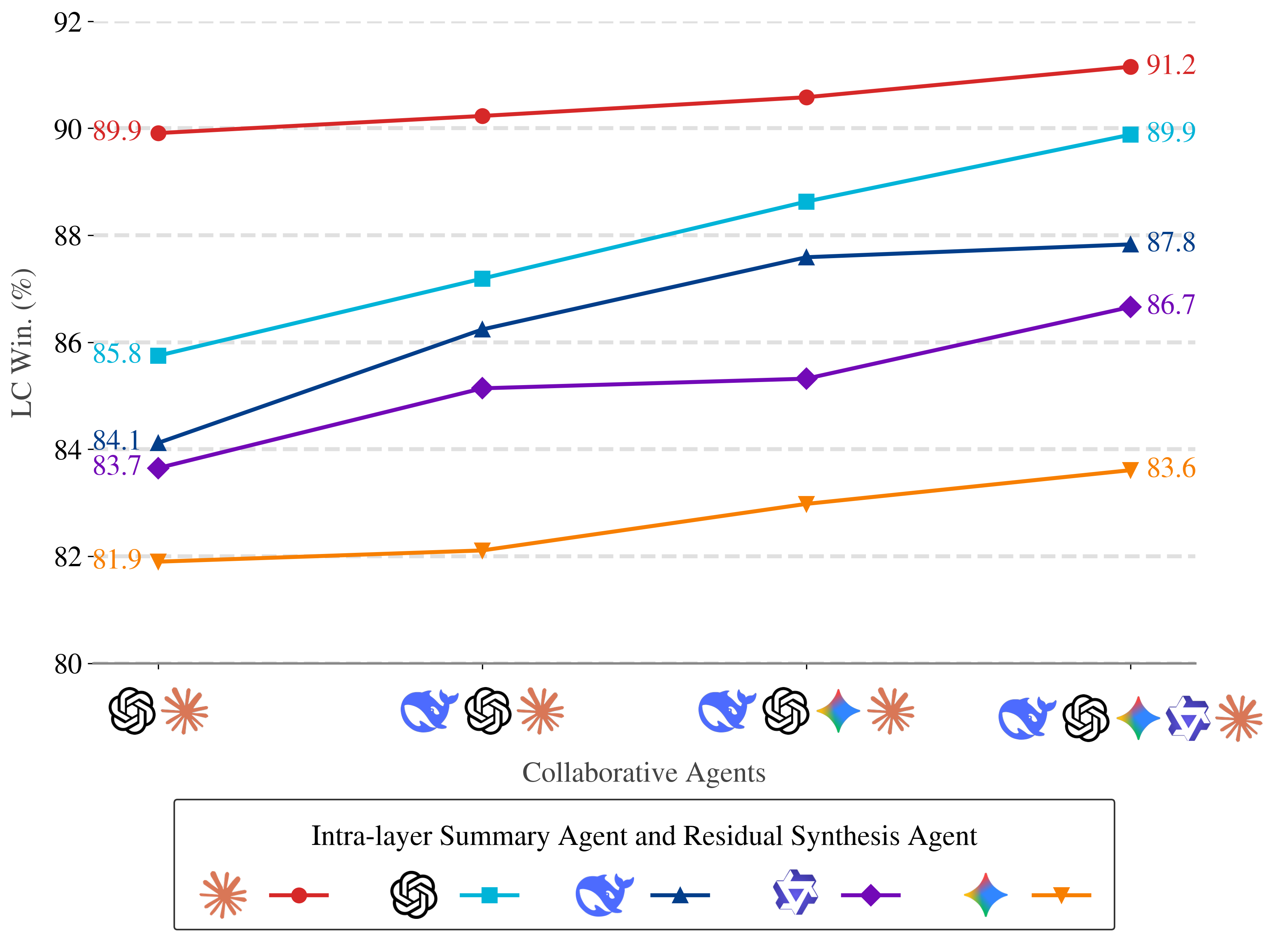
Mixture-of-Agents (MoA) signifies a departure from traditional large language models (LLMs) functioning as single, unified entities. Instead, MoA employs an ensemble architecture consisting of multiple, specialized agents that operate in parallel. Each agent within the mixture is designed to focus on a specific subtask or possess unique expertise, allowing for a decomposition of complex problems. This contrasts with monolithic LLMs, where all processing occurs within a single model, potentially limiting efficiency and adaptability. The shift to MoA enables the distribution of computational load and the application of diverse reasoning strategies, representing a fundamental change in how language models are structured and deployed.
The Mixture-of-Agents (MoA) architecture achieves improved computational efficiency by distributing reasoning tasks across multiple specialized agents operating in parallel. Rather than a single Large Language Model (LLM) processing a query sequentially, MoA enables concurrent analysis and processing by individual agents, each potentially optimized for a specific sub-task or knowledge domain. This parallelization reduces the overall latency associated with complex problem-solving and allows for increased throughput. Furthermore, the specialized nature of each agent-focused on a narrower scope of expertise-can minimize redundant computation and enhance the speed of individual reasoning steps, contributing to a more efficient overall system.
Mixture-of-Agents (MoA) systems employ an iterative reasoning process achieved through inter-agent communication and critique. Agents do not operate in isolation; instead, they exchange intermediate reasoning steps and provide feedback on each other’s work. This allows for a refinement of initial hypotheses, as agents can challenge assumptions, identify errors, and propose alternative solutions. The system simulates aspects of human cognitive processes, where ideas are developed, tested, and revised through internal dialogue and external feedback, leading to more robust and accurate outcomes than those produced by a single, static model. This collaborative approach enhances the overall quality of reasoning by distributing cognitive load and promoting critical evaluation.
Attention-MoA: A Framework for Collaborative Intelligence
Attention-MoA incorporates Inter-agent Semantic Attention, a mechanism enabling agents within the framework to evaluate and improve upon the responses generated by their peers through natural language feedback. This process involves one agent generating an initial response, followed by another agent analyzing it and providing a critique expressed in natural language. The original agent then utilizes this feedback to refine its response, creating an iterative cycle of peer review and improvement. This differs from traditional methods by moving beyond simple scoring or ranking of responses, and instead focuses on substantive, linguistically-expressed critiques that directly inform revision and enhance the quality of reasoning.
Inter-layer residual connections are implemented within the Attention-MoA framework to mitigate information loss as data propagates through multiple agent layers. These connections directly add the input of each layer to its output, creating a shortcut for the gradient during backpropagation and preventing the vanishing gradient problem. This architecture ensures that crucial information from earlier reasoning steps is preserved and accessible to subsequent layers, enabling the construction of more robust and reliable reasoning chains, particularly in complex multi-agent interactions where cumulative errors could otherwise significantly impact performance.
Adaptive Early Stopping is implemented to improve the efficiency of the iterative reasoning process by dynamically terminating redundant cycles. This optimization monitors the consistency of responses generated across consecutive reasoning steps; when subsequent outputs exhibit minimal change relative to prior iterations, the process halts. This technique reduces computational cost by avoiding unnecessary token generation, resulting in an observed reduction of 11% in total tokens used during inference without compromising the quality of the final output. The implementation prioritizes balancing reasoning depth with computational efficiency, ensuring a practical trade-off for resource-constrained environments.
Prefix-Caching is implemented to mitigate redundant computation during the iterative reasoning process of Attention-MoA. This technique stores and reuses the hidden states computed for the initial prefix of the input sequence across multiple reasoning steps. By avoiding recalculation of these shared states, Prefix-Caching significantly reduces the computational workload, particularly in scenarios involving lengthy input sequences or multiple reasoning cycles. This optimization contributes to a measurable improvement in inference speed and overall system performance, complementing other efficiency measures within the framework.
![Adaptive Early Stopping improves layer-wise LC Win rates, demonstrated by early termination [latex] ext{(blue bars)}[/latex] and resulting token savings [latex] ext{(red bars)}[/latex] across network depth.](https://arxiv.org/html/2601.16596v1/sections/images/earlystop_bar_chart.png)
Beyond Benchmarks: Demonstrating a New Standard for Reasoning
Evaluations conducted with state-of-the-art language models – including GPT-4.1, Gemini-2.5-Pro, and Claude-4.5-Sonnet – reveal substantial performance gains across a range of established benchmarks. These experiments leveraged datasets like AlpacaEval 2.0, designed to assess instruction-following capabilities, MT-Bench, focused on multi-turn conversation, and FLASK, which challenges models with complex reasoning and knowledge application. The consistent improvements observed across these diverse benchmarks underscore the robustness and generalizability of the advancements made, indicating a significant step forward in language model capabilities and a potential reshaping of performance standards within the field.
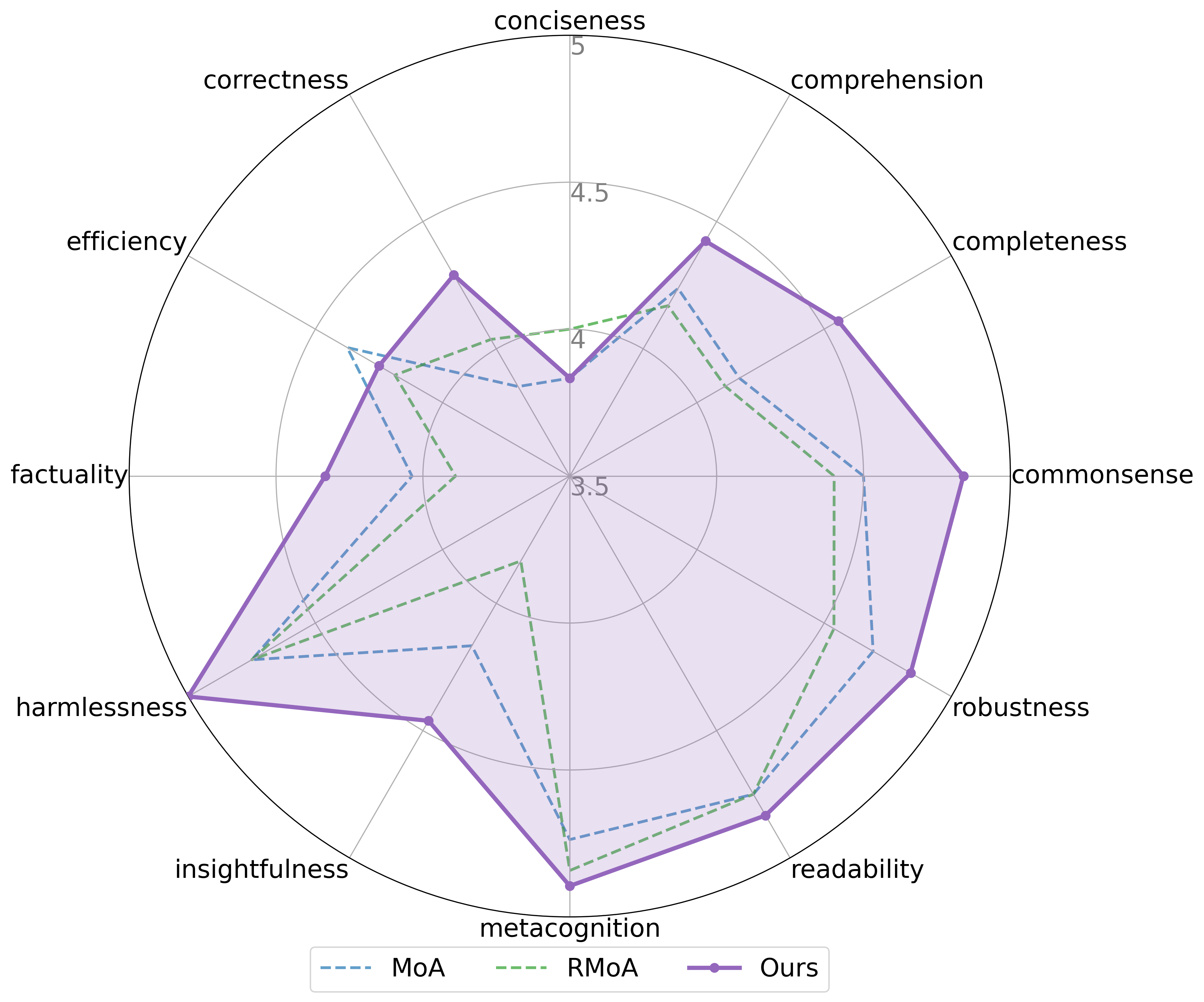
Evaluations reveal that the model exhibits marked improvements across several cognitive benchmarks, notably in its ability to sustain coherent and contextually relevant interactions during multi-turn dialogues. Performance gains are also apparent when tackling complex reasoning tasks, suggesting an enhanced capacity for logical inference and problem-solving. Crucially, the model demonstrates superior long-context comprehension, effectively retaining and utilizing information from extended passages to inform its responses – a capability vital for nuanced understanding and sophisticated applications. These combined advancements indicate a significant step toward creating AI systems capable of more natural, insightful, and human-like communication and reasoning.
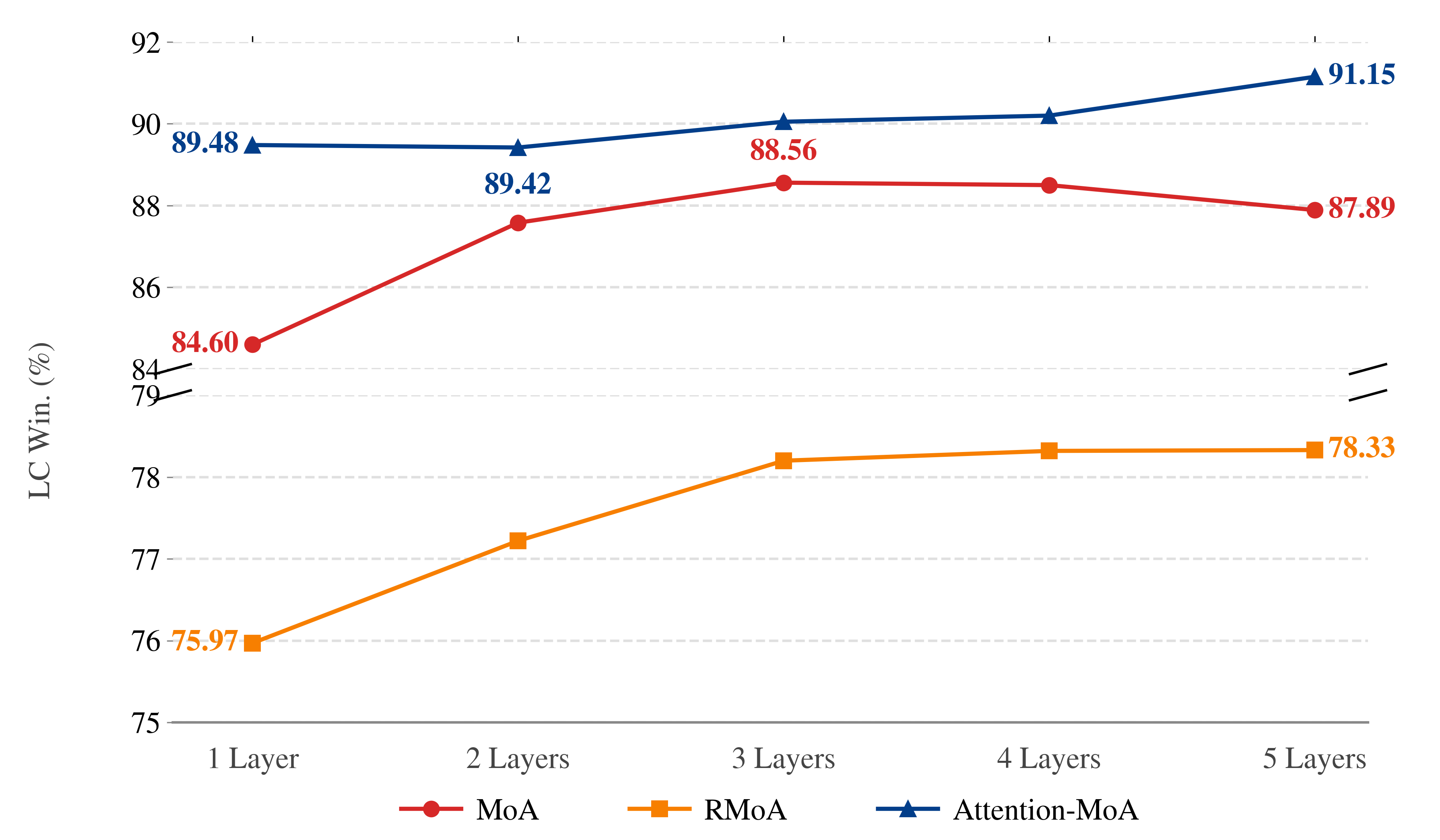
Evaluations demonstrate that Attention-MoA significantly elevates performance across established benchmarks. Specifically, the model achieves a Length-Controlled Win Rate of 91.15% on the AlpacaEval 2.0 dataset, surpassing the capabilities of existing Mixture-of-Experts (MoE) architectures. This indicates a marked improvement in handling variable input lengths while maintaining response quality. Complementing this result, Attention-MoA attains an MT-Bench score of 9.32, further solidifying its position as a high-performing language model capable of excelling in multi-turn dialogue and complex reasoning tasks. These metrics collectively highlight the model’s robust performance and its ability to generate coherent and contextually relevant responses.
Evaluations using the challenging FLASK (Hard subset) benchmark reveal that Attention-MoA consistently outperforms existing architectures across the majority of tested dimensions-achieving superior results in 10 out of 12 categories. This advantage extends to direct comparisons with Claude-4.5-Sonnet in smaller model configurations, where Attention-MoA attains a noteworthy MT-Bench score of 8.83, exceeding Claude-4.5-Sonnet’s 8.62. Furthermore, the model demonstrates a significantly higher Length-Controlled Win Rate on AlpacaEval 2.0-77.36% compared to Claude-4.5-Sonnet’s 73.49%-highlighting its capacity to maintain performance consistency even with extended input sequences and complex dialogue.
Toward Artificial General Intelligence: Scaling Collaboration and Understanding
Ongoing research prioritizes the development of sophisticated agent specialization strategies within Mixture-of-Agents (MoA) systems, moving beyond static role assignment. This involves investigating methods for agents to dynamically identify and cultivate expertise in specific sub-tasks, fostering a more adaptable and efficient collaborative environment. Crucially, future work centers on creating robust dynamic task allocation algorithms, enabling agents to seamlessly transfer ownership of problems based on evolving skillsets and real-time performance metrics. Such systems promise not only enhanced problem-solving capabilities but also a greater resilience to changing conditions and an ability to optimize collective intelligence through continuously refined specializations and task distributions.
The current collaborative AI framework demonstrates promising results, but future development centers on significantly increasing its capacity for complex problem-solving and broadening its applicability. Researchers are actively working to move beyond narrowly defined tasks, intending to equip the system with the ability to dissect multifaceted challenges requiring nuanced reasoning. This involves not only improving the AI’s internal analytical capabilities, but also designing mechanisms for effective knowledge transfer and adaptation to entirely new domains – ranging from scientific discovery and logistical planning to creative endeavors. The ambition is to create a system capable of learning and applying reasoning skills across a spectrum of disciplines, mirroring the versatility of human intelligence and ultimately paving the way for truly generalized artificial intelligence.
The pursuit of artificial intelligence increasingly centers on the ambition to build systems exhibiting human-level reasoning – a capability extending beyond pattern recognition to encompass genuine understanding, problem-solving, and adaptability. This necessitates moving past narrow AI, designed for specific tasks, towards artificial general intelligence (AGI) capable of tackling novel, complex challenges in unpredictable real-world scenarios. Such systems would not merely process information, but comprehend context, draw inferences, and formulate solutions with the flexibility and ingenuity characteristic of human cognition. The development of AGI promises transformative applications, from accelerating scientific discovery and addressing global challenges like climate change and disease, to enabling entirely new forms of human-computer collaboration and innovation, ultimately redefining the boundaries of what machines can achieve.
The pursuit of enhanced multi-agent collaboration, as detailed in Attention-MoA, necessitates a ruthless pruning of complexity. The framework’s emphasis on inter-agent semantic attention and deep residual synthesis reflects a dedication to structural efficiency. G.H. Hardy observed that “the essence of mathematics lies in its elegance and simplicity.” This echoes the core principle of Attention-MoA: achieving state-of-the-art performance not through sheer scale, but through refined inter-layer communication and focused attention mechanisms. The resulting scalability with smaller models demonstrates that true progress arises from distilling concepts to their most essential form.
The Road Ahead
The presented work, while achieving demonstrable gains in collaborative reasoning, merely scratches the surface of a fundamental truth: scaling model size is a palliative, not a cure. Attention-MoA offers efficiency, yes, but the underlying complexity of true collaboration remains a stubborn problem. Future efforts must resist the temptation to add layers of abstraction. The focus should be on distilling existing mechanisms – semantic attention, residual synthesis – into forms as self-evident as gravity. Intuition suggests a more elegant solution exists, one where inter-agent communication isn’t a learned behavior, but an inherent property of the system’s architecture.
A critical limitation lies in the reliance on large language models as the foundation. Can the principles of Attention-MoA be divorced from this dependency? Exploring alternative substrates-systems built from first principles of distributed cognition-could reveal unforeseen efficiencies and capabilities. The current paradigm implicitly equates intelligence with parameter count; a demonstrably flawed assumption.
Ultimately, the field requires a shift in perspective. Less emphasis on what models can learn, and more on how they learn it. The goal isn’t to create increasingly sophisticated simulations of intelligence, but to understand the minimal necessary conditions for genuine collaborative reasoning. Perfection isn’t reached with more layers; it’s achieved when everything superfluous has been stripped away.
Original article: https://arxiv.org/pdf/2601.16596.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
2026-01-27 05:49