Author: Denis Avetisyan
A new benchmark assesses how well artificial intelligence agents handle realistic software engineering challenges, moving beyond simple code completion.
![The system employs a rigorous execution pipeline wherein each task is encapsulated within a Docker container, enabling the automated launch of agents-be they large language models or oracle baselines equipped with integrated development environment tools-and the comprehensive capture of all interactions, followed by automated grading via test suite execution and precise code change extraction using [latex]git\ diff[/latex] for comparison against a definitive golden solution.](https://arxiv.org/html/2601.20886v1/x1.png)
Researchers introduce IDE-Bench, a comprehensive evaluation suite for AI IDE agents focused on tool-calling and code generation capabilities within real-world software engineering tasks.
Existing benchmarks for large language models often fall short in evaluating their capabilities as practical software engineering collaborators. To address this, we introduce IDE-Bench, a comprehensive framework for rigorously evaluating AI IDE agents on real-world tasks through an IDE-native tool interface. Our benchmark utilizes 80 never-published tasks across C/C++, Java, and MERN stacks to systematically correlate agent-reported intent with successful, project-level code modifications-a crucial step beyond simple code generation. Will this more holistic evaluation reveal the true potential-and limitations-of LLMs in automating complex software development workflows?
The Imperative of Realistic Evaluation in AI-Driven Development
The pursuit of genuinely intelligent AI-powered Integrated Development Environments (IDEs) is currently hampered by a significant limitation in how these systems are evaluated. Existing benchmarks, designed to measure a model’s coding ability, frequently rely on simplified tasks that bear little resemblance to the intricacies of professional software development. These benchmarks often focus on isolated code snippets or narrowly defined problems, neglecting the long-term dependencies, complex architectures, and nuanced requirements characteristic of real-world projects. Consequently, models that perform well on these benchmarks may still struggle with the sustained reasoning, debugging, and collaborative aspects of building and maintaining substantial software systems. This discrepancy between benchmark performance and real-world capability creates a misleading impression of progress and underscores the urgent need for more robust and representative evaluation metrics that accurately reflect the challenges of realistic software engineering.
Contemporary code generation methods frequently falter when confronted with tasks demanding extended, multi-step reasoning within a complex codebase. Unlike benchmarks focused on isolated code snippets, real-world software development necessitates maintaining context across numerous files, understanding intricate dependencies, and adapting to evolving requirements over extended periods. These ‘long-horizon’ tasks – such as refactoring a large system, debugging a subtle error across multiple modules, or implementing a feature requiring coordination with existing components – present a significant challenge. Current approaches often exhibit a decline in performance as the task duration increases, struggling with the cumulative effects of errors and the need for sustained, accurate reasoning. This limitation underscores the need for new techniques capable of not only generating syntactically correct code but also of managing the cognitive load inherent in navigating and modifying substantial, interconnected software projects.
IDE-Bench: A Framework for Comprehensive Assessment
IDE-Bench is designed as a holistic evaluation framework for AI-powered IDE agents, moving beyond isolated code snippets to assess performance on complete software engineering projects. The benchmark centers on tasks representative of full-stack web development, requiring agents to demonstrate proficiency across front-end, back-end, and database interactions. A key characteristic of IDE-Bench is its emphasis on “long-horizon reasoning,” meaning agents must maintain context and plan multi-step solutions over extended coding sessions – not just generate immediate code completions. This necessitates the ability to manage dependencies, track variable states, and address issues that arise during the development of a substantial application, mirroring real-world software engineering workflows.
IDE-Bench’s evaluation methodology moves beyond assessing basic code completion capabilities by focusing on more complex software engineering tasks. Specifically, agents are evaluated on their ability to perform debugging – identifying and resolving errors within existing codebases – as well as feature development, requiring the implementation of new functionalities. The benchmark also includes code refactoring tasks, which assess an agent’s capacity to improve code quality and maintainability without altering its external behavior. These assessments are designed to provide a more holistic understanding of an AI agent’s practical coding skills in realistic development scenarios.
IDE-Bench specifically evaluates AI agents’ capacity to utilize external tools as part of the software development process. This assessment goes beyond core coding abilities by measuring how effectively an agent can identify when a tool is needed – such as a debugger, linter, or testing framework – and then correctly integrate that tool into its workflow. The benchmark tracks both the successful execution of tool calls and the agent’s ability to interpret and utilize the resulting output to inform subsequent coding actions, quantifying the benefits of augmented coding through external resources. This tool-calling evaluation is a core component of IDE-Bench, differentiating it from benchmarks focused solely on code generation or completion.
![Task-level success rates demonstrate the performance of a cross-lingual document translator built with a [latex]MERN[/latex] stack (MongoDB, Express, React, and Node.js) across different translation tasks.](https://arxiv.org/html/2601.20886v1/x17.png)
Fundamental Capacities of Autonomous AI IDE Agents
Effective autonomous AI agents operating within a software development environment necessitate a robust understanding of codebase context to facilitate navigation and informed decision-making. This contextual awareness extends beyond simple syntactic parsing; agents must comprehend semantic relationships between code elements, including variable scopes, function dependencies, and the overall architectural design of the project. Successful agents utilize techniques like Abstract Syntax Tree (AST) analysis, control flow analysis, and data flow analysis to build a comprehensive internal representation of the codebase. This representation enables the agent to accurately identify relevant code sections, predict the impact of proposed changes, and generate code that integrates seamlessly with existing functionality, ultimately improving development velocity and code quality.
Efficient codebase search within Autonomous AI IDE Agents relies on indexing and retrieval algorithms to identify relevant code segments based on semantic understanding and contextual relevance. These agents utilize techniques such as keyword matching, abstract syntax tree analysis, and vector embeddings to locate code snippets, function definitions, and dependencies with minimal latency. The speed of this search directly impacts development velocity, enabling rapid prototyping, bug fixing, and feature implementation. Agents capable of quickly pinpointing the required code elements significantly reduce the time spent manually navigating large projects and understanding complex relationships between different code modules, thereby accelerating overall development workflows.
Modern application development frequently requires integration with external services and APIs, and autonomous AI IDE agents must effectively leverage these interactions to function as complete development tools. Specifically, technologies like the MERN stack – MongoDB, Express.js, React, and Node.js – commonly rely on APIs for database access, backend logic, and front-end data retrieval. An agent’s ability to construct, execute, and interpret API calls – including handling authentication, request formatting, and response parsing – is therefore critical for tasks such as data fetching, service integration, and building connected applications. Without this capability, the agent is limited to static code manipulation and cannot dynamically interact with the broader software ecosystem.
A well-defined system prompt is fundamental to the operation of an autonomous AI IDE agent, serving as the primary method for establishing behavioral boundaries and directing output. This prompt, a natural language instruction set, communicates the agent’s role, acceptable actions, and desired output format. Consistent and unambiguous prompting is critical; variations in phrasing can lead to unpredictable results and diminished performance. Effective system prompts specify constraints, such as permitted programming languages, coding style guidelines, or the scope of acceptable modifications, thereby ensuring the agent operates within predefined parameters and delivers consistently structured and reliable code contributions. The prompt also defines the agent’s persona – for example, specifying it should act as a “senior software engineer” or a “security auditor” – further refining its behavior.
Validation of IDE-Bench with Advanced Language Models
IDE-Bench utilizes large language models, specifically GPT-5.2 and Claude Sonnet, as the core evaluation engine for assessing AI IDE agent performance. These models are employed across a spectrum of software engineering tasks, including code generation, bug fixing, and code completion. The benchmark’s design enables a quantitative measurement of an agent’s capabilities by submitting code generated or modified by the agent to the language model for validation; the model then determines if the agent’s output meets the task requirements. This approach allows for standardized and reproducible evaluation, facilitating comparisons between different AI IDE agents and tracking improvements in their performance over time.
IDE-Bench distinguishes itself from prior benchmarks by incorporating direct file editing capabilities within a simulated IDE environment. This functionality allows AI agents to not only propose code changes but to actively modify files, compile, and test their solutions. The benchmark provides agents with programmatic access to standard IDE features, including file creation, deletion, and modification, enabling a more comprehensive evaluation of coding skills beyond simple code completion or generation. This direct manipulation of code is crucial for assessing an agent’s ability to perform complete software engineering tasks, such as bug fixing, feature implementation, and refactoring, within a realistic development workflow.
IDE-Bench utilizes Test-Driven Development (TDD) by requiring agents to first pass provided unit tests before submitting code. Each task within the benchmark includes a suite of tests that define the expected functionality and behavior of the solution. Agents are evaluated on their ability to generate code that successfully passes these tests, ensuring adherence to specific requirements and promoting the creation of reliable code. The benchmark’s structure incentivizes agents to prioritize correctness and functionality as defined by the tests, providing a measurable metric for code quality and reducing the likelihood of submitting incomplete or erroneous solutions.
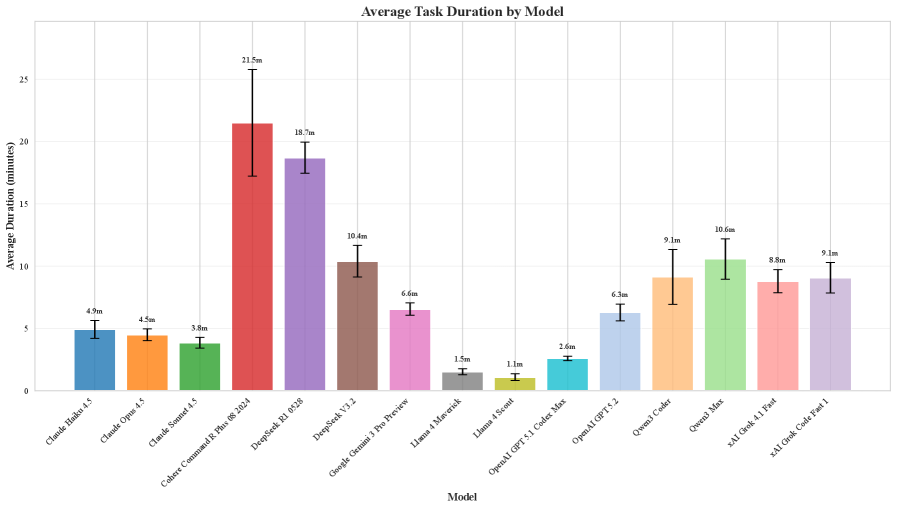
Current leading language models, when evaluated using the IDE-Bench benchmark on real-world software engineering tasks, achieve a pass@5 rate ranging from 83% to 95%. The pass@5 metric indicates the percentage of tasks for which the model successfully generates a correct solution within five attempts. This performance level suggests a substantial capability in automated code generation and problem-solving within a realistic software development context, indicating progress towards practical application in AI-assisted programming tools. The benchmark tasks are designed to mirror common software engineering challenges, providing a representative assessment of model proficiency.
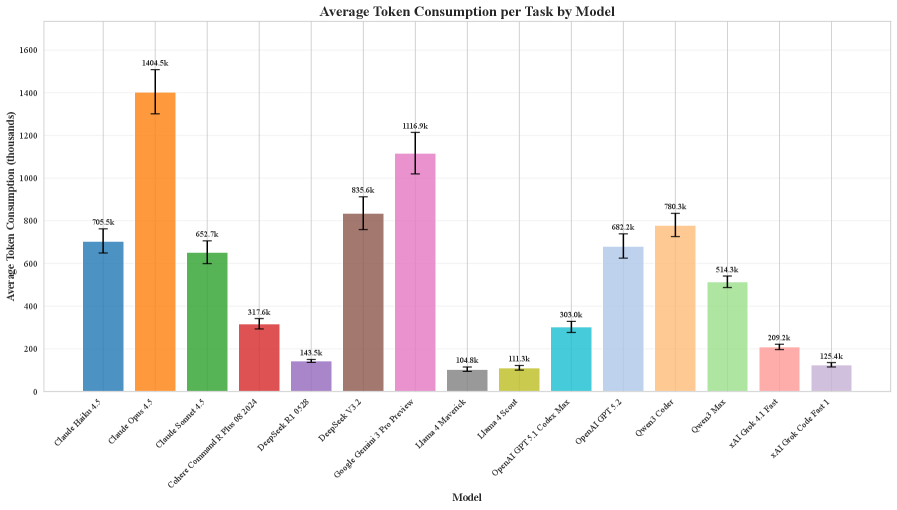
![GPT-5.2 and Claude Haiku demonstrate superior token efficiency, achieving high task success rates [latex]pass@5[/latex] with minimal token consumption, positioning them in the optimal upper-left quadrant of the analysis.](https://arxiv.org/html/2601.20886v1/x9.png)
The Future Trajectory of AI-Powered Software Engineering
The rapidly evolving landscape of artificial intelligence demands robust evaluation tools, and IDE-Bench rises to this challenge by offering a standardized framework for assessing AI-powered software engineering agents. This benchmark isn’t merely a collection of tasks; it’s a meticulously designed system built to rigorously test an agent’s capabilities across the full software development lifecycle, from initial problem understanding to code implementation and debugging. By providing a common ground for researchers and developers, IDE-Bench facilitates meaningful comparisons between different AI approaches, accelerates innovation, and fosters collaborative progress in the field. The framework’s emphasis on rigorous evaluation ensures that advancements are not simply incremental improvements, but represent genuine leaps towards truly intelligent and capable AI assistants for software engineers, ultimately driving both productivity and software quality higher.
Current evaluations of AI-powered software engineering tools often fall short, lacking the complexity and realism to truly gauge an agent’s capabilities. IDE-Bench directly confronts these shortcomings by introducing a benchmark suite built around authentic software engineering tasks – not simplified proxies – and a rigorous evaluation framework. This allows researchers to move beyond superficial performance metrics and assess an AI’s ability to navigate the nuanced challenges of real-world development, including code understanding, bug fixing, and feature implementation. By providing a standardized and challenging platform, IDE-Bench isn’t simply measuring existing AI; it’s actively shaping the trajectory of the field, encouraging the creation of agents capable of genuine intelligence and practical utility within the software development lifecycle. The result promises a future where AI meaningfully assists, and even augments, the work of human programmers.
Rigorous evaluation using benchmarks like IDE-Bench is poised to dramatically reshape software development practices. By pinpointing the strengths and weaknesses of AI agents across diverse coding tasks, developers can strategically integrate these tools to augment human capabilities, rather than simply automating existing processes. This focused approach promises a significant boost in developer productivity, allowing engineers to concentrate on higher-level design and problem-solving. Furthermore, consistent evaluation facilitates the creation of more reliable and robust AI-assisted tools, ultimately leading to a demonstrable improvement in software quality through reduced errors and enhanced code maintainability. The data derived from such benchmarks isn’t merely academic; it’s a catalyst for building practical AI solutions that genuinely accelerate and refine the entire software lifecycle.
Recent evaluations using the IDE-Bench framework demonstrate a marked specialization among AI models designed for software engineering tasks. Analysis of model behavior, quantified through Read-to-Edit ratios – measuring the amount of code read versus code modified – reveals considerable variation, ranging from 1.70 to 5.29. This suggests that different models adopt distinctly different strategies for problem-solving; those with lower ratios tend towards more focused editing, while those with higher ratios exhibit greater exploration of the codebase before committing to changes. The observed divergence highlights a critical aspect of AI agent design – the trade-off between exploiting known solutions and exploring potential alternatives – and underscores the need for tailored approaches to optimize performance across specific software engineering challenges. These findings contribute to a deeper understanding of how AI agents ‘think’ when coding, paving the way for more efficient and effective AI-assisted software development tools.
The pursuit of robust IDE agents, as detailed in this paper, necessitates a focus on provable correctness, not merely functional outcomes. Donald Davies observed, “The only thing that matters is that it works.” However, ‘working’ in the context of software engineering demands more than passing tests; it requires a transparent, verifiable foundation. IDE-Bench rightly addresses this by emphasizing tool-calling and code generation capabilities, pushing beyond superficial benchmarks to evaluate agents on genuinely complex, real-world tasks. The benchmark’s rigorous approach seeks to reveal invariants-the underlying truths that guarantee a solution’s reliability-rather than accepting solutions that feel like magic due to opaque inner workings.
What’s Next?
The introduction of IDE-Bench represents a necessary, if belated, insistence on analytical rigor. Too often, assessments of these ‘intelligent’ agents devolve into demonstrations of superficial functionality – a program that appears to work on curated examples is not, in itself, proof of a sound underlying principle. The benchmark’s emphasis on tool-calling, while pragmatic, merely scratches the surface of the true challenge: formalizing the semantics of software development itself. One suspects the limitations will not lie in the models’ capacity for syntactic manipulation, but in the difficulty of representing intent with sufficient precision to allow for automated verification.
Future work must move beyond merely measuring performance on tasks and begin to investigate provability. A system that can generate code and demonstrably prove its correctness – even for limited domains – is qualitatively different from one that simply passes a set of tests. The current evaluation landscape rewards expediency; true progress demands a shift toward formal methods and a willingness to embrace the inherent complexity of software engineering. Optimization without analysis remains self-deception, a trap for the unwary engineer, and its allure will likely persist.
Ultimately, the value of benchmarks such as IDE-Bench lies not in their ability to crown a ‘winner’, but in their capacity to expose the fundamental gaps in our understanding. The pursuit of genuinely intelligent IDE agents is, at its core, a quest to formalize not just programming, but thought itself – a task of formidable, and perhaps insurmountable, difficulty.
Original article: https://arxiv.org/pdf/2601.20886.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Limbus Company 2026 Roadmap Revealed
- EMEA Masters Winter 2026 introduces official Qualifier for Esports World Cup
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Total Football free codes and how to redeem them (March 2026)
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
2026-02-02 03:28