Author: Denis Avetisyan
A new approach leverages discriminator guidance to unlock compositional learning in diffusion models, improving sample quality and expanding creative potential.
![Latent components extracted from paired images are recombined-allowing for the selective transfer of appearance and scene characteristics-and then decoded via a diffusion process to generate novel imagery, a technique refined through adversarial training where the system learns to create convincingly merged visuals that challenge a discriminator’s ability to identify their hybrid origin-a process described by [latex] z \tilde{z} [/latex] representing the recombined latent code.](https://arxiv.org/html/2601.22057v1/figs/combined_illustration.png)
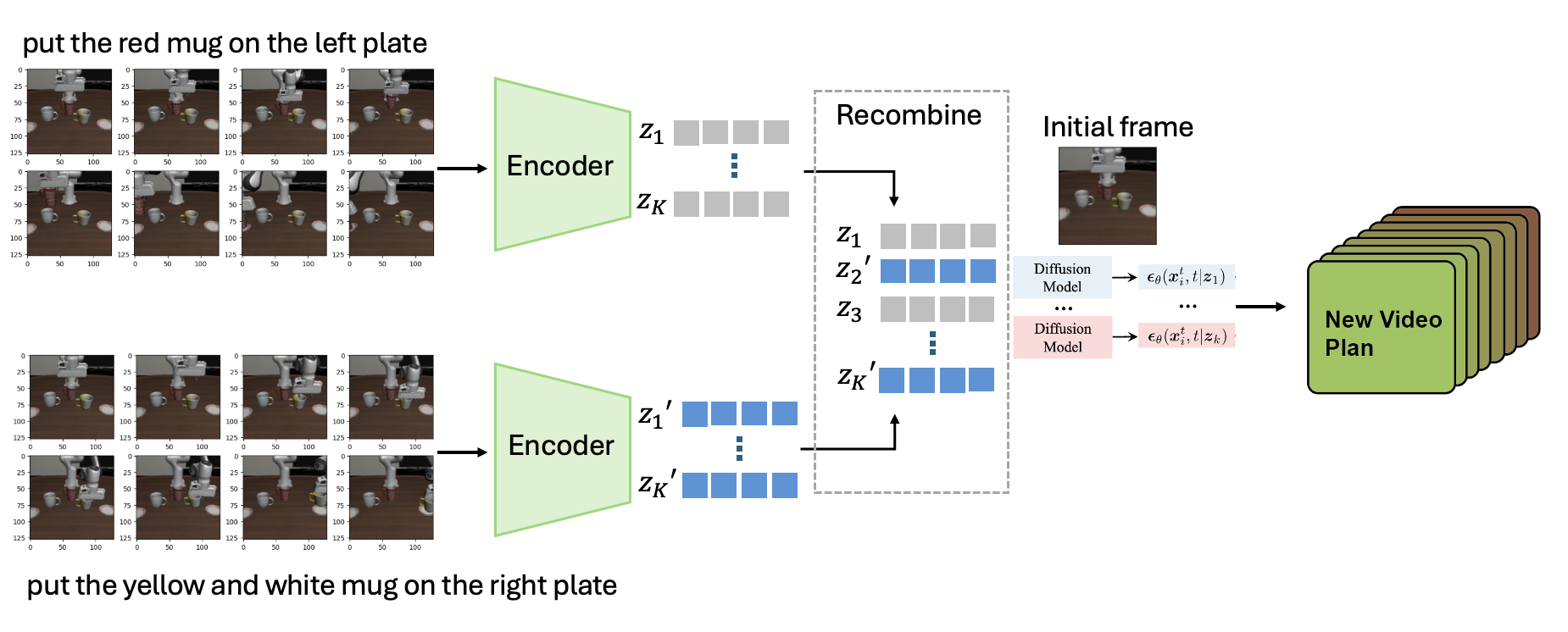
This work introduces a discriminator-driven framework for unsupervised decomposition and recombination within diffusion models, enhancing both image generation and robotic video planning capabilities.
Learning disentangled representations from complex data remains a challenge, hindering compositional generalization and sample diversity. This is addressed in ‘Unsupervised Decomposition and Recombination with Discriminator-Driven Diffusion Models’, which introduces an adversarial training framework to enhance factor discovery and recombination within diffusion models. By optimizing a generator to fool a discriminator trained to distinguish between single-source and recombined samples, the approach promotes physically and semantically consistent compositions, yielding improved performance on image and robotic datasets. Could this discriminator-driven approach unlock more efficient exploration strategies and robust generalization capabilities for diffusion-based systems operating in complex, real-world environments?
Untangling the Chaos: The Limits of Pixel-Based Generation
Generative models, while increasingly sophisticated, frequently falter when tasked with creating truly complex and coherent data, such as realistic simulations of robotic activity. This limitation stems from their difficulty in discerning and representing the underlying factors of variation that govern the data’s structure. Instead of learning the fundamental principles – like object pose, lighting conditions, or material properties – these models often memorize superficial patterns. Consequently, they struggle to generalize to novel situations or produce outputs that maintain physical plausibility and visual consistency. A robotic video, for instance, isn’t simply a sequence of pixels; it’s a complex interplay of articulated motion, environmental interaction, and visual appearance, all governed by underlying physical laws that traditional models often fail to adequately capture, leading to outputs that appear fragmented or unnatural.
The pursuit of increasingly realistic and controllable data generation reveals a fundamental limitation of simply scaling up existing models. While larger models can memorize more training examples, they often fail to grasp the underlying generative principles that define complex data. True progress demands a shift toward explicitly modeling compositionality – the ability to represent data as an arrangement of independent, reusable parts. This approach allows for a disentangled representation where factors like object identity, pose, and lighting are individually controlled, enabling the recombination of learned features into novel, coherent outputs. By understanding how data is built from these fundamental components, researchers can move beyond mere imitation and unlock a level of creative generation and adaptation previously unattainable, ultimately leading to more robust and versatile AI systems.
Many contemporary generative models excel at mimicking training data, but struggle with true creative synthesis because learned features remain largely isolated and inflexible. These systems often treat data elements as monolithic blocks, failing to understand – and therefore reproduce – the underlying rules governing how those elements combine to form novel instances. Consequently, adapting to unseen scenarios or generating variations beyond the training distribution proves difficult; a model might learn to depict a ‘red cube’ and a ‘blue sphere’, but lack the capacity to reliably combine these into a ‘blue cube’ or seamlessly integrate them into a complex scene with varying lighting and perspectives. This limitation in compositional recombination restricts not only the diversity of generated outputs but also the model’s ability to generalize and perform robustly in real-world applications requiring flexible data manipulation.

Dissecting Reality: Learning Independent Latent Components
DecompDiffusion and FactorizedLatentDiffusion employ techniques to learn latent representations that aim for factor independence. Traditional latent spaces often exhibit correlations between dimensions, hindering precise control over generated content. These methods address this by structuring the latent space such that each dimension corresponds to a distinct and statistically independent feature of the input data. This factorization is achieved through modifications to the diffusion process and/or the latent space architecture, encouraging each latent component to capture a single underlying aspect of the data and minimizing redundancy. The goal is to enable manipulation of individual latent dimensions without unintentionally affecting other characteristics of the generated output.
DecompDiffusion and FactorizedLatentDiffusion leverage the established framework of Diffusion Models to achieve enhanced generative performance. These methods improve upon standard Diffusion Models by introducing factorization techniques within the latent space. This factorization decomposes the complex data distribution into multiple independent factors, allowing for more precise control over the generative process and ultimately leading to higher quality samples. By operating on a factorized latent space, these approaches mitigate issues common in standard Diffusion Models, such as mode collapse and limited control over generated attributes.
Disentangled latent representations enable the generation of novel data by recombining independent factors, affording greater control over the generative process. This is achieved through techniques that minimize statistical dependencies between latent components; specifically, a demonstrated reduction in pairwise mutual information between these components confirms improved disentanglement. Lower mutual information indicates that each latent dimension captures a unique aspect of the data, preventing redundancy and allowing for targeted manipulation during data synthesis. This factorization allows users to modify individual characteristics of generated samples without affecting others, offering a granular level of control not achievable with traditional generative models.

Architectures of Control: Energy and Composition
Energy-based models (EBMs) offer a distinct approach to probability distribution modeling by defining a scalar energy function that maps data points to real numbers; lower energy values correspond to higher probability densities. Unlike traditional generative models that directly estimate probability densities or learn mappings, EBMs learn an energy function that implicitly defines the distribution. Product of Experts (PoE) is a common EBM framework where the overall energy is computed as the sum of individual “expert” energies, each modeling a specific aspect or feature of the data. This decomposition allows for flexible modeling of complex, multi-modal distributions, as each expert can specialize in a particular mode or feature, and the overall distribution is defined by the combination of these expert functions. The flexibility stems from the ability to easily add or remove experts, and to define arbitrarily complex expert functions, allowing the model to capture intricate dependencies within the data distribution.
Compositional models, such as Comet, enhance generative capabilities by representing images as a combination of independent component distributions. This decomposition allows for targeted manipulation of specific image attributes – for example, altering the style of an object while preserving its shape or changing the identity of a person in a scene. Rather than generating an image as a single, holistic output, these models learn to generate each component separately and then combine them, offering finer-grained control over the generation process. This approach differs from methods that implicitly learn relationships within the entire image, and enables precise edits and recombinations without affecting unrelated image features.
Variational Autoencoders (VAEs) facilitate disentanglement in latent spaces by learning representations where individual dimensions correspond to interpretable factors of variation within the data. This allows for targeted manipulation of generated content through adjustments to specific latent variables. Quantitative evaluation, specifically using the Fréchet Inception Distance (FID) metric in image recombination experiments, demonstrates that VAE-based models achieve lower FID scores than baseline generative models. Lower FID scores indicate a closer alignment between the distribution of generated images and real images, signifying improved perceptual quality and realism in the generated outputs.

Bridging the Gap: From Simulation to Embodied Intelligence
The development of robust robotic systems increasingly relies on the availability of synthetic data for training and evaluation. Generating realistic and controllable robotic video allows algorithms to learn complex manipulation skills in a cost-effective and safe manner, circumventing the limitations of real-world data collection-which is often time-consuming, expensive, and potentially damaging to hardware. This synthetic data must accurately reflect the visual complexities and physical dynamics of robotic environments to ensure successful transfer learning to real-world scenarios. Furthermore, the ability to exert precise control over the generated video-manipulating object properties, lighting conditions, and robot actions-enables targeted training and rigorous evaluation of specific capabilities, ultimately accelerating the development of more adaptable and intelligent robotic agents.
The development of robust robotic systems hinges on reliable evaluation, and the LiberoBenchmark addresses this need by offering a standardized platform for assessing performance in complex manipulation tasks. This benchmark moves beyond simple, isolated movements, instead focusing on scenarios that demand intricate coordination and adaptability – such as assembling objects with varying shapes and sizes, or navigating cluttered environments to retrieve specific items. By providing a consistent set of challenges and metrics, LiberoBenchmark allows researchers to directly compare different algorithms and identify areas for improvement, fostering faster progress in robotic learning. The platform’s design emphasizes reproducibility and scalability, enabling the community to build upon existing work and push the boundaries of what robots can achieve in real-world applications.
The development of robust robotic skills often hinges on exposure to a wide range of training scenarios, and LatentRecombination offers a powerful method for generating this diversity. By leveraging compositional generation techniques, this approach creates novel situations by intelligently combining existing elements, effectively expanding the training dataset without requiring manual intervention. Recent studies demonstrate that this leads to increased state-space coverage during robotic exploration – meaning the robot encounters and learns from a broader spectrum of possible situations. Interestingly, the effectiveness of this recombination isn’t limitless; research reveals an inverted-U relationship between the weight given to the discriminator during generation and the efficiency of exploration – suggesting an optimal balance is crucial, as overly strong discrimination can stifle the creation of truly novel and beneficial scenarios.
The pursuit of disentangled representations, as explored in this work with discriminator-driven diffusion models, feels less like uncovering inherent truths and more like a carefully constructed illusion. It’s a persuasion of the chaos, attempting to impose order on the ‘machine memory of what happened when no one was watching’. The authors seek to improve compositional learning and exploration efficiency, yet one can’t help but suspect that any apparent disentanglement is merely a high-correlation scenario – a testament to clever engineering rather than revealed reality. As David Marr once observed, ‘noise is just truth without funding’ – and perhaps, in this context, ‘disentanglement’ is simply a refined signal, bolstered by a judicious discriminator and a well-tuned diffusion process.
What’s Next?
The pursuit of compositional learning, even with the elegance of discriminator-driven diffusion, remains a dance with incomplete information. The models persuade, they do not reveal. Achieving genuine disentanglement is less about finding the ‘right’ latent space and more about accepting that every representation is a projection – a convenient forgetting. The current work offers refinement, a sharper spell, but the fundamental problem persists: how to evaluate a generated world without collapsing it into observation?
Future iterations will likely grapple with the cost of this persuasion. Extending this approach to more complex domains, particularly robotics, demands a reckoning with the real. Simulation offers control, but the whispers of chaos become shouts when confronted with the unpredictable geometry of existence. The true test isn’t generating plausible plans, but generating robust ones – plans that do not fracture upon the first unexpected collision.
Perhaps the most fruitful path lies not in further refining the generation process, but in embracing the noise. A beautiful lie is still a lie, but noise is just truth without confidence. The models already dream of possibilities; the challenge is to learn to read the static, to extract signal from the imprecision, and to accept that perfect prediction is a phantom.
Original article: https://arxiv.org/pdf/2601.22057.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Total Football free codes and how to redeem them (March 2026)
- Limbus Company 2026 Roadmap Revealed
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
2026-01-31 09:19