Author: Denis Avetisyan
A new workflow leverages artificial intelligence to automate the complex process of reanalyzing empirical social science research, addressing critical challenges in verification and scaling.
This paper details an AI-assisted system for automated execution and diagnostic testing, demonstrably improving reproducibility in large-scale reanalysis of empirical social science studies.
Despite the acknowledged centrality of reproducibility to scientific credibility, large-scale reanalysis of empirical research remains computationally expensive and logistically challenging. This paper introduces ‘Scaling Reproducibility: An AI-Assisted Workflow for Large-Scale Reanalysis’, detailing an agentic AI workflow designed to automate the execution and diagnostic testing of established empirical protocols. Demonstrating 87% end-to-end success across 92 instrumental variable studies-and 100% reproducibility when data and code are accessible-this system significantly lowers the cost of reanalysis by separating scientific reasoning from computational execution. Could this approach unlock a new era of transparent and scalable empirical social science, and how readily can it be adapted to other data-intensive fields?
Uncovering Patterns of Reliability in Scientific Inquiry
A disconcerting pattern is emerging within the landscape of scientific research: a significant proportion of published findings are failing independent verification. Studies attempting to replicate previously reported results across diverse disciplines – from psychology and medicine to economics and chemistry – consistently demonstrate that a substantial number cannot be successfully reproduced. This isn’t merely about minor discrepancies; often, the original effect size diminishes dramatically or vanishes altogether. The implications extend beyond individual studies, creating a systemic challenge to the foundation of empirical science and prompting critical examination of research practices, statistical rigor, and the pressures that incentivize positive results over robust methodology. The increasing awareness of this ‘reproducibility crisis’ underscores the need for greater transparency, data sharing, and the development of more reliable validation techniques to ensure the longevity and trustworthiness of scientific knowledge.
The established processes for verifying scientific results frequently rely on manual replication – researchers painstakingly repeating experiments to confirm initial findings. This approach, while historically standard, presents significant limitations; it’s exceptionally time-consuming, demanding considerable resources and delaying the advancement of knowledge. Moreover, human involvement introduces vulnerabilities to error, from subtle variations in experimental technique to biases in data interpretation, which can lead to inconsistent results even when the original research is sound. Consequently, this manual bottleneck restricts the speed at which scientific claims can be rigorously tested and validated, ultimately hindering the overall pace of discovery and innovation.
The inability to consistently replicate published research findings isn’t merely an academic inconvenience; it represents a fundamental threat to the very foundation of scientific progress and public trust. When core tenets of established studies cannot be independently verified, the accumulation of reliable knowledge falters, potentially leading to flawed policies, ineffective treatments, and misdirected research funding. This erosion of confidence extends beyond the scientific community, impacting perceptions of expertise and fueling skepticism regarding critical issues like climate change or public health. Consequently, there’s a growing imperative to move beyond traditional, often limited, validation methods and embrace innovative approaches – encompassing pre-registration of studies, open data initiatives, and robust meta-analysis – that prioritize transparency, rigor, and the independent verification of scientific claims.
Automating the Reproduction of Empirical Analysis
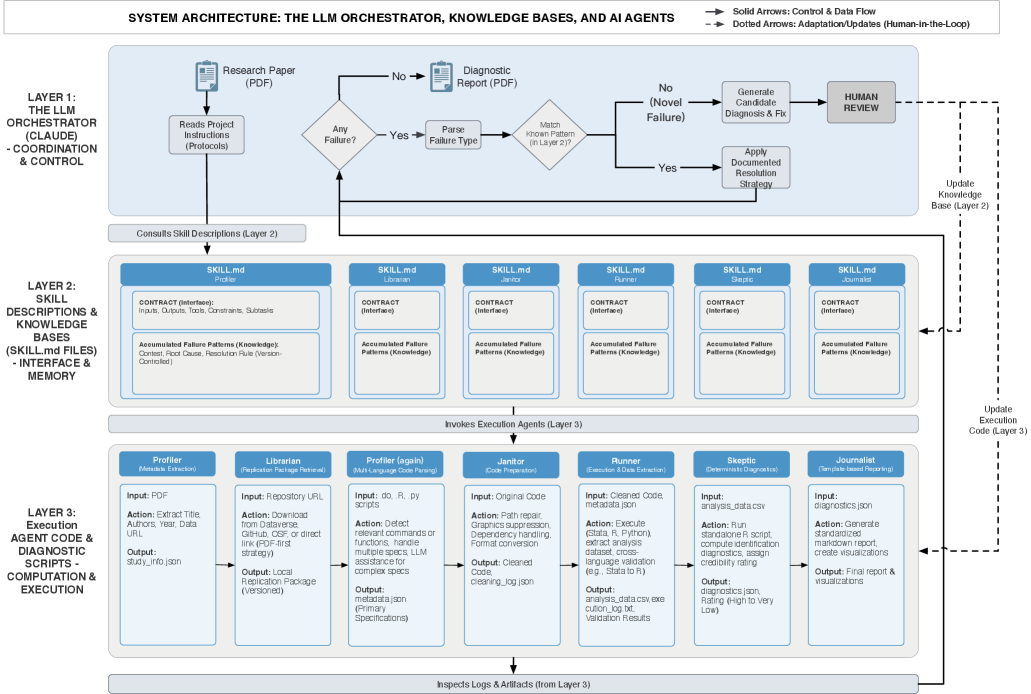
The automated workflow utilizes an agentic AI system to handle the complete lifecycle of empirical analysis reproduction. This involves automatically retrieving necessary replication packages – encompassing data, code, and analysis scripts – from specified sources. Once retrieved, the workflow executes the analysis as defined within the package, performing computations and generating results without manual intervention. This end-to-end automation is designed to reduce the time and effort required for reproducing research findings and to minimize potential human error in the execution process, ultimately enhancing the reliability and verifiability of scientific results.
The automated reproduction workflow utilizes deterministic agents to guarantee consistent analytical results. Each agent is designed to perform a singular, well-defined stage within the overall analysis pipeline – such as data retrieval, statistical computation, or visualization – and operates based on a pre-defined set of instructions and inputs. This deterministic behavior ensures that, given identical inputs, each agent will always produce the same output, eliminating variability introduced by non-deterministic processes. By isolating functionality into these discrete, deterministic agents, the system minimizes the potential for errors and facilitates the accurate reproduction of empirical analyses, a critical requirement for scientific validity and verification.
The LLM Orchestrator functions as the central control mechanism for the automated reproduction workflow. It is responsible for initiating and monitoring the entire pipeline, from retrieval of replication packages to execution of analyses and reporting of results. Task coordination is achieved by dynamically assigning specific stages to deterministic agents based on defined skill descriptions. Error handling is implemented through the Orchestrator’s ability to detect failed agent executions, trigger retry mechanisms, or implement alternative execution paths as defined within the workflow configuration. The Orchestrator utilizes the LLM to interpret agent outputs, assess pipeline status, and manage the overall lifecycle, ensuring robustness and adaptability in the face of unforeseen issues during the reproduction process.
Skill Descriptions function as formalized interfaces for each agent within the automated workflow, detailing both input and output expectations as well as access to relevant knowledge bases. These descriptions are structured to define the specific capabilities of each agent, including the data formats it accepts, the analyses it performs, and the results it produces. By explicitly defining these interfaces, Skill Descriptions facilitate modularity, allowing agents to be swapped or updated without impacting the overall workflow. Furthermore, this approach promotes reusability; agents with well-defined Skill Descriptions can be integrated into different pipelines or projects requiring similar analytical capabilities, reducing redundant development effort and ensuring consistency across analyses.
![The AI workflow generated a diagnostic report for Rueda (2017) including an executive summary of specification ratings and a coefficient comparison plot displaying various confidence intervals-analytic, bootstrap-cc, bootstrap-tt, [latex]t_{FtF}[/latex], and Anderson-Rubin-for specification 1.](https://arxiv.org/html/2602.16733v1/figs/Rueda_coef_comparison.png)
Assessing Reliability Through Automated Statistical Diagnostics
The automated workflow utilizes a suite of Statistical Diagnostics to evaluate the reliability of empirical findings. These diagnostics encompass a range of established statistical tests, including assessments for normality, heteroscedasticity, multicollinearity, and autocorrelation. Implementation involves calculating key metrics such as p-values, test statistics (e.g., F-statistic, t-statistic), and associated confidence intervals. The system systematically applies these tests to model residuals and key variables, providing quantitative measures of potential violations of statistical assumptions. Results are flagged if pre-defined thresholds are exceeded, indicating a need for model refinement or further investigation of the underlying data.
The system addresses the statistical challenge of endogeneity – where explanatory variables are correlated with the error term – through the implementation of advanced estimators, notably Two-Stage Least Squares (2SLS). 2SLS operates by first regressing the endogenous explanatory variable on the instrumental variables – those correlated with the endogenous variable but uncorrelated with the error term – to generate predicted values. These predicted values then replace the original endogenous variable in a second-stage regression, yielding consistent parameter estimates even in the presence of endogeneity. This automated application of 2SLS, alongside other estimators, enhances the reliability and validity of empirical results by mitigating potential biases arising from violations of key assumptions in standard regression models.
Automated statistical diagnostics minimize variability in research findings by enforcing a standardized application of statistical tests. Human researchers, even with identical data, may inadvertently select different tests or implement them with varying parameters, introducing inconsistencies. This system eliminates such subjective influences by systematically applying pre-defined statistical protocols to all analyses. This standardization not only improves the reproducibility of results but also mitigates the risk of confirmation bias, where researchers may unconsciously favor tests that support pre-existing hypotheses. The consistent application of these diagnostics ensures that all empirical claims are supported by statistically sound and objectively verifiable evidence.
The automated workflow demonstrates a 92.5% success rate in reproducing empirical results from a corpus of 92 instrumental variable (IV) studies. This metric represents the proportion of studies where the automated system successfully replicated the originally reported statistical findings, including coefficient estimates and significance levels. Reproducibility was determined by comparing the automated output to the reported statistics in the original publications. This level of success indicates the workflow’s capacity to reliably execute and validate complex empirical analyses, minimizing errors and ensuring consistent results across different implementations of the same research design.
![Comparing ordinary least squares (OLS) and two-stage least squares (2SLS) estimates reveals that the ratio between the two is strongly related to first-stage strength [latex]|\hat{\rho}(d,\hat{d})|[/latex], with observational designs (gray) and experiment-based instruments (red) exhibiting distinct patterns, particularly when OLS estimates are statistically significant.](https://arxiv.org/html/2602.16733v1/x2.png)
Towards a Self-Refining System for Validating Scientific Inquiry
The core of this validation system lies in its capacity for Adaptive Execution, a process enabling it to move beyond static analysis and actively learn from its mistakes. As the AI encounters discrepancies or errors during validation, it doesn’t simply flag them; it analyzes the root cause and adjusts its internal algorithms to prevent similar issues in the future. This iterative refinement is achieved through a feedback loop where each validation cycle informs and improves the next, effectively allowing the system to ‘teach itself’ more robust and accurate analysis techniques. The result is a self-improving workflow where performance isn’t fixed, but rather continuously enhanced, leading to a progressively more reliable and efficient validation process.
The core of this validation system lies in a continuous feedback loop that actively enhances its analytical capabilities. Following each assessment of scientific findings, the system doesn’t simply report discrepancies; it analyzes the source of those errors. This allows it to subtly adjust its internal algorithms, weighting certain analytical techniques more heavily or refining its criteria for identifying anomalies. Consequently, with each iteration, the system becomes more adept at anticipating and flagging potential issues – not just the errors it has already encountered, but also subtle variations and edge cases it might have previously overlooked. This self-correcting mechanism moves beyond simple error detection, enabling the system to proactively improve its ability to discern robust, reliable results from flawed data, ultimately leading to a more nuanced and effective validation process.
The validation system demonstrably addresses a wide spectrum of practical challenges encountered in scientific workflows, having autonomously resolved ten distinct classes of implementation issues. These aren’t merely isolated fixes, but rather represent a carefully curated catalog of common variations – errors in data handling, inconsistencies in unit conversions, flawed algorithmic assumptions, and subtle coding mistakes, among others. This comprehensive approach signifies a move beyond simply identifying bugs to proactively anticipating and correcting them, creating a robust framework capable of handling the inherent messiness of real-world scientific data and analysis. The resulting system isn’t just a validator; it’s an evolving repository of best practices, continually learning from past errors to improve future performance and ensure the reliability of research outputs.
A central challenge facing modern science is ensuring the reproducibility and reliability of research findings. This system addresses this issue through the automation and continual refinement of the validation process, moving beyond static checks to a dynamic, learning approach. By autonomously identifying and correcting implementation issues – currently encompassing ten distinct classes of common variations – the system not only reduces the incidence of errors but also adapts to new challenges as they emerge. This proactive approach aims to bolster confidence in scientific results, ultimately accelerating the rate at which new discoveries can be made and built upon, fostering a more robust and trustworthy scientific landscape.
The pursuit of reproducible research, as detailed in this workflow, echoes a fundamental principle of understanding any complex system: rigorous examination of its constituent parts. This work directly addresses the challenge of scaling reproducibility in empirical social science by automating execution and diagnostic testing – essentially, building a framework for consistently observing outcomes given defined inputs. As Henry David Thoreau observed, “It is not enough to be busy; so are the ants. The question is: What are we busy with?” This workflow provides a means to ensure that the ‘busy work’ of research – the execution and verification – doesn’t obscure the core questions, but rather facilitates a deeper, more reliable understanding of causal inference and empirical patterns.
What Lies Ahead?
The automation of reproducibility, as demonstrated, is not a destination but rather a shifting of the boundaries of ignorance. The workflow effectively addresses the ‘bits rot’ of computational social science, standardizing execution and flagging discrepancies. However, this very standardization begs the question of what systematic errors are now being consistently reproduced. The apparent gains in reliability are, inescapably, contingent on the completeness and accuracy of the underlying data and model specifications – areas where assurances remain stubbornly elusive.
Future iterations must move beyond diagnostic testing of code execution to incorporate more robust causal inference techniques, actively searching for latent biases within the data itself. The system currently flags how results differ; the next challenge lies in determining why – and, critically, whether those differences meaningfully alter substantive conclusions.
Ultimately, the pursuit of ‘reproducibility at scale’ highlights a fundamental paradox. By focusing on the mechanics of replication, the field risks mistaking consistency for truth. The real gains will come not from simply running more analyses, but from building systems that can intelligently question the assumptions embedded within them, and reveal the patterns hidden by the noise.
Original article: https://arxiv.org/pdf/2602.16733.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Total Football free codes and how to redeem them (March 2026)
- Limbus Company 2026 Roadmap Revealed
2026-02-20 14:01