Author: Denis Avetisyan
New research explores how artificial intelligence can automatically recreate and repair computational analyses in the social sciences, addressing a critical challenge to scientific validity.
A comparative study reveals that AI agents outperform direct prompting of large language models in achieving computational reproducibility.
Despite the expectation that computational research should be easily verifiable through code re-execution, failures due to environmental inconsistencies and logical errors remain prevalent, hindering scientific progress. This study, ‘Automating Computational Reproducibility in Social Science: Comparing Prompt-Based and Agent-Based Approaches’, investigates whether large language models and AI agents can automate the diagnosis and repair of such failures in R-based social science analyses. Results demonstrate that agent-based systems, which autonomously inspect and modify code, substantially outperform prompt-based language models in restoring computational reproducibility, achieving success rates up to 96%. Could these automated workflows fundamentally reshape how computational research is validated and built upon, fostering greater transparency and accelerating discovery?
The Inherent Fallibility of Complex Systems
Contemporary software systems are characterized by an unprecedented scale of complexity, frequently comprising millions of lines of code developed by diverse teams. This inherent intricacy renders errors not merely probable, but virtually guaranteed – a simple oversight in such vast codebases can have cascading effects. The consequences of these errors extend far beyond mere inconvenience; they can translate into significant financial losses, compromised data security, and even endanger human lives in critical applications like medical devices or autonomous vehicles. The increasing reliance on software across all facets of modern life amplifies the potential impact of these vulnerabilities, demanding innovative approaches to ensure reliability and minimize the risk associated with inevitable coding errors.
The process of identifying and rectifying errors in software, traditionally reliant on manual debugging, presents significant challenges in modern development. While meticulous code review and testing are essential, these methods are inherently time-consuming, demanding substantial developer effort to trace the execution path and pinpoint the source of defects. More critically, traditional approaches often struggle to uncover subtle vulnerabilities or edge-case errors that manifest infrequently or under specific conditions. These hidden flaws can remain undetected despite rigorous testing, potentially leading to system failures, security breaches, or unexpected behavior in deployed applications. The increasing complexity of software systems, coupled with shrinking development cycles, exacerbates this problem, making it increasingly difficult to ensure complete code reliability through manual inspection alone.
Automated code repair represents a significant advancement in software engineering, offering the potential to drastically reduce the time and resources dedicated to debugging and maintenance. Rather than relying solely on human developers to identify and fix errors, these systems leverage techniques from artificial intelligence, including machine learning and program synthesis, to automatically detect vulnerabilities and generate corrective patches. This approach not only accelerates the repair process but also promises to uncover subtle bugs that might otherwise remain hidden during manual testing. Current research explores various strategies, from template-based fixes for common errors to more sophisticated methods that learn from vast code repositories and adapt to diverse programming styles. While still an evolving field, automated code repair holds the key to building more robust, secure, and reliable software systems, ultimately decreasing development costs and enhancing user experience.
Navigating the Landscape of AI-Driven Code Correction
Prompt-based code repair utilizes Large Language Models (LLMs) to generate potential fixes based on input describing the error or desired functionality. This approach typically involves providing the LLM with the erroneous code snippet, along with an error message, stack trace, or natural language description of the problem. The LLM then leverages its pre-trained knowledge and generative capabilities to produce code suggestions intended to resolve the issue. The quality of the repair is heavily dependent on the clarity and specificity of the prompt provided, as well as the LLM’s training data and model size. This method excels at addressing syntactical errors and common bugs but may struggle with complex logical errors or those requiring deep understanding of the codebase’s intent.
Agent-based repair systems utilize autonomous AI agents to actively engage with the runtime environment of the code being analyzed. These agents execute the code, observe its behavior-including error messages, stack traces, and program state-and leverage this information to pinpoint the root cause of defects. Unlike prompt-based methods, agent-based repair doesn’t rely solely on static analysis or error descriptions; it dynamically diagnoses issues through execution. The agents then implement repairs, often through automated code transformations, and re-test the modified code to validate the fix. This iterative process of execution, diagnosis, repair, and validation continues until the code operates as expected or a predefined repair limit is reached.
Consistent and reproducible environments are fundamental to the efficacy of both prompt-based and agent-based AI code repair techniques. These environments guarantee that the code being tested and validated is assessed under identical conditions each time, mitigating the impact of external factors such as differing system configurations, library versions, or data states. This repeatability is critical for accurately identifying the root cause of errors and verifying that proposed fixes genuinely resolve the issue without introducing regressions. Reproducibility is often achieved through containerization technologies like Docker, virtual machines, or carefully managed dependency specifications, ensuring that the testing process yields deterministic results and facilitates reliable evaluation of repair suggestions.
Establishing a Rigorous Benchmark for Synthetic Code Repair
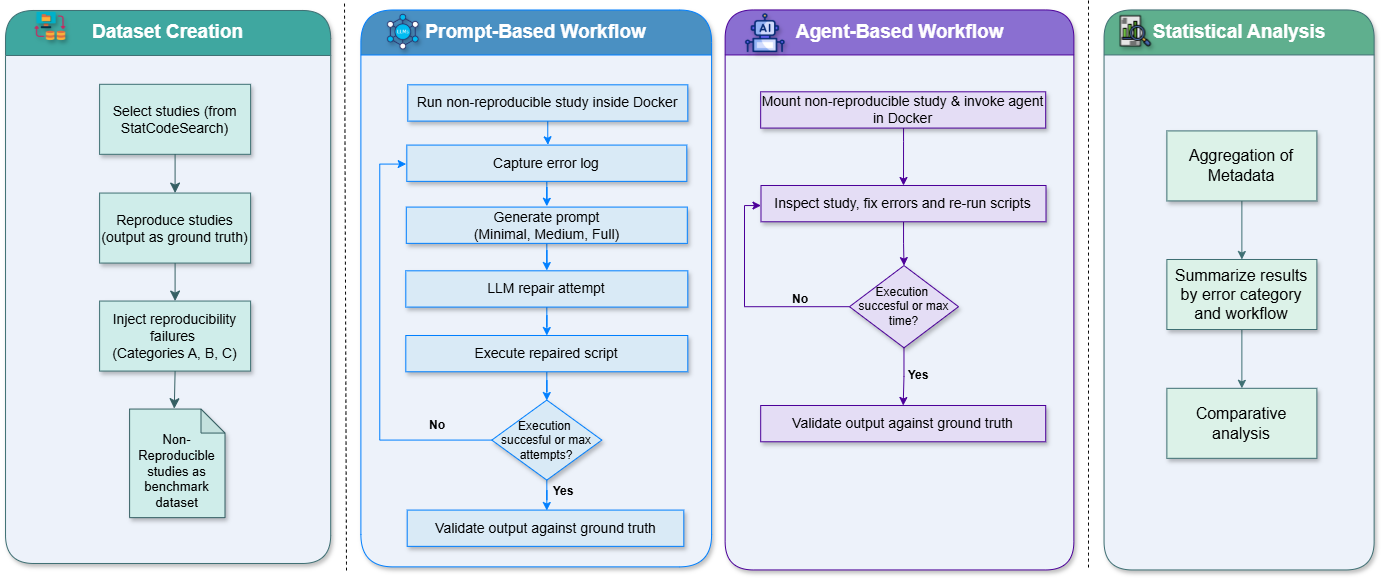
The synthetic benchmark is constructed utilizing the R programming language to facilitate a rigorously controlled evaluation of code repair workflows. This approach allows for precise manipulation of test conditions and repeatable experimentation, isolating the performance of different repair strategies. R was selected for its robust statistical computing capabilities and extensive package ecosystem, enabling the generation of diverse code faults and the quantitative analysis of repair outcomes. The benchmark’s foundation in code, rather than relying on real-world datasets, ensures consistent and predictable failure modes for objective comparison of repair tools and techniques.
The synthetic benchmark utilizes error injection to create a controlled testing environment that mirrors real-world code failure scenarios. This process involves programmatically introducing faults – such as syntax errors, logical errors, and runtime exceptions – into the codebase being evaluated. By systematically injecting these errors, the benchmark can assess the ability of different repair workflows to accurately identify, diagnose, and resolve a diverse range of defects. The quantity, type, and distribution of injected errors are configurable, allowing for targeted evaluation of repair workflows under specific failure conditions and enabling a comprehensive assessment of their robustness and reliability. This approach provides a more rigorous and quantifiable measure of repair performance than relying solely on naturally occurring defects.
Docker containers are utilized to establish a standardized execution environment for the benchmarking process, mitigating inconsistencies arising from differing system configurations and software dependencies. By encapsulating the repair workflow, including all necessary libraries and tools, within a container, the benchmark ensures that results are reproducible regardless of the host operating system or hardware. This containerization strategy isolates the repair process, preventing interference from pre-existing software on the host machine and guaranteeing that each test run is performed under identical conditions. The resulting container images can be easily distributed and deployed, facilitating collaborative research and validation of results across diverse platforms and computing environments.
Validating Trustworthy Results: The Cornerstone of Reliable Code Repair
Rigorous output validation stands as a cornerstone of trustworthy automated code repair, ensuring that any modifications introduced not only compile without error but also demonstrably produce the expected results. This process moves beyond superficial checks, demanding a comparison between the behavior of the original, flawed code and the repaired version against a predefined set of test cases. Successful validation confirms that the repair has addressed the intended issue without introducing regressions or unintended side effects; it is a critical step in establishing confidence in the automated process. Without this crucial verification stage, even syntactically correct repairs could perpetuate errors or introduce new vulnerabilities, ultimately undermining the utility and reliability of the entire system.
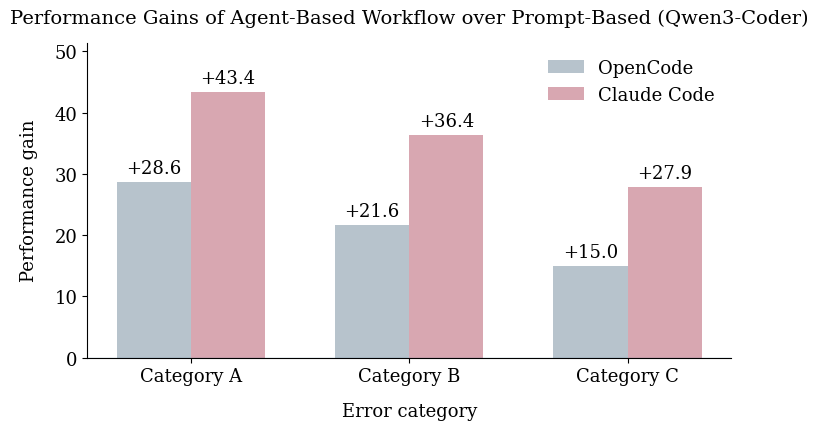
Rigorous statistical analysis formed a crucial component of evaluating automated code repair workflows, moving beyond anecdotal evidence to establish quantifiable performance differences. By employing statistical methods, researchers could objectively compare the success rates of various approaches – such as agent-based systems versus prompt-based large language models – across diverse error categories. This quantitative assessment revealed, for instance, that agent-based workflows consistently outperformed prompt-based methods, exhibiting up to a 27.9% increase in successful repairs for complex Category C errors. Furthermore, detailed statistical reporting, including reproducibility success rates-like the 96.3% achieved by the Claude Code agent for Category A errors versus 81.5% with OpenCode-provided a granular understanding of each workflow’s strengths and weaknesses, facilitating targeted improvements and fostering confidence in the overall findings.
Computational reproducibility is paramount to establishing confidence in scientific findings, and this research underscores its importance through meticulous documentation and open data sharing practices. By comprehensively detailing the experimental setup, code, and datasets used in automated code repair, the study enables independent verification of its results. This commitment to transparency not only facilitates scrutiny and validation by the broader research community, but also allows for the replication of experiments, fostering further innovation and building a foundation of trust in the efficacy of agent-based workflows for complex error correction. Such practices move beyond simply reporting findings to actively demonstrating their reliability, a cornerstone of robust scientific inquiry.
Recent investigations reveal a substantial performance advantage for agent-based workflows when tackling complex code repair challenges. Specifically, these systems, which leverage autonomous agents to navigate and rectify errors, consistently surpassed the efficacy of prompt-based Large Language Models (LLMs). In scenarios involving Category C Errors – those demanding intricate logical reasoning and extensive code modification – agent-based approaches demonstrated up to a 27.9% higher success rate. This improvement suggests that the iterative, exploratory nature of agent workflows allows for more robust error diagnosis and more effective repair strategies compared to the single-step reasoning often employed by prompt-based LLMs, highlighting a promising direction for automated software repair.
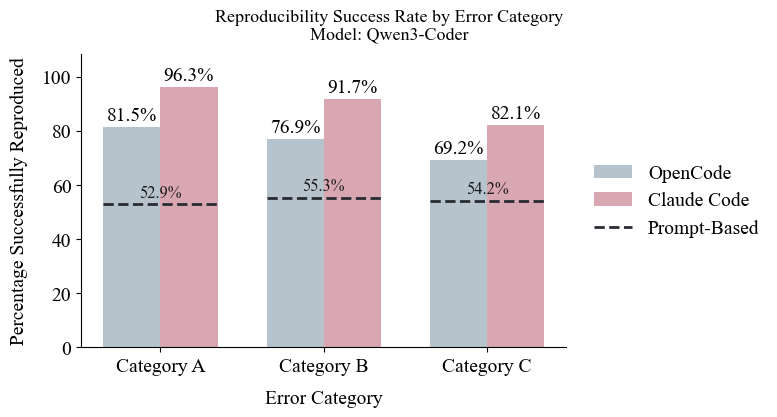
Evaluations revealed substantial differences in the reproducibility of code repairs between leading Large Language Models. The Claude Code agent demonstrated a notably high success rate of 96.3% in consistently reproducing correct repairs for Category A errors – those representing relatively simple fixes. This performance significantly surpassed that of the OpenCode model, which achieved a reproducibility success rate of 81.5% for the same error category. The observed disparity underscores the importance of model architecture and training data in ensuring the reliability of automated code repair systems, particularly when dealing with even straightforward debugging tasks.
Analysis revealed a substantial performance advantage for the Claude Code agent when addressing Category C errors – those representing the most complex repair scenarios. Specifically, the agent achieved a 27.9% higher reproducibility success rate compared to traditional prompt-based large language models. This indicates that the agent-based workflow, with its iterative and structured approach to code repair, is considerably more reliable in resolving intricate bugs. The improvement suggests that simply providing a prompt to an LLM is insufficient for challenging errors, while a system capable of independent reasoning and testing yields demonstrably more trustworthy results, bolstering confidence in automated code repair technologies.
The pursuit of robust and verifiable results is significantly strengthened through the adoption of Open Science principles. This research actively promotes transparency by emphasizing meticulous documentation of workflows, comprehensive data sharing, and a commitment to publicly available code repositories. Such practices not only facilitate independent verification of findings, bolstering confidence in the presented outcomes, but also enable broader collaboration and accelerate future innovation within the field of automated code repair. By prioritizing openness, this work moves beyond isolated success rates to establish a foundation for collective advancement and long-term reliability in software engineering practices.
The pursuit of computational reproducibility, as detailed in this research, echoes a fundamental tenet of elegant code: provability, not merely functionality. This study’s comparison of prompt-based and agent-based approaches reveals a clear preference for the latter’s ability to systematically repair analyses – a process akin to formally verifying an algorithm’s correctness. As Ken Thompson famously stated, “If it feels like magic, you haven’t revealed the invariant.” The agent-based methods, by explicitly outlining their repair strategies, move closer to revealing those underlying invariants, diminishing the ‘magic’ and bolstering confidence in the reproduced results. This aligns perfectly with the core idea that a robust solution isn’t simply one that works on a given test, but one demonstrably correct by its internal logic.
What Lies Ahead?
The demonstrated superiority of agent-based systems over direct prompt engineering, while encouraging, does not resolve the fundamental issue. Reproducibility remains a probabilistic outcome, not a deterministic guarantee. Current approaches excel at repairing code to yield a desired result-a superficial fix, perhaps-but do not address the underlying fragility inherent in much computational social science. The ease with which analyses can be subtly altered to achieve statistical significance demands more than automated patching; it necessitates a shift towards provable, rather than merely ‘working’, code.
A critical limitation lies in the evaluation metrics. Assessing reproducibility by confirming the attainment of a specific output ignores the infinite space of equally valid, yet different, analytical pathways. Future work must move beyond output congruence and focus on algorithmic equivalence-demonstrating that the repaired code implements the originally intended logic, not simply produces a matching number. This requires formal verification techniques, a significant departure from the empirical ‘test and adjust’ paradigm that currently dominates.
The ultimate goal is not to automate the illusion of reproducibility, but to engineer systems that enforce it as a mathematical certainty. Until computational social science embraces a commitment to provability-to algorithms that can be formally proven correct-it will remain, at best, an approximation of a science. The pursuit of elegance, it seems, is often abandoned in favor of expediency.
Original article: https://arxiv.org/pdf/2602.08561.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- Annulus redeem codes and how to use them (April 2026)
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Gear Defenders redeem codes and how to use them (April 2026)
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- Silver Rate Forecast
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Total Football free codes and how to redeem them (March 2026)
- Simon Baker’s ex-wife left ‘shocked and confused’ by rumours he is ‘enjoying a romance’ with Nicole Kidman after being friends with the Hollywood star for 40 years
2026-02-10 18:18