Author: Denis Avetisyan
Researchers have developed a new AI framework capable of simultaneously creating both convincing 3D human motion and corresponding video footage.
CoMoVi leverages diffusion models and cross-attention mechanisms to achieve state-of-the-art results in 3D human motion and video co-generation, accompanied by a new high-quality dataset.
Generating plausible and coherent human behavior in video remains a challenge due to the intrinsic link between 3D motion and realistic visual appearance. This paper introduces CoMoVi: Co-Generation of 3D Human Motions and Realistic Videos, a novel framework that addresses this by simultaneously generating both motion and video within a unified diffusion process. By leveraging cross-attention mechanisms and a new 2D motion representation, CoMoVi effectively couples motion and video generation, achieving state-of-the-art results and introducing the large-scale CoMoVi Dataset. Could this co-generative approach unlock more natural and believable human-computer interaction and virtual experiences?
Unveiling Movement: The Challenge of Bridging Real and Simulated Human Action
Achieving truly realistic human simulation necessitates the seamless synchronization of three-dimensional motion data with corresponding video imagery, a pairing historically hampered by significant technical challenges. The core difficulty lies in the disparate nature of these data types; motion capture provides skeletal kinematics, while video delivers photorealistic visual detail. Bridging this gap requires not merely combining these elements, but ensuring they are temporally and spatially consistent – every movement must be accurately reflected in the visual output, and vice versa. Previous attempts often prioritized one aspect over the other, resulting in either physically plausible but visually unconvincing animations, or aesthetically pleasing videos with unrealistic movement. Consequently, a unified framework capable of generating both high-fidelity motion and visually believable video in real-time remains a central pursuit in fields ranging from virtual reality and gaming to robotics and advanced visual effects.
The creation of truly believable digital humans is hampered by a fundamental challenge: simultaneously achieving both realistic motion and visually convincing video. Current techniques typically prioritize one aspect at the expense of the other; systems capable of generating fluid, physically accurate movements often produce videos with noticeable visual artifacts, while those focused on photorealistic rendering struggle to maintain believable dynamics. This disconnect arises from the complex interplay between how humans move and how those movements appear on camera – subtle variations in timing, acceleration, and body posture significantly impact visual plausibility. Consequently, existing methods frequently result in digital characters that either move unnaturally or look artificial, even with advanced rendering technologies, highlighting the need for integrated approaches that address motion and visual fidelity as a unified problem.
The creation of truly convincing digital humans hinges on a unified framework that seamlessly integrates motion and visual realism. Existing techniques often treat these aspects as separate problems, leading to discrepancies where physically plausible movement doesn’t align with believable visual appearance – a digital character might move correctly but still appear unnatural. A robust solution necessitates a system where motion generation directly informs the rendering process, and visual feedback refines the movement, ensuring a reciprocal relationship. This involves not just accurate biomechanical modeling, but also a nuanced understanding of how human motion affects visual cues like skin deformation, muscle flex, and subtle changes in silhouette. Successfully bridging this gap demands advancements in areas like differentiable rendering and physics-based simulation, ultimately allowing for the creation of digital humans capable of convincingly replicating the complexity of real human behavior and appearance.
The creation of truly convincing digital humans is hampered by a fundamental disconnect in current simulation approaches: a failure to accurately capture the intricate relationship between movement and visual appearance. Existing systems often treat these elements as separate processes, leading to inconsistencies where motion appears unnatural when rendered visually, or where realistic visuals are not dynamically informed by the subtleties of movement. This disconnect manifests in a variety of ways, from subtle distortions in muscle deformation during complex actions to a lack of appropriate visual feedback – such as clothing or skin reacting realistically to dynamic poses. The result is a perceptible uncanny valley effect, where digital humans, though technically impressive, lack the believable fluidity and responsiveness that characterizes natural human behavior, highlighting the need for a unified framework that seamlessly integrates motion and visual representation.
![Our method generates more realistic 3D human motion compared to state-of-the-art text-to-motion models [84, 34, 20, 17], outperforming a baseline combining video generation and motion capture [85, 66] even with simple text prompts.](https://arxiv.org/html/2601.10632v1/figure/mogen_comp.png)
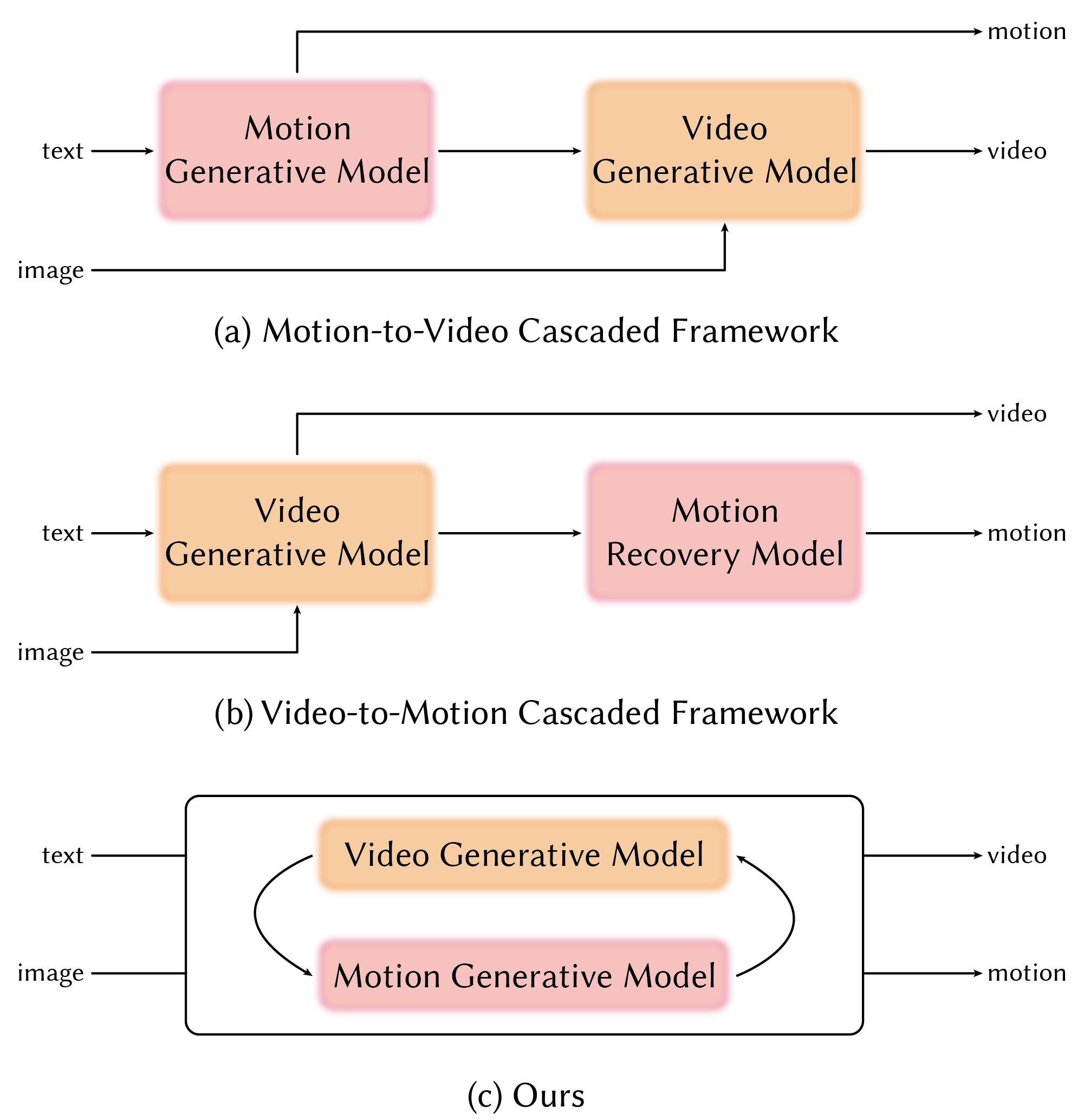
CoMoVi: A Parallel Approach to Motion and Video Synthesis
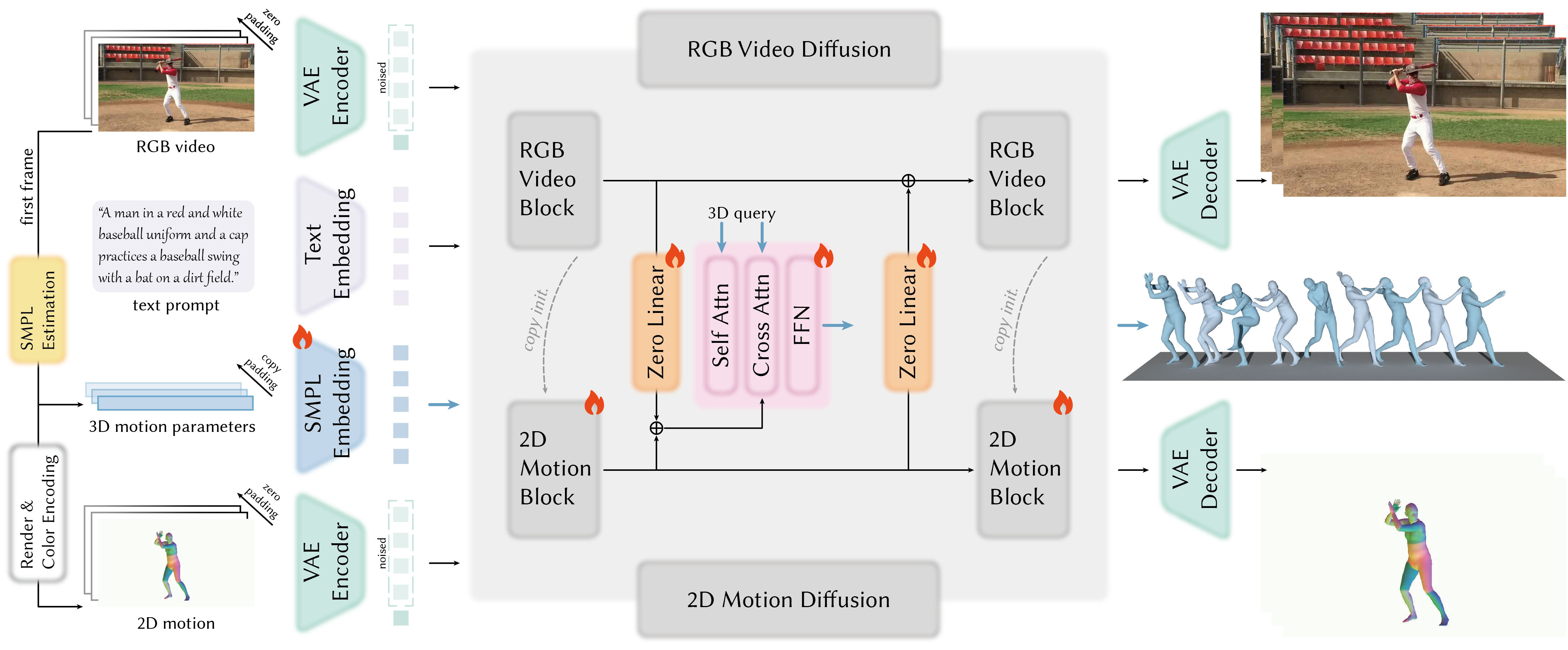
CoMoVi employs a dual-branch diffusion model architecture wherein 3D motion and video are generated in parallel. This approach diverges from sequential methods by simultaneously diffusing and denoising both modalities. Each branch consists of a U-Net structure trained to predict noise added to the respective data type – 3D skeletal joint positions for the motion branch and pixel values for the video branch. This parallel processing reduces computational latency and allows for more efficient training, as the model learns to generate both motion and video concurrently rather than conditioning one on the other in a step-by-step manner. The independent diffusion processes within each branch are then integrated through cross-attention mechanisms to ensure temporal and visual coherence.
The CoMoVi architecture employs 3D-2D cross-attention mechanisms to facilitate information transfer between the 3D motion and 2D video generation branches. Specifically, these mechanisms allow features from the 3D motion branch to attend to and modulate features in the 2D video branch, and vice versa. This bi-directional attention enables the video generation process to be conditioned on the generated motion, ensuring visual consistency, while also allowing motion generation to be informed by visual context. The cross-attention layers compute attention weights based on the similarity between queries from one branch and keys/values from the other, effectively enabling selective feature aggregation and refinement across modalities.
Zero-Linear Modules (ZLM) within the CoMoVi architecture are designed to efficiently combine features from the 3D motion and 2D video branches. These modules employ a specific parameterization where weights are not directly learned, but instead calculated based on the input features themselves, effectively creating a dynamic, input-dependent interaction. This approach avoids the computational cost of traditional attention mechanisms while still enabling cross-modal feature blending. By allowing features to interact without requiring learned parameters, ZLMs facilitate a more streamlined information exchange, which demonstrably improves the temporal and visual coherence between the generated motion and corresponding video output.
CoMoVi’s approach to generating realistic simulations involves an initial decoupling of 3D motion and video streams during the diffusion process. This separation allows each branch to be modeled with specific constraints and characteristics – motion focusing on kinematic plausibility and video on visual fidelity. Following independent diffusion, the model re-integrates these streams using 3D-2D cross-attention and Zero-Linear Modules. This re-integration isn’t a simple concatenation; instead, the cross-attention mechanism facilitates information transfer, ensuring visual elements align with the generated motion and vice-versa, resulting in a temporally coherent and visually plausible output that avoids the artifacts often seen in directly coupled generation methods.
Constructing the Foundation: The CoMoVi Dataset
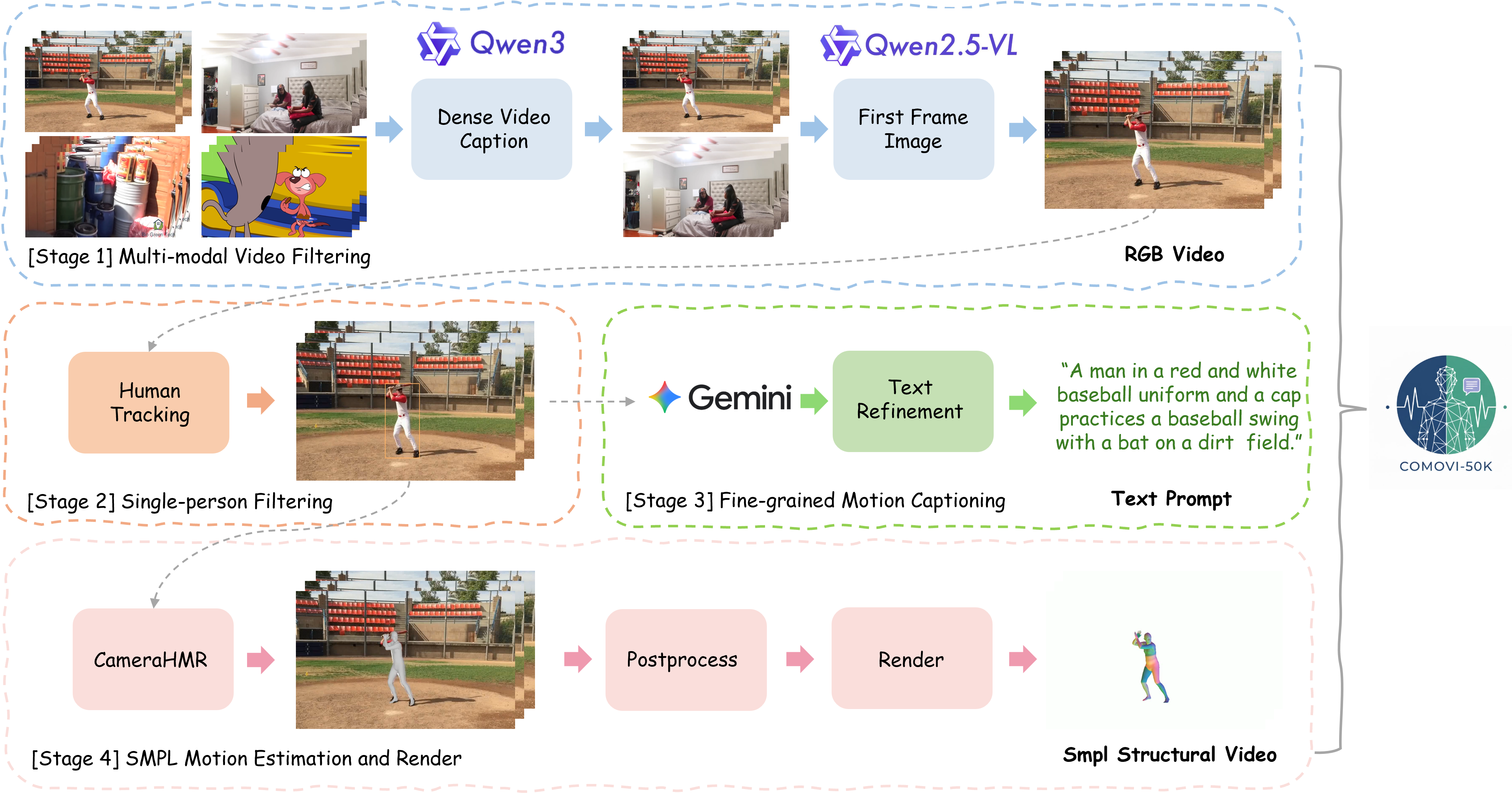
The CoMoVi dataset consists of a large-scale collection of human video sequences, each synchronized with corresponding 3D human motion capture data and descriptive text annotations. This multi-modal data pairing is fundamental to the operation of the CoMoVi framework, enabling research in areas requiring the understanding of human movement and its semantic context. The dataset’s size allows for the training of complex models, while the inclusion of both 3D pose data and textual descriptions facilitates the development of algorithms capable of linking visual actions with their corresponding language representations. The dataset’s scale is designed to support advanced machine learning techniques and to promote the creation of robust and generalizable models for human behavior analysis.
The CoMoVi dataset incorporates a multi-stage filtering process to maintain data quality and relevance. Initially, YOLO object detection identifies and filters out videos lacking prominent human subjects. Subsequently, ViTPose is employed for pose estimation; videos with unreliable pose estimations are excluded. Further refinement utilizes Qwen2.5-VL, a vision-language model, to assess the alignment between video content and associated textual descriptions, removing instances of mismatch. Finally, Qwen3, another large language model, performs a final quality check, identifying and removing videos exhibiting low semantic coherence or other quality issues, ensuring the dataset contains only high-quality, accurately annotated video data.
Video captioning within the CoMoVi dataset is performed utilizing the Gemini-2.5-Pro large language model. This process automatically generates descriptive text for each video segment, providing semantic information that complements the 3D motion capture and other annotations. The resulting captions detail actions, objects, and contextual elements present in the video, effectively bridging the gap between visual data and machine-understandable language. This enrichment allows for more sophisticated model training, enabling the development of systems capable of understanding and interpreting human movement in a broader context.
The CoMoVi dataset’s extensive scale, encompassing a large number of video samples and annotated frames, directly contributes to the development of more robust machine learning models. Diversity within the dataset – encompassing variations in subject demographics, actions performed, camera viewpoints, and environmental conditions – is equally crucial. Training on a diverse dataset mitigates overfitting to specific scenarios and enhances a model’s ability to generalize its performance to unseen data and real-world applications. Insufficient scale or limited diversity can result in models with poor performance on novel inputs or biased predictions reflecting the limitations of the training data.
Demonstrating Impact and Charting Future Directions
CoMoVi demonstrably advances the field of video generation by achieving state-of-the-art performance across critical evaluation metrics. The framework excels in producing both realistic motion and visually compelling videos, as evidenced by its superior results in R-Precision and Frechet Inception Distance (FID) assessments. R-Precision quantifies the accuracy of generated motions, while FID measures the visual fidelity of the resulting videos by comparing them to real-world footage; CoMoVi’s success in both indicates a significant leap towards generating convincingly lifelike synthetic videos. This dual achievement signifies not simply improved aesthetics, but a robust capability to synthesize motion and visuals in a manner that closely mimics reality, opening doors for increasingly immersive digital experiences.
Evaluations demonstrate that CoMoVi distinguishes itself through superior video realism, as quantified by a lower Frechet Inception Distance (FID) score compared to existing motion-to-video generation models. Critically, this advancement in visual fidelity is achieved without compromising the accuracy of generated motions; CoMoVi maintains R-Precision scores comparable to those of state-of-the-art methods. This balance – high realism coupled with precise motion reproduction – signifies a substantial step forward in generating convincingly lifelike and accurate video sequences from motion inputs, offering a marked improvement over prior approaches that often prioritize one aspect at the expense of the other.
CoMoVi builds upon the established capabilities of the Wan2.2-I2V-5B model, a powerful foundation for generating video content, and significantly refines its performance. Rather than constructing a video generation system from scratch, the researchers strategically leveraged Wan2.2-I2V-5B’s existing architecture and pre-trained weights, allowing for a more efficient development process and ultimately, a higher quality output. This approach facilitated a targeted enhancement of video realism and motion accuracy, resulting in a system capable of producing more compelling and lifelike sequences; by optimizing the existing framework, CoMoVi achieves state-of-the-art results in both motion generation and video fidelity, demonstrating the benefits of building upon – and improving – established models in the field.
To ensure precise alignment between generated motion and visual content, the CoMoVi framework integrates CameraHMR, a sophisticated technique for refining motion analysis and video synchronization. This component meticulously estimates 3D human pose from video, providing crucial data for accurately translating desired movements into realistic animations. By leveraging CameraHMR, CoMoVi minimizes discrepancies between the depicted action and the visual representation, resulting in a significantly more believable and immersive experience. The system’s ability to finely tune motion synchronization is a key factor in achieving state-of-the-art performance, particularly when generating complex or nuanced movements, and ultimately contributes to the overall realism of the generated videos.
Evaluations using the comprehensive VBench benchmark demonstrate that CoMoVi establishes a new standard in video generation capabilities. Across multiple quantitative metrics within VBench, the framework consistently surpasses the performance of leading existing models, including CogVideoX1.5-I2V-5B and Wan2.2-I2V-5B. This achievement signifies not merely incremental improvement, but a substantial leap forward in the fidelity and coherence of generated video content, validating the effectiveness of CoMoVi’s architectural innovations and training methodologies. The consistent outperformance across VBench underscores the model’s robustness and generalizability, positioning it as a leading solution for high-quality video synthesis.
The development of CoMoVi represents a significant step towards genuinely immersive virtual experiences, extending beyond current limitations in motion generation and video realism. By achieving state-of-the-art performance, this framework unlocks new possibilities for a range of applications, notably within the entertainment industry where more lifelike digital characters and environments can enhance storytelling. Beyond entertainment, the refined motion analysis and synchronization capabilities hold substantial promise for advancements in robotics, enabling more natural and intuitive human-robot interaction. Ultimately, the principles underlying CoMoVi’s success suggest a future where virtual and physical realities converge with greater fidelity, impacting fields as diverse as training simulations, remote collaboration, and accessibility technologies.
![Our human-generated videos demonstrate significantly improved visual quality and coherence compared to results from current open-source image-to-video models [108, 85].](https://arxiv.org/html/2601.10632v1/figure/vigen_comp.png)
The development of CoMoVi exemplifies a commitment to understanding complex systems through patterned data. This framework, by simultaneously generating 3D human motion and video, moves beyond isolated analyses of either component. It recognizes that realistic visual data is not simply a collection of frames, but an interwoven pattern of movement and appearance. As Fei-Fei Li observes, “AI has the potential to empower people and enrich lives,” and CoMoVi actively demonstrates this potential. The cross-attention mechanism within the diffusion model specifically highlights this focus on relationships – revealing how movement and video data inform and constrain each other, mirroring the careful observation needed to decipher any intricate system. Quick conclusions about isolated motions or frames could mask structural errors in the overall coherence of the generated sequence; instead, CoMoVi prioritizes a holistic, interconnected understanding.
What Lies Ahead?
The coupling of motion and video generation, as demonstrated by CoMoVi, reveals a fundamental truth: each modality serves as a structural constraint on the other. The pursuit of photorealism in video often necessitates plausible motion, while mechanically correct motion appears uncanny without visual grounding. Future work will undoubtedly focus on tightening this constraint, exploring methods for representing uncertainty in both domains and propagating it effectively through the generative process. The current reliance on diffusion models, while producing impressive results, invites investigation into alternative architectures that might offer greater control or efficiency.
A critical, and often overlooked, aspect remains the evaluation of generated sequences. Current metrics tend to reward superficial fidelity, failing to capture the subtle nuances of human behavior. The dataset introduced alongside CoMoVi is a step forward, but the field needs more diverse and ecologically valid benchmarks, perhaps incorporating interaction-based tasks to assess the ‘believability’ of synthesized agents. Each image hides structural dependencies that must be uncovered, and interpreting models is more important than producing pretty results.
Ultimately, the true test lies not in generating isolated sequences, but in integrating these systems into interactive environments. Can these models anticipate and respond to external stimuli? Can they learn from and adapt to user feedback? These questions point toward a future where synthesized human behavior is not merely visually convincing, but functionally indistinguishable from reality – a prospect as fascinating as it is fraught with ethical implications.
Original article: https://arxiv.org/pdf/2601.10632.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- How to find the Roaming Oak Tree in Heartopia
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- M7 Pass Event Guide: All you need to know
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- ATHENA: Blood Twins Hero Tier List
2026-01-17 13:41