Author: Denis Avetisyan
A new framework leverages the laws of physics and deep learning to generate realistic microscopic images, dramatically improving the accuracy of microrobot pose estimation.
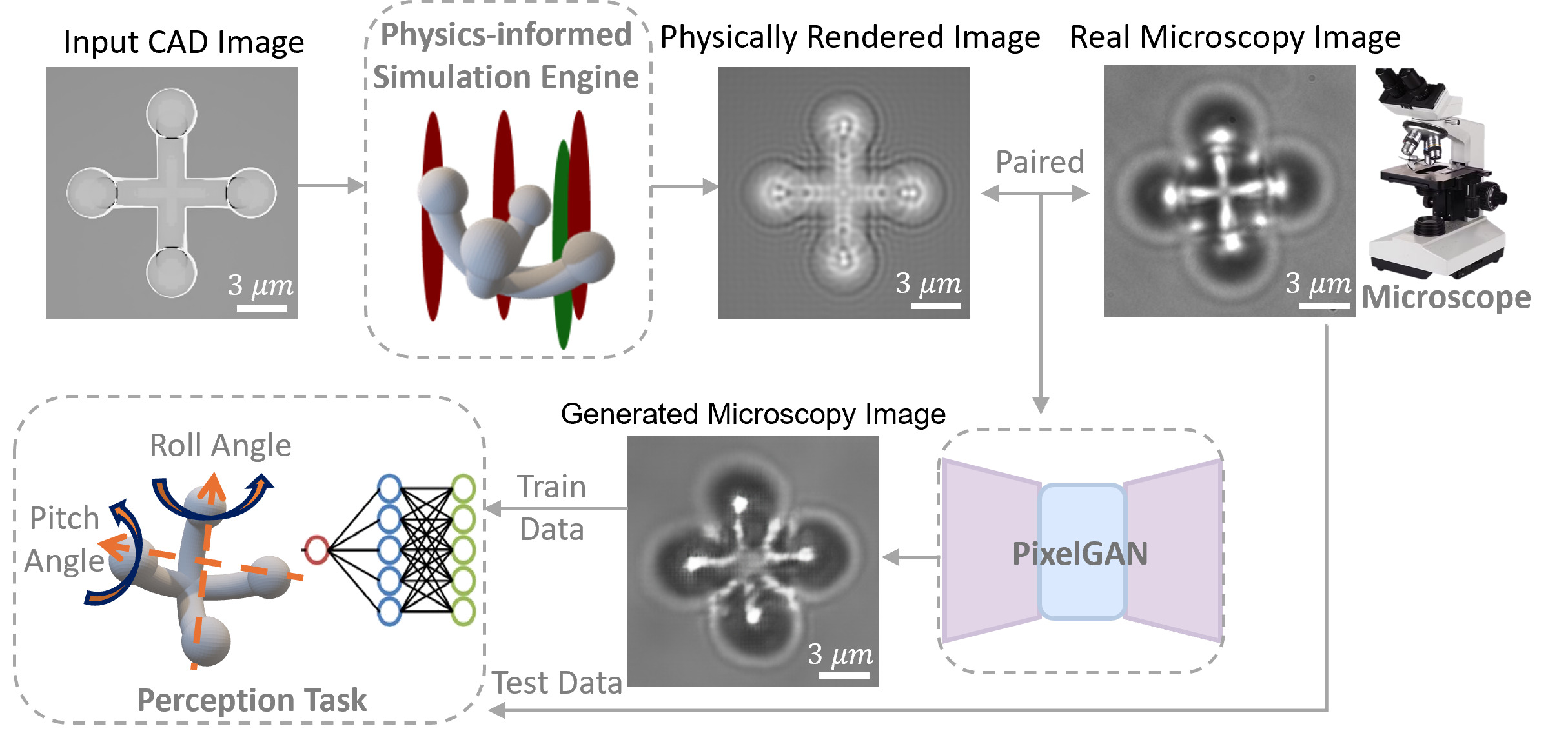
Physics-informed machine learning and generative adversarial networks enable efficient sim-to-real data augmentation for optical microscopy-based microrobot pose estimation.
Accurate pose estimation of micro-objects is crucial for automated biological studies, yet acquiring sufficient labelled microscopy data remains a significant bottleneck. This work, ‘Physics-Informed Machine Learning for Efficient Sim-to-Real Data Augmentation in Micro-Object Pose Estimation’, introduces a novel framework that bridges the reality gap in sim-to-real transfer by integrating wave optics-based rendering within a generative adversarial network. The resulting synthetic images substantially improve pose estimation accuracy – achieving up to 93.9% accuracy – while reducing reliance on costly real-world datasets. Could this physics-informed approach unlock more robust and generalizable AI for precision manipulation in complex microscopic environments?
Decoding the Microscopic Realm: Challenges in Robotic Localization
Accurate control of microrobotic systems operating within complex environments fundamentally relies on precise pose estimation – determining the robot’s position and orientation in three-dimensional space. However, conventional localization techniques, particularly those reliant on image-based analysis, encounter substantial difficulties at the microscale. These challenges stem from the inherent limitations in capturing clear, interpretable visual data when dealing with microscopic features and the increased sensitivity to factors like lighting and surface textures. Consequently, standard computer vision algorithms, designed for macroscopic scenes, often fail to provide the necessary accuracy and robustness required for effective microrobot navigation and manipulation, necessitating the development of specialized techniques tailored to the unique demands of this field.
The inherent difficulties in visualizing and interpreting images at the microscale present a significant hurdle for microrobot navigation. Traditional computer vision algorithms, designed for macroscopic scenes, often falter when applied to the blurred, distorted, and low-contrast imagery typical of microscopic environments. This stems from factors like diffraction limits of optics, the shallow depth of field, and the increased influence of surface scattering. Consequently, robust and adaptable techniques – potentially incorporating novel image processing methods, machine learning algorithms trained on synthetic micro-imagery, or even multi-sensor fusion – are essential to reliably extract positional information and enable precise microrobot control within complex biological or industrial settings. Overcoming these limitations is not merely a matter of increasing image resolution; it requires fundamentally rethinking how visual data is acquired, processed, and interpreted at the microscale.
Microrobotic navigation within biological tissues and intricate microenvironments is significantly hampered by distortions inherent in microscopic imaging. Traditional computer vision algorithms, designed for macroscopic scenes, struggle to interpret images captured through a microscope due to phenomena like spherical aberration, scattering, and diffraction. These optical effects warp the appearance of features, making accurate pose estimation – determining the microrobot’s position and orientation – exceptionally difficult. Consequently, algorithms relying on simple image comparisons often produce substantial errors, leading to imprecise control and hindering the reliable execution of tasks. Researchers are now focusing on developing novel techniques that model and compensate for these distortions, employing strategies like physics-based rendering and advanced image reconstruction to improve the fidelity of visual data and enable robust microrobotic localization.

Constructing a Virtual Microcosm: The Physics-Informed Digital Twin
A digital twin of the microrobotic system is created via physics-based modeling, employing wave optics to simulate the image formation process. This approach differs from ray tracing by accounting for the wave nature of light, enabling the accurate representation of phenomena like diffraction and interference. The simulation propagates light fields through the system’s optical components and the surrounding microenvironment, calculating the resulting image as it would be observed by the imaging system. This method allows for the prediction of image characteristics based on the system’s geometry, material properties, and illumination conditions, providing a virtual testing ground for algorithm development and system optimization prior to physical experimentation.
The integration of wave optics into digital twin construction enables accurate modeling of the system’s $MTF$ and aberrations, directly impacting the fidelity of simulated images. Traditional image formation models often rely on simplifying assumptions that limit their ability to represent the complexities of light propagation. Wave optics, by solving the wave equation, accounts for phenomena such as diffraction and interference, leading to a more realistic representation of how light interacts with the microenvironment and optical components. Specifically, the $MTF$ – a measure of image sharpness – is calculated based on the wave-optical simulation, providing a quantitative assessment of image quality. Aberrations, which cause distortions in the image, are also modeled with greater precision, allowing for the development of correction algorithms and a more accurate depiction of the observed imagery within the digital twin.
Physics-Informed Machine Learning (PIML) techniques augment the digital twin by incorporating data-driven models constrained by the underlying physics of light-tissue interaction. These methods address complexities not fully captured by purely physics-based simulations, such as scattering from heterogeneous microenvironments and variations in tissue refractive index. PIML approaches typically involve training neural networks with datasets generated from wave optics simulations, while simultaneously enforcing physical constraints via regularization terms in the loss function. This ensures the learned models remain consistent with established optical principles, improving the accuracy of image formation modeling and enabling more realistic simulations of the microrobotic system’s visual perception within complex biological media. The integration of PIML bridges the gap between computational efficiency and physical fidelity, allowing for effective prediction of image characteristics in scenarios with significant optical scattering and absorption.
Zernike Polynomials are utilized within the digital twin simulation to represent wavefront aberrations, which degrade image quality in optical systems. These polynomials form a complete orthogonal set, allowing for the decomposition of any wavefront error into a series of weighted Zernike modes. Specifically, each Zernike polynomial, defined by radial and angular indices ($R$, $L$), describes a specific type of aberration, such as defocus, astigmatism, and coma. By quantifying aberrations using Zernike coefficients and incorporating these into the wave optics model, the simulation accurately replicates the effects of optical imperfections, enabling the evaluation and correction of aberrations within the virtual microrobotic system. This approach allows for the precise modeling of image distortions and facilitates the development of aberration correction algorithms.

Validating the Virtual: Training and Simulation-Driven Algorithm Development
Pose estimation algorithms are trained within the digital twin environment utilizing a substantial and varied dataset of synthetically generated images. This training encompasses both Convolutional Neural Networks (CNNs), such as the ResNet18 architecture, and vision transformer (ViT) models. The simulated dataset provides complete ground truth annotations for each image, including precise 3D joint positions, which are crucial for supervised learning. The scale of the dataset, coupled with its diversity in terms of object pose, lighting conditions, and background clutter, is intended to enhance the algorithms’ ability to generalize to real-world scenarios. Training within the digital twin allows for iterative refinement of the algorithms without the need for costly and time-consuming real-world data collection.
The Isaac Sim platform streamlines the creation of training datasets for pose estimation algorithms by providing a physically realistic and programmable simulation environment. This enables the automated generation of large volumes of labeled data, including variations in lighting, textures, and object configurations, which are crucial for training robust models. Data generation is accelerated through parallelization and the platform’s NVIDIA RTX rendering capabilities, significantly reducing the time required for algorithm development and optimization compared to reliance on manually collected real-world data. The platform also supports programmatic control of the simulation, allowing for targeted data generation to address specific failure cases or edge conditions, further improving algorithm performance.
Data augmentation leverages Generative Adversarial Networks (GANs), specifically the PixelGAN architecture, to enhance the performance of pose estimation algorithms. PixelGAN introduces variations in the simulated training data by generating new images that maintain realistic characteristics but differ in subtle ways from the original simulations. This process increases the diversity of the training set, exposing the algorithms to a wider range of potential scenarios and improving their ability to generalize to real-world data. By artificially expanding the dataset with GAN-generated samples, the robustness of the algorithms against variations in lighting, texture, and viewpoint is significantly improved, leading to more accurate and reliable pose estimation in practical applications.
PixelGAN and Laplacian of Gaussian (LoG) methods address the domain gap between simulated and real-world data by refining pixel-level alignment. PixelGAN, a Generative Adversarial Network, is employed to translate synthetic images to appear more realistic, reducing discrepancies in texture and appearance. Simultaneously, LoG is utilized for feature detection and matching; it identifies edges and corners in both simulated and experimental images, providing a basis for correspondence mapping. These techniques facilitate improved depth estimation and pose reconstruction by minimizing errors arising from differences in image characteristics and ensuring accurate feature correspondence between the two datasets. The combined approach enhances the transferability of algorithms trained in simulation to real-world scenarios.

Bridging the Reality Gap: Sim-to-Real Transfer and Performance Validation
The culmination of this research involved deploying the trained pose estimation algorithms onto a physical microrobotic system, a critical step in validating the efficacy of the simulation-based training. Results demonstrate a marked improvement in both accuracy and robustness when contrasted with conventional pose estimation techniques employed in real-world robotic applications. This enhanced performance stems from the algorithm’s ability to generalize learned features from the simulated environment to the complexities of a live robotic system, effectively bridging the reality gap. The successful deployment signifies a substantial advancement towards reliable and precise robotic manipulation, opening avenues for applications requiring delicate and accurate control within constrained spaces.
Bridging the divide between controlled simulation and unpredictable reality is paramount for successful robotic deployment, and this work leverages Sim-to-Real transfer techniques to address this challenge. These techniques actively reduce the “domain gap” – the discrepancies in visual appearance and dynamics between the simulated environment and the real world – by adapting the training process. Through methods like domain randomization and adversarial learning, the system learns to generalize beyond the pristine conditions of simulation, becoming more robust to noise, lighting variations, and imperfections inherent in real-world scenarios. This adaptation is crucial because a pose estimation algorithm trained solely in simulation often falters when confronted with the complexities of a physical environment; therefore, minimizing this gap ensures the reliable and accurate performance of the microrobotic system in practical applications.
Rigorous evaluation of pose estimation accuracy necessitates the use of quantifiable metrics, and this framework employs several key indicators to achieve that goal. Mean Squared Error ($MSE$) assesses the average squared difference between estimated and ground truth poses, providing a direct measure of error magnitude; however, it can be sensitive to outliers. To address this, Peak Signal-to-Noise Ratio ($PSNR$) is utilized, expressing the ratio between the maximum possible power of a signal and the power of corrupting noise, effectively highlighting the clarity of the estimation. Complementing these, the Structural Similarity Index ($SSIM$) measures the perceived change in structural information, focusing on aspects like luminance, contrast, and structure – providing a more perceptually aligned assessment of fidelity. By integrating these metrics, a comprehensive and nuanced understanding of pose estimation performance is achieved, allowing for precise comparisons and improvements.
The developed framework demonstrably bridges the gap between simulated environments and real-world robotic applications, achieving a significant $35.6\%$ improvement in image fidelity as measured by the Structural Similarity Index (SSIM). This enhancement translates directly into a reduced sim-to-real disparity, confining the performance difference for a Convolutional Neural Network (CNN) pose estimator to a remarkably narrow range of $5.0\%-5.4\%$. Such a minimized discrepancy indicates the efficacy of the transfer learning techniques employed, allowing algorithms trained in simulation to perform with high accuracy when deployed on a physical microrobotic system, and suggesting a robust and reliable solution for real-world pose estimation tasks.
Comparative analysis between PixelGAN-30 and PixelGAN-35 reveals a nuanced trade-off between simulation realism and pose estimation accuracy. While PixelGAN-35 enhances the fidelity of simulated images, potentially bridging the sim-to-real gap, it exhibits a relative 2.5% decrease in accuracy when applied to previously unseen robotic poses. This suggests that increasing the complexity of the simulation – and striving for photorealism – doesn’t automatically guarantee improved performance on novel scenarios; a point where the benefits of enhanced visual detail are offset by potential overfitting to the specific characteristics of the training data. This observation underscores the importance of careful validation and generalization testing when employing domain randomization and sim-to-real transfer techniques, highlighting that a balance between simulation fidelity and robustness is crucial for successful deployment on real-world microrobotic systems.
The pursuit of accurate microrobot pose estimation, as detailed in this work, hinges on discerning underlying structural dependencies within the generated imagery. Each simulated image, while computationally efficient, must convincingly replicate the complexities of wave optics to bridge the sim-to-real gap. This aligns with David Marr’s assertion that “representation is the key; the trick is to find the right one.” The framework detailed here doesn’t merely aim to produce realistic images; it prioritizes building a representational model informed by physical principles, ultimately allowing for more robust pose estimation and minimizing reliance on expansive, costly real-world datasets. The PixelGAN component serves as a means to an end – a method for creating representations that capture the essential features for accurate analysis.
Beyond the Looking Glass
The presented framework, while demonstrably effective in bridging the sim-to-real gap, highlights a recurring pattern in computational microscopy: the persistent tension between fidelity and efficiency. The successful integration of physics-informed machine learning suggests that simply increasing simulation complexity isn’t the answer; instead, intelligent abstraction, guided by fundamental physical principles, offers a more promising path. Future work should explore how to systematically identify and model those aspects of wave optics most critical to accurate pose estimation, potentially employing techniques from sensitivity analysis to prune unnecessary computational burden.
A lingering question concerns the generalizability of this approach. While effective for microrobots, the specific physics-informed loss functions were tailored to their geometry and optical properties. The field now faces the challenge of developing more adaptable, even meta-physical, priors – loss functions that can automatically infer relevant physical constraints from limited data. This would necessitate exploring architectures capable of learning the “rules of the game” from observation, rather than relying on pre-defined models.
Ultimately, the creation of a truly robust digital twin requires more than just visually convincing imagery. It demands a comprehensive understanding of the underlying physics, and an acknowledgement that even the most sophisticated models are, at best, approximations of a fundamentally complex reality. The pursuit of perfect simulation may be a fool’s errand; the art lies in knowing which imperfections matter, and building systems that are resilient to them.
Original article: https://arxiv.org/pdf/2511.16494.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- M7 Pass Event Guide: All you need to know
- Clash Royale Furnace Evolution best decks guide
- Clash Royale Season 79 “Fire and Ice” January 2026 Update and Balance Changes
- World Eternal Online promo codes and how to use them (September 2025)
- Clash of Clans January 2026: List of Weekly Events, Challenges, and Rewards
- Best Arena 9 Decks in Clast Royale
- Best Hero Card Decks in Clash Royale
2025-11-24 03:09