Author: Denis Avetisyan
A new study examines how the language used in pull request descriptions generated by AI coding assistants influences human reviewers and the likelihood of code being merged.
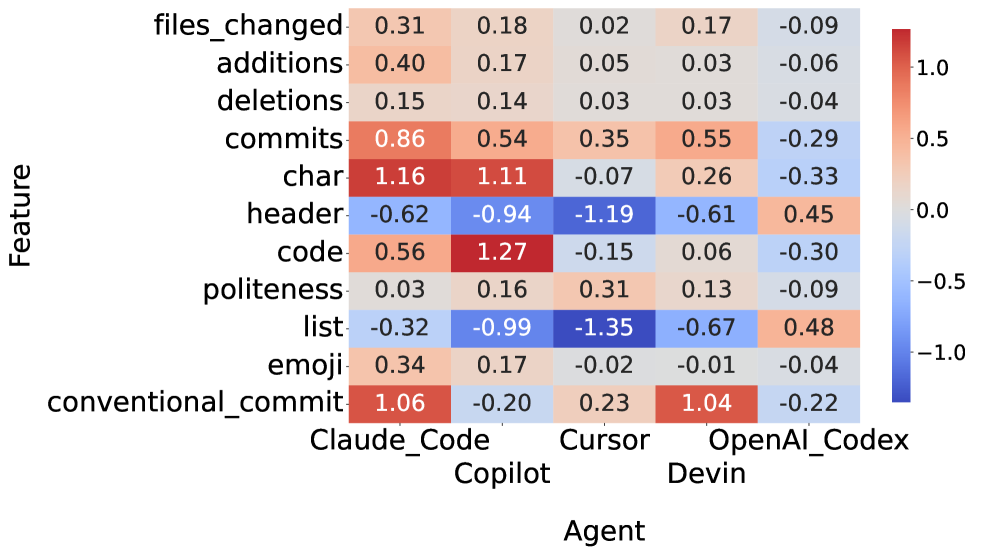
Researchers analyzed the characteristics of AI-generated pull request descriptions and their correlation with human reviewer feedback and code acceptance rates.
While increasingly capable at generating code, the efficacy of AI coding agents hinges on successful human-AI collaboration during code review. This study, ‘How AI Coding Agents Communicate: A Study of Pull Request Description Characteristics and Human Review Responses’, investigates how variations in pull request (PR) description characteristics-generated by different AI agents-impact human reviewer engagement and merge outcomes. Our analysis of the AIDev dataset reveals distinct stylistic differences in PR descriptions across agents, correlating with measurable differences in review response times, sentiment, and ultimate acceptance rates. How might a deeper understanding of these communication dynamics optimize the integration of AI agents into collaborative software development workflows?
Deconstructing the Software Labyrinth: The Rise of AI Agents
Contemporary software development grapples with an escalating level of intricacy, fueled by demands for faster release cycles and increasingly sophisticated applications. This complexity isn’t simply a matter of more lines of code; it arises from distributed systems, microservices architectures, and the integration of numerous external APIs. Traditional methodologies, while still valuable, often struggle to maintain development velocity in this environment, leading to bottlenecks and delays. The sheer volume of interconnected components necessitates more robust testing, debugging, and maintenance procedures, further compounding the challenge. Consequently, the industry is actively seeking innovative approaches – including, but not limited to, AI-assisted tools – that can streamline workflows, automate repetitive tasks, and ultimately, preserve the pace of innovation despite the growing complexity of modern software projects.
The advent of large language models is rapidly reshaping software creation, fostering the emergence of AI Coding Agents capable of automating substantial parts of the development lifecycle. These agents, trained on vast datasets of code, transcend simple code completion; they can now generate entire functions, suggest architectural improvements, and even translate code between programming languages with increasing accuracy. This isn’t merely about increasing developer productivity through assistance; it represents a fundamental shift towards a more automated coding process, where agents handle repetitive tasks and developers focus on higher-level design and problem-solving. The potential extends to reducing errors, accelerating time-to-market, and democratizing software development by lowering the barrier to entry for aspiring programmers – though careful consideration of code quality and security remains paramount as these systems mature.
The advent of AI Coding Agents signals a move beyond traditional software development practices, a transition now recognized as Software Engineering 3.0. This isn’t simply about automating existing tasks; it demands a fundamental rethinking of how code is created, tested, and maintained. Traditional workflows, built around manual coding and sequential review processes, may become bottlenecks in a world where AI can generate substantial portions of code autonomously. Consequently, developers will need to focus more on high-level design, prompt engineering – crafting effective instructions for AI agents – and validating the AI’s output rather than writing every line of code themselves. Code review, too, will evolve, shifting from scrutinizing implementation details to verifying architectural soundness and ensuring the AI-generated code aligns with intended functionality and security standards. Successfully navigating this shift requires embracing new tools, fostering collaboration between humans and AI, and prioritizing quality assurance in an environment of accelerated development cycles.
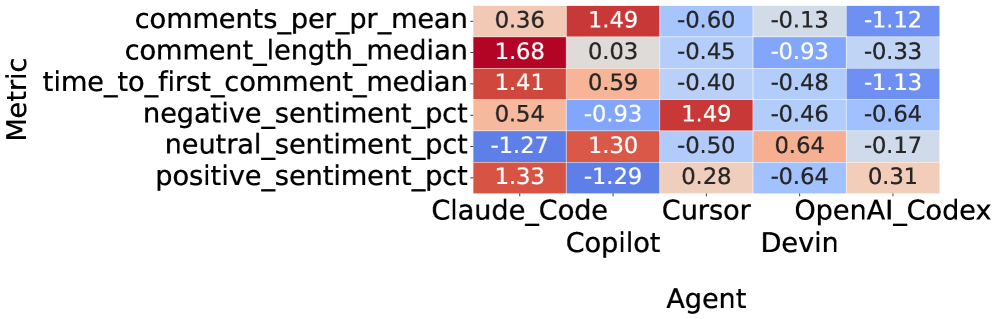
Decoding Intent: The Language of AI-Generated Pull Requests
AI coding agents, when generating code contributions, utilize Pull Requests (PRs) as the primary mechanism for conveying their proposed changes to human developers. Consequently, the characteristics of the PR description – encompassing elements such as the summary of changes, rationale for the implementation, and details regarding testing performed – are fundamentally critical for effective human comprehension. These descriptions serve as the agent’s explicit communication of intent; without clear and informative PR descriptions, reviewers are forced to expend additional effort deciphering the code’s purpose and validating its correctness, directly impacting the efficiency and reliability of the code review process. The quality of the description, therefore, isn’t merely a stylistic concern, but a functional requirement for seamless human-agent collaboration.
Pull Request (PR) description characteristics-specifically description style, PR compliance, and work style-are demonstrably linked to the efficiency of code review and reviewer understanding. Description style encompasses factors like clarity, conciseness, and the use of appropriate technical language; poorly written descriptions increase cognitive load for reviewers. PR compliance refers to adherence to established team or project conventions for PR formatting and content, with deviations requiring additional reviewer effort to interpret. Work style, as reflected in the description, communicates the agent’s approach to the task-for example, whether the PR represents a complete feature, a work-in-progress, or a refactoring-influencing reviewer expectations and assessment criteria. Variations in these characteristics directly correlate with review time, the number of requested changes, and overall reviewer satisfaction.
Comparative analysis of Pull Request descriptions generated by AI coding agents – specifically OpenAI Codex, Claude Code, and Devin – reveals quantifiable differences in their communicative effectiveness. Investigations into these descriptions focus on attributes such as the presence of detailed explanations for code changes, adherence to established commit message conventions, and the inclusion of relevant context regarding the problem being solved. By evaluating these characteristics across multiple agents, researchers can establish metrics for assessing an agent’s ability to clearly convey its intent, facilitating more efficient and accurate code review by human collaborators. These analyses move beyond simple functional correctness to examine the quality of the communication itself, identifying areas where agent ‘communication’ can be improved to streamline the development process.
The efficiency of code review is directly correlated with the quality of pull request descriptions; inadequate descriptions necessitate increased reviewer effort to understand the proposed changes, identify potential issues, and validate the implementation. This impacts review time, increases the likelihood of errors being overlooked, and ultimately reduces the overall development velocity. Analysis of PR descriptions generated by AI coding agents reveals inconsistencies in clarity, completeness, and adherence to established coding standards, indicating a significant area for improvement in agent behavior and a crucial factor in seamless human-AI collaboration. Addressing these deficiencies through improved agent training and standardized description formats can demonstrably reduce review cycles and enhance software quality.
The Human Firewall: Validating AI Contributions
Human reviewers remain a critical component in evaluating the contributions of AI coding agents due to the nuanced nature of software development and the potential for subtle errors or unintended consequences. While automated testing can verify functional correctness, human assessment is necessary to confirm code quality, maintainability, and adherence to project-specific standards. This validation process extends beyond simply identifying bugs; it encompasses evaluating the overall design, clarity, and long-term implications of the AI-generated code. The subjective judgment of experienced developers is currently irreplaceable in ensuring that AI contributions seamlessly integrate into existing codebases and align with broader architectural goals.
Sentiment analysis, utilizing models such as RoBERTa, provides a quantifiable approach to assessing reviewer reactions to pull requests. These models process textual data – specifically, reviewer comments and associated text within the pull request – to determine the expressed sentiment, typically categorized as positive, negative, or neutral. RoBERTa, a transformer-based language model, achieves this by analyzing contextual relationships within the text, allowing for a more nuanced understanding of sentiment than simpler lexicon-based approaches. The resulting sentiment score can then be used as a metric to evaluate the clarity and effectiveness of the pull request description and the proposed code changes, offering an objective measure of how well the contribution is received by reviewers.
Sentiment analysis, utilizing models such as RoBERTa, provides quantifiable data regarding reviewer reactions to pull request descriptions generated by AI coding agents. This analysis moves beyond subjective assessments by measuring reviewer sentiment – positive, negative, or neutral – directly from their comments and interactions with the pull request. Specifically, the system assesses the language used in review comments to determine the degree to which the PR description successfully conveys the changes and their rationale. The resulting sentiment score serves as an objective indicator of how well the description facilitates understanding and, consequently, acceptance of the proposed code modifications, allowing for data-driven improvements to AI agent communication strategies.
Analysis of pull request review data indicates statistically significant differences in reviewer engagement when responding to contributions generated by AI coding agents. Specifically, the number of comments received per pull request exhibited a partial eta-squared (ε²) value of 0.280, demonstrating a moderate effect size. Furthermore, comment length also showed a statistically significant, albeit small, difference with a partial eta-squared of 0.006. These metrics suggest that PRs originating from AI agents elicit a different level of reviewer interaction compared to human-authored PRs, warranting further investigation into the characteristics driving these observed variations.
Correlating characteristics of Pull Request (PR) descriptions with reviewer sentiment, as measured through tools like RoBERTa, enables the identification of specific textual features that influence code review efficiency. Analysis indicates that certain description attributes – including clarity, detail, and the presence of contextual information – are statistically linked to positive reviewer responses and increased engagement. Specifically, features promoting understanding correlate with a reduction in review time and an increase in the number of comments, suggesting reviewers are more willing to engage with well-documented changes. This data-driven approach allows for iterative refinement of AI coding agent communication strategies, ultimately improving the quality and speed of code integration.
Quantifying Progress: Completion and Merge Rates as Metrics of Success
The AIDev Dataset represents a novel contribution to the field of software engineering research by offering an unprecedented level of granularity into the collaborative process of pull request (PR) development. This resource meticulously catalogs not only the code changes themselves, but also the nuanced interactions between developers and AI coding assistants during the PR lifecycle. By capturing data on reviewer comments, code revisions, and the utilization of tools like GitHub Copilot and Cursor, the dataset allows researchers to move beyond simple performance benchmarks and delve into how AI is influencing the software development workflow. The scope of the AIDev Dataset facilitates a deeper understanding of collaboration dynamics, enabling the identification of best practices and potential bottlenecks in the integration of AI-powered coding tools – ultimately fostering more efficient and effective software creation processes.
The efficiency of a software development process isn’t simply about lines of code written; it’s demonstrably reflected in how quickly changes are integrated into the main project. Completion Time, measuring the duration from pull request creation to final merge, provides a clear indicator of development speed. Crucially, Merge Rate – the percentage of pull requests successfully merged – speaks to the quality and compatibility of submitted code, and the effectiveness of the review process. These metrics aren’t isolated data points; they’re interconnected signals revealing bottlenecks, highlighting areas for improvement in workflow, and ultimately quantifying the productivity of the development team. A consistently high merge rate combined with shorter completion times suggests a streamlined, effective process, while delays or frequent rejections indicate potential issues requiring attention.
The efficacy of AI coding agents, such as GitHub Copilot and Cursor, is increasingly quantifiable through their demonstrable influence on established software development metrics. Rather than relying solely on subjective assessments of code quality, researchers and developers are now leveraging Completion Time and Merge Rate as objective indicators of performance. By analyzing pull requests generated with and without the assistance of these agents, it becomes possible to determine whether they genuinely accelerate the development process. A higher merge rate suggests faster code integration, while a reduced completion time indicates increased developer productivity-both signifying a positive impact from the AI assistant. This data-driven approach offers a robust framework for comparing different agents and refining their capabilities to optimize the software development lifecycle.
Analysis of the AIDev Dataset reveals substantial variations in the performance of different AI coding agents, as measured by pull request (PR) merge rates and completion times. Statistical comparisons demonstrate not just differences, but significant differences – indicated by medium-to-large effect sizes – suggesting these aren’t merely random fluctuations. Specifically, some agents consistently facilitated faster PR completion and higher merge success rates than others, implying a tangible impact on developer productivity. These findings highlight the potential for AI to accelerate the software development lifecycle, but also emphasize that the effectiveness of these tools isn’t uniform; careful evaluation and agent selection are crucial to realizing these benefits.
Positive shifts in Completion Time and Merge Rate serve as compelling indicators that artificial intelligence is becoming a productive component of the software development lifecycle. These metrics aren’t merely quantitative; they represent tangible gains in developer efficiency and project velocity. A faster Completion Time suggests AI agents are assisting in quicker code authoring or problem resolution, while a higher Merge Rate demonstrates improved code quality and reduced friction in the review process. Consequently, consistent improvements across both metrics validate the potential for AI to not only augment developer capabilities, but also to streamline the entire process from code submission to successful integration, fostering a more responsive and agile development environment.
The study meticulously dissects the language of AI-generated pull request descriptions, revealing how seemingly minor characteristics influence human reviewers. This echoes Carl Friedrich Gauss’s sentiment: “If others would think as hard as I do, they would not think so differently.” The research doesn’t merely accept the output of these AI agents; it subjects them to rigorous scrutiny, effectively ‘breaking down’ the communication process to understand its underlying mechanisms. Just as Gauss sought fundamental truths through intense calculation, this paper investigates the ‘design sins’ within these AI systems – the subtle flaws in communication that impact acceptance rates and reviewer effort, ultimately challenging the notion of seamless human-AI collaboration.
Opening the Black Box Further
The study exposes a predictable, yet persistently irritating, truth: communication matters, even – perhaps especially – when the communicator is a non-human intelligence. The correlation between pull request description characteristics and human review outcomes isn’t surprising; humans, despite their pretensions, still respond to signals, however subtly encoded. But the real question isn’t if these agents can mimic effective communication, but what constitutes ‘effective’ in a human-machine collaborative loop. This work suggests current metrics – code functionality, bug reduction – are insufficient proxies for a successful integration, hinting at a deeper, more nuanced interplay between the technical and the rhetorical.
Future investigations shouldn’t settle for simply optimizing AI-generated descriptions for human approval. A more fruitful, if messier, path lies in deliberately probing the boundaries of acceptable communication. Can an AI agent successfully submit a technically sound, yet deliberately obtuse, pull request? What are the limits of human patience, and where does frustration give way to automated rejection? Such experiments, while potentially disruptive, will reveal the implicit assumptions baked into the human review process, and expose the true cost of collaboration.
Ultimately, this line of inquiry isn’t about building better AI coding agents. It’s about reverse-engineering the human reviewer – understanding what triggers acceptance, what sparks resistance, and what, precisely, constitutes ‘good’ code in the eyes of another intelligence. The code itself is merely a carrier signal; the real message is in the interpretation.
Original article: https://arxiv.org/pdf/2602.17084.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Last Furry: Survival redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- eFootball 2026 “Countdown to 1 Billion Downloads” Campaign arrives with new Epics and player packs
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Limbus Company 2026 Roadmap Revealed
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
2026-02-20 17:27