Author: Denis Avetisyan
A new benchmark challenges large language models to move beyond memorization and demonstrate true experimental reasoning in the life sciences.
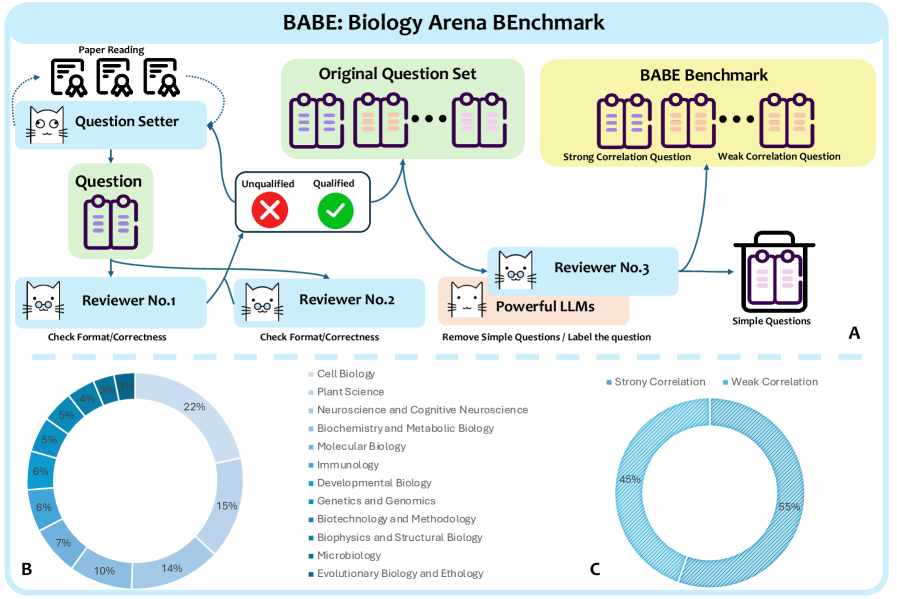
BABE-the Biology Arena Benchmark-rigorously assesses a model’s ability to integrate experimental results with existing biological knowledge.
While large language models excel at increasingly complex tasks, robustly evaluating their capacity for genuine scientific reasoning-specifically integrating experimental results with existing biological knowledge-remains a challenge. To address this gap, we introduce ‘BABE: Biology Arena BEnchmark’, a novel benchmark constructed from peer-reviewed research to assess the experimental reasoning capabilities of biological AI systems. BABE uniquely challenges models to perform causal reasoning and cross-scale inference, offering a more authentic measure of their potential to contribute to biological research. Will this benchmark facilitate the development of AI systems capable of truly accelerating scientific discovery in the life sciences?
Deconstructing Biological Reasoning: The Limits of Pattern Recognition
Large language models demonstrate a remarkable capacity for identifying patterns within data, a skill honed through exposure to vast textual datasets. However, this proficiency doesn’t readily translate to the complexities of biological reasoning. Interpreting biological experiments demands more than simply recognizing correlations; it requires understanding causal relationships, accounting for confounding variables, and integrating findings with a pre-existing framework of biological knowledge. Current LLMs often falter when faced with the subtle nuances of experimental design, the ambiguity inherent in biological systems, and the need to extrapolate beyond explicitly stated information. While adept at identifying that ‘gene A is often expressed when condition B is present’, these models struggle to determine why this correlation exists, or whether it indicates a direct causal link, a functional relationship, or merely a coincidental observation – a critical distinction for accurate scientific inference.
Many existing artificial intelligence benchmarks, designed to assess reasoning capabilities, fall short when applied to biological research due to a reliance on simplistic problem structures. These benchmarks frequently prioritize pattern matching over the sequential, multi-step logic inherent in interpreting experimental data; an AI might correctly identify keywords or correlations without truly understanding the underlying biological processes. Consequently, performance metrics can be artificially inflated, suggesting a level of reasoning ability that doesn’t translate to real-world biological inquiry. The nuance of contextual understanding – recognizing how prior knowledge shapes interpretation, or how experimental limitations impact conclusions – is often absent, leading to systems that excel at superficial analysis but struggle with the integrative reasoning essential for scientific discovery. This discrepancy highlights the need for more sophisticated evaluation tools that mirror the complexity and iterative nature of biological investigation.
The true test of artificial intelligence in biology hinges not on recognizing patterns, but on synthesizing knowledge and interpreting experimental findings with the same rigor as a seasoned researcher. Current evaluation methods often fall short, providing a superficial measure of performance that doesn’t reflect an AI’s capacity for genuine biological reasoning. A crucial advancement requires benchmarks designed to challenge AI systems with tasks demanding the integration of new data – from experiments – with established biological principles. These benchmarks must assess whether an AI can formulate hypotheses, evaluate evidence, and ultimately, draw valid conclusions – mirroring the iterative process of scientific discovery and revealing a system’s ability to move beyond mere data correlation towards meaningful biological understanding.
BABE: A Benchmark Forged in the Crucible of Real Research
The Benchmark for Experimental Biological Insight (BABE) is uniquely constructed by sourcing tasks directly from published, peer-reviewed biological research. This methodology ensures a high degree of ecological validity, as the benchmark’s challenges are not artificially generated, but rather reflect the complexities and nuances of actual scientific investigations. Specifically, BABE tasks are derived from experimental designs, data analysis, and interpretations presented in existing literature, thereby focusing assessment on skills directly applicable to real-world biological research and reducing the potential for solutions that exploit spurious correlations present in synthetic datasets. This approach differentiates BABE from benchmarks relying on artificially constructed problems and prioritizes the evaluation of reasoning abilities within the context of authentic scientific inquiry.
The BABE benchmark utilizes two distinct question types to evaluate reasoning capabilities: ‘Strong Correlation Questions’ and ‘Weak Correlation Questions’. Strong Correlation Questions require models to perform sequential reasoning, processing information in a specific order to arrive at an answer, mimicking the step-by-step analysis often needed in experimental interpretation. Conversely, Weak Correlation Questions assess parallel information extraction, where the answer is derived from simultaneously considering multiple pieces of data without a strict sequential dependency. This dual approach ensures a comprehensive assessment of reasoning skills, moving beyond simple associative learning and probing a model’s ability to handle both linear and non-linear relationships within biological data.
The BABE benchmark differentiates itself from typical machine learning evaluations by requiring models to synthesize information from both experimental data and pre-existing biological knowledge. Unlike tasks solvable through pattern recognition within datasets, BABE questions are designed such that correct answers necessitate understanding the context of the experiment – including the biological principles at play, the rationale behind specific methodologies, and the implications of the results. This integration requirement moves beyond superficial correlations and compels models to demonstrate a form of reasoning that mirrors the analytical process of a human biologist, assessing not just what happened in an experiment, but why it happened and what it means in a broader biological context.
Amplifying Intelligence: Context and Reasoning as Force Multipliers
Achieving strong performance on the Big-Bench Active Reasoning Evaluation (BABE) requires methodologies that extend beyond standard large language model (LLM) architectures. This is because BABE tasks often demand specific background knowledge not inherently present within the LLM’s pre-training data. ‘Contextual Grounding’ addresses this limitation by explicitly providing the LLM with relevant external information during inference. This process involves retrieving and incorporating pertinent data, allowing the model to reason more effectively and accurately on tasks requiring specialized or up-to-date knowledge, ultimately improving performance where a simple parametric response would be insufficient.
Retrieval-Augmented Generation (RAG) is implemented within Deep Research Agents to improve reasoning capabilities by dynamically accessing and incorporating external data sources. This technique mitigates the limitations of LLMs’ fixed knowledge cutoffs and allows the agent to ground its responses in current and specific information. The process involves retrieving relevant documents or data fragments based on the current reasoning task, then augmenting the LLM’s input with this retrieved context. This enables the LLM to generate more informed, accurate, and contextually relevant outputs, effectively expanding its knowledge base during inference without requiring retraining of the model itself.
Multi-Trial Inference improves Large Language Model (LLM) performance by executing multiple inference runs and aggregating the results. This technique enhances both the robustness and accuracy of LLM outputs, particularly for models already demonstrating strong reasoning capabilities. Observed gains from implementing Multi-Trial Inference range up to 30 points on relevant benchmarks. Importantly, the benefit plateaus at approximately 30 points, indicating asymptotic gains; further increasing the number of trials beyond a certain point yields diminishing returns in performance improvement.
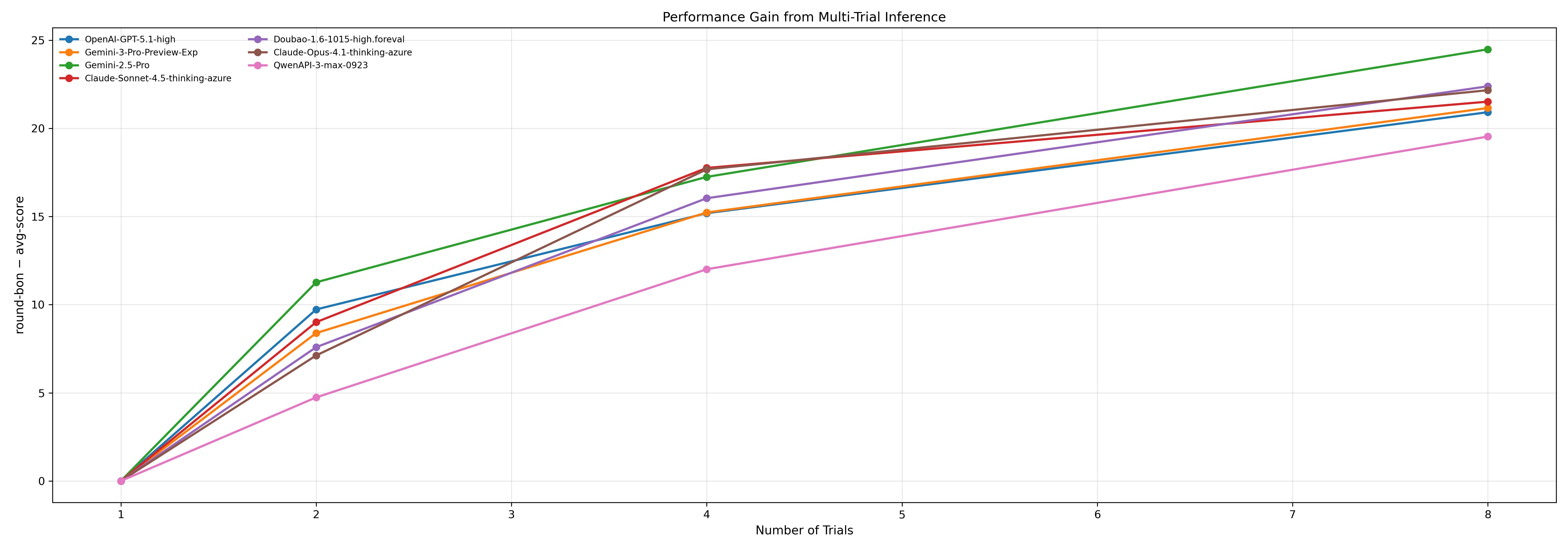
Beyond Correlation: Charting a Course for Truly Intelligent Biological Systems
Evaluation of large language models, including GPT-5.1 and Gemini-3-Pro, using the novel BABE benchmark demonstrates substantial differences in their capacity for biological reasoning. While OpenAI’s GPT-5.1-high achieved the highest average score of 52.31, performance varied considerably across models, indicating that current AI systems still struggle with the complexities of interpreting biological experiments. This disparity suggests a critical need to move beyond simple knowledge recall and focus on developing AI capable of nuanced, contextual understanding and genuine inferential reasoning within the life sciences. The benchmark’s design, emphasizing realistic experimental scenarios, highlights the limitations of existing models and underscores the challenges in creating AI that can effectively contribute to biological research.
Current biology-specific benchmarks often assess factual recall, but the BABE benchmark pushes beyond simple knowledge retrieval to evaluate a model’s ability to interpret experimental design and draw logical conclusions. This benchmark achieves a more nuanced assessment by presenting scenarios that require reasoning about potential confounding factors, appropriate controls, and the validity of experimental results – skills crucial for genuine biological understanding. Notably, OpenAI’s GPT-5.1-high achieved a Strong Correlation score of 51.79 and a Weak Correlation score of 52.86, indicating a moderate ability to navigate these complex reasoning tasks, though still leaving considerable room for improvement in aligning AI performance with expert biological reasoning.
The current limitations in artificial intelligence’s ability to accurately interpret and apply biological knowledge, as revealed by performance on benchmarks like BABE, necessitate a focused research agenda. Progress demands innovation in knowledge grounding – ensuring AI systems connect abstract concepts to concrete biological realities – and a significant enhancement of reasoning capabilities, moving beyond pattern recognition to true inferential thinking. Ultimately, the development of AI capable of addressing complex biological research questions requires a paradigm shift towards systems that not only process data but also understand underlying mechanisms, formulate hypotheses, and critically evaluate evidence – a challenge that promises to unlock new frontiers in both artificial intelligence and biological discovery.
The creation of BABE, as a rigorous benchmark for biological reasoning, echoes a fundamental principle of knowledge acquisition: understanding emerges from challenging existing frameworks. It’s not enough for a large language model to simply contain biological information; it must demonstrate an ability to synthesize, analyze, and extrapolate – to essentially ‘break’ the problem down to its core components and rebuild understanding. This pursuit of robust evaluation aligns perfectly with the spirit of Paul Erdős, who once stated, “A mathematician knows a great deal and knows very little.” The benchmark isn’t about finding models that ‘know’ everything, but identifying those capable of discerning the boundaries of their knowledge and, crucially, how to navigate them-an exploit of comprehension in the arena of biological research.
Pushing the Boundaries
The introduction of BABE isn’t about establishing a new high score; it’s an admission that current large language models still fundamentally misunderstand experimentation. They can correlate, they can regurgitate, but true biological reasoning demands more than sophisticated pattern matching. The benchmark highlights a critical gap: the ability to dynamically integrate new, potentially contradictory, experimental data with pre-existing knowledge, and to reason about why an experiment succeeded or failed – not simply predict the outcome. It’s a system built to be stressed, to reveal where the elegant façade of understanding breaks down.
Future iterations shouldn’t focus solely on increasing dataset size or model parameters. Instead, the field needs to grapple with the inherent messiness of biological systems. Introducing noise, ambiguity, and incomplete data – actively breaking the models – will be far more illuminating than striving for ever-higher accuracy on curated datasets. The real challenge lies in building agents that don’t just answer questions, but formulate better questions, designing experiments to resolve uncertainty.
Ultimately, BABE serves as a provocation. It suggests that evaluating biological reasoning isn’t about achieving consensus, but about identifying and exploiting points of contention. The aim isn’t to create a model that confirms what is already known, but one that aggressively challenges it – a digital contrarian, relentlessly seeking the flaws in the prevailing narrative.
Original article: https://arxiv.org/pdf/2602.05857.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- GearPaw Defenders redeem codes and how to use them (April 2026)
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Limbus Company 2026 Roadmap Revealed
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- Gold Rate Forecast
2026-02-06 15:18