Author: Denis Avetisyan
A new benchmark assesses how well artificial intelligence can independently complete full data science workflows, from initial analysis to final results.
The study evaluates generative AI performance on end-to-end data science tasks, finding strong capabilities but ongoing need for human judgment and validation.
Despite advances in artificial intelligence, comprehensive evaluation remains limited to isolated skills rather than integrated workflows. This is addressed in ‘Benchmarking AI Performance on End-to-End Data Science Projects’, which introduces a new benchmark comprising 40 complete data science projects to systematically assess generative AI’s capabilities. Results demonstrate that while recent models can achieve performance comparable to an undergraduate data scientist on structured tasks, significant gaps remain in areas requiring subjective judgment and necessitating human verification. As AI increasingly automates analytical processes, how can we best ensure responsible implementation and maintain critical oversight in complex data science applications?
The Bottleneck in LLM Advancement: Beyond Superficial Metrics
The development of Large Language Models (LLMs) is significantly slowed by the reliance on human evaluation, a process that demands substantial resources and time. Assessing the quality of LLM outputs – verifying accuracy, relevance, and coherence – traditionally requires skilled annotators to manually review and score responses. This manual approach doesn’t scale effectively with the increasing size and complexity of these models, creating a bottleneck in the iterative development cycle. Each refinement necessitates repeated human assessment, driving up costs and delaying progress. Furthermore, subjective human judgments introduce variability and potential bias, making reliable performance comparisons difficult and hindering the ability to consistently improve model capabilities. The sheer volume of data required for robust evaluation exacerbates these challenges, making fully manual processes impractical for cutting-edge LLM research and deployment.
Current evaluation benchmarks for Large Language Models frequently fall short when gauging their capacity for genuine data science tasks. These benchmarks often prioritize narrow, isolated skills-like memorizing facts or performing simple arithmetic-over the multifaceted reasoning required for complex analytical workflows. A typical benchmark might assess a model’s ability to write SQL queries, but fails to evaluate its capacity to formulate a relevant research question, identify appropriate datasets, critically assess results, or communicate findings effectively. This limited scope creates a disconnect between benchmark scores and real-world performance; a model achieving high marks on simplified tests may still struggle with the ambiguity, nuance, and iterative problem-solving characteristic of authentic data science projects. Consequently, relying solely on existing benchmarks can provide an overly optimistic-and potentially misleading-assessment of an LLM’s true capabilities in tackling complex data challenges.
The relentless pursuit of more capable Large Language Models (LLMs) demands evaluation strategies that match the pace of innovation. Currently, manual assessment of LLM performance presents a significant bottleneck, proving both costly and impractical for iterative development cycles. Scalable, automated evaluation isn’t merely about speed; it’s about establishing reliable comparative metrics. These systems allow developers to rigorously test models across diverse datasets and complex tasks, uncovering subtle strengths and weaknesses that might otherwise remain hidden. Without standardized, automated benchmarks, gauging true progress becomes difficult, hindering responsible development and impeding the deployment of LLMs in critical applications. The ability to consistently and efficiently assess LLM capabilities is, therefore, foundational to accelerating advancement and ensuring these powerful tools meet real-world demands.
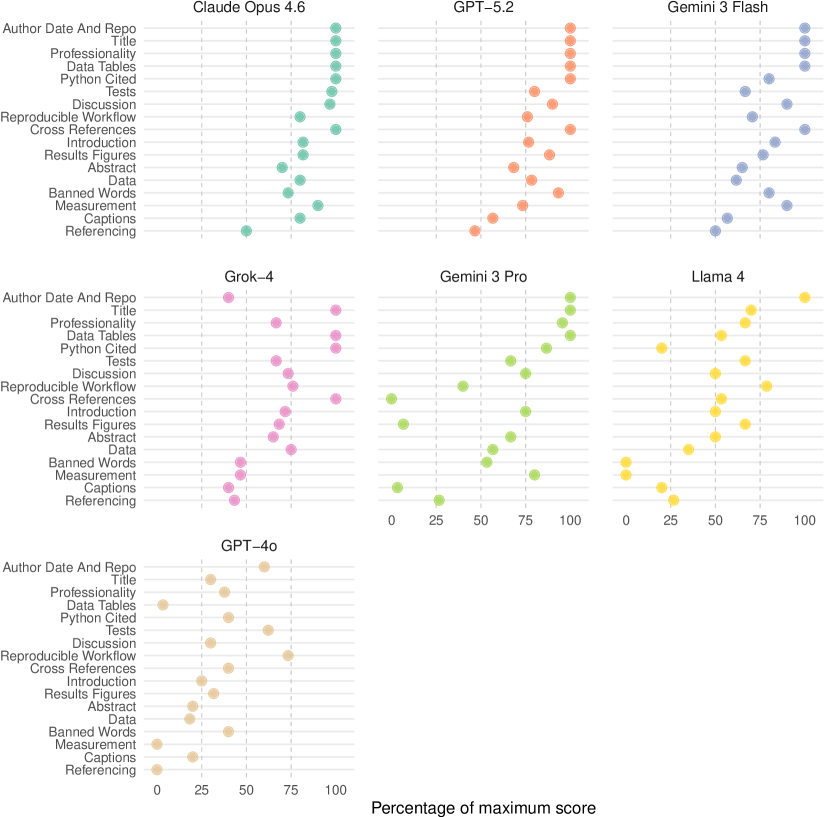
![Model performance, assessed across rubric categories-Reproducibility ([latex]9[/latex] points), Presentation ([latex]10[/latex] points), Analysis ([latex]10[/latex] points), Graphs ([latex]8[/latex] points), Referencing ([latex]4[/latex] points), and Writing ([latex]4[/latex] points)-is reported as a percentage of the maximum achievable score for each category.](https://arxiv.org/html/2602.14284v1/x2.png)
DataSciBench: A Benchmark Rooted in Practical Data Science
DataSciBench is a newly developed benchmark intended to assess the capabilities of Large Language Models (LLMs) when applied to complete data science workflows. Unlike benchmarks focused on isolated tasks, DataSciBench requires LLMs to execute a full project lifecycle, including data cleaning, exploratory data analysis, data visualization, and the development of predictive models. This holistic approach provides a more comprehensive evaluation of an LLM’s ability to integrate multiple data science techniques and deliver a functional solution, simulating real-world data science tasks and assessing end-to-end problem-solving abilities. The benchmark aims to move beyond simple code generation and evaluate an LLM’s capacity for practical data science application.
DataSciBench leverages datasets obtained from Open Data Toronto to provide a realistic assessment of LLM capabilities in data science. These datasets are not synthetically generated; they represent actual, publicly available information collected by the City of Toronto, introducing the complexities inherent in real-world data such as missing values, inconsistencies, and varying data types. The selection of these datasets ensures the benchmark evaluates LLMs on tasks mirroring practical data science projects, rather than idealized scenarios, and encompasses a range of domains including city services, demographics, and urban planning. This focus on authenticity is intended to provide a more reliable indicator of an LLM’s ability to perform data science tasks in production environments.
DataSciBench employs a standardized nine-step project workflow to facilitate consistent LLM prompting and rigorous evaluation. This process encompasses problem definition, data acquisition, data cleaning, exploratory data analysis, feature engineering, model selection, model training, model evaluation, and final report generation. The pipeline leverages specific tools to ensure reproducibility and structure: Quarto for document creation and report generation, UV for dependency management and environment isolation, and pydantic for data validation and schema definition. This structured approach allows for objective assessment of an LLM’s capabilities across the complete data science lifecycle, moving beyond isolated task performance.
The DataSciBench pipeline integrates BibTeX to facilitate reproducible research and ensure accurate citation of all utilized resources. Each project within the benchmark explicitly manages dependencies and references through a BibTeX file, detailing data sources, relevant publications, and software packages. This allows for verification of the project’s foundation and enables researchers to trace the origins of any applied methodology or utilized dataset. The BibTeX entries are programmatically incorporated into generated reports, guaranteeing consistent and verifiable citations throughout the evaluation process and promoting transparency in the LLM’s project execution.
LLM-as-a-Judge: Automating Evaluation with Rigorous Standards
The ‘LLM-as-a-judge’ pipeline utilizes Anthropic’s Claude Sonnet 4.5 model to provide automated evaluation of projects created by other large language models. This system is designed to assess generated code and related deliverables, offering a scalable solution for benchmarking and comparing the performance of different LLMs. The implementation focuses on objective assessment by applying a predefined rubric to each project, enabling consistent and repeatable evaluation across a large dataset. This automated pipeline streamlines the grading process, reducing the need for manual review and facilitating more frequent and comprehensive performance analysis.
The automated evaluation pipeline employs a predefined rubric to standardize assessment across all projects. This rubric explicitly defines criteria for code correctness, evaluating functional accuracy and adherence to coding best practices; data analysis quality, focusing on the validity of methodologies and the interpretation of results; and overall project structure, encompassing code organization, documentation, and modularity. Utilizing a rubric ensures consistent and objective grading by providing a clear, quantifiable framework for evaluating each project component, minimizing subjective bias in the assessment process and enabling reproducible results.
To establish the reliability of the automated grading pipeline, a cross-evaluation was performed using GPT-5.2 on a representative subset of projects. This secondary evaluation served to verify the consistency of the LLM-as-a-Judge system and mitigate potential biases in scoring. The results demonstrated a high degree of agreement between the two evaluation methods, indicated by a standard deviation of only 1.2 points out of a total possible score of 45. This low standard deviation confirms the robustness and dependability of the automated pipeline in providing consistent and objective project assessments.
The LLM-as-a-judge pipeline underwent performance validation utilizing established benchmarks in the software engineering and coding domains. Specifically, the system was assessed using HumanEval, a dataset focused on functional code generation; MBPP (Mostly Basic Programming Problems), which evaluates code correctness on simpler tasks; and SWE-bench, a more comprehensive suite designed to measure performance across a range of software engineering challenges. Evaluation against these benchmarks provided quantitative data regarding the system’s ability to accurately and consistently assess code quality and functionality, demonstrating its applicability to diverse coding tasks and problem-solving scenarios.
Performance Landscape: Discerning True Data Science Proficiency
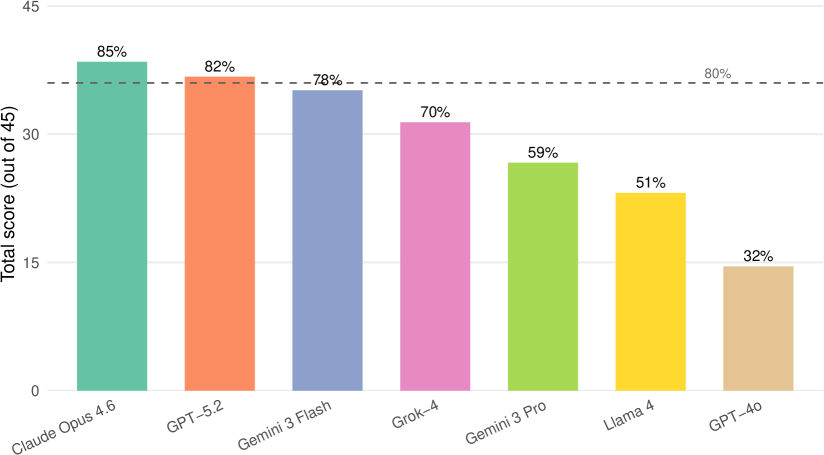
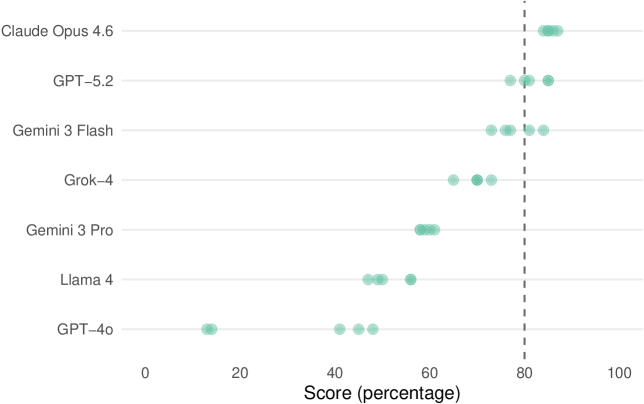
Claude Opus 4.6 demonstrated exceptional capabilities in data science reasoning, consistently achieving the highest scores on the DataSciBench assessment. The model attained an overall performance of 85%, surpassing all other large language models evaluated and exceeding the benchmark’s threshold for an A-/B+ level undergraduate student – a score of 80%. This result indicates a robust understanding of data manipulation, analysis, and problem-solving within the scope of the benchmark’s tasks, suggesting a significant advancement in the ability of AI to perform complex data science workflows. The consistently high performance positions Claude Opus 4.6 as a leading model for applications requiring sophisticated data reasoning and analytical capabilities.
Evaluations reveal GPT-5.2 demonstrated a level of performance remarkably close to that of the leading model, Claude Opus 4.6, both achieving scores of 82% and 85% respectively on the DataSciBench assessment. This parity suggests significant advancements in GPT-5.2’s capabilities, particularly in tackling complex data science challenges. The near-identical scores indicate a comparable ability to process information, solve problems, and generate accurate results within the scope of the benchmark’s tasks. This competitive standing positions GPT-5.2 as a highly capable large language model, offering performance that closely rivals the current industry leader and showcasing substantial progress in artificial intelligence.
Gemini 3 Flash demonstrated robust capabilities, achieving a score of 78% on the DataSciBench assessment – a performance level comparable to an A- or B+ grade in an undergraduate course. This result positions the model as a strong contender within the current landscape of large language models, showcasing its ability to effectively address complex data science challenges. The score suggests a solid grasp of fundamental principles and a capacity for practical application, indicating that Gemini 3 Flash can reliably handle tasks representative of real-world data workflows. Its performance highlights a significant advancement in model capabilities and suggests its potential as a valuable tool for data scientists and researchers alike.
The evaluation of GPT-4o on the DataSciBench revealed a moderate level of proficiency, achieving an overall score of 32%. This result signifies a considerable performance gap when contrasted with contemporary large language models such as Claude Opus 4.6, GPT-5.2, and Gemini 3 Flash, all of which demonstrated substantially higher scores. The disparity underscores the rapid advancements in the field, highlighting how quickly newer architectures and training methodologies can surpass the capabilities of previously state-of-the-art models in complex data science tasks. While still a capable system, GPT-4o’s performance suggests a need for ongoing development to maintain competitiveness against the latest generation of LLMs.
The increasing sophistication of large language models (LLMs) necessitates robust evaluation beyond simple conversational ability. Recent benchmarking efforts emphasize the critical need for comprehensive datasets mirroring authentic data science workflows, including tasks like data manipulation, statistical analysis, and machine learning model building. Such evaluations reveal that performance on generic benchmarks doesn’t always translate to practical data science competency; a model excelling at text generation might falter when presented with a complex pandas DataFrame or asked to interpret statistical outputs. Consequently, benchmarks like DataSciBench provide a more nuanced understanding of an LLM’s capabilities, pinpointing strengths and weaknesses in specific data science areas and guiding future model development towards genuinely useful applications.
The pursuit of automated evaluation in data science, as explored in this work, echoes a fundamental human challenge: discerning quality without exhaustive examination. This mirrors Pascal’s observation that ‘The heart has its reasons which reason knows nothing of.’ While LLMs like Claude Opus 4.6 demonstrate impressive capabilities in completing data science workflows – even reaching undergraduate-level performance – the benchmark reveals a critical need for human oversight, particularly where nuanced judgment is required. The model’s output, however statistically sound, lacks the intuitive understanding necessary for truly elegant solutions, reminding us that complete automation, even in technical fields, remains an elusive ideal. The benchmark’s focus on end-to-end projects isn’t merely about assessing technical skill; it’s about evaluating the ability to synthesize information and arrive at meaningful conclusions – a distinctly human trait.
What’s Next?
The pursuit of automated intelligence in data science, as demonstrated by this work, reveals a curious paradox. Models now approach, and occasionally surpass, the performance of a novice-a feat not insignificant. Yet, the lingering necessity of human oversight isn’t a technological failing, but a signal. It suggests that true understanding isn’t merely about arriving at a correct answer, but about the justification of that answer-a process that, at present, demands a nuanced judgment currently beyond the reach of even the most sophisticated algorithms. A good interface is invisible to the user, yet felt; similarly, a truly intelligent system should not simply produce results, but articulate its reasoning.
Future work must therefore move beyond metrics of simple accuracy. The focus should shift toward evaluating a model’s ability to explain its choices, to identify its own limitations, and to acknowledge uncertainty. The current benchmark, while valuable, represents only a single slice of the data science lifecycle. Expanding this to encompass iterative refinement, active learning, and the ethical considerations inherent in data-driven decision-making will be critical. Every change should be justified by beauty and clarity.
Ultimately, the goal isn’t to replace the data scientist, but to augment their capabilities. The true measure of progress will not be how much automation is achieved, but how much insight is unlocked. The pursuit of artificial intelligence should, therefore, be tempered by a healthy dose of humility-a recognition that elegance isn’t optional; it is a sign of deep understanding and harmony between form and function.
Original article: https://arxiv.org/pdf/2602.14284.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
2026-02-17 15:19