Author: Denis Avetisyan
A new foundation model, LDA-1B, is pushing the boundaries of embodied AI by learning robust interaction dynamics from a vast and diverse range of real-world robot data.
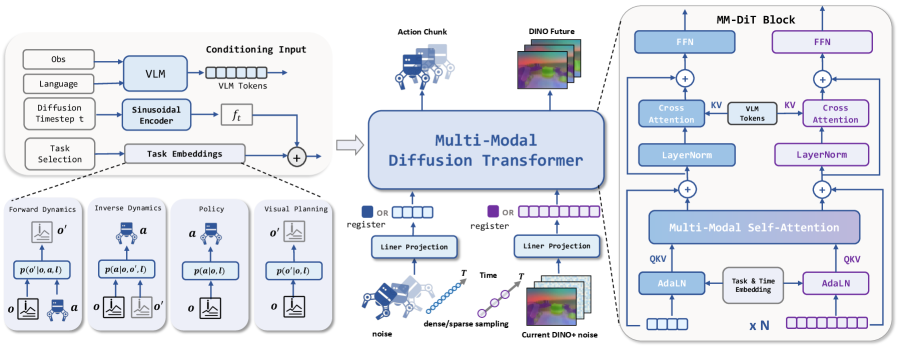
LDA-1B scales latent dynamics action modeling via universal embodied data ingestion, leveraging a diffusion transformer to create a unified world model for robots.
Existing robot foundation models often discard valuable dynamics knowledge embedded within the vast amounts of heterogeneous embodied data they collect. This work introduces ‘LDA-1B: Scaling Latent Dynamics Action Model via Universal Embodied Data Ingestion’, a scalable approach that leverages a unified world model and multi-modal diffusion transformers to ingest and learn from diverse robot interaction data. LDA-1B achieves state-of-the-art performance-outperforming prior methods by up to 48%-by jointly learning dynamics, policy, and visual forecasting within a structured latent space, and even demonstrates gains from traditionally discarded low-quality trajectories. Could this universal data ingestion paradigm unlock a new era of adaptable and robust robot learning?
The Fragility of Calculation: Beyond State Estimation
Conventional robotics frequently prioritizes meticulously calculating the current state of the environment and the robot itself – a process known as state estimation. However, this approach proves remarkably fragile when confronted with the inherent messiness of real-world conditions. Imperfect sensors, unpredictable disturbances, and the sheer complexity of dynamic environments introduce errors that rapidly accumulate, leading to instability and failure. Unlike the controlled settings of a laboratory, the real world rarely conforms to precise models; a slightly skewed sensor reading, an unexpected gust of wind, or even a subtle change in lighting can throw off these calculations. Consequently, a reliance on perfect knowledge of the present leaves many robotic systems vulnerable and unable to adapt to the inevitable uncertainties of everyday operation.
Rather than reacting to the present, increasingly sophisticated robotic systems are being designed to anticipate it. This shift towards predictive control represents a fundamental departure from traditional robotics, which heavily relies on accurate, but often fragile, estimations of the current state. By learning to forecast the likely consequences of actions, and even passively predicting what will happen next, robots can achieve a far more robust and adaptable interaction with complex environments. This proactive approach allows for smoother navigation, more precise manipulation, and a greater capacity to recover from unexpected disturbances – essentially enabling robots to ‘expect the unexpected’ and respond accordingly, rather than being perpetually caught off guard by the dynamic nature of the real world.
Effective modeling of dynamic systems demands a departure from solely reinforcing successful outcomes; instead, robust learning requires exposure to a comprehensive range of experiences, including failures and near-misses. This approach acknowledges that understanding the full scope of potential interactions – even those that don’t immediately yield positive results – is crucial for building predictive capabilities. By analyzing a broad spectrum of sensory inputs and corresponding motor outputs, a system can develop a more nuanced and generalized understanding of underlying physical laws. This isn’t simply about avoiding errors, but about extracting valuable information from every interaction, allowing for more adaptable and resilient behavior in unpredictable environments. Consequently, systems trained on diverse datasets demonstrate a superior capacity to anticipate future states and respond effectively to novel situations, far exceeding the performance of those limited to successful action pathways.
Effective prediction of future states hinges on the seamless integration of what is seen and what is possible. Research demonstrates that simply processing visual information is insufficient; a system must also possess an internal model of its own agency and the potential consequences of its actions. This unified approach allows for anticipatory control, where the system doesn’t merely react to stimuli, but proactively prepares for likely outcomes based on both sensory input and motor capabilities. Consequently, advancements in robotics and artificial intelligence increasingly focus on architectures that learn a shared representation of perception and action, enabling more fluid, adaptable, and robust interactions with dynamic environments. The brain, for example, doesn’t separate seeing and acting – and replicating this unified processing is proving crucial for building truly intelligent systems.
![The model accurately predicts future visual states [latex]\hat{x}_t[/latex] (top) that align with ground truth observations [latex]x_t[/latex] (bottom), demonstrating an understanding of object semantics and motion dynamics over time.](https://arxiv.org/html/2602.12215v1/figures/dino.jpg)
Universal Data Ingestion: Embracing the Spectrum of Experience
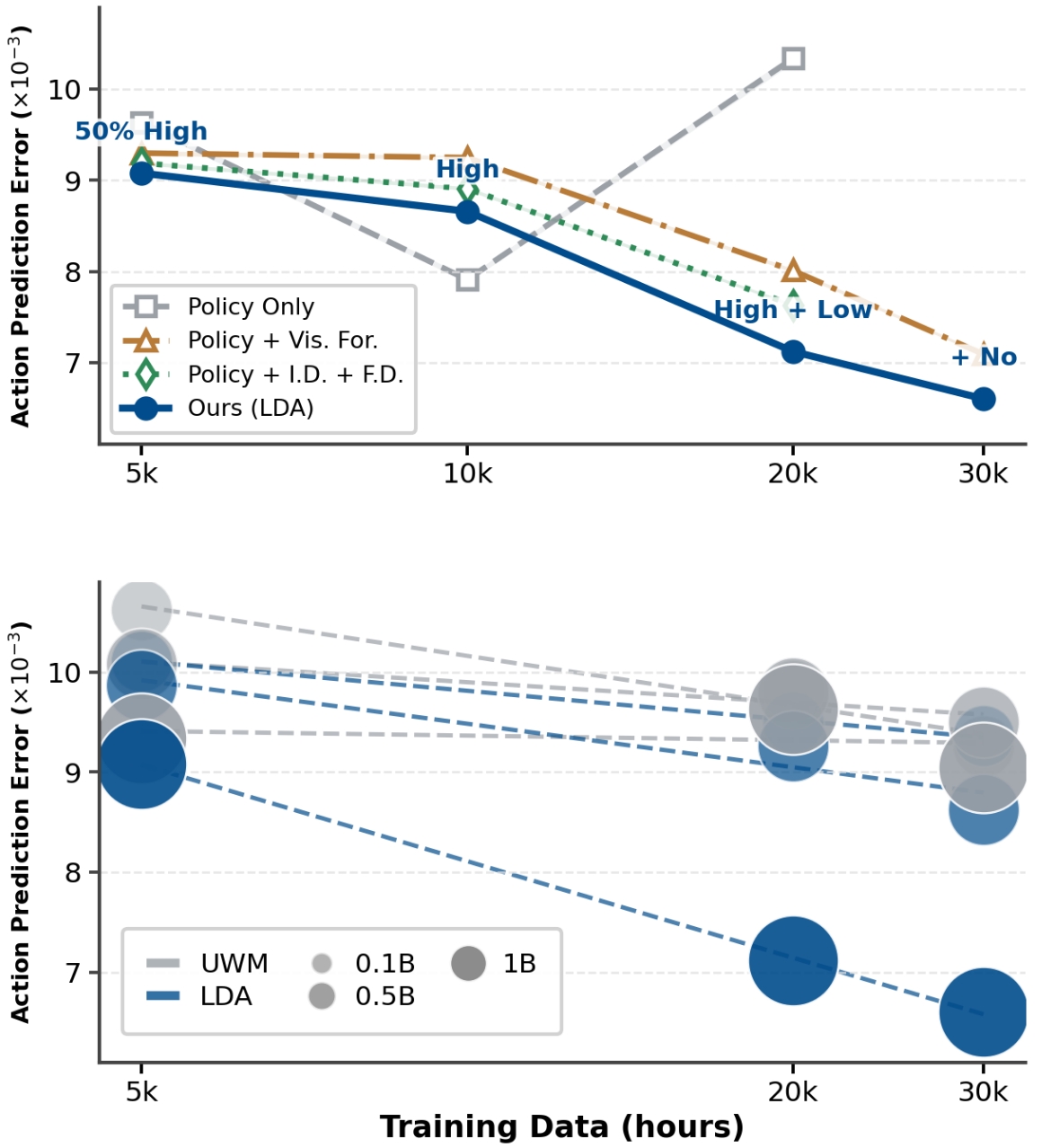
LDA-1B utilizes a ‘Universal Embodied Data Ingestion’ strategy, meaning the model is trained on a heterogeneous collection of data sources beyond solely optimal actions. This data includes demonstrations of correct task completion, examples of suboptimal or failed attempts at those tasks, and data gathered from passive observation of the environment without any specific goal-directed action. By incorporating these diverse data streams, the model aims to build a more comprehensive understanding of the environment and the effects of various actions, improving its ability to generalize to new situations and learn from a wider range of experiences.
Employing a strategy of universal embodied data ingestion allows the LDA-1B model to enhance its performance across varied and unpredictable scenarios. Training on a broad spectrum of experiences – encompassing both successful and unsuccessful attempts, as well as passive observation – facilitates improved robustness to novel situations and environments. This broadened training base directly contributes to better generalization capabilities, enabling the model to adapt more effectively to unseen data and tasks compared to models trained on limited, high-quality datasets alone. The inclusion of suboptimal trajectories, while seemingly counterintuitive, further strengthens this generalization by exposing the model to a wider range of possible states and actions.
The LDA-1B model’s universal data ingestion is not a passive process; it is actively supervised by two core learning tasks: visual forecasting and dynamics learning. Visual forecasting requires the model to predict future states of the environment based on current observations, while dynamics learning focuses on understanding the underlying physics and relationships governing those changes. This dual-task supervision creates a synergistic effect, where improvements in one task positively reinforce learning in the other. Specifically, forecasting errors provide signals for refining the dynamics model, and a more accurate dynamics model, in turn, improves forecasting accuracy. This integrated approach allows the model to extract more meaningful information from the ingested data, accelerating learning and improving overall performance.
The EI-30K dataset comprises 30,000 hours of embodied interaction data utilized for training the LDA-1B model. This large-scale dataset is critical for achieving robust performance, and notably incorporates not only high-quality, successful trajectories but also suboptimal or failed attempts. By leveraging these lower-quality data points, the model demonstrates a 10% improvement in data efficiency compared to training solely on successful demonstrations. This increased efficiency reduces the overall amount of data required to achieve a given level of performance, contributing to faster training times and reduced computational costs.
LDA-1B: A Foundation Forged in Perception and Action
LDA-1B employs a Multi-Modal Diffusion Transformer architecture to correlate visual observations with predicted actions, even when these inputs are not temporally aligned. This alignment process facilitates robust state estimation by allowing the model to infer the current state of the environment based on potentially incomplete or asynchronous sensory data. The diffusion transformer component enables probabilistic reasoning about future states, contributing to improved control performance by predicting the likely outcomes of different actions. By effectively bridging the gap between perception and action despite asynchronous inputs, LDA-1B achieves more reliable and adaptable robotic behavior in dynamic environments.
LDA-1B employs the DINO (Self-Distillation with no labels) framework to process visual inputs and generate latent feature vectors. DINO is a self-supervised learning method that trains a visual encoder by predicting its own output at different levels of abstraction, enabling it to capture semantic and spatial information without requiring explicit annotations. These learned latent features represent a compressed and meaningful representation of the observed scene, facilitating downstream tasks such as state estimation and action prediction by providing the model with a robust understanding of object identities, relationships, and spatial configurations. The resulting features are not pixel-level representations, but rather high-level abstractions that are more resilient to variations in lighting, viewpoint, and occlusion.
LDA-1B incorporates Qwen3-VL, a vision-language model, to enhance its predictive capabilities by associating visual observations with linguistic context. This integration allows the model to interpret and utilize high-level instructions and contextual cues present in natural language descriptions of tasks or environments. Specifically, Qwen3-VL processes visual inputs alongside textual prompts, enabling LDA-1B to ground its action predictions in semantic understanding rather than solely relying on low-level visual features. This contextual grounding is critical for adapting to novel situations and generalizing learned behaviors beyond the specific training data.
LDA-1B demonstrates significant performance improvements in robotic manipulation tasks through the implementation of a Latent Dynamics Representation. Specifically, the model achieves a 21% increase in success rate for contact-rich manipulation, reaching 55.4% – a 14.4% improvement over the GR00T baseline. Furthermore, LDA-1B exhibits a 48% gain in dexterous manipulation, also attaining a 55.4% success rate, and outperforms GR00T by 33.4%. These gains indicate the model’s ability to effectively predict and control complex robotic movements, establishing a foundation for developing autonomous robotic behaviors.
![Across a suite of real-world manipulation tasks, the LDA model consistently achieved a higher success rate than both GR00T-N1.6[40] and [latex]\pi_{0.5}[/latex][23] after few-shot fine-tuning on the Galbot platform.](https://arxiv.org/html/2602.12215v1/x3.png)
Beyond Automation: A Future Woven with Adaptable Intelligence
LDA-1B signifies a notable advancement in robotics by establishing a foundation model capable of generalizing across diverse tasks. Unlike traditionally programmed robots designed for singular functions, LDA-1B leverages a vast dataset of robotic experiences – encompassing manipulation, navigation, and interaction – to learn adaptable behaviors. This approach mirrors the success of large language models, where pre-training on extensive text corpora enables versatile language processing. The model’s architecture allows it to receive diverse instructions and execute them in novel environments without requiring task-specific retraining, effectively bridging the gap between rigid automation and flexible, human-like assistance. By demonstrating the feasibility of a broadly capable robotic system, LDA-1B paves the way for robots that can learn and perform a wider range of actions, ultimately fostering more seamless integration into everyday life.
The emergence of robot foundation models signifies a paradigm shift in robotics, drawing heavily from the successes of Large Language Models and Vision-Language Models in artificial intelligence. Prior robotic systems were typically designed for highly specific tasks, demanding extensive, bespoke training for even minor variations in environment or objective. These new models, however, leverage the power of broad data exposure and learned representations to achieve a remarkable level of generalization. By pre-training on vast datasets encompassing diverse robotic experiences – including visual input, sensor data, and action sequences – the models develop an underlying understanding of the physical world and task execution. This allows them to adapt to novel situations with significantly less task-specific data, effectively bridging the gap between rigid automation and flexible, intelligent behavior previously considered unattainable in robotics.
Traditional robotics often demands extensive, specialized training for each new skill a robot is expected to perform – a process that is both time-consuming and resource-intensive. However, the development of robot foundation models, akin to those driving advancements in artificial intelligence, offers a paradigm shift. These models are trained on massive datasets of robotic experiences, allowing them to generalize learned behaviors to previously unseen scenarios. Consequently, a robot built upon such a foundation requires significantly less task-specific programming; instead of being explicitly taught each action, it can leverage its pre-existing knowledge to quickly adapt and perform new tasks in unfamiliar environments. This adaptability is crucial for deploying robots in dynamic, real-world settings where pre-programmed responses are insufficient, promising a future where robots can seamlessly integrate into various contexts with minimal human intervention.
The development of increasingly adaptable robotic systems promises a future where robots move beyond specialized roles and become truly integrated companions in daily life. These advanced machines envision assisting with commonplace tasks – from managing household chores and providing personalized care to offering support in educational settings – while also possessing the capacity to collaborate on intricate projects alongside humans. This isn’t merely about automation; it’s about creating partners capable of understanding nuanced instructions, learning from experience, and proactively contributing to a shared environment. Such seamless integration hinges on a robot’s ability to generalize its knowledge, allowing it to address unforeseen challenges and operate effectively in dynamic, real-world scenarios, ultimately reshaping how humans interact with technology and redefining the boundaries of collaborative potential.
![Our learning-based dynamic adaptation (LDA) model successfully generalizes across diverse robot platforms-including Galbot G1 with both a parallel gripper and a [latex]22[/latex] DoF SharpaWave hand, and a Unitree G1 with a [latex]10[/latex] DoF BrainCo hand and Zed Mini camera-demonstrating robustness to variations in robot morphology and end-effector design.](https://arxiv.org/html/2602.12215v1/figures/real_setup.jpg)
The pursuit of a unified world model, as demonstrated by LDA-1B, echoes a fundamental truth about complex systems. It isn’t about imposing order, but about cultivating the conditions for emergence. The model’s ability to ingest heterogeneous data and predict action dynamics isn’t a testament to engineering prowess alone, but to an acceptance of inherent unpredictability. As Henri Poincaré observed, “It is through science that we arrive at certainty, but it is through uncertainty that we arrive at truth.” This sentiment resonates deeply; LDA-1B doesn’t solve the problem of robot interaction, it provides a framework for navigating its inevitable revelations. Monitoring the model’s performance, then, becomes the art of fearing consciously – anticipating not failures of prediction, but the insights they reveal about the underlying system.
What’s Next?
The pursuit of a ‘unified world model’ invariably reveals the inadequacy of unification itself. LDA-1B, in its attempt to ingest universal embodied data, doesn’t solve the problem of robot interaction – it merely postpones the inevitable fracturing. A system that predicts action based on latent dynamics will, at some point, encounter an action for which no useful latent representation exists. The model will not fail gracefully; it will hallucinate coherence. This is not an error, but a necessary condition for continued evolution.
The scaling achieved is, predictably, a temporary reprieve. Heterogeneous data, while offering breadth, introduces new vectors for systemic brittleness. Each added sensor, each new environment, is a point of potential catastrophic divergence. The model’s predictive power will always lag behind the complexity of the world it attempts to represent. The goal, then, isn’t to minimize prediction error, but to design for recoverable failure.
Future work will not focus on larger models or more data, but on the mechanisms for accepting, even embracing, disintegration. A truly robust system isn’t one that never breaks, but one that knows how to break well. Perfection leaves no room for people, and the same is true for artificial intelligence. The architecture should not seek to eliminate surprise, but to channel it.
Original article: https://arxiv.org/pdf/2602.12215.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Total Football free codes and how to redeem them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- Gold Rate Forecast
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Nicole Kidman and Jamie Lee Curtis elevate new crime drama Scarpetta, which is streaming now
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
2026-02-14 21:54