Author: Denis Avetisyan
A new framework tackles the challenges of transferring robot skills from simulation to the real world, boosting performance on complex tasks like garment manipulation.
![This framework addresses distributional inconsistencies across a three-stage pipeline-expanding training coverage via heuristic DAgger and spatio-temporal augmentation in [latex]P_{\text{train}}[/latex], merging complementary policies in weight space with stage-aware advantage in [latex]Q_{\text{model}}[/latex], and ensuring execution accuracy with temporal chunk-wise smoothing and closed-loop refinement in [latex]P_{\text{test}}[/latex].](https://arxiv.org/html/2602.09021v1/x1.png)
χ0 aligns distributional inconsistencies through model merging, stage advantage, and train-deploy alignment, improving long-horizon robot learning.
Despite advances in robotic learning, achieving reliable long-horizon manipulation remains challenging due to discrepancies between training data, learned policies, and real-world execution. This work, titled ‘$χ_{0}$: Resource-Aware Robust Manipulation via Taming Distributional Inconsistencies’, addresses this critical limitation by introducing a framework that explicitly mitigates distributional inconsistencies through model arithmetic, stage-aware advantage estimation, and train-deploy alignment. Demonstrated on complex garment manipulation tasks with dual-arm robots, our approach achieves a nearly 250% improvement in success rate over state-of-the-art methods using only 20 hours of data and limited compute. Could this resource-efficient approach pave the way for more adaptable and robust robotic systems in unstructured environments?
The Challenge of Robust Robotic Action
Traditional reinforcement learning, while successful in simulated environments, frequently encounters difficulties when applied to real-world robotic manipulation. The inherent complexities of physical systems – including unpredictable sensor noise, imprecise actuators, and the sheer variety of possible states – present significant challenges for algorithms trained on simplified models. Consequently, robots often exhibit brittle behavior, failing to generalize learned skills to even slightly altered scenarios. A policy successfully trained to grasp a specific object under ideal lighting may falter when presented with a different object, altered lighting conditions, or minor variations in the environment’s configuration. This lack of robustness stems from the difficulty in creating training data that adequately captures the full spectrum of real-world variability, ultimately limiting the deployment of reinforcement learning in practical robotic applications.
The capacity for a robot to adapt to novel situations remains a significant hurdle in achieving truly autonomous operation. Current learning algorithms frequently struggle when faced with even minor deviations from their training environment, a phenomenon stemming from the challenge of policy generalization. This difficulty isn’t simply about encountering entirely new tasks, but rather subtle changes in conditions – altered lighting, unexpected object textures, or slight variations in object positioning – that constitute what is known as distributional shift. These shifts create a mismatch between the data a robot learns from and the data it encounters during real-world deployment, causing performance to degrade and undermining the reliability of robotic systems. Effectively addressing this generalization problem requires developing learning approaches that are robust to these inevitable distributional shifts, allowing robots to maintain consistent performance across a wider range of conditions and tasks.
The discrepancy between a robot’s training environment and the realities of deployment introduces a critical fragility in performance. Often, robotic systems are honed in controlled, simulated, or narrowly defined settings, creating a ‘reality gap’ when faced with even slight variations in lighting, object textures, or unforeseen disturbances. This mismatch, termed a distributional shift, can cause a trained policy to generate actions that are wildly inappropriate or even dangerous in the real world. Consequently, a robot exhibiting seamless performance during training may suddenly falter, exhibiting jerky movements, failing to grasp objects, or – in more critical applications – causing damage to itself or its surroundings. Addressing these shifts isn’t merely about improving accuracy; it’s about building robust, dependable systems capable of navigating the inherent unpredictability of physical environments and ensuring safe, reliable operation beyond the confines of the laboratory.
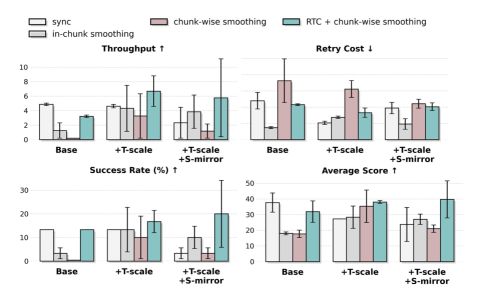
Stabilizing Learning Through Advantage Estimation
The Advantage Function is a key component in addressing instability during reinforcement learning in long-horizon tasks. It operates by estimating the relative benefit of taking a specific action in a given state, compared to the average expected reward from that state. This is calculated as the difference between the actual [latex]Q(s, a)[/latex] value – representing the expected cumulative reward for taking action [latex]a[/latex] in state [latex]s[/latex] – and the state value function [latex]V(s)[/latex], which represents the expected cumulative reward achievable from state [latex]s[/latex] following an optimal policy. By focusing on the advantage – the degree to which an action exceeds expectations – the learning signal is refined, reducing variance and facilitating more stable and efficient learning, particularly when dealing with delayed rewards common in complex, extended tasks.
Stage Advantage (SA) enhances learning stability by incorporating stage-aware labels into the reward signal. This addresses challenges posed by temporal mismatch, where the timing of reward delivery doesn’t align with the action that generated it, and delayed rewards, common in long-horizon tasks. By providing more immediate and relevant feedback based on the current stage of the task, SA reduces the variance in the learning signal. Quantitative results, as depicted in Figure 8, demonstrate that SA significantly improves numerical stability, specifically as measured by the Smooth Frame Ratio (SFR), indicating a more consistent and reliable learning process.
By incorporating stage-aware labels, the Stage Advantage (SA) method demonstrably improves numerical stability during reinforcement learning, enabling more effective learning over extended time horizons and complex tasks. Traditional long-horizon tasks often suffer from instability due to temporal mismatch and delayed rewards; SA mitigates these issues by providing a more consistent and reliable supervision signal. This enhanced stability allows the learning agent to maintain consistent gradients and avoid divergence, resulting in improved performance and faster convergence, particularly in scenarios with sparse or delayed rewards where standard methods struggle.
![Self-attention (SA) enhances numerical stability and consistently outperforms a [latex]\pi_{0.6} <i> \pi^</i>_{0.6}[/latex]-style advantage baseline on Task C, even when the Direct + Stage variant experiences a performance decrease.](https://arxiv.org/html/2602.09021v1/x14.png)
Addressing Coverage Deficiency with Data Augmentation and Policy Merging
Coverage Deficiency in robotic systems arises when the training dataset lacks sufficient diversity to represent the full spectrum of states and scenarios encountered in real-world operation. This limitation directly impacts a robot’s ability to generalize its learned behaviors, resulting in unpredictable performance or complete failure when presented with previously unseen situations. The extent of Coverage Deficiency is directly correlated with the breadth and representativeness of the training data; a limited dataset will inevitably lead to gaps in the robot’s understanding of its environment and its ability to react appropriately, especially in complex or dynamic conditions. Consequently, a robot exhibiting Coverage Deficiency will demonstrate reduced robustness and reliability in practical deployments.
Spatio-Temporal Augmentation increases the size and diversity of the robot training dataset by applying transformations to existing data. These transformations include variations in object positions, lighting conditions, and background scenes – representing spatial augmentations. Temporal augmentations introduce variations in the timing and duration of actions within a sequence. By systematically altering these parameters, the robot is exposed to a broader range of potential scenarios than those present in the original dataset, improving its ability to generalize to unseen environments and novel situations. This technique effectively addresses Coverage Deficiency by artificially expanding the experiential base during training, leading to more robust and adaptable robot behavior.
Model Arithmetic (MA) addresses limitations in robot policy coverage by combining the strengths of independently trained policies. This technique linearly interpolates the parameters of two or more neural network policies, [latex] \theta = \alpha \theta_1 + (1 – \alpha) \theta_2 [/latex], where θ represents the combined policy and α is a weighting factor between 0 and 1. By merging policies trained on distinct datasets – for example, one trained in simulation and another on real-world data, or policies specializing in different tasks – MA creates a new policy that exhibits broader behavioral coverage. This parameter-space merging reduces bias inherent in any single policy and improves generalization performance, particularly in scenarios where the training data does not fully represent the operational environment.
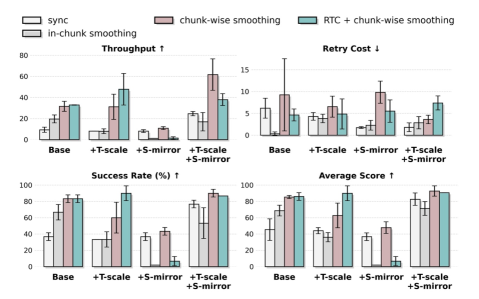
Bridging the Reality Gap: The Power of Alignment
Garment manipulation presents a significant hurdle for robotic systems due to the inherent complexity of dealing with deformable objects. Unlike rigid bodies, clothing lacks a fixed shape and responds unpredictably to force, demanding robots exhibit both precise motor control and a capacity to adapt to the material’s ever-changing properties-such as stretch, drape, and friction. The task isn’t simply about grasping and moving an object; it requires nuanced understanding of how the fabric will react, anticipating wrinkles, folds, and potential tangling. This necessitates advanced algorithms capable of handling uncertainty and continuously adjusting to the garment’s behavior, a challenge that pushes the boundaries of current robotic dexterity and sensing capabilities.
The complexities of transferring robotic policies from simulated environments to real-world applications are directly confronted by the Train-Deploy-Alignment (TDA) technique. This approach strategically integrates three core components to bridge the persistent sim-to-real gap. Heuristic DAgger, a dataset aggregation method, expands the training data with diverse, yet plausible, scenarios. This is coupled with spatio-temporal augmentation, which artificially increases the variety of training data by applying realistic physical distortions and movements. Finally, temporal chunk-wise smoothing refines the learned policy by reducing abrupt changes in robot actions, creating a more stable and reliable performance in the face of real-world uncertainties and sensor noise. Through this combined methodology, TDA enables robots to more effectively generalize learned skills to previously unseen situations, paving the way for robust and adaptable robotic systems.
The implementation of the Train-Deploy-Alignment technique yields a substantial advancement in robotic garment manipulation, achieving a nearly 250% increase in successful task completion when contrasted with the widely-used π0.5 baseline. This dramatic improvement isn’t simply a matter of more attempts; the system demonstrates markedly robust and reliable performance through a reduction in failure cascades – those situations where one small error quickly escalates into complete task failure. By effectively minimizing these compounding errors, the methodology maximizes the probability of completing collaborative garment manipulation tasks, offering a significant step towards practical robotic assistance in everyday life and industrial automation.
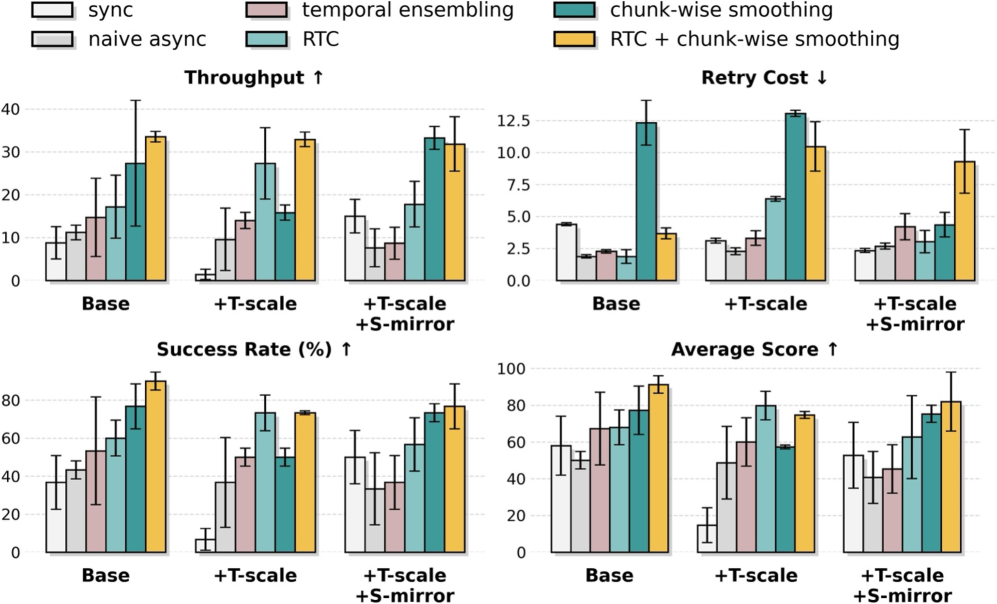
Towards Generalizable Robot Intelligence: A Foundation for the Future
The pursuit of truly intelligent robots has long been hampered by the need for task-specific programming; however, a shift towards robot foundation models offers a promising alternative. These models, analogous to large language models in natural language processing, are pre-trained on vast and diverse datasets encompassing robot states, actions, and sensory inputs. This pre-training equips them with a broad understanding of robotic principles and environmental interactions, allowing for rapid adaptation to new tasks with significantly less task-specific data. Rather than learning from scratch, a robot leveraging a foundation model can fine-tune its existing knowledge, effectively transferring skills learned in one context to another – a crucial step towards generalizable intelligence and a future where robots can seamlessly navigate and interact with the complexities of the real world.
Recent advancements in robot intelligence leverage the power of large, pre-trained models, but adapting these models to real-world tasks often demands substantial computational resources. Flow Matching offers a particularly efficient fine-tuning approach, effectively distilling the knowledge embedded within these foundation models for specific applications. This technique, coupled with access to high-performance hardware such as the A100 GPU, dramatically reduces the training time and data requirements traditionally associated with robotic adaptation. By optimizing the learning process, Flow Matching enables robots to rapidly acquire new skills and navigate complex environments with greater proficiency, paving the way for more versatile and responsive robotic systems.
The creation of truly adaptable robotic systems hinges on a concerted effort to refine training methodologies, expand data diversity, and ensure behavioral alignment. Robust training techniques fortify a robot’s performance against unforeseen circumstances and noisy sensor data, preventing catastrophic failures in real-world deployments. Complementing this, data augmentation artificially expands the training dataset by introducing variations – like altered lighting or object positions – forcing the robot to generalize beyond the specific examples it has seen. Crucially, alignment procedures guide the robot’s learning process, ensuring its goals and actions remain consistent with human expectations and safety protocols. When these three principles – resilience, breadth, and ethical guidance – are interwoven, the result is a robot capable of not just executing pre-programmed tasks, but of intelligently navigating and responding to the inherent complexities of dynamic environments, ultimately unlocking a new era of versatile robotic solutions.
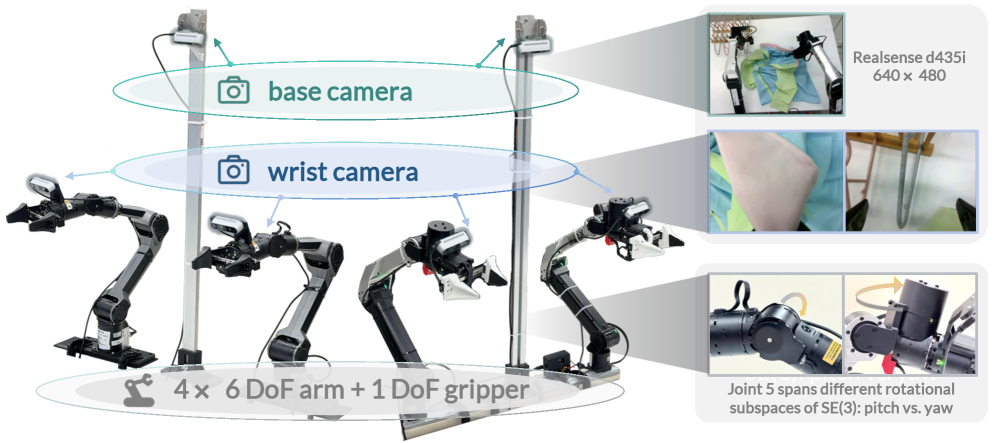
The pursuit of robust robotic manipulation, as demonstrated by χ0, inherently demands a parsimonious approach to complexity. The framework’s emphasis on distributional alignment and model merging isn’t about adding layers of sophistication, but rather refining existing components to achieve a more consistent and reliable outcome. This echoes Donald Knuth’s sentiment: “Premature optimization is the root of all evil.” χ0 doesn’t seek to anticipate every possible scenario through excessive modeling; instead, it focuses on effectively handling distributional inconsistencies – a form of ‘taking away’ unnecessary complexity to achieve a core functionality in long-horizon garment manipulation.
The Road Ahead
The presented framework, while demonstrably effective in taming distributional inconsistencies, merely addresses a symptom. The core difficulty remains: robot learning, particularly in long-horizon manipulation, often demands generalization from limited, imperfect data. Model arithmetic, stage advantage, and train-deploy alignment are clever bandages, but the wound is a fundamental mismatch between simulated and real-world dynamics. Future work must aggressively pursue methods that reduce the reliance on extensive, curated datasets. Intuition suggests the most fruitful path lies not in more complex models, but in simpler ones rigorously grounded in physical principles.
A critical limitation is the current dependence on task-specific formulations. The demonstrated improvements on garment manipulation, while encouraging, do not guarantee transferability. The field needs to move beyond bespoke solutions and explore truly foundational models-representations that capture the underlying structure of manipulation tasks independent of specific objects or goals. Data augmentation, as currently practiced, feels like rearranging deck chairs; the real prize is learning to extract more signal from fewer examples.
Ultimately, the question isn’t whether robots can imitate human manipulation, but whether they can understand it. Code should be as self-evident as gravity, and current approaches remain frustratingly opaque. The pursuit of robustness should not be mistaken for intelligence. The next decade will likely be defined not by algorithmic novelty, but by a renewed commitment to clarity and a ruthless pruning of unnecessary complexity.
Original article: https://arxiv.org/pdf/2602.09021.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Total Football free codes and how to redeem them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
- Nicole Kidman and Jamie Lee Curtis elevate new crime drama Scarpetta, which is streaming now
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
2026-02-14 08:14