Author: Denis Avetisyan
Researchers present X-SYS, a comprehensive architecture designed to bridge the gap between explainable AI research and real-world application.

X-SYS delivers a reference architecture for interactive explanation systems, prioritizing stakeholder needs, system quality, and a modular design leveraging the SemanticLens framework.
Despite advances in Explainable AI (XAI), translating research into deployable systems remains a significant challenge. This paper introduces X-SYS: A Reference Architecture for Interactive Explanation Systems, addressing this gap by framing interactive explainability as an information systems problem centered on stakeholder needs and system-level qualities. X-SYS proposes a modular, five-component architecture organized around the core attributes of scalability, traceability, responsiveness, and adaptability, and is instantiated through the SemanticLens system for vision-language models. By decoupling user interfaces from backend computation, can this reference architecture finally bridge the gap between XAI research and practical, operational deployment?
The Opaque Algorithm: Unveiling the Challenge
The escalating power of artificial intelligence frequently comes at the cost of transparency, creating what is often termed the “black-box” problem. As models grow in complexity – incorporating millions or even billions of parameters – the internal logic guiding their decisions becomes increasingly opaque. This lack of visibility isn’t merely a technical hurdle; it directly impacts trust and accountability. Without understanding how a model arrives at a specific prediction, it becomes difficult to identify biases, debug errors, or ensure responsible deployment, particularly in high-stakes applications like healthcare or criminal justice. Consequently, the very strengths of these advanced AI systems are undermined by an inability to scrutinize – and therefore validate – their reasoning processes, fostering skepticism and hindering widespread adoption.
The ability to discern the rationale behind an artificial intelligence’s prediction is not merely a technical refinement, but a foundational requirement for its trustworthy implementation. Without understanding why a model arrives at a specific conclusion, identifying and rectifying errors becomes significantly more difficult, potentially perpetuating biases embedded within the training data. This lack of transparency poses serious challenges to fairness, particularly in high-stakes applications like loan approvals or medical diagnoses, where unaccountable decisions can have profound consequences. Responsible deployment, therefore, necessitates moving beyond simply assessing what a model predicts, and prioritizing the development of systems capable of articulating the logic driving those predictions, fostering accountability and building public confidence.
Many current techniques for peering inside artificial intelligence systems operate as ‘afterthoughts’ – applied after a model is trained, attempting to deduce reasoning from its outputs. These post-hoc interpretability methods often rely on approximations and simplifications, highlighting correlations rather than causations and thus failing to fully represent the complex internal processes that led to a specific prediction. Consequently, explanations generated by these tools can be misleading or incomplete, offering a superficial understanding that doesn’t accurately reflect the model’s decision-making logic. This limitation is particularly concerning in critical applications where a nuanced comprehension of why an AI arrived at a conclusion is essential for ensuring reliability, fairness, and accountability; a simple feature importance score, for instance, might not capture intricate interactions between variables driving the outcome.
The pursuit of truly explainable artificial intelligence necessitates a fundamental shift in design philosophy. Rather than attempting to dissect the ‘black box’ of already-trained, complex models, researchers increasingly advocate for building interpretability into the system from its inception. This proactive approach involves constructing models with inherent transparency – architectures where the reasoning process is visible and understandable by design, not inferred through post-hoc approximations. Such systems prioritize clarity alongside performance, potentially sacrificing some predictive power for the benefit of accountability and trust. By focusing on intrinsically interpretable models, developers can move beyond merely identifying what a system predicts to understanding why, fostering more reliable, fair, and ethically sound AI applications.

Interactive Systems: Illuminating the Algorithmic Path
Interactive Explanation Systems differentiate themselves from traditional methods, such as feature importance scores, by allowing users to actively investigate the rationale behind a model’s prediction for a specific instance. Rather than providing a static summary of overall feature influence, these systems facilitate a dynamic interrogation process; users can submit counterfactual queries-modifying input data and observing resulting prediction changes-or request justifications for specific decision paths. This granular level of access enables a deeper understanding of model behavior, exposing potential biases, identifying edge cases, and building user trust through transparency. The focus shifts from what factors influenced a prediction to how those factors combined to produce the outcome, offering insights beyond correlational metrics.
Interactive Explanation Systems are constructed using a modular architecture to facilitate independent development, maintenance, and scaling of individual functionalities. This architecture typically comprises three core components: a model serving component responsible for receiving input data and generating predictions; a data access component providing standardized access to necessary datasets and feature information; and an explanation generation component which receives predictions and data, then constructs and delivers explanations to the user. Decoupling these components allows for flexibility in choosing and updating specific technologies within each module without impacting the overall system functionality, and supports parallel development efforts.
Standardized data transfer objects (DTOs) are a core component in the design of Interactive Explanation Systems, facilitating consistent data exchange between modular services such as model serving, data access, and explanation generation. Utilizing DTOs enforces a contract between these services, defining the structure and types of data passed, thereby reducing dependencies and enabling independent development and scaling. This decoupling allows for modifications within one service without requiring changes to others, as long as the DTO contract remains consistent. Furthermore, DTOs improve data validation and error handling, ensuring data integrity throughout the system and simplifying debugging processes. The explicit definition of data structures via DTOs also enhances code readability and maintainability.
The X-SYS architecture serves as a reference implementation for building interactive explanation systems, prioritizing four core tenets: responsiveness, traceability, adaptability, and scalability. Responsiveness is achieved through asynchronous processing and optimized data transfer. Traceability is maintained by logging all requests and explanations with unique identifiers, enabling auditing and debugging. Adaptability is facilitated by a modular design, allowing for the easy integration of new models and explanation techniques. Finally, scalability is addressed through the use of microservices and horizontally scalable components, enabling the system to handle increasing user demand and data volume. This architecture aims to provide a robust and flexible foundation for developing production-ready interactive explanation systems.
Deep Exploration: Methods for Unveiling Internal Logic
The system implements semantic search capabilities, enabling users to pose questions about model behavior using natural language. This functionality is driven by models such as MobileCLIP, which facilitates the mapping of textual queries to relevant explanation components. Rather than relying on keyword matching, the system understands the meaning of the query, allowing it to retrieve explanations pertaining to specific concepts or features, even if those concepts are not explicitly mentioned in the associated documentation. This approach broadens the scope of accessible insights and supports more exploratory investigation of model reasoning.
Activation steering involves systematically altering the activations within a machine learning model to observe the resulting changes in its predictions. This is achieved by identifying specific neurons or layers and applying targeted modifications – such as increasing, decreasing, or nullifying their output. By quantifying the correlation between these activation changes and shifts in the model’s output, researchers can establish the causal influence of individual components. Techniques include gradient-based methods for identifying influential activations and direct manipulation of activation values to test hypotheses about model behavior. The resulting data allows for the isolation of features and reasoning processes that drive specific predictions, contributing to model interpretability and debugging.
XUI Services constitute the primary interface between the explanation system and the end user, responsible for the visualization and delivery of generated explanations. These services translate the internal representations of explanations – derived from semantic search, activation steering, and other analytical components – into a format suitable for interactive display. Rendering capabilities include the presentation of relevant evidence, highlighting of influential factors, and provision of controls for users to explore explanations at varying levels of detail. The XUI layer supports multiple visualization types, such as saliency maps, feature attributions, and counterfactual examples, and is designed to facilitate both passive review and active manipulation of explanatory data, all while maintaining responsiveness as defined by the system’s performance requirements.
System responsiveness is a critical design element, targeting interaction times of ≤ 1 second. This performance threshold is grounded in cognitive psychology research indicating that delays exceeding this duration can disrupt a user’s train of thought and negatively impact comprehension. Achieving sub-second latency requires optimization across the entire explanation pipeline, including model inference, data retrieval, and rendering processes. Real-time feedback is prioritized to facilitate iterative exploration and maintain user engagement, enabling a fluid and uninterrupted analytical experience.
Orchestration and Governance components within the explanation pipeline are critical for maintaining system integrity and data quality. These components implement version control for all models and explanation algorithms, ensuring reproducibility and auditability. Access control mechanisms restrict data access and modification, adhering to security protocols and compliance requirements. Data validation procedures verify the integrity of inputs and outputs at each stage of the pipeline, preventing propagation of errors. Automated monitoring and alerting systems detect anomalies and failures, enabling proactive intervention and minimizing downtime. Finally, standardized logging and reporting provide a comprehensive record of all explanation requests and system events for debugging, performance analysis, and regulatory compliance.
Toward Trustworthy AI: A Future Defined by Transparency
Modern artificial intelligence systems are increasingly designed with built-in mechanisms for tracking their own decision-making processes, a feature known as traceability. This isn’t simply about logging inputs and outputs; it involves recording the rationale behind each prediction, allowing developers and auditors to understand why a model arrived at a particular conclusion. Crucially, these systems aren’t static; adaptability is woven into their core, enabling continuous refinement based on audit findings and real-world performance. This iterative process – tracing, evaluating, and adjusting – facilitates ongoing improvement, addressing potential biases and ensuring models remain aligned with intended objectives. By prioritizing these features, developers can move beyond ‘black box’ AI, creating systems that are not only powerful but also transparent, accountable, and demonstrably trustworthy.
Interactive Explanation Systems are fundamentally reshaping how artificial intelligence is vetted and understood by those most familiar with the data it processes. These systems don’t simply offer post-hoc justifications for a model’s decisions; instead, they provide domain experts with tools to actively probe the AI’s reasoning, simulating different inputs and observing the resulting changes in output. This granular level of access allows specialists to identify subtle biases embedded within the model – biases that might otherwise remain hidden during standard performance evaluations. By facilitating a dialogue between human expertise and algorithmic logic, these systems move beyond mere transparency to enable genuine validation, ensuring that AI operates not just efficiently, but also equitably and in alignment with real-world knowledge. The result is a more trustworthy and accountable AI, capable of earning the confidence of both specialists and the wider public.
The architecture underpinning this trustworthy AI system is engineered for adaptability, seamlessly transitioning from individual developer debugging to comprehensive multi-user audit scenarios. This scalability isn’t merely a technical feature; it’s fundamental to real-world deployment. The system efficiently manages resource allocation, allowing a single user to investigate localized model behavior while simultaneously supporting a team of auditors examining the model’s broader performance and potential biases. This capability is critical for organizations needing to comply with increasingly stringent AI regulations, such as the EU AI Act, and for fostering confidence in high-stakes applications where transparency and accountability are paramount. The ability to scale audit processes ensures that AI systems remain reliable and trustworthy as they evolve and are deployed across diverse contexts.
A robust architectural foundation is now available to meet the stringent demands of modern AI governance, notably the record-keeping obligations outlined in the EU AI Act. This system meticulously logs critical data throughout the AI lifecycle – from initial training datasets and model parameters to runtime decisions and performance metrics – creating an unbroken chain of custody. Such detailed traceability isn’t merely about compliance; it provides the necessary evidence for validating model behavior, pinpointing the root cause of errors, and demonstrating accountability. The design enables efficient retrieval of this information, facilitating both internal audits and external regulatory reviews, and ultimately fostering greater transparency in increasingly complex AI systems.
The development of trustworthy artificial intelligence hinges on establishing both accountability and user confidence, and recent advances are designed to achieve precisely that. By prioritizing features like detailed model traceability and interactive explanation systems, these innovations move beyond simply achieving results to demonstrating how those results are obtained. This transparency isn’t merely a technical detail; it’s fundamental to building public and regulatory trust, ensuring AI systems are demonstrably fair, reliable, and aligned with ethical guidelines. Consequently, this increased confidence is anticipated to unlock broader adoption across critical sectors – from healthcare and finance to autonomous systems – fostering responsible innovation and realizing the full potential of AI while mitigating inherent risks.
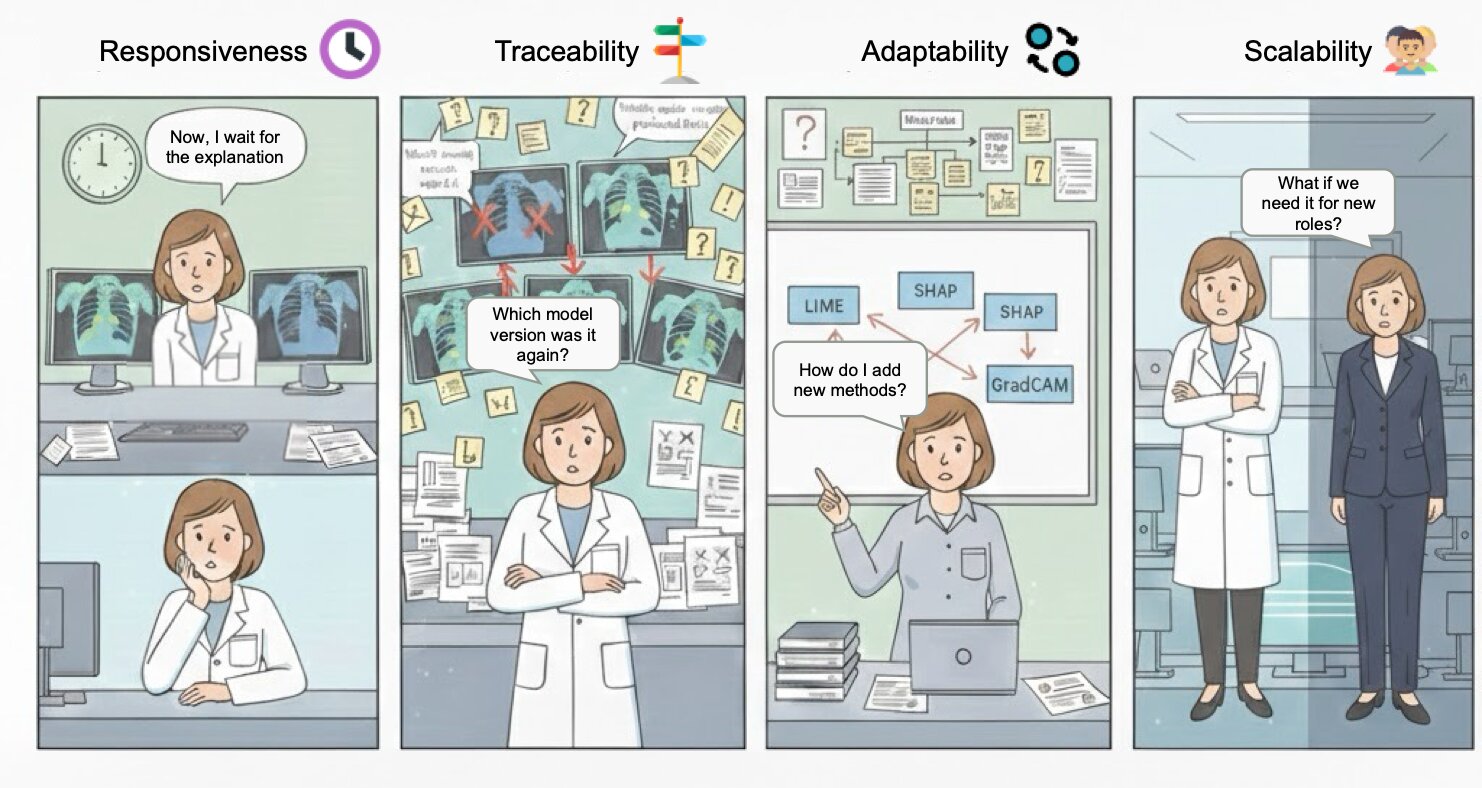
The presented X-SYS architecture prioritizes a modular design, acknowledging the inherent complexity of interactive explanation systems. This echoes Donald Davies’ sentiment: “Simplicity is the key to reliability.” The architecture’s focus on stakeholder needs and quality attributes isn’t merely about feature inclusion; it’s a deliberate reduction of extraneous elements. By concentrating on core functionalities and measurable outcomes-as X-SYS proposes with its semantic lens-the system avoids the pitfalls of over-engineering. Such restraint isn’t a limitation, but a strengthening force, resulting in a more robust and understandable framework for Explainable AI.
What Lies Ahead?
The articulation of X-SYS, as a reference architecture, does not resolve the fundamental tension within explainable AI: the belief that explanation is inherently a technical problem. It merely shifts the locus of difficulty. The architecture’s strength lies in its explicit consideration of stakeholder needs and quality attributes – a necessary, if belated, acknowledgement that explanation is not a property of a model, but a relationship between a model and an interpreter. The true challenge, then, isn’t building better explanation systems, but cultivating a deeper understanding of what constitutes meaningful intelligibility in diverse contexts.
Future work must address the inevitable fragmentation of ‘explanation’. X-SYS offers a modular framework, but the combinatorial explosion of potential stakeholder groups, quality attribute trade-offs, and underlying model complexities suggests that a single, universally applicable architecture is an illusion. The field will likely move toward specialized architectures, or, more radically, toward meta-architectures capable of dynamically assembling explanations based on real-time contextual analysis.
Ultimately, the persistence of ‘explainable AI’ as a distinct field may be a symptom of its own success. The goal should not be to perpetually refine the mechanisms of explanation, but to render them transparently integrated into the design of intelligent systems. When explanation ceases to be a separate component, and instead becomes an inherent property of intelligent action, the field, having served its purpose, will quietly dissolve.
Original article: https://arxiv.org/pdf/2602.12748.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
- Roco Kingdom: World China beta turns chaotic for unexpected semi-nudity as players run around undressed
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
2026-02-17 02:02