Author: Denis Avetisyan
A new vision integrates the power of large language models with rigorous formal methods to automate the creation and reuse of system contracts, paving the way for scalable and dependable software verification.
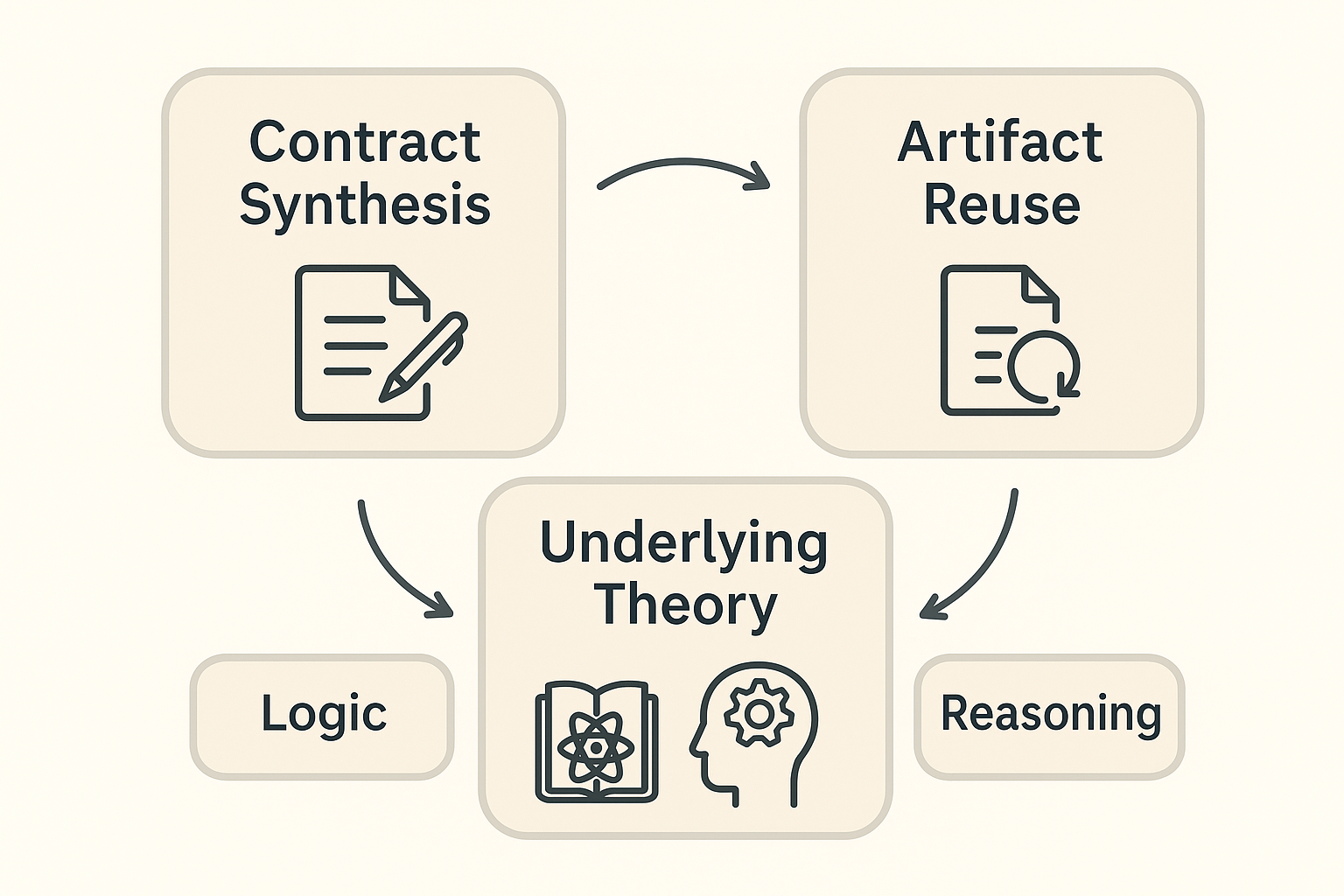
This review explores how learning-infused formal reasoning can advance contract synthesis, semantic artifact reuse, and the development of unifying theories for formal verification based on refinement calculus and graph matching.
Despite decades of progress, formal verification remains a bottleneck in building trustworthy software systems, often requiring bespoke effort for each new specification. This paper, ‘Learning-Infused Formal Reasoning: From Contract Synthesis to Artifact Reuse and Formal Semantics’, proposes a paradigm shift towards scalable, knowledge-driven verification by integrating large language models with established formal methods. We envision a framework that automates contract synthesis, enables semantic reuse of verification artifacts, and ultimately accelerates assurance through systematic evolution of verification ecosystems. Could such an approach unlock a future where verification knowledge compounds, rather than requiring constant reinvention?
The Inherent Limitations of Contemporary Verification
Despite the inherent rigor of traditional formal verification, its application to contemporary systems faces significant hurdles. These methods, reliant on exhaustive state exploration and precise logical deduction, encounter scalability bottlenecks as system complexity increases. The exponential growth in state space-a common characteristic of modern software and hardware-quickly overwhelms even the most sophisticated verification tools. Consequently, verifying all possible behaviors becomes computationally intractable, forcing engineers to prioritize specific aspects or rely on incomplete verification, which introduces the risk of undetected errors. This limitation hinders the deployment of formal methods in critical domains where absolute reliability is paramount, prompting the search for alternative or complementary approaches to ensure system trustworthiness.
A novel approach to system verification, termed Learning-Infused Formal Reasoning (LIFR), is proposed as a means of overcoming limitations inherent in traditional methods. While formal verification excels at establishing the correctness of systems with mathematical rigor, its scalability falters when confronted with the intricate complexity of contemporary designs. LIFR addresses this challenge by integrating machine learning techniques – renowned for their adaptability and pattern recognition capabilities – directly into the formal reasoning process. This synergistic combination allows for the creation of verification systems that not only guarantee trustworthiness through formal proofs, but also possess the flexibility to handle the nuances and scale of real-world applications, effectively bridging a critical gap in the field of reliable system design.
Learning-Infused Formal Reasoning endeavors to synthesize the reliability of formal methods with the robustness of machine learning, yielding systems equipped to navigate intricate, real-world challenges. Traditional formal verification, while guaranteeing correctness, often falters when confronted with the scale of contemporary software and hardware; its rigid rules struggle to abstract complex behaviors. Conversely, machine learning excels at pattern recognition and generalization, but lacks inherent guarantees of safety or correctness. LIFR addresses this dichotomy by intelligently integrating learned models – trained on vast datasets – into the formal reasoning process. This allows systems to automatically discover invariants, suggest proofs, and guide verification efforts, effectively scaling formal methods to previously intractable problems while maintaining a commitment to trustworthy operation. The resulting architecture promises not merely to verify systems, but to learn how to verify them, adapting to evolving complexities and ensuring continued reliability in dynamic environments.
Automated Contract Synthesis: A Necessary Advancement
Contract synthesis automates the creation of formal, verifiable program contracts directly from natural language specifications, addressing the limitations of manual contract creation which is both time-consuming and prone to human error. This automated approach increases efficiency by eliminating the need for developers to manually translate requirements into a formal language suitable for verification tools. The process involves parsing natural language input, identifying key constraints and preconditions, and generating a corresponding contract expressed in a formal specification language. By reducing manual intervention, contract synthesis minimizes the risk of inconsistencies and ambiguities between the stated requirements and the implemented code, ultimately leading to more reliable and secure software systems.
Large Language Models (LLMs) facilitate automated contract synthesis by performing three key functions. First, they assist in specification generation, transforming high-level, natural language requirements into more formal, machine-readable specifications. Second, LLMs enable semantic alignment, ensuring that the intent expressed in the natural language requirements is accurately reflected in the generated contract, bridging the gap between informal descriptions and formal logic. Finally, LLMs contribute to knowledge discovery by identifying relevant information within existing codebases or documentation to inform contract creation, effectively leveraging pre-existing knowledge to improve accuracy and completeness.
Large Language Models (LLMs) employ semantic embeddings – vector representations of text – to capture the underlying meaning of both natural language requirements and source code. These embeddings are generated through neural networks trained on extensive datasets, allowing the LLM to map semantically similar phrases or code snippets to nearby points in a high-dimensional vector space. This capability facilitates translation between informal requirements and formal contract languages by identifying corresponding semantic concepts, even when expressed using different syntax. The LLM can then utilize these embeddings to generate or refine contract specifications, ensuring a degree of semantic alignment between the original intent and the verifiable code contract.
Formal verification tools such as Frama-C, Z3, CVC4, and CVC5 are integral to the process of ensuring software correctness when utilizing automatically generated contracts. Frama-C is a static analysis platform for C code, enabling contract verification and deductive reasoning. Z3, CVC4, and CVC5 are Satisfiability Modulo Theories (SMT) solvers that determine the validity of logical formulas representing the contract and the program’s behavior. These tools accept formal contracts – often expressed in languages like Why3 – and systematically explore possible program states to confirm that the program adheres to the specified contract, identifying potential violations or runtime errors before deployment. The effectiveness of these tools is directly linked to the quality and precision of the input contracts, which are increasingly generated through the automation techniques described in contract synthesis.
Amplifying Verification Through Artifact Reuse
Artifact reuse in formal verification centers on the identification, comparison, and modification of pre-existing formal specifications – including contracts and associated proofs – to avoid repeating verification work. This process involves locating relevant artifacts, determining semantic equivalences or correspondences between them and the new system component being verified, and then adapting those artifacts – often through transformations or refinements – for use in the current verification context. By leveraging previously verified components, artifact reuse significantly reduces the overall effort required for system verification, improves verification efficiency, and promotes consistency across different parts of a complex system. The core principle is to avoid de novo verification whenever possible, instead building upon a library of trusted, reusable components.
Graph matching techniques are central to artifact reuse by enabling the identification of semantic correspondences between formal artifacts. These artifacts, such as contracts and proofs, are represented as graphs where nodes represent components or concepts and edges represent relationships between them. Graph matching algorithms, including subgraph isomorphism and approximate matching, are employed to find similarities between these graphical representations. Successful matching indicates that components or logical structures in one artifact have equivalent functionality or meaning in another, allowing for the adaptation or direct reuse of verification results. The efficiency and accuracy of these algorithms are critical, as the complexity of graph matching grows rapidly with artifact size; therefore, optimized algorithms and heuristics are frequently utilized to manage computational demands.
Large Language Models (LLMs) facilitate artifact reuse by automating portions of the alignment process between formally verified components with differing specifications or proof structures. Specifically, LLMs can be employed to translate between specification languages, identify equivalent expressions across different formalisms, and suggest adaptations to proofs to accommodate minor variations in component interfaces. This capability reduces the manual effort required to determine the compatibility of existing artifacts, accelerating the integration of reusable components and extending the applicability of formal verification to more complex systems. LLMs do not independently verify correctness, but rather assist engineers in the alignment and adaptation tasks necessary to leverage existing, verified artifacts.
Expanding the applicability of formal verification beyond traditionally verified, safety-critical components is achieved through techniques that reduce the cost and effort associated with creating formal models and proofs. Previously, the high resource demands of formal methods limited their use to smaller, well-defined systems; however, artifact reuse, combined with automated assistance from tools like Large Language Models and graph matching algorithms, enables the adaptation of existing formal specifications and proofs to new contexts. This lowers the barrier to entry for applying formal verification to larger, more complex systems – including those with evolving requirements – and to a broader range of application domains where the cost previously outweighed the benefits. Consequently, systems previously reliant on less rigorous testing methodologies can now incorporate the increased assurance provided by formal verification.
Dynamic Analysis: A Complementary Verification Strategy
PathCrawler functions as a powerful dynamic analysis tool, extending the capabilities of static verification techniques by actively executing code and observing its behavior. While static analysis identifies potential flaws through examination of the source code, PathCrawler uncovers errors that only manifest during runtime – such as division by zero, null pointer dereferences, and memory safety violations. This is achieved through a process of symbolic execution and concrete testing, systematically exploring different execution paths and identifying vulnerabilities that might be missed by purely static methods. By complementing static verification, PathCrawler offers a more comprehensive approach to software robustness, ensuring that systems not only adhere to specified properties but also function reliably under a variety of operating conditions and input scenarios. The tool’s dynamic nature allows it to detect issues arising from complex interactions and external factors, contributing to the development of more trustworthy and secure software.
PathCrawler achieves its analytical power through a crucial symbiotic relationship with Frama-C, a static analysis platform. This integration isn’t merely a matter of compatibility, but a deliberate architectural choice enabling a hybrid verification approach. Frama-C first performs static checks, identifying potential issues without executing the code, and then PathCrawler leverages this pre-analysis to intelligently guide its dynamic exploration. Specifically, Frama-C’s intermediate representation of the code, along with its understanding of program semantics, informs PathCrawler’s path generation heuristics, allowing it to prioritize potentially vulnerable execution paths. This combined strategy significantly reduces the search space for dynamic analysis, making it more efficient and effective at uncovering runtime errors and security flaws that static analysis alone might miss, ultimately contributing to a more trustworthy and robust system.
Effective utilization of PathCrawler necessitates careful attention to path exploration heuristics and tool configuration, as these directly impact both the speed and completeness of analysis. The tool’s ability to navigate complex code relies on intelligently prioritizing execution paths; poorly chosen heuristics can lead to superficial testing, missing critical vulnerabilities hidden within less-frequently traversed branches. Similarly, adjustments to configuration parameters – such as memory limits, timeout durations, and the depth of symbolic execution – are crucial for balancing thoroughness with computational feasibility. Optimizing these settings isn’t merely about faster execution; it’s about maximizing the likelihood of uncovering subtle runtime errors and security flaws, ultimately bolstering the robustness of the analyzed system. A well-tuned PathCrawler transforms from a simple execution engine into a powerful, focused verification asset.
The pursuit of truly trustworthy systems hinges on sustained investigation into foundational principles like the Unifying Theory of Programming and the Theory of Institutions. This ongoing research isn’t simply about improving existing verification methods; it aims to establish a new paradigm where correctness and security are not post-hoc testing concerns, but inherent properties of the system’s design. By providing the mathematical tools to formally specify, analyze, and ultimately prove the behavior of complex software and hardware, these theoretical advancements promise a future where critical infrastructure – from financial networks to autonomous vehicles – operates with unprecedented levels of assurance. This proactive approach to reliability is essential as systems become increasingly intertwined with daily life, demanding a shift from reactive error correction to preventative, provable security.
Foundational Principles for Demonstrably Reliable Systems
The Unifying Theory of Programming (UTP) proposes a single, coherent framework for understanding the meaning of programs written in vastly different languages – from imperative languages like C to functional languages like Haskell, and even concurrent systems. Rather than treating each programming paradigm as isolated, UTP defines a common semantic language based on logical relations, allowing programmers and researchers to express program specifications and verify correctness in a unified way. This approach transcends syntactic differences, focusing instead on the underlying behavior of programs, and enables the development of tools that can reason about programs regardless of their implementation language. By providing a shared foundation, UTP facilitates the translation of verification efforts across languages, fostering greater confidence in complex, multi-language systems and ultimately paving the way for more reliable and secure software.
The Theory of Institutions provides a powerful, abstract framework for understanding and relating different logical systems-such as those used in program verification and artificial intelligence. Rather than treating each logic as isolated, this theory views them as instances of a universal structure, allowing researchers to define precisely how these systems connect and to compare their expressive power. This categorical approach facilitates the development of verification tools that aren’t limited to a single logic; instead, these tools can be designed to work across multiple logics, adapting to the specific requirements of a given system. Consequently, the Theory of Institutions supports a more flexible and expressive approach to ensuring the correctness and reliability of increasingly complex software and AI applications, ultimately enabling the creation of more trustworthy systems.
A dependable foundation in formal methods is becoming increasingly vital as artificial intelligence systems grow in both complexity and societal impact. Current AI relies on vast datasets and intricate algorithms, creating challenges for verification and validation; traditional testing methods struggle to guarantee reliability in these scenarios. The theoretical underpinnings of programming language semantics, like the Unifying Theory of Programming and the Theory of Institutions, provide the necessary tools to move beyond empirical testing toward provable correctness. By establishing a rigorous, mathematical basis for system behavior, these approaches enable the development of a scalable infrastructure capable of supporting the safety, security, and trustworthiness of increasingly sophisticated AI applications – ultimately fostering confidence in systems designed to operate autonomously and make critical decisions.
The pursuit of demonstrably reliable systems hinges on sustained investigation into foundational principles like the Unifying Theory of Programming and the Theory of Institutions. This ongoing research isn’t simply about improving existing verification methods; it aims to establish a new paradigm where correctness and security are not post-hoc testing concerns, but inherent properties of the system’s design. By providing the mathematical tools to formally specify, analyze, and ultimately prove the behavior of complex software and hardware, these theoretical advancements promise a future where critical infrastructure – from financial networks to autonomous vehicles – operates with unprecedented levels of assurance. This proactive approach to reliability is essential as systems become increasingly intertwined with daily life, demanding a shift from reactive error correction to preventative, provable security.
The pursuit of automated contract synthesis, as detailed in the paper, mirrors a fundamental principle of elegant code: demonstrable correctness. Tim Berners-Lee aptly stated, “The Web as I envisaged it, we have not seen it yet. The future is still so much bigger than the past.” This sentiment applies directly to formal verification; current systems, while functional, lack the scalability and expressiveness necessary to truly realize the vision of trustworthy software. The integration of large language models offers a path towards achieving this, not by sacrificing mathematical rigor, but by augmenting it, allowing for the creation of verification systems that are both powerful and provably correct – a future significantly beyond current capabilities. The paper’s focus on unifying theories of programming and refinement calculus seeks precisely this consistency – a bedrock for verifiable systems.
What’s Next?
The ambition to unite the pragmatic power of large language models with the rigor of formal verification is not without its inherent tensions. The current reliance on statistical correlation, while producing superficially convincing results, remains fundamentally distinct from the deductive certainty demanded by true verification. The promise of automated contract synthesis and semantic artifact reuse hinges on resolving this dissonance – on moving beyond pattern recognition to provable correctness. Graph matching, while a useful heuristic, is not a theorem prover.
Future work must address the limitations of current approaches. A critical path lies in the development of robust, mathematically grounded methods for translating natural language specifications into formal logic, and conversely, for interpreting formal proofs in human-understandable terms. The paper rightly points toward unifying theories of programming, but the path to such a synthesis is fraught with the complexities of differing semantic models and the ever-present challenge of compositional reasoning.
Ultimately, the field requires a shift in emphasis. The focus should not be solely on scaling existing techniques, but on establishing a firmer theoretical foundation – on building verification systems where trust is derived from mathematical proof, not empirical observation. In the chaos of data, only mathematical discipline endures.
Original article: https://arxiv.org/pdf/2602.02881.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Limbus Company 2026 Roadmap Revealed
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Total Football free codes and how to redeem them (March 2026)
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
2026-02-04 21:07