Author: Denis Avetisyan
A new review examines the current state of automated testing methods for task-based chatbots and highlights the challenges in ensuring their reliability.
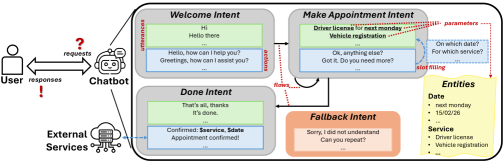
This paper presents a comprehensive study of test generation techniques, coverage criteria, and the ongoing oracle problem in conversational AI testing.
Despite the increasing prevalence of task-based chatbots in everyday applications, systematically evaluating their quality remains a significant challenge. This paper, ‘Automated Testing of Task-based Chatbots: How Far Are We?’, presents a comprehensive study of state-of-the-art automated testing techniques applied to a diverse set of open-source and commercial chatbots. Our findings reveal limitations in current approaches, particularly concerning the complexity of generated test scenarios and the reliability of implemented oracles-essential for accurately assessing chatbot performance. Given these shortcomings, what novel strategies are needed to ensure the robustness and trustworthiness of increasingly sophisticated conversational AI systems?
Deconstructing Dialogue: The Reliability Imperative
Task-based chatbots are rapidly becoming ubiquitous across numerous industries, offering the potential to revolutionize customer service, automate routine tasks, and deliver personalized experiences. These systems, designed to assist users in completing specific goals – such as booking a flight or troubleshooting a technical issue – promise significant gains in efficiency and user satisfaction. However, realizing this potential is hampered by a persistent challenge: reliability. Despite advancements in natural language processing, these chatbots frequently misinterpret user requests, fail to handle unexpected inputs, or provide inaccurate information, leading to frustrating experiences and eroding user trust. This unreliability stems from the inherent complexity of human conversation and the difficulty of creating algorithms that can accurately model and respond to the nuances of language, context, and user intent, necessitating ongoing research and development to improve their performance and robustness.
The functionality of task-based chatbots hinges on a dual process of discerning what a user wants – their intent – and identifying the specific details, or entities, within that request. Successfully interpreting intent moves beyond simple keyword recognition; the system must grasp the underlying goal of the conversation, even with ambiguous phrasing. Simultaneously, entity extraction pinpoints crucial pieces of information, such as dates, locations, or product names, which are then used to fulfill the user’s request. A failure in either of these areas – misinterpreting the intent or inaccurately identifying entities – results in an irrelevant or incorrect response, highlighting the critical interplay between these two processes for effective conversational AI.
The intricate nature of modern conversational AI presents a considerable challenge to conventional software testing protocols. Unlike traditional programs with defined input-output relationships, chatbots navigate dynamic, multi-turn dialogues where understanding nuanced language and context is paramount. Standard testing methods, often focused on isolated function calls, fail to capture the emergent behaviors that arise from these complex conversational flows. This inadequacy leads to unpredictable responses, as edge cases and unforeseen user inputs expose weaknesses in the chatbot’s ability to maintain coherent and helpful interactions. Consequently, even seemingly functional chatbots can exhibit erratic behavior in real-world deployments, highlighting the need for novel testing strategies designed to evaluate not just individual components, but the entire conversational experience.

Automated Probes: Scaling the Pursuit of Robustness
Robust validation of task-based chatbot functionality relies on comprehensive conversational test suites. However, manual creation of these suites presents significant challenges in terms of both time and completeness; the process is inherently labor-intensive and susceptible to overlooking critical conversational paths and edge cases. This results in potential gaps in testing coverage, increasing the risk of undetected errors and negatively impacting the user experience. A well-defined test suite should account for various user inputs, dialog states, and expected system responses, which becomes increasingly complex as the chatbot’s functionality expands. Consequently, automated approaches to test suite generation and execution are crucial for ensuring the reliability and performance of task-based dialog systems.
Botium is a toolset designed to automate the creation and execution of conversational tests for dialog systems. It functions by allowing developers to define test cases using a variety of formats, including simple text, JSON, or YAML, and then executes these tests against a deployed chatbot. This automation streamlines the testing process, significantly reducing the manual effort required to validate chatbot functionality and ensuring consistent test coverage. By automating test generation and execution, Botium enables teams to scale their testing efforts, supporting continuous integration and continuous deployment (CI/CD) pipelines for more frequent and reliable chatbot releases. The framework supports multiple channels, including text-based interfaces and voice assistants, facilitating comprehensive testing across diverse deployment environments.
This research presents a comparative evaluation of five conversational test generation (CTG) tools, representing the most extensive study of its kind to date. These tools extend the functionality of frameworks like Botium by automating the creation of test cases, thereby addressing the limitations of manual test suite development. The evaluation focused on the tools’ ability to dynamically generate tests and optimize for dialog coverage, assessing their efficiency in creating comprehensive and scalable test suites for task-based dialog systems. Performance metrics included test suite size, coverage of dialog states, and the time required for test generation and execution.

Beyond Surface Checks: Uncovering the Cracks in the Facade
Test flakiness, defined as inconsistent pass/fail results for the same test case, represents a significant challenge in chatbot testing as it complicates the identification of actual defects. To quantify this issue, we conducted an analysis involving five repeated executions of each test case for every chatbot under evaluation. This methodology allowed us to measure the rate of inconsistent results and differentiate between genuine failures and those attributable to environmental factors or test instability, providing a clearer assessment of the chatbot’s reliability and the effectiveness of the test suite.
Mutation testing assesses test suite quality by intentionally introducing small, artificial defects – known as mutations – into the chatbot’s code. These mutations represent potential real-world errors. The test suite is then run against the mutated code; a successful test suite should detect and fail on these introduced defects. The percentage of mutations detected – the mutation score – provides a quantifiable measure of test suite effectiveness. A higher mutation score indicates a more robust and reliable test suite capable of identifying a broader range of potential issues. This method goes beyond simply verifying expected behavior and actively seeks out vulnerabilities in the chatbot’s logic.
Charm extends the capabilities of the Botium testing framework by incorporating robustness testing, a process that systematically alters input sentences to identify vulnerabilities in chatbot responses to minor phrasing variations. This is achieved by applying predefined modifications – such as synonym replacement, reordering of words, and the addition of superfluous terms – to valid input statements. By assessing the chatbot’s ability to maintain consistent and accurate responses despite these alterations, Charm highlights potential weaknesses in natural language understanding and ensures the chatbot exhibits resilience to real-world user input, which is rarely perfectly formulated. The results provide a quantifiable measure of robustness, allowing developers to address areas where the chatbot’s performance degrades with slight input changes.
LLM-based techniques, such as those implemented in Tracer, generate test interactions by simulating user behavior. These tools utilize Large Language Models to create diverse and contextually relevant prompts and utterances, moving beyond pre-defined test scripts. This approach allows for the creation of more comprehensive test profiles, covering a wider range of potential user inputs and conversational flows. By leveraging the LLM’s natural language generation capabilities, these techniques can identify vulnerabilities that might be missed by traditional, static test cases, particularly in handling nuanced or unexpected user phrasing. The resulting test suites offer improved coverage and a more realistic assessment of chatbot performance under varied conditions.
Mapping the Conversational Landscape: A Wider Ecosystem
The development of task-based chatbots isn’t confined to a single technological pathway; instead, a diverse ecosystem of platforms supports their creation, most notably Rasa, Dialogflow, and Amazon Lex. Each platform presents a unique set of capabilities and limitations, influencing the design and implementation of conversational AI. Rasa, an open-source framework, offers greater flexibility and control but demands significant development expertise. Dialogflow, backed by Google’s infrastructure, provides ease of use and powerful natural language understanding, though with less customization. Amazon Lex integrates seamlessly with other Amazon Web Services, simplifying deployment but potentially creating vendor lock-in. Consequently, developers must carefully evaluate these trade-offs, selecting the platform that best aligns with the chatbot’s specific requirements and the available resources.
Maintaining consistent quality across diverse conversational platforms requires testing methods that transcend specific implementations. A chatbot’s core logic may function flawlessly within its development environment-such as Rasa or Dialogflow-but subtle variations in platform handling of natural language, or differing API behaviors, can introduce unexpected errors when deployed elsewhere. Consequently, robust testing suites must be adaptable, focusing on the intent of user inputs and the accuracy of the chatbot’s responses, rather than being rigidly tied to the nuances of any single platform. This platform-agnostic approach ensures that a chatbot’s performance remains reliable and predictable, regardless of where it is integrated, ultimately bolstering user trust and satisfaction.
Evaluating the performance of task-based chatbot test suites requires more than simply measuring accuracy; a crucial element is assessing conversational coverage – the extent to which a test suite explores the full range of possible dialog paths a chatbot might encounter. This metric provides a standardized approach to comparing the effectiveness of different testing strategies, moving beyond isolated utterance testing to a more holistic evaluation of the chatbot’s conversational capabilities. By quantifying how thoroughly the chatbot’s dialog space is explored, researchers and developers gain a clearer understanding of potential weaknesses and areas for improvement, ultimately leading to more robust and reliable conversational AI systems. A higher conversational coverage indicates a more comprehensive test suite, offering greater confidence in the chatbot’s ability to handle diverse user interactions.
The research leveraged a significantly expanded dataset, encompassing 45 distinct task-based chatbots, to rigorously evaluate conversational testing techniques. This represents a threefold increase over the scope of prior investigations, such as the work conducted by Gómez-Abajo et al. (2024), and allows for more statistically robust conclusions regarding the effectiveness of different testing strategies. By analyzing a substantially larger and more diverse collection of chatbots, the study addresses limitations inherent in smaller-scale analyses and provides a more comprehensive understanding of the challenges and best practices in ensuring quality across a broad spectrum of conversational AI applications. The increased scale enabled the identification of subtle performance differences and generalized patterns that would have been obscured in previous investigations.
The pursuit of robust task-based chatbots, as detailed in this study, inherently demands a willingness to challenge established boundaries. It’s a process of deliberate disruption, akin to probing a system for weaknesses. As Ken Thompson famously stated, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code first, debug it twice and then write the code again.” This sentiment encapsulates the iterative nature of testing – particularly when confronting the ‘oracle problem’ in conversational AI. Generating effective tests isn’t simply about verifying functionality; it’s about actively seeking out failure points, meticulously ‘debugging’ the system’s comprehension, and rebuilding towards greater reliability. The research highlights that current test generation techniques are far from perfect, and thus, the cycle of exploration and refinement continues.
Where Do We Go From Here?
The pursuit of automated testing for task-based chatbots reveals, predictably, that the core difficulty isn’t writing code to probe the system, but defining what constitutes ‘correct’ behavior. The so-called ‘oracle problem’ isn’t a bug in the testing framework; it’s a symptom of our incomplete understanding of intention itself. The system responds to prompts, but verifying that response aligns with a user’s true goal-a goal often expressed imprecisely, even to themselves-remains a fundamental challenge. This work underscores that current coverage criteria, while useful, are superficial metrics. They measure what was said, not whether the interaction meaningfully progressed toward a resolution.
The limitations identified in test generation techniques aren’t dead ends, but rather signposts pointing toward more ambitious approaches. Mutation testing, for example, highlights vulnerabilities, but relies on predefined ‘mutations.’ A truly robust system would anticipate-and test against-unforeseen user inputs and emergent conversational patterns. The field needs to move beyond adversarial testing – intentionally breaking the chatbot – and towards a more holistic approach that models user behavior and evaluates the quality of the interaction, not just its functional correctness.
Ultimately, this isn’t about perfecting a testing methodology. It’s about reverse-engineering intelligence. Reality is open source – the rules governing conversation exist – and each failed test, each flaky interaction, is simply a line of code that hasn’t yet been deciphered. The goal isn’t to build better tests, but to finally begin reading the source code.
Original article: https://arxiv.org/pdf/2602.13072.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
2026-02-17 07:03