Author: Denis Avetisyan
A new benchmark assesses whether large language model agents can reliably reproduce findings in the social and behavioral sciences, revealing critical hurdles beyond just code execution.
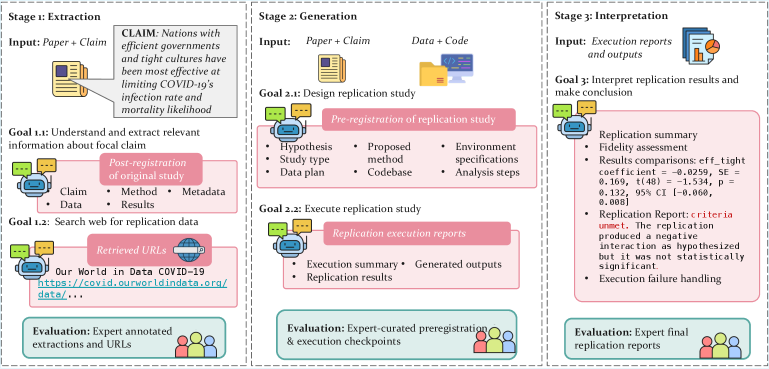
ReplicatorBench evaluates LLM agents’ ability to retrieve data, interpret results, and replicate research claims in fields like psychology and economics.
While current benchmarks assess AI agents’ capacity to reproduce research findings given code and data, they overlook the crucial challenges of real-world replication in the social and behavioral sciences. To address this gap, we introduce ReplicatorBench: Benchmarking LLM Agents for Replicability in Social and Behavioral Sciences, a novel end-to-end benchmark evaluating agents’ ability to navigate the full replication lifecycle-from data retrieval and experimental design to result interpretation-using both replicable and non-replicable claims. Our evaluation reveals that despite promising capabilities in experimental execution, current large language model (LLM) agents struggle significantly with the critical task of acquiring necessary resources, such as updated data, for successful replication. Can we develop agentic frameworks that effectively bridge the gap between computational reproducibility and the complexities of scientific replication in a dynamic research landscape?
The Fragile Foundation: Replicability in an Age of Automation
The foundations of scientific understanding rely on the ability to consistently reproduce published results, yet a growing body of evidence suggests a significant replication crisis is underway. Across diverse fields, studies have failed to yield the same conclusions when re-examined by independent researchers, casting doubt on the robustness of previously accepted findings. This isn’t necessarily indicative of intentional misconduct, but rather highlights the influence of factors like publication bias – where statistically significant results are more likely to be published – and questionable research practices. The inability to reliably replicate studies erodes confidence in the scientific record, potentially leading to wasted resources, flawed policies, and a diminished public trust in the process of scientific discovery. Addressing this crisis is paramount to ensuring the long-term integrity and progress of knowledge creation.
The painstaking process of manually replicating research findings presents a significant bottleneck in the social and behavioral sciences. Each attempt demands considerable time, skilled personnel, and substantial financial investment – resources often stretched thin even under ideal circumstances. This manual approach not only limits the number of studies that can be independently verified, but also introduces potential for human error and subjective interpretation, further complicating the validation process. Consequently, the slow pace of replication hinders the cumulative building of knowledge, delaying the identification of robust findings and impeding progress towards a more reliable and trustworthy scientific record. The sheer logistical challenge associated with manual replication frequently results in important studies remaining unverified for years, effectively slowing the advancement of the field.
Addressing the growing concerns surrounding the reproducibility of scientific findings, researchers are increasingly turning to automated replication powered by intelligent agents. This approach offers a significant advantage over traditional manual replication, which is both costly and limited in scope. A newly developed benchmark demonstrates the viability of this automated system, containing 1,568 distinct, evaluable checkpoints distributed across 19 separate studies. This rigorous testing showcases the potential for scalable validation of existing research, effectively strengthening the scientific record by systematically verifying published results and identifying areas where further investigation is needed. The system doesn’t simply confirm or deny findings, but provides granular, checkpoint-level assessments, offering a detailed audit trail of the replication process and fostering greater transparency within the scientific community.
Dissecting the Process: A Framework for Automated Replication
ReplicatorBench utilizes a three-stage framework to assess an agent’s capacity for research claim replication. The initial Extraction stage centers on identifying and collecting pertinent information directly from the source research paper, alongside acquiring any necessary data resources for subsequent steps. Following extraction, the Generation stage focuses on establishing an executable computational environment and executing the code required to reproduce the original study’s findings. Finally, the Interpretation stage involves analyzing the generated results to determine if the replication was successful and comparing them to the original research outcomes, providing a systematic and quantifiable measure of replicability.
The Extraction Stage of ReplicatorBench is designed to assess an agent’s capability to identify and collect essential information from a research paper and its associated data resources. Performance in this stage is quantified using an LLMEval score, which measured 66.57 for the automated agent. For comparison, human annotators achieved a score of 72.14 on the same task, indicating a current performance gap between automated agents and human expertise in accurately extracting the necessary components for replication. This stage prioritizes retrieving elements like experimental setup details, datasets used, and key parameters reported in the original study.
The Generation Stage of ReplicatorBench centers on establishing a functional computational environment to execute the study’s associated code. This involves dependency installation, data loading, and code execution as specified in the original research. Successful completion of this stage requires not only accurate code reproduction but also verification that the generated results align with the reported findings. The framework assesses the ability to create a reproducible computational workflow, moving beyond simple code replication to functional execution and result generation.
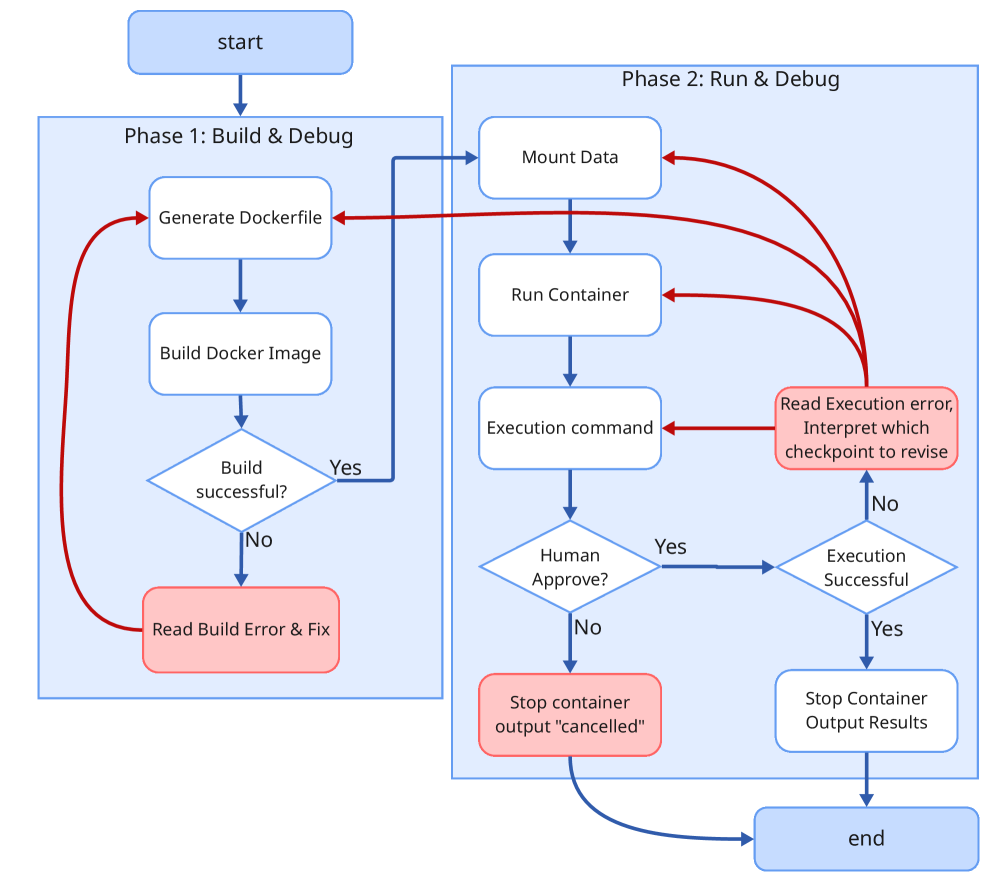
The Translation Problem: Bridging the Language Gap in Research
A significant portion of academic research, particularly in fields like computer science and engineering, publishes accompanying code implementations in languages such as C++, Java, MATLAB, and R. This presents a fundamental challenge for Large Language Model (LLM) agents designed to interpret and execute research findings, as these agents typically operate within the Python ecosystem. The disparity in programming languages necessitates a translation step to allow LLMs to utilize and replicate the results detailed in these papers; without this capability, agents are limited to only processing research described textually, hindering their ability to validate or extend existing work through code execution and experimentation.
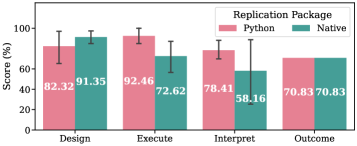
Effective replication of research findings by language model agents necessitates the translation of code written in languages other than Python – termed ‘Native Code’ – into executable Python. This translation process is crucial because most LLM agents operate primarily within the Python ecosystem and lack native support for other programming languages. Accurate conversion of algorithms and logic from Native Code to Python allows agents to not only understand the research methodology but also to execute the code, verify results, and build upon existing work. The ability to perform this translation autonomously is a key capability for agents aiming to automate the scientific process and facilitate reproducible research.
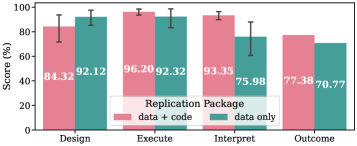
A data-only setting evaluates an agent’s capacity to recreate functional code solely from research paper descriptions, without access to the original source code implementation. This rigorously tests the agent’s comprehension of algorithmic logic and its ability to translate natural language explanations into executable Python. Performance in this setting highlights limitations in an agent’s reasoning and code generation capabilities, specifically its reliance on directly copying or adapting existing code rather than independently deriving a correct implementation. Consequently, a data-only evaluation provides a clear metric for assessing an agent’s true understanding of the underlying research and its proficiency in code synthesis.
The Judge in the Machine: Evaluating Replication with LLMs
The Interpretation Stage of replication validation necessitates the application of statistical analysis to determine the success or failure of replication attempts. This involves evaluating the outputs generated during replication against the original results, utilizing methods to quantify the degree of correspondence. Statistical measures employed can include, but are not limited to, t-tests, ANOVA, and correlation coefficients, depending on the nature of the replicated task and data types. The purpose of this analysis is to objectively assess whether the replicated results are statistically significantly similar to the original findings, accounting for potential noise or variation inherent in the replication process, and to provide a quantifiable metric for evaluating replication fidelity.
The ‘LLM-as-a-Judge’ methodology utilizes large language models to objectively evaluate the outputs generated by replicating agents. This assessment isn’t based on simple output matching; instead, the LLM analyzes the replicated results to determine their fidelity to the original findings, considering factors such as statistical significance and methodological soundness. This approach allows for nuanced evaluation beyond pass/fail criteria, providing a means to quantify the quality of replication and identify potential areas where agents struggle with complex research tasks. The LLM’s judgment is then used to score the performance of individual agents and the overall replication process, facilitating comparative analysis and iterative improvement of agent capabilities.
The ReplicatorAgent functions as a foundational, tool-utilizing agentic system designed to facilitate and assess the ReplicatorBench evaluation process. This agent provides a standardized framework for conducting replication studies and measuring their success. Performance metrics, as demonstrated in initial evaluations, indicate a Macro F1 Score of 0.5476 when applied to replication outcomes; this score reflects the agent’s ability to accurately identify and reproduce research findings within the ReplicatorBench environment and serves as a benchmark for comparing the performance of more advanced agentic systems.
The Looming Horizon: Scaling Validation with Advanced LLMs
The ReplicatorAgent’s effectiveness is intrinsically linked to the capabilities of large language models, with advancements in these models directly translating to improved replication success. Current research demonstrates that GPT-5 significantly outperforms its predecessor, GPT-4o, achieving a 20% net gain in recall when tasked with replicating scientific findings. This boost in performance isn’t merely incremental; it suggests that more sophisticated LLMs are better equipped to understand complex methodologies, identify crucial experimental parameters, and accurately reconstruct research procedures. The enhanced recall rate indicates a reduced likelihood of false negatives-instances where a valid finding is incorrectly deemed non-replicable-and underscores the potential for LLMs to become indispensable tools in the pursuit of robust and verifiable scientific knowledge. Further refinement of these models, such as the o3 architecture, promises even greater accuracy and efficiency in the automated replication process.
The advent of automated replication, exemplified by the ReplicatorBench, presents a transformative opportunity to expedite the pace of scientific discovery. By systematically re-executing studies and comparing results, this approach moves beyond traditional peer review to offer an objective assessment of research robustness. Successfully replicated findings gain increased credibility, while inconsistencies or failures to replicate serve as critical flags, prompting further investigation into potential methodological flaws, biases, or even fraudulent practices. This proactive identification of questionable research isn’t intended to punish, but rather to refine the body of scientific knowledge, ensuring that future research builds upon a foundation of reliable and verifiable results – ultimately accelerating progress across all disciplines.
The automation of scientific replication, driven by tools like ReplicatorBench and advanced language models, holds substantial promise for bolstering the integrity of the scientific record. By systematically re-examining published findings, this approach doesn’t simply accumulate confirmations, but actively identifies inconsistencies and potential errors, thereby mitigating the spread of flawed research. This rigorous process fosters a more reliable foundation of knowledge, encouraging greater confidence in published results and ultimately strengthening public and professional trust in the scientific enterprise. A consistent application of automated replication isn’t merely about verifying existing claims; it’s about cultivating a self-correcting system that prioritizes robustness and transparency, leading to a more credible and dependable body of scientific understanding.
The pursuit of replicability, as championed by ReplicatorBench, isn’t merely a technical exercise, but a recognition of inherent systemic fragility. The benchmark’s focus extends beyond code execution to the murkier realms of data retrieval and interpretation, acknowledging that even perfect execution cannot guarantee consistent results when foundational data shifts. This resonates with a sentiment expressed by Ken Thompson: “There are no best practices – only survivors.” The ecosystem of computational social science, much like any complex system, doesn’t yield to rigid control. Instead, it favors adaptability, recognizing that order is, at best, a temporary reprieve-a cache between inevitable outages. ReplicatorBench, therefore, doesn’t promise solutions, but offers a means of measuring resilience in the face of inherent uncertainty.
What Lies Ahead?
ReplicatorBench does not solve the problem of replication-it exposes the inevitable sites of its failure. The benchmark rightly shifts focus beyond mere code execution, acknowledging that the true bottleneck lies in the messy, ambiguous work of translating claims into retrievable data and interpretable results. A system that never breaks is a dead one, and any benchmark that appears to achieve perfect replication should be viewed with profound skepticism. It has merely found a way to exclude the very complexities that define social and behavioral science.
The current emphasis on LLM agents as replicators presupposes a static body of knowledge to replicate. Yet, the social world is not a fixed object, but a constantly evolving ecosystem. Future work should not ask if an agent can reproduce a past result, but how it adapts to-and is ultimately confounded by-a changing landscape. The benchmark itself, too, must be treated as a temporary scaffolding, destined to be overtaken by the very systems it attempts to evaluate.
Perfection leaves no room for people. A truly useful benchmark will not deliver flawless replication, but rather illuminate the points of divergence-the subtle interpretations, the unarticulated assumptions-where human judgment remains essential. The goal is not to automate social science, but to understand the limits of automation, and to preserve the space for critical inquiry.
Original article: https://arxiv.org/pdf/2602.11354.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Gold Rate Forecast
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Total Football free codes and how to redeem them (March 2026)
- Nicole Kidman and Jamie Lee Curtis elevate new crime drama Scarpetta, which is streaming now
- Olivia Colman’s highest-rated drama hailed as “exceptional” is a must-see on TV tonight
2026-02-13 12:02