Author: Denis Avetisyan
Researchers are building advanced robotic systems powered by a novel computing architecture that merges the strengths of neuromorphic and traditional processors.
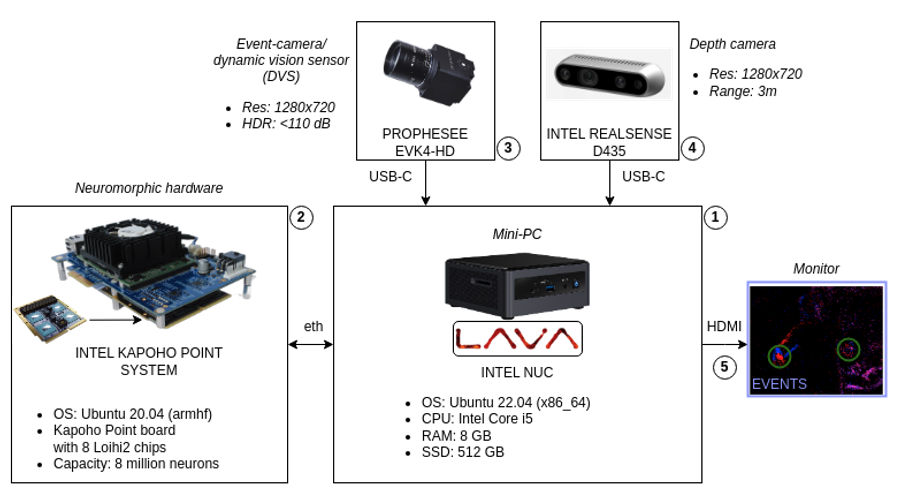
This review details a heterogeneous computing platform integrating neuromorphic hardware with GPUs for low-latency, energy-efficient cognitive AI in robotics, demonstrated through an interactive musical performance with a humanoid robot.
Achieving truly responsive and intelligent robotics demands overcoming the limitations of conventional computing architectures. This paper, ‘Heterogeneous computing platform for real-time robotics’, introduces a novel system integrating neuromorphic hardware-specifically the Loihi2 processor and event-based vision-with the parallel processing power of GPUs to create a low-latency, energy-efficient platform for cognitive AI. We demonstrate this architecture’s capabilities through an interactive task involving a humanoid robot collaboratively performing music with a human, highlighting seamless data flow and synergistic processing. Could such heterogeneous designs unlock a new era of robotic autonomy and redefine human-robot interaction in complex, real-time environments?
The Inevitable Cascade: Reimagining Computation
Contemporary computing systems, while remarkably powerful, face inherent limitations in their ability to efficiently handle the escalating demands of artificial intelligence. The von Neumann architecture, foundational to most computers, processes information sequentially, requiring constant energy expenditure even when idle. This ‘memory bottleneck’ and continuous data transfer become particularly problematic with complex AI algorithms – such as those used in deep learning – that necessitate massive datasets and countless calculations. Consequently, scaling these systems to achieve true artificial general intelligence is increasingly constrained by power consumption and heat dissipation. The energy demands not only limit the deployment of AI on resource-constrained devices-like smartphones or embedded sensors-but also pose significant environmental concerns due to the growing energy footprint of data centers and AI infrastructure.
Spiking Neural Networks represent a departure from traditional artificial neural networks by more closely emulating the way biological brains process information. Instead of continuously transmitting signals, SNNs communicate via discrete spikes – brief electrical pulses – triggered only when a neuron reaches a certain threshold. This event-driven computation drastically reduces energy consumption, as processing occurs only when necessary, unlike the constant activity in conventional systems. Each spike acts as a computational step, and the timing of these spikes carries information, allowing SNNs to potentially encode and process temporal data with greater efficiency. This biomimicry doesn’t just offer power savings; it unlocks the possibility of creating AI systems capable of learning and adapting in a more nuanced and brain-like manner, potentially enabling advanced pattern recognition and real-time decision-making with significantly reduced energy footprints.
The pursuit of low-power artificial intelligence is rapidly converging on bio-inspired computing, specifically Spiking Neural Networks. Unlike conventional systems that consume energy with every clock cycle, SNNs operate on a demand-driven basis, processing information only when a neuron ‘fires’ a spike – mirroring the efficiency of the biological brain. This event-driven architecture drastically reduces energy consumption, making SNNs ideally suited for deployment on edge devices – from smartphones and wearables to autonomous sensors – where battery life and thermal constraints are paramount. Beyond individual devices, the scalability of low-power SNNs promises a pathway toward sustainable computing, lessening the environmental impact of increasingly complex AI applications and fostering a future where intelligent systems operate with minimal energy expenditure.
![The Spaun 2.0 model architecture was distributed across 7 GPUs, with each red box representing a component executing on a dedicated processing unit (based on Choo [2018]).](https://arxiv.org/html/2601.09755v1/images/SPAUN_gpu.png)
Accelerating the Inevitable: Hardware for Neuromorphic Systems
Intel’s Loihi2 is a second-generation neuromorphic research chip designed to accelerate Spiking Neural Networks (SNNs) and facilitate real-time processing of complex data streams. Building on the original Loihi, Loihi2 features an increased neuron count, enhanced on-chip learning capabilities, and improved programmability. The architecture utilizes asynchronous spiking neurons and programmable synaptic plasticity, allowing for energy-efficient computation inspired by biological neural systems. Loihi2 is fabricated on Intel’s 7nm process technology and supports a significantly larger network scale compared to its predecessor, enabling the implementation and testing of more sophisticated SNN models for applications including pattern recognition, optimization, and robotics.
Heterogeneous computing architectures leveraging Intel’s Loihi2 alongside GPUs such as those found in NVIDIA DGX A100 systems provide complementary strengths for neuromorphic workloads. Loihi2 efficiently executes spiking neural networks (SNNs) due to its asynchronous, event-driven processing, minimizing energy consumption for inference tasks. However, training large-scale SNNs remains computationally intensive. By offloading the training phase to the massively parallel processing capabilities of GPUs, and then deploying the trained model onto Loihi2 for inference, these systems optimize both performance and energy efficiency. This division of labor allows for the practical implementation of complex SNNs, such as the 6.5 million neuron Spaun 2.0 model, and demonstrably reduces energy consumption – achieving a 1/10th reduction compared to equivalent implementations on SpiNNaker2 using solely GPU-based resources.
The integration of Intel’s Loihi 2 neuromorphic processor with conventional GPU systems enables the execution of substantially larger spiking neural network (SNN) models than previously possible. Specifically, the 6.5 million neuron Spaun 2.0 model has been successfully trained and deployed using this heterogeneous architecture. Comparative analysis against a SpiNNaker2 GPU-based implementation reveals a ten-fold reduction in energy consumption for equivalent computational tasks, demonstrating the potential for significantly more efficient SNN processing through this combined approach.
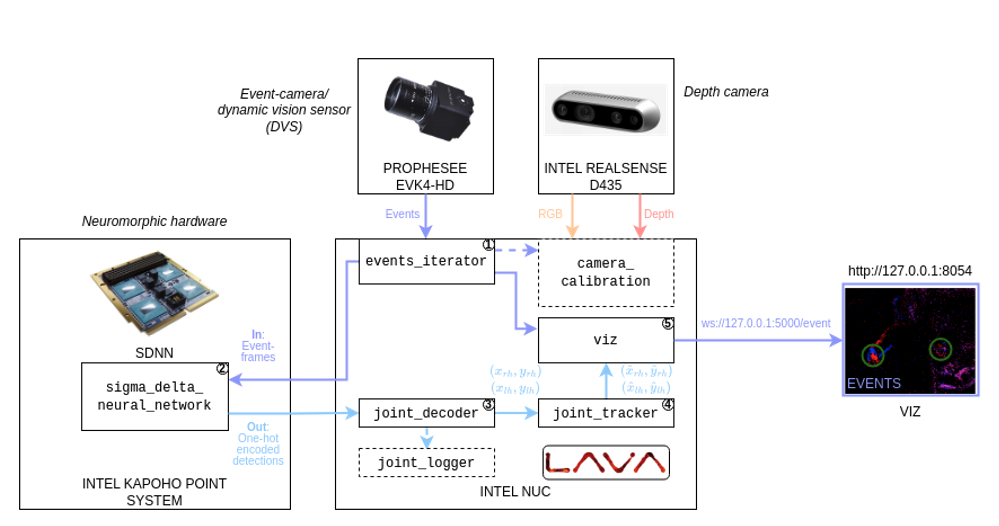
Embodied Intelligence: The Dance of Perception and Action
Ameca is a humanoid robot developed by Engineered Arts and utilized as a testbed for cutting-edge artificial intelligence research. Its fully articulated face and body, driven by pneumatic actuators, allow for a highly expressive range of non-verbal communication. Crucially, Ameca’s architecture is designed to facilitate the implementation and evaluation of advanced AI algorithms, specifically Spiking Neural Networks (SNNs). SNNs, inspired by biological neural processing, offer potential advantages in energy efficiency and speed compared to traditional Artificial Neural Networks, and Ameca provides a physical platform to demonstrate these capabilities in a realistic, interactive setting. The robot’s open software architecture enables researchers to integrate and test novel algorithms for perception, planning, and control, accelerating the development of more sophisticated and lifelike robotic systems.
Ameca utilizes Dynamic Vision Sensors (DVS) – also known as event cameras – in conjunction with Spiking Neural Networks (SNNs) to achieve efficient visual processing. Unlike traditional cameras that capture frames at fixed intervals, DVS detects individual pixel changes caused by movement, generating data only when an event occurs. This event-based approach drastically reduces data volume and power consumption. SNNs, inspired by the biological nervous system, process these asynchronous events with high speed and low latency, enabling Ameca to track hand movements in real-time. The combination of DVS and SNNs allows for visual processing speeds and efficiencies that exceed those of conventional vision systems, closely mimicking the responsiveness of biological vision.
Ameca achieves fluid human-robot interaction by integrating event-based perception from Dynamic Vision Sensors with several AI models. Visual data is processed in real-time and fed into the LLaMA large language model, enabling contextual understanding and response generation. Audio input is handled via OpenAI’s Whisper speech recognition, which transcribes spoken language into text for processing. Ameca then utilizes Amazon Polly for text-to-speech synthesis, generating spoken responses. This combination of technologies was demonstrated through Ameca’s ability to interact with a Theremin, responding to musical cues and human direction with appropriate vocalizations and movements.

The Inexorable Shift: Towards Sustainable Supercomputing
The relentless advancement of artificial intelligence is creating an unprecedented demand for computational power, a trend that necessitates a fundamental shift towards sustainable supercomputing practices. Traditional computing methods are increasingly energy intensive, posing significant environmental challenges and economic burdens. Researchers and engineers are now focused on minimizing the carbon footprint of AI by prioritizing energy efficiency at every level of hardware and software design. This includes exploring novel chip architectures, optimizing algorithms for reduced computational load, and adopting innovative cooling solutions. Ultimately, the future of AI is inextricably linked to its sustainability; continued progress depends on developing intelligent systems that are not only powerful but also environmentally responsible, ensuring that the benefits of this technology can be realized without compromising the planet’s resources.
Liquid cooling systems are rapidly becoming indispensable for modern supercomputing, directly addressing the escalating energy demands of advanced artificial intelligence. Unlike traditional air cooling, which struggles to dissipate heat from densely packed processors, liquid cooling utilizes a fluid-often water or a specialized dielectric fluid-to absorb heat directly from components. This method boasts significantly higher thermal conductivity, allowing processors to operate at higher frequencies and achieve greater computational performance without overheating. The increased efficiency translates directly into lower energy consumption, reducing operational costs and minimizing the environmental footprint of these powerful machines. Furthermore, the compact nature of liquid cooling solutions enables higher component densities, paving the way for even more powerful and sustainable supercomputers capable of driving innovation in fields like climate modeling, drug discovery, and the development of next-generation AI.
The pursuit of sustainable supercomputing isn’t merely about reducing a carbon footprint; it fundamentally enables the realization of Cognitive Cities – intricately networked urban ecosystems driven by artificial intelligence. These aren’t simply ‘smart’ cities adding technology to existing infrastructure, but rather responsive, self-optimizing systems where AI manages resources – energy grids, traffic flow, waste disposal – with unprecedented efficiency. By minimizing the energy demands of the computational power that underpins this intelligence, cities can drastically reduce operational costs and environmental impact. This creates a positive feedback loop: lower energy consumption allows for greater computational capacity, fostering more complex and effective AI solutions, ultimately leading to more livable, resilient, and sustainable urban environments. The potential extends to predictive maintenance of infrastructure, optimized public transportation, and even personalized services tailored to citizen needs, all powered by an intelligent core demanding less from the planet.
Expanding the Horizon: Frontiers of Neuromorphic Intelligence
SpiNNaker2 represents a significant advancement in the field of neuromorphic computing, offering a dedicated platform for the simulation and analysis of massively parallel, spiking neural networks. This architecture departs from traditional von Neumann computing by mimicking the asynchronous, event-driven processing of the brain, potentially unlocking greater energy efficiency and faster computation for specific tasks. Crucially, SpiNNaker2’s 19MB of on-chip static random-access memory (SRAM) provides a localized memory resource, dramatically reducing the bottlenecks associated with off-chip data transfer – a major limitation in conventional systems. This localized memory allows for rapid communication between artificial neurons, facilitating the exploration of complex network dynamics and enabling the study of large-scale brain models with unprecedented detail. The platform’s capabilities are fostering new insights into the fundamental principles of brain-inspired computation and paving the way for the development of next-generation artificial intelligence systems.
Dynamic Neural Fields (DNF) represent a powerful shift in computational modeling, enabling researchers to move beyond traditional artificial neural networks and explore more biologically plausible cognitive architectures. These frameworks utilize continuous, distributed representations – akin to how the brain processes information – to model complex phenomena such as visual perception and information filtering. Unlike discrete, layer-based deep learning, DNF operates on fields of activity, allowing for the representation of spatial relationships and contextual information with greater fidelity. This approach allows for efficient processing of sensory input, robust pattern recognition, and adaptive filtering of irrelevant data, mimicking the brain’s ability to prioritize salient features in a dynamic environment. The continuous nature of DNF also opens avenues for modeling temporal dynamics and learning continuous control policies, potentially leading to more adaptable and efficient artificial intelligence systems.
Deep Spiking Neural Networks represent a compelling evolution in artificial intelligence, forging a path beyond the limitations of traditional deep learning architectures. These networks capitalize on the energy efficiency inherent in spiking neural networks – systems that more closely mimic the biological brain – while retaining the powerful representational capacity of deep learning’s multiple layers. Unlike conventional AI, which relies on continuous values, DSNNs operate with discrete, asynchronous spikes of information, dramatically reducing computational demands and enabling potential deployment on low-power hardware. This fusion allows for the processing of complex data, such as images and speech, with significantly reduced energy consumption and latency, opening doors to real-time applications in robotics, edge computing, and neuromorphic computing systems. The architecture promises not only more efficient AI but also potentially more robust and adaptable intelligence, capable of learning and responding to stimuli in a manner closer to biological systems.
The pursuit of a heterogeneous computing platform, as detailed in this work, echoes a fundamental principle of resilient systems. Just as a diversified architecture mitigates single points of failure, so too does the integration of neuromorphic hardware with conventional GPUs offer robustness against the limitations of either alone. Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” This sentiment resonates with the design of this cognitive AI platform; it isn’t about creating intelligence ex nihilo, but rather about efficiently executing known algorithms-in this case, spiking neural networks-through a carefully orchestrated computational ecosystem. The platform’s low-latency performance, demonstrated through the interactive musical performance, speaks to a system engineered for graceful aging – adapting and responding effectively over time.
What’s Next?
The presented architecture, while demonstrating a compelling integration of disparate computational substrates, merely delays the inevitable entropy. Low latency is not permanence; it is a temporary reprieve from the tax every request must pay. The successful musical performance, though a satisfying proof-of-concept, highlights the core challenge: scaling these cognitive architectures beyond curated demonstrations. True robustness demands a system capable of gracefully degrading under unpredictable conditions-a capacity not yet demonstrated.
Further inquiry must address the limitations inherent in mapping brain-inspired algorithms onto silicon. The energy efficiency gains, while promising, are predicated on specialized hardware. The long-term viability of neuromorphic computing hinges not just on performance metrics, but on the development of compilers and software tools capable of abstracting away the underlying hardware complexities. The current reliance on bespoke implementations represents a significant bottleneck.
Ultimately, the pursuit of cognitive architectures is an exercise in managing complexity. Stability is an illusion cached by time. The next phase of research should focus less on achieving peak performance in controlled environments and more on building systems capable of adapting, learning, and surviving in the face of inherent uncertainty-acknowledging that every computational flow is, fundamentally, a temporary structure against the current.
Original article: https://arxiv.org/pdf/2601.09755.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- How to find the Roaming Oak Tree in Heartopia
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Best Arena 9 Decks in Clast Royale
- ATHENA: Blood Twins Hero Tier List
- Clash Royale Furnace Evolution best decks guide
- Brawl Stars December 2025 Brawl Talk: Two New Brawlers, Buffie, Vault, New Skins, Game Modes, and more
- How To Watch Tell Me Lies Season 3 Online And Stream The Hit Hulu Drama From Anywhere
2026-01-16 09:05