Author: Denis Avetisyan
New research demonstrates that standard reinforcement learning techniques, when carefully tuned, can reliably transfer policies learned in simulation to physical robots for stable and efficient online learning.
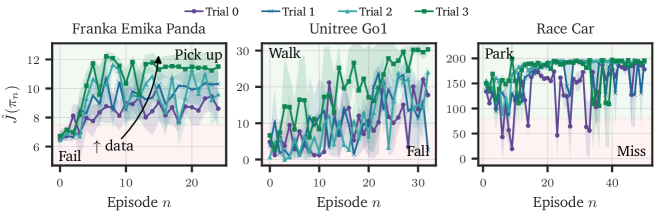
Careful data retention, warm starts, and asymmetric actor-critic updates enable effective sim-to-real transfer using off-policy reinforcement learning algorithms.
Despite advances in reinforcement learning, reliably transferring policies from simulation to real-world robots remains a significant challenge. This paper, ‘What Matters for Simulation to Online Reinforcement Learning on Real Robots’, systematically investigates the algorithmic, systems, and experimental design choices critical for successful online robot learning. Through 100 real-world training runs across three robotic platforms, we demonstrate that careful consideration of data retention, warm starts, and asymmetric actor-critic updates enables stable and efficient policy transfer using standard off-policy algorithms. Can these findings pave the way for more accessible and robust deployment of reinforcement learning on physical robots with reduced engineering overhead?
The Challenge of Efficient Learning
Conventional Reinforcement Learning methodologies typically necessitate a substantial volume of direct interaction with the environment to achieve optimal performance. This reliance on iterative trial-and-error presents a considerable hurdle in practical applications; each interaction represents a cost, whether it be time, resources, or even potential damage to physical systems. For instance, training a robotic arm through traditional RL requires countless physical movements, accelerating wear and tear on the machinery and consuming significant energy. This constraint renders the approach infeasible for scenarios where environmental interaction is expensive, time-consuming, or carries inherent risks, effectively limiting the widespread adoption of RL in fields like healthcare, finance, and complex industrial automation. The need for efficient learning strategies that minimize direct environmental contact is therefore a central challenge driving current research in the field.
The practical application of reinforcement learning frequently encounters a critical bottleneck: the scarcity of interactive data. Unlike simulations where agents can endlessly explore and learn, many real-world problems require learning from finite, pre-existing datasets – collections of observations gathered from past experiences or limited trials. This presents a fundamental challenge to standard RL algorithms, which are fundamentally designed to iteratively improve through direct environmental interaction. These algorithms often struggle to generalize effectively from limited data, leading to suboptimal performance or outright failure in complex scenarios. Consequently, researchers are actively exploring methods like offline reinforcement learning and imitation learning to enable agents to learn robust policies from static datasets, unlocking the potential of RL in fields where active data collection is expensive, dangerous, or simply impossible.
The practical implementation of reinforcement learning faces considerable hurdles when applied to fields like robotics and autonomous driving due to the inherent need for extensive trial-and-error learning. Collecting the necessary data in these domains is not merely time-consuming, but can be prohibitively expensive – think of the costs associated with maintaining a fleet of robots or vehicles for data acquisition. More critically, certain actions during the learning process can be genuinely dangerous; an autonomous vehicle learning to navigate cannot repeatedly cause accidents, and a robot operating in a sensitive environment cannot risk damaging equipment while exploring its surroundings. This reality necessitates alternative learning approaches that can effectively leverage limited, pre-existing datasets, rather than relying on continuous interaction with a potentially costly or hazardous environment.
Off-Policy Learning: The Power of Replay
On-policy reinforcement learning algorithms update their policy based solely on data collected while following that current policy. In contrast, off-policy algorithms possess the capability to learn from experiences generated by any behavior policy, including those preceding the current policy or entirely different strategies. This decoupling of data generation and learning allows for greater sample efficiency, as data collected from diverse sources – such as expert demonstrations, random exploration, or previous iterations of the agent – can be leveraged to improve performance. This characteristic is fundamental to techniques like Q-learning and Deep Q-Networks (DQN), enabling them to learn from historical data and explore more effectively than algorithms constrained to their current behavioral path.
The Replay Buffer is a fundamental component enabling off-policy reinforcement learning. It functions as a finite-capacity data storage system, typically implemented as a circular queue, that stores transitions experienced by the agent. Each transition consists of a state, action, reward, and next state – [latex] (s_t, a_t, r_t, s_{t+1}) [/latex]. By storing these experiences, the agent can decouple data collection from learning; experiences are not immediately used for updating the policy but are instead sampled randomly during training. This allows for efficient data utilization, as each experience can contribute to multiple learning updates, and facilitates learning from previously suboptimal or exploratory actions without requiring new environmental interactions.
The utilization of a Replay Buffer enables the decoupling of data generation and learning, which allows an agent to break sequential correlations present in typical interaction data. Traditional reinforcement learning often processes experiences in the order they are obtained, leading to correlated updates and potentially unstable learning. By storing experiences – state, action, reward, and next state tuples – and randomly sampling mini-batches from this buffer, the algorithm receives a more diverse and independent set of data points for each update. This random sampling reduces variance in gradient estimates, leading to more efficient learning, particularly when interactions with the environment are costly or limited. Consequently, the agent can maximize data reuse and improve sample efficiency without requiring new environment steps for every learning iteration.
While re-utilizing past experiences via a replay buffer offers significant advantages in off-policy reinforcement learning, two primary challenges impede performance. Overestimation bias arises because the same data is used to evaluate and improve the policy, leading to inflated Q-value estimates. This is particularly problematic in algorithms like Q-learning. Distribution shift, also known as covariate shift, occurs when the distribution of states encountered during data collection differs from the distribution experienced during policy evaluation, leading to inaccurate value estimations and potentially unstable learning. Techniques such as importance sampling, target networks, and conservative Q-learning are employed to mitigate these issues and ensure stable and accurate learning from off-policy data.
![Leveraging simulation data during online learning stabilizes performance, even without pre-training the initial buffer with the [latex]\pi_0[/latex] policy.](https://arxiv.org/html/2602.20220v1/x17.png)
Stabilizing the Learning Process
TD3, or Twin Delayed Deep Deterministic Policy Gradient, addresses the issue of overestimation bias common in value-based reinforcement learning algorithms. This bias arises when the Q-value estimates are systematically higher than the actual expected return, leading to suboptimal policies. TD3 mitigates this by employing two critic networks to estimate the Q-value independently; the minimum of these two estimates is then used to update the actor and target networks. Furthermore, policy updates are delayed – the actor network is updated less frequently than the critic networks – to stabilize learning by reducing the impact of potentially inaccurate Q-value estimates on the policy. This combination of techniques results in more reliable and robust policy learning.
Soft Actor-Critic (SAC) incorporates a maximum entropy objective into the reinforcement learning framework. This objective, represented mathematically as maximizing the expected return plus the entropy of the policy π, incentivizes the agent to not only maximize cumulative reward but also to maintain a diverse policy. By maximizing entropy, SAC encourages exploration of the state space, leading to more robust policies that are less susceptible to becoming trapped in local optima. This contrasts with traditional methods that focus solely on maximizing reward, which can lead to overly deterministic and fragile behaviors. The entropy term effectively adds a regularization component, promoting exploration and improving generalization performance, particularly in complex and stochastic environments.
Asymmetric updates, particularly within the Soft Actor-Critic (SAC) algorithm, improve training stability by increasing the frequency of critic network updates relative to the actor network. This approach addresses the potential for divergence arising from rapidly changing policies; more frequent critic updates provide a more accurate and timely evaluation of policy improvements. Specifically, the critic network, responsible for value estimation, is updated more often to better track the evolving policy, while the actor network, which dictates the agent’s actions, is updated less frequently to prevent drastic policy shifts. This imbalance ensures the critic remains a reliable guide for policy improvement, reducing oscillations and promoting convergence during reinforcement learning.
Our research demonstrates that stable reinforcement learning within practical time constraints is achievable through the combined use of data retention, warm starts, and asymmetric actor-critic updates. Specifically, interleaving actor updates with every 20 critic updates yielded demonstrably improved stability compared to synchronous updates. This approach leverages the more frequent critic updates to provide a more accurate valuation of actions, effectively guiding the actor’s policy improvements and reducing the potential for divergence during training. Data retention further contributes to stability by allowing the agent to learn from a more diverse dataset, while warm starts initialize the learning process with pre-trained knowledge, accelerating convergence and reducing initial instability.
![Pretraining a soft actor-critic policy on a simplified bicycle model and finetuning on realistic dynamics with reduced friction and increased [latex]M[/latex] values (ablation study with [latex]M \in\{20,10,5,1\}[/latex]) significantly improves stability and learning performance across the Franka Emika Panda, Unitree G1, and Go1 robots, requiring a learning rate reduction from [latex]3\times 10^{-4}[/latex] to [latex]1\times 10^{-5}[/latex].](https://arxiv.org/html/2602.20220v1/x4.png)
Bridging Simulation and Reality
Recent advancements demonstrate the growing efficacy of off-policy reinforcement learning algorithms in controlling a widening array of robotic systems. Researchers have successfully implemented these algorithms – which learn from previously collected data, rather than requiring constant interaction – on platforms as diverse as the Franka Emika Panda robotic arm, the quadrupedal Unitree Go1, and even full-scale race cars. This adaptability highlights a crucial step towards more generalized robotic control, as the same underlying learning framework can be applied across vastly different mechanical structures and operational environments. The ability to train an agent using data generated from any behavioral policy, and then deploy it using a different policy, offers significant advantages in terms of data efficiency and real-world applicability, paving the way for robots that can learn and adapt more quickly and reliably.
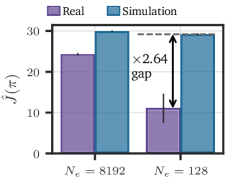
Successfully transferring learned behaviors from simulated environments to real-world robotic systems remains a central challenge in reinforcement learning, primarily due to the phenomenon known as distribution shift – the discrepancy between the simulated and physical worlds. However, recent advancements demonstrate that this gap can be effectively bridged through meticulous data collection strategies and the implementation of robust algorithms. Researchers are focusing on gathering diverse and representative datasets in simulation, often employing domain randomization techniques to expose the learning agent to a wider range of conditions. Simultaneously, algorithms are being developed to be less sensitive to these distribution shifts, leveraging techniques like adaptive normalization and robust loss functions. These combined efforts allow robots to generalize learned policies from the predictable confines of simulation to the noisy and unpredictable realities of physical operation, enabling more efficient and reliable deployment in real-world applications.
The efficiency of reinforcement learning in robotics is markedly improved through techniques like Warm Start, a method that leverages previously acquired knowledge to expedite training in novel environments. Rather than beginning the learning process from a state of complete randomness, Warm Start initializes the agent’s replay buffer-a crucial component for off-policy algorithms-with data generated by a preceding policy. This pre-population provides the agent with an immediate foundation of successful experiences, effectively shortening the exploration phase and allowing it to quickly adapt to the nuances of a new task or environment. By retaining and reusing relevant data, the agent avoids redundant learning and concentrates on refining its skills, ultimately resulting in faster convergence and enhanced performance across diverse robotic platforms.
Recent advancements in robotic control demonstrate the substantial benefits of retaining and repurposing training data across varied platforms. Studies involving the Franka Emika Panda, Unitree Go1, and a race car reveal that implementing ‘warm starts’ – initializing new learning tasks with data previously gathered from similar, but not identical, scenarios – markedly accelerates the training process and enhances overall performance. This approach circumvents the need for exhaustive re-learning with each new robotic system, capitalizing on previously acquired knowledge and reducing the time required to achieve robust control policies. The consistent performance gains observed across these diverse platforms underscore the effectiveness of data retention as a key strategy for efficient and adaptable robotic learning, suggesting a pathway towards more generalized and readily deployable robotic intelligence.

The pursuit of seamless sim-to-real transfer, as detailed in this work, often succumbs to unnecessary complexity. The paper champions a return to fundamental principles – carefully retaining data, leveraging warm starts, and employing asymmetric actor-critic updates – to bridge the reality gap. This echoes Donald Knuth’s sentiment: “Premature optimization is the root of all evil.” The researchers avoid elaborate solutions, instead focusing on a refined, efficient approach to off-policy learning. By prioritizing clarity in the transfer process, they demonstrate that robust online learning on real robots doesn’t necessitate convoluted methods, but rather, a deep understanding of core principles and careful execution.
What Remains?
The demonstrated efficacy of established off-policy algorithms, when judiciously applied to real robotic systems, suggests a curious truth: complexity was the impediment, not the problem itself. The field, for a time, chased novelty in architectures and reward functions, overlooking the potency of disciplined application. The remaining challenge isn’t finding new methods, but refining the existing ones. Specifically, the persistence of distribution shift, even with retention strategies, indicates a fundamental limitation in current state representation. A policy, however robustly trained, remains tethered to the precision of its perception.
Future work must therefore prioritize not merely the transfer of policies, but the transfer of understanding. This necessitates a shift from pixel-level or joint-angle inputs to abstracted, invariant features. Such representations would mitigate the impact of real-world noise and variability, allowing for truly generalizable robotic intelligence. Simplicity, ironically, requires a deeper level of abstraction – a willingness to discard the superfluous in favor of essential qualities.
The pursuit of perfect simulation is a fool’s errand. A truly intelligent system will not seek to replicate reality, but to understand it, and to act effectively despite its inherent imperfections. The focus should be less on closing the reality gap, and more on building bridges across it, constructed from principles of robust representation and efficient learning.
Original article: https://arxiv.org/pdf/2602.20220.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Limbus Company 2026 Roadmap Revealed
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- Total Football free codes and how to redeem them (March 2026)
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
2026-02-25 23:43