Author: Denis Avetisyan
A new approach focuses on capturing user intent and aesthetic preferences, rather than strict photorealism, to create more compelling image layouts.

Researchers introduce StickerNet, a deep learning model trained on user edits to predict sticker placement and style for expressive image composition.
While image composition is traditionally framed as achieving photorealistic integration, modern visual content creation often prioritizes artistic expression and social engagement over strict realism. This motivates the work ‘Beyond Realism: Learning the Art of Expressive Composition with StickerNet’, which introduces a new formulation of image composition focused on capturing user intent and stylistic diversity. The authors present StickerNet, a deep learning framework trained on a large-scale dataset of authentic user edits, effectively predicting sticker placement, scale, and opacity. Could learning directly from creative human behavior unlock a new generation of visual understanding systems that prioritize expressiveness over purely realistic constraints?
Beyond Mimicry: Unveiling Expressive Intent in Image Composition
Historically, image composition techniques have prioritized the accurate replication of visual reality – a pursuit of photorealism. This emphasis, while technically impressive, often overshadows the crucial role of artistic intent and personal expression. Conventional methods frequently operate under the assumption that a ‘good’ composition faithfully reproduces a scene as the human eye perceives it, neglecting the power of deliberate stylistic choices to convey emotion, highlight specific themes, or simply reflect the creator’s unique perspective. Consequently, images produced under these paradigms can feel technically proficient yet emotionally sterile, lacking the subjective impact that arises when aesthetic choices are driven by a desire to communicate something beyond mere visual accuracy. This prioritization of fidelity over feeling represents a significant limitation in the realm of image creation and manipulation.
Existing image manipulation techniques frequently prioritize replicating visual realism, inadvertently overlooking the subtle but significant role of expressive composition. These methods often treat embellishments – such as selective blurring, exaggerated color palettes, or symbolic object placement – as distortions to be minimized, rather than as deliberate artistic choices conveying deeper meaning. Consequently, current systems struggle to understand or recreate images where aesthetic impact and emotional resonance are paramount, failing to recognize that alterations can powerfully shape narrative and intent beyond mere visual accuracy. This limitation highlights a need for algorithms capable of interpreting and generating imagery that prioritizes artistic expression, effectively moving beyond faithful reproduction towards a more nuanced understanding of visual communication.
The limitations of current image manipulation techniques have spurred a growing need for systems that move beyond simple realism and embrace aesthetic impact. Existing tools often prioritize accurate visual reproduction, leaving little room for users to intentionally shape an image’s emotional resonance or artistic style. Consequently, research is increasingly focused on developing interfaces and algorithms that empower individuals to directly express their creative intent, allowing for embellishments and stylistic choices that transcend photorealistic accuracy. This shift demands a new generation of image editors capable of interpreting and realizing subjective aesthetic goals, ultimately transforming image manipulation from a technical process into a truly creative endeavor and unlocking personalized visual storytelling.

StickerNet: A Two-Stage System for Compositional Understanding
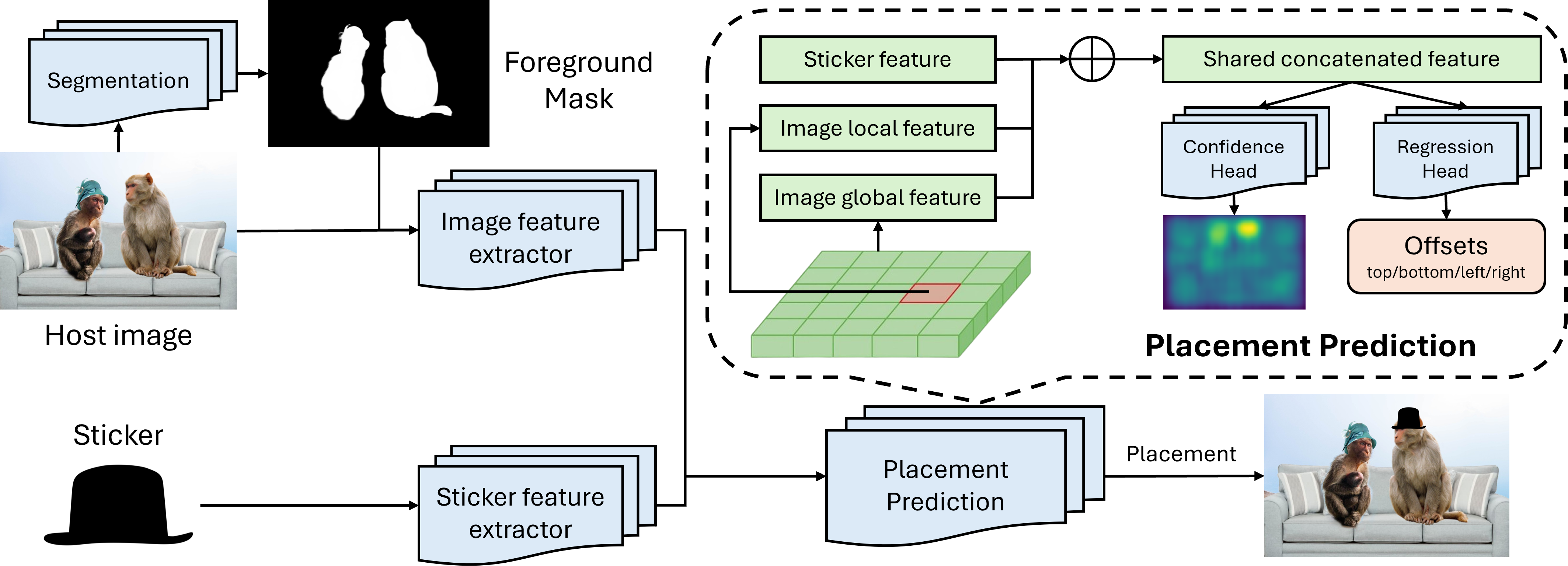
StickerNet utilizes a two-stage process for image composition: type classification followed by element placement prediction. Initially, the model determines whether the desired composition is a filter or a sticker application. This classification step informs the subsequent stage, which predicts the coordinates and scale of the chosen element(s) within the image. This staged approach allows the model to first establish the overall compositional goal before addressing the specific spatial arrangement, contributing to efficient and accurate image manipulation.
StickerNet’s architecture utilizes two distinct deep learning components to separate the concepts of stylistic application and spatial arrangement. The Type Classifier, a convolutional neural network, determines whether the desired modification is a filter or a sticker, effectively categorizing the intended aesthetic. Following type classification, the Placement Predictor, also a convolutional neural network, focuses solely on predicting the bounding box coordinates for element placement within the image. This decoupling allows the model to independently learn and control both the visual style and the geometric layout, improving compositional flexibility and enabling targeted modifications without conflating aesthetic and spatial attributes.
The StickerNet architecture’s modularity enables independent manipulation of aesthetic and spatial image characteristics. The Type Classifier controls stylistic elements – effectively the ‘feel’ of the image – by determining whether a filter or sticker composition is applied. Simultaneously, the Placement Predictor governs the visual impact by defining the location and arrangement of elements within the image. This separation allows users to adjust stylistic preferences without altering the composition’s layout, and vice-versa, providing granular control over the final output and facilitating experimentation with different visual effects.

Dissecting the Mechanics: Feature Extraction and Loss Optimization
Both the Type Classifier and Placement Predictor models employ a ResNet-50 architecture for initial feature extraction from input images. ResNet-50, a 50-layer residual network, provides a balance between model depth and computational efficiency, allowing for robust feature representation with a manageable parameter count. This convolutional neural network is pre-trained on ImageNet, enabling transfer learning and accelerating convergence during training on the target dataset. The extracted features serve as input to subsequent layers responsible for classification and regression tasks within each respective predictor.
The Placement Predictor utilizes DeepLabV3, a convolutional neural network, to generate pixel-level foreground masks from input images. These masks delineate the boundaries of objects within the scene, providing the model with detailed information about object shape and location. This precise segmentation is critical for accurate element placement, as it allows the model to understand which areas of the image are available for placing new objects and avoids occlusion or unrealistic overlap. The DeepLabV3 architecture employs atrous convolution to effectively capture multi-scale contextual information, enhancing the accuracy of the generated masks and ultimately improving the quality of element placement within the scene.
The training process for both the Type Classifier and Placement Predictor is optimized using the Distance-IoU (DIoU) Loss function. Evaluations against baseline loss functions indicated that DIoU Loss consistently achieved the highest Intersection over Union (IoU) scores. This quantitative result was further corroborated by findings from a user study, establishing a strong correlation between the DIoU Loss optimization and perceived visual quality, suggesting the model learns to predict bounding boxes aligned with human expectations of element placement and object recognition. The $DIoU$ Loss calculates the loss based on the distance between the center points of the bounding boxes and the overlap area, providing a more robust gradient for optimization compared to traditional IoU-based losses.
Validating the Approach: Outperforming Established Benchmarks
To rigorously assess its capabilities, StickerNet underwent comparative evaluation against a spectrum of established image composition models, including the sophisticated GracoNet, and simpler, more conventional approaches like random sticker placement and center-based positioning. This multifaceted comparison wasn’t merely about surpassing basic techniques; it aimed to demonstrate StickerNet’s ability to rival and exceed the performance of current state-of-the-art systems designed for similar tasks. By benchmarking against both complex and rudimentary methods, researchers could accurately gauge the true innovation and effectiveness of StickerNet’s compositional algorithms, establishing a clear understanding of its strengths within the field of automated image editing.
A crucial element in evaluating the authenticity of StickerNet’s compositions involved establishing a robust baseline derived from genuine user behavior. The research team incorporated ‘user history’ – data reflecting actual sticker placements made by individuals – as a comparative standard. This approach moved beyond simplistic random or centrally-focused placements, instead offering a realistic representation of how people naturally arrange stickers within images. By benchmarking against these original user edits, the study aimed to determine whether StickerNet could not only generate aesthetically pleasing compositions, but also align with the intuitive aesthetic preferences demonstrated by real-world users, providing a more meaningful measure of success beyond purely algorithmic optimization.
A comprehensive user study rigorously evaluated StickerNet’s performance in image composition, revealing a substantial advantage over existing methods. The system achieved an overall success rate exceeding 70%, measured by user ratings of ‘Acceptable’ or ‘Perfect’ compositions, definitively outperforming simpler baselines like random or center placement, as well as more sophisticated models such as GracoNet. Notably, StickerNet attained an 86.8% ‘Perfect Rating’ – a significantly higher score than any other tested approach – demonstrating its capacity to generate compositions that closely align with user aesthetic preferences and establishing it as a leading solution for automated image editing.

Beyond Automation: Envisioning the Future of Creative Expression
StickerNet represents a significant step towards understanding and replicating human creativity in image composition. The system doesn’t rely on explicitly defined aesthetic rules, but instead learns directly from the editing behaviors of real users. By analyzing vast datasets of image manipulations – where and how users place stickers, filters, and other elements – StickerNet identifies subtle, often unconscious, preferences for balance, color harmony, and visual storytelling. This allows it to capture complex creative patterns that would be difficult to codify manually, effectively distilling a collective understanding of “good design” from observed practice. The result is a system capable of not just mimicking existing styles, but also anticipating user intent and suggesting compositions aligned with individual aesthetic sensibilities, opening possibilities for truly personalized image editing experiences.
The development of systems like StickerNet heralds a shift towards truly personalized image editing experiences. Rather than relying on generic filters or pre-defined templates, future tools will analyze a user’s past editing choices – the stickers they favor, the layouts they select, and the overall aesthetic they gravitate towards – to anticipate their creative intent. This proactive approach allows the software to suggest compositions, even generate entire edits, that align with an individual’s established style, effectively becoming a digital assistant for creative expression. Such automation promises to not only streamline the editing process but also inspire users by offering novel variations and possibilities based on their unique preferences, potentially unlocking new levels of creative output and accessibility.
The principles underpinning StickerNet, initially demonstrated through automated image composition, are poised for broader application within the realm of creative automation. Researchers envision extending the model’s capabilities to more complex tasks like video editing, where aesthetic preferences regarding pacing, transitions, and visual effects can be learned from user behavior. Similarly, StickerNet’s capacity to discern and replicate creative patterns holds promise for graphic design, potentially enabling the automated generation of layouts, color palettes, and typography choices aligned with individual stylistic inclinations. This expansion isn’t merely about replicating existing designs; it aims to empower users with tools that proactively suggest and refine creative options, effectively pushing the boundaries of what’s achievable through automated assistance and ushering in a new era of personalized content creation.

The pursuit of expressive composition, as detailed in this work, hinges on discerning underlying patterns within user-generated edits. This aligns perfectly with David Marr’s assertion that “vision is not about constructing a complete 3D model of the world, but about creating representations that are useful for action.” StickerNet, through its data-driven approach to placement prediction, doesn’t aim for photorealistic accuracy. Instead, it focuses on learning the useful patterns-the aesthetic preferences-embedded within the training data. The model effectively captures how users prioritize visual impact over strict realism, building a representation of ‘good composition’ directly from observed behavior. This mirrors Marr’s emphasis on computational pragmatism – understanding what the system does, rather than merely what it represents.
Beyond the Sticker
The pursuit of ‘expressive composition’ exposes a curious tension. StickerNet demonstrates a capacity to predict aesthetic choices, effectively mimicking user intent. However, the model inherently learns from existing patterns. This begs the question: can a system truly innovate in visual language, or is it destined to refine existing tropes? The elegance of the approach lies in its data-driven nature, yet this also represents a fundamental limitation – novelty remains elusive without a mechanism to generate truly unexpected, yet coherent, compositions.
Future work might explore incorporating elements of computational creativity, perhaps through generative adversarial networks trained not on imitation, but on the deliberate disruption of established visual norms. A further refinement could involve a more nuanced understanding of why users choose specific sticker placements and styles – moving beyond ‘what’ to address the underlying cognitive and emotional drivers of aesthetic preference. This demands exploring methods to quantify subjective qualities like ‘playfulness’ or ‘seriousness’.
Ultimately, the success of StickerNet is not simply in its predictive accuracy, but in its implicit acknowledgment that visual communication is, at its core, a form of pattern recognition. The next challenge is to understand how to introduce controlled ‘noise’ into those patterns, allowing for the emergence of genuinely expressive and innovative visual forms.
Original article: https://arxiv.org/pdf/2511.20957.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Brawl Stars December 2025 Brawl Talk: Two New Brawlers, Buffie, Vault, New Skins, Game Modes, and more
- Mobile Legends: Bang Bang (MLBB) Sora Guide: Best Build, Emblem and Gameplay Tips
- Clash Royale Best Boss Bandit Champion decks
- Best Hero Card Decks in Clash Royale
- Call of Duty Mobile: DMZ Recon Guide: Overview, How to Play, Progression, and more
- Clash Royale December 2025: Events, Challenges, Tournaments, and Rewards
- Best Arena 9 Decks in Clast Royale
- Clash Royale Best Arena 14 Decks
- Clash Royale Witch Evolution best decks guide
- Brawl Stars December 2025 Brawl Talk: Two New Brawlers, Buffie, Vault, New Skins, Game Modes, and more
2025-11-28 21:41