Author: Denis Avetisyan
This review examines the potential of artificial intelligence systems to automatically adapt and improve datasets used in software engineering tasks.
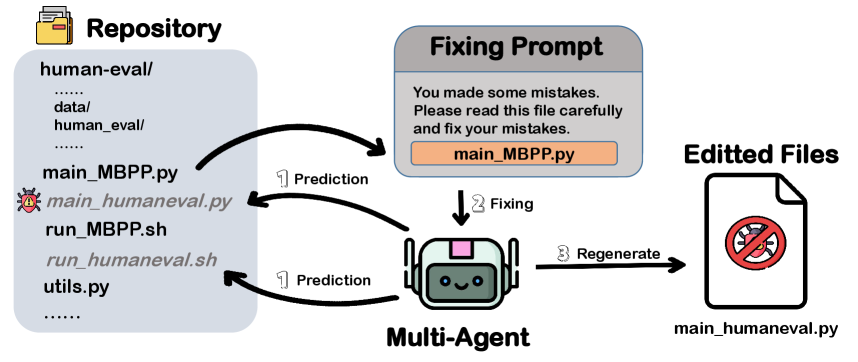
A critical analysis of multi-agent systems-and their limitations-in automating dataset adaptation for improved code generation and software maintenance.
Despite growing demands for reproducible research in software engineering, adapting existing artifacts to new datasets remains a largely manual and challenging process. This paper, ‘Multi-Agent Systems for Dataset Adaptation in Software Engineering: Capabilities, Limitations, and Future Directions’, presents the first empirical evaluation of state-of-the-art, large language model-based multi-agent systems-specifically, those leveraging GPT-4.1 and Claude Sonnet-for automating this crucial adaptation task. Our findings reveal that while current systems can identify relevant files and generate partial adaptations, achieving fully functional implementations proves difficult without human guidance, though targeted prompt interventions-such as providing execution error messages-significantly improve performance. What architectural and training strategies will be necessary to build truly self-correcting agents capable of reliable, automated dataset adaptation in software engineering research?
The Evolving Landscape of Automated Software Creation
Software creation has historically been a process characterized by distinct, linear stages – requirements gathering, design, implementation, testing, and deployment – each demanding considerable human attention and effort. This sequential nature often introduces bottlenecks, as developers move from one task to the next, frequently requiring context switching and manual intervention to address dependencies or resolve issues. The reliance on manual processes extends to even seemingly simple tasks, like code refactoring, bug fixing, or documentation updates, which consume valuable time and resources. Consequently, the software development lifecycle is often protracted and expensive, hindering innovation and responsiveness to evolving user needs. This inherent inefficiency motivates the exploration of automated solutions capable of streamlining these traditionally manual, sequential workflows.
The emergence of sophisticated Large Language Models (LLMs) is reshaping the landscape of software engineering by enabling the creation of intelligent agents capable of automating traditionally manual tasks. These agents, powered by models trained on vast datasets of code and natural language, can now perform functions ranging from code generation and debugging to test case creation and documentation. Rather than simply responding to prompts, these LLM-based agents can reason about software requirements, decompose complex problems into manageable steps, and even proactively identify and address potential issues. This shift signifies a move towards more autonomous software development, promising increased efficiency and potentially unlocking new levels of innovation by freeing developers from repetitive and time-consuming work. The potential extends beyond simple automation, hinting at systems capable of learning and adapting to evolving project needs, ultimately accelerating the entire software development lifecycle.
The integration of Large Language Model (LLM) agents into software engineering workflows promises a significant leap in developer productivity and a faster pace for the entire software development lifecycle. These agents aren’t merely code completion tools; they demonstrate an ability to autonomously handle complex tasks, from generating code from natural language specifications to identifying and resolving bugs, and even automating testing procedures. This capability frees developers from repetitive and time-consuming duties, allowing them to focus on higher-level design, innovation, and problem-solving. Early implementations suggest a potential for substantial reductions in development time and costs, as agents can operate continuously and at scale, effectively augmenting the capabilities of human engineers and streamlining the traditionally sequential stages of software creation. The result is a more agile and efficient development process, capable of rapidly responding to evolving requirements and delivering software solutions with increased speed and reliability.
Determining the true potential of LLM agents in software engineering demands more than anecdotal evidence; rigorous experimentation and systematic analysis are crucial. Researchers are actively developing benchmarks and evaluation frameworks to assess agent performance across diverse coding tasks, including bug fixing, code generation, and documentation. These evaluations aren’t simply about whether an agent produces code, but whether that code is correct, efficient, secure, and maintainable. Furthermore, understanding the limitations of these agents – identifying scenarios where they struggle or produce incorrect results – is equally important. This involves analyzing error patterns, probing their reasoning processes, and establishing clear metrics for quantifying their capabilities, ultimately paving the way for reliable and trustworthy AI-assisted software development.
Mapping Tasks to Artifacts: A Formalized Experimental Framework
The Mapping Function is a formalized process designed to convert high-level software engineering tasks – such as code review, bug fixing, or feature implementation – into concrete, executable experiments. This translation involves defining specific inputs, expected outputs, and evaluation metrics for each task. The function operates by identifying the necessary resources – datasets, tools, and environments – to perform the task in a controlled and reproducible manner. Crucially, the Mapping Function provides a standardized interface between task definition and experimental execution, enabling automated evaluation of agent performance across a range of software engineering challenges. The output of this function is a set of experimental configurations ready for execution and analysis.
The Mapping Function utilizes the Research Data Repository – Development (RDR_D) and the Research Test Repository – Tools (RTR_T) to establish a direct correlation between defined software engineering tasks and the resources required for their execution. RDR_D provides access to datasets relevant to specific tasks, while RTR_T catalogues available technologies and tools. This connection is achieved by referencing unique identifiers within both repositories, enabling the function to automatically select and provision the appropriate datasets and technologies necessary to perform a given task, thereby facilitating automated experimentation and reproducibility.
ROCODE, a Python-based artifact, functions as the primary test case for evaluating agent performance within the experimental framework. This artifact provides a concrete implementation against which different agent configurations can be benchmarked and compared. Its selection is predicated on its suitability for automated testing and its ability to represent a realistic, albeit simplified, software engineering task. The Python implementation facilitates integration with existing testing infrastructure and allows for rapid iteration on agent designs. Performance metrics derived from ROCODE execution provide quantifiable data for assessing agent effectiveness in addressing the defined software engineering challenge.
The implemented mapping function facilitates systematic evaluation of agent configurations by providing a standardized process for executing experiments and collecting performance data. Each agent configuration is subjected to the same set of tasks, as defined by the mapping to datasets within repositories like RDR_D and RTR_T, ensuring a controlled comparison. Quantitative metrics, derived from the execution of the ROCODE artifact, are then recorded for each configuration, enabling objective assessment and identification of optimal parameters. This approach allows for statistically significant comparisons, mitigating the impact of random variation and providing reliable insights into agent performance characteristics.
Evaluating State-of-the-Art Agents and GitHub Copilot
The evaluation of State-of-the-Art (SOTA) agents was conducted using a specifically designed experimental framework to address research question RQ1, which concerns the capabilities of these agents in automated dataset adaptation. This benchmarking process involved subjecting multiple SOTA agents to a standardized series of tasks and assessing their performance against pre-defined metrics. The framework facilitated a controlled comparison, allowing for quantitative analysis of each agent’s strengths and weaknesses in relation to the target adaptation problem. Data collected during the benchmarking process forms the basis for the subsequent analysis presented in this study, enabling a rigorous evaluation of current agent capabilities.
GitHub Copilot was incorporated into the evaluation as a prominent example of a Large Language Model (LLM)-based agent to provide a benchmark against which to measure the performance of other agents within the experimental framework. Its inclusion allowed for assessment of current LLM capabilities in practical software development tasks, specifically focusing on its ability to interact with and modify code repositories. Copilot’s operational characteristics, including its reliance on tool use for repository interaction and file editing, were considered during the evaluation process to determine its efficacy compared to other agents and human performance benchmarks.
GitHub Copilot’s functionality extends beyond code suggestion through its integration with tools designed for software development workflows. Specifically, Copilot leverages the MCP Tools suite to directly interact with code repositories, enabling actions such as cloning, branching, and committing changes. This capability facilitates file editing and modification within the repository, allowing Copilot to not only propose code snippets but also to implement them directly into a project. The use of MCP Tools demonstrates Copilot’s capacity for practical application beyond simple code completion, positioning it as an agent capable of automating portions of the software development lifecycle.
Evaluation of current Large Language Model (LLM)-based multi-agent systems revealed limited success in achieving functional equivalence to established methods for dataset adaptation tasks. Specifically, across a range of tested artifacts designed to assess adaptation capability, only one instance of successful adaptation was observed. This suggests a significant performance gap between these systems and current real-world implementations, indicating that LLM-based agents currently lack the robustness and reliability required for autonomous dataset adaptation in practical scenarios.
The Impact of Prompting on Agent Performance
The study systematically examined how alterations to prompts-the initial instructions given to language model agents-affected their overall performance. Researchers focused on prompt-level interventions, meaning they directly modified the wording and structure of these instructions to observe the resulting changes in agent behavior and output quality. This investigation directly addressed research question RQ2, aiming to determine the degree to which carefully designed prompts could steer agents towards more accurate, efficient, and desired outcomes. By manipulating prompt characteristics, the research sought to establish a clear relationship between input instruction and agent performance, providing insights into the crucial role of prompt engineering in maximizing the potential of these AI systems.
The efficacy of large language models (LLMs) is inextricably linked to the quality of the instructions they receive, highlighting the critical role of prompt engineering. Rather than solely relying on model size or training data, carefully constructed prompts serve as a precise steering mechanism, guiding LLMs toward desired outputs and substantially improving task completion rates. This process involves more than simply phrasing a request; it necessitates a nuanced understanding of how LLMs interpret language, including strategic keyword usage, contextual framing, and the inclusion of few-shot examples. Through deliberate prompt design, even relatively simple LLMs can achieve surprisingly complex tasks, demonstrating that thoughtful instruction can often outperform sheer computational power in achieving optimal results. Consequently, prompt engineering has emerged not merely as a technique, but as a foundational skill for effectively harnessing the potential of LLMs across diverse applications.
The study delved into methods for fostering effective collaboration between multiple agents, recognizing that complex tasks often demand a division of labor and shared knowledge. Researchers explored various agent coordination techniques, focusing on establishing clear communication protocols and shared understanding of goals. This involved designing mechanisms for agents to exchange information, negotiate task assignments, and resolve conflicts, ultimately aiming to create a synergistic effect where the collective performance exceeded that of individual agents working in isolation. The investigation highlighted the importance of not just what information is shared, but how it is presented and interpreted, revealing that structured communication and well-defined roles are critical for achieving seamless cooperation and maximizing overall system efficiency.
Research indicates that strategic prompt design exerts a substantial influence on the quality of generated code, particularly in multi-agent systems. A study focusing on code similarity revealed a dramatic improvement following prompt-level interventions; baseline JPlag similarity measurements registered at just 7.25%, but carefully crafted prompts propelled this figure to 67.14%. This represents a nearly tenfold increase, suggesting that precise instructions and contextual cues within prompts are critical for fostering consistency and reducing redundancy in code produced by large language models. The findings highlight the potential for optimizing agent performance not through algorithmic changes, but through refinements in how tasks are communicated, ultimately leading to more coherent and reliable outputs.
Validating Code Similarity and Ensuring Quality
To rigorously assess the originality and quality of solutions produced by multiple language model agents, a detailed analysis of code similarity was conducted using JPlag. This tool functions by breaking down code into a sequence of tokens – keywords, identifiers, operators, and literals – and then comparing these token sequences across different submissions. By focusing on the structural similarities rather than simply lexical matches, JPlag effectively identifies instances of code duplication or near-identical solutions, even when superficial changes like variable names or whitespace have been introduced. This token-based approach provides a robust metric for determining whether agents are independently generating solutions or merely replicating existing code, thus ensuring the validity and trustworthiness of the automated software engineering process.
Determining the originality and quality of code generated by artificial intelligence agents requires careful scrutiny for potential duplication or plagiarism. Automated analysis tools compare the structural similarities between different code submissions, identifying instances where solutions share significant portions of their underlying logic. This process isn’t simply about detecting exact matches; it extends to recognizing paraphrased or rearranged code segments that represent derivative work. Such assessments are vital for ensuring the integrity of automated software engineering and for validating that the agents are truly generating novel, effective solutions rather than reproducing existing codebases. Ultimately, this focus on originality reinforces trust in the reliability and innovation of agent-driven software development.
Large language model (LLM) agents demonstrate a crucial ability to adapt to varied datasets, fundamentally broadening the scope of automated software engineering. Traditionally, automated techniques required meticulously curated and standardized inputs; however, these agents can effectively generalize from limited examples and apply their knowledge to novel, differently formatted datasets without extensive retraining. This adaptability stems from their pre-training on massive code corpora and their capacity for in-context learning, allowing them to infer the underlying structure and requirements of a new task even with incomplete or unconventional data. Consequently, the application of automated software engineering principles-such as code generation, testing, and debugging-is no longer constrained by the need for perfectly prepared datasets, paving the way for more flexible and robust software development workflows.
Investigations are now shifting toward applying these agent-based systems to increasingly intricate software engineering challenges, moving beyond the initial scope of simpler tasks. A crucial aspect of this ongoing research centers on evaluating scalability – determining how effectively these systems maintain performance and quality as the complexity of projects and the number of participating agents increase. This includes assessing the computational resources required, identifying potential bottlenecks, and refining the agent interactions to optimize efficiency. Ultimately, the goal is to demonstrate the feasibility of deploying these autonomous systems in real-world software development environments, capable of handling large-scale projects and contributing to substantial improvements in productivity and code quality.
The exploration of multi-agent systems in dataset adaptation, as detailed in the paper, highlights a critical need for systemic understanding. It’s not simply about improving individual agents or prompt engineering techniques; the entire architecture dictates the system’s capacity for true adaptation. This resonates with Donald Davies’ assertion that “the key is not to try to solve everything at once, but to create a system that can evolve.” The study demonstrates current limitations in achieving full automation, but points towards the potential of human-guided interventions – a process akin to carefully guiding the evolution of infrastructure without wholesale rebuilding, allowing the system to learn and refine its capabilities over time. This mirrors Davies’ philosophy of organic system growth.
What Lies Ahead?
The exploration of multi-agent systems applied to dataset adaptation reveals a familiar pattern: automation, even when powered by large language models, rarely achieves complete autonomy. The current limitations aren’t simply about scaling computational resources or refining prompt engineering; rather, they expose a fundamental tension between the rigidity of data structures and the nuanced, context-dependent nature of software engineering tasks. Modifying one component of a dataset, even with intelligent agents, triggers a cascade of implications throughout the entire system, often requiring a holistic understanding that current architectures lack.
Future work must move beyond isolated problem-solving and focus on the architecture of these systems themselves. The promise doesn’t lie in creating agents that replace human oversight, but in developing systems that amplify human intuition. Effective dataset adaptation necessitates a feedback loop, where agents propose changes, humans validate their relevance within the broader software context, and the system learns from these interactions.
Ultimately, the field’s progression hinges on recognizing that dataset adaptation isn’t merely a technical challenge; it’s a socio-technical one. Elegant solutions won’t emerge from increasingly complex algorithms, but from simpler, more transparent systems that acknowledge the essential role of human judgment in maintaining software integrity. The objective should be a symbiotic partnership, not a quest for complete automation-a lesson frequently rediscovered in the history of engineering.
Original article: https://arxiv.org/pdf/2511.21380.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- World Eternal Online promo codes and how to use them (September 2025)
- How to find the Roaming Oak Tree in Heartopia
- Clash Royale Season 79 “Fire and Ice” January 2026 Update and Balance Changes
- Clash Royale Furnace Evolution best decks guide
- Best Arena 9 Decks in Clast Royale
- Best Hero Card Decks in Clash Royale
- FC Mobile 26: EA opens voting for its official Team of the Year (TOTY)
2025-11-28 08:24