Author: Denis Avetisyan
A new decoding strategy focuses on exploring less probable, but potentially more accurate, options to improve the quality and reliability of generated text.
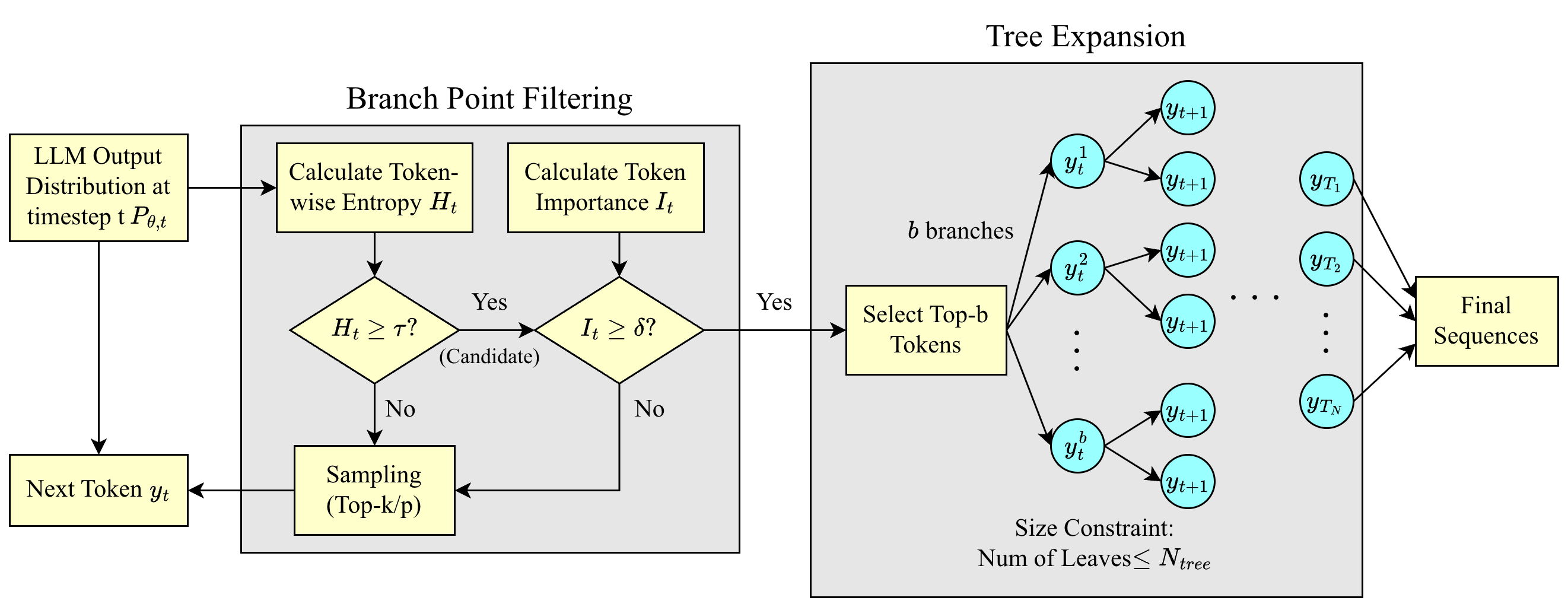
Entropy-Tree utilizes entropy-guided tree search to enhance both the accuracy and calibration of large language model outputs by prioritizing high-entropy tokens.
Despite the strong reasoning capabilities of large language models, current decoding strategies often fall into the trap of either exhaustive, yet inefficient, exploration or redundant sampling. To address this, we introduce Entropy-Tree-a novel tree-based decoding method detailed in ‘Entropy-Tree: Tree-Based Decoding with Entropy-Guided Exploration’, which leverages model entropy to intelligently guide search and prioritize exploration at points of genuine uncertainty. This approach demonstrably improves both the accuracy and calibration of generated outputs across diverse reasoning tasks, achieving superior performance compared to existing methods like multi-chain sampling. Could Entropy-Tree represent a crucial step towards more reliable and trustworthy large language model outputs?
The Fragility of Deterministic Decoding
Despite their impressive capabilities, many large language models frequently employ a technique called Greedy Decoding, wherein each word in a generated response is selected solely based on its immediate probability, often resulting in outputs that lack nuance and appear remarkably deterministic. This approach, while computationally efficient, prioritizes local optimization over global coherence, making the models susceptible to generating predictable and, at times, illogical sequences. The consequence is a fragility in their reasoning; slight alterations in the input prompt can dramatically shift the output, revealing a limited capacity for genuine understanding and creative problem-solving. Essentially, Greedy Decoding trades flexibility for speed, producing responses that, while grammatically correct, often fail to reflect the full spectrum of possible, and potentially more insightful, solutions.
The limitations of current large language models often stem from a failure to acknowledge the uncertainty intrinsic to complex reasoning. While these models excel at predicting the most probable continuation of a sequence, they struggle when faced with ambiguity or incomplete information, treating single predictions as definitive truths. This approach bypasses the nuanced probabilistic nature of real-world problem-solving, where multiple valid solutions or interpretations frequently exist. Consequently, the resulting outputs can be brittle and unreliable, particularly in tasks requiring creative synthesis or judgment under conditions of incomplete knowledge; the models lack a mechanism to express or explore the range of plausible responses, instead committing to a single, potentially flawed, answer. This inability to represent epistemic uncertainty significantly hinders the deployment of these models in critical applications where robustness and trustworthiness are paramount.
While techniques like Beam Search and Self-Consistency represent advancements over simple Greedy Decoding, they still fall short in fully exploring the solution space inherent in complex reasoning. Beam Search, by maintaining a limited number of promising candidates, risks prematurely discarding potentially valuable, yet initially less probable, paths. Self-Consistency, which samples multiple solutions and aggregates them, offers a broader perspective, but its effectiveness is constrained by the number of samples taken – a trade-off between computational cost and comprehensive exploration. Neither method fully accounts for the inherent ambiguity often present in natural language or the multifaceted nature of logical deduction, leaving room for outputs that, while plausible, may not represent the full spectrum of viable answers or exhibit true robustness in the face of nuanced inputs. Consequently, these approaches often struggle with tasks demanding creative or unconventional solutions, highlighting the need for more expansive and adaptable decoding strategies.
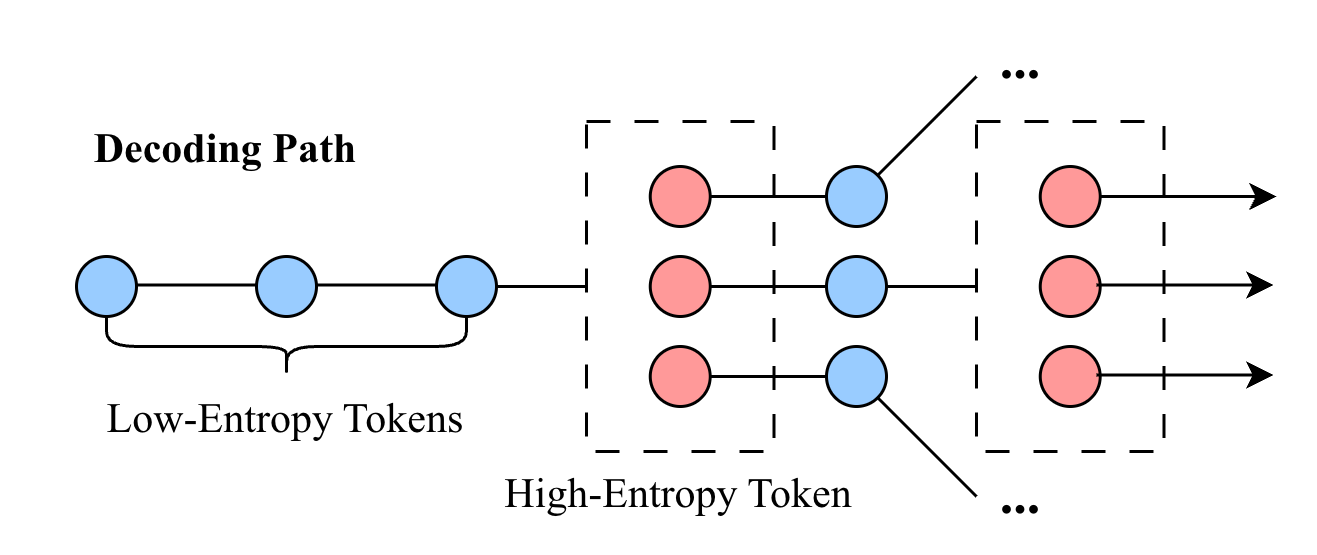
Branching Through Uncertainty: An Adaptive Approach
Entropy-Tree Decoding implements dynamic branching during text generation by identifying and acting upon tokens with high entropy, indicative of prediction uncertainty. This is achieved by calculating the entropy of the probability distribution derived from the model’s output logits for each token. When a token’s entropy exceeds a predefined threshold, the decoding process forks, creating multiple parallel decoding paths, each representing a possible continuation. This contrasts with deterministic decoding methods that select a single, most probable token at each step, and allows the model to explore multiple potential reasoning paths based on areas of high uncertainty, ultimately improving robustness and the potential for generating diverse and accurate outputs.
Branching within Entropy-Tree Decoding utilizes the Self-Attention mechanism to evaluate relationships between tokens, enabling the model to identify and prioritize potential continuations based on contextual relevance. This process incorporates Model Logits – the pre-softmax output of the language model – as a direct measure of the model’s confidence in each token’s probability. By examining logit values across multiple possible next tokens, the algorithm constructs a branching tree where each branch represents a distinct reasoning path, effectively exploring a wider range of hypotheses beyond the single most probable sequence. The magnitude of the logit difference between the top candidates determines the degree of branching, allocating more exploration to tokens where the model exhibits greater uncertainty.
Entropy-Tree Decoding builds upon established decoding strategies such as Beam Search and Self-Consistency by introducing dynamic branching based on token entropy. While Beam Search maintains a fixed number of top-k candidates, and Self-Consistency samples multiple completions, Entropy-Tree Decoding adaptively expands the search space only when encountering high-uncertainty tokens. This allows for a more focused exploration of potentially valid reasoning paths, increasing the probability of identifying correct solutions without the computational cost of exhaustively exploring all possibilities. The method effectively addresses limitations in both Beam Search – which can prematurely discard viable paths – and Self-Consistency – which may not sufficiently prioritize promising continuations, resulting in a more robust and comprehensive solution space exploration.
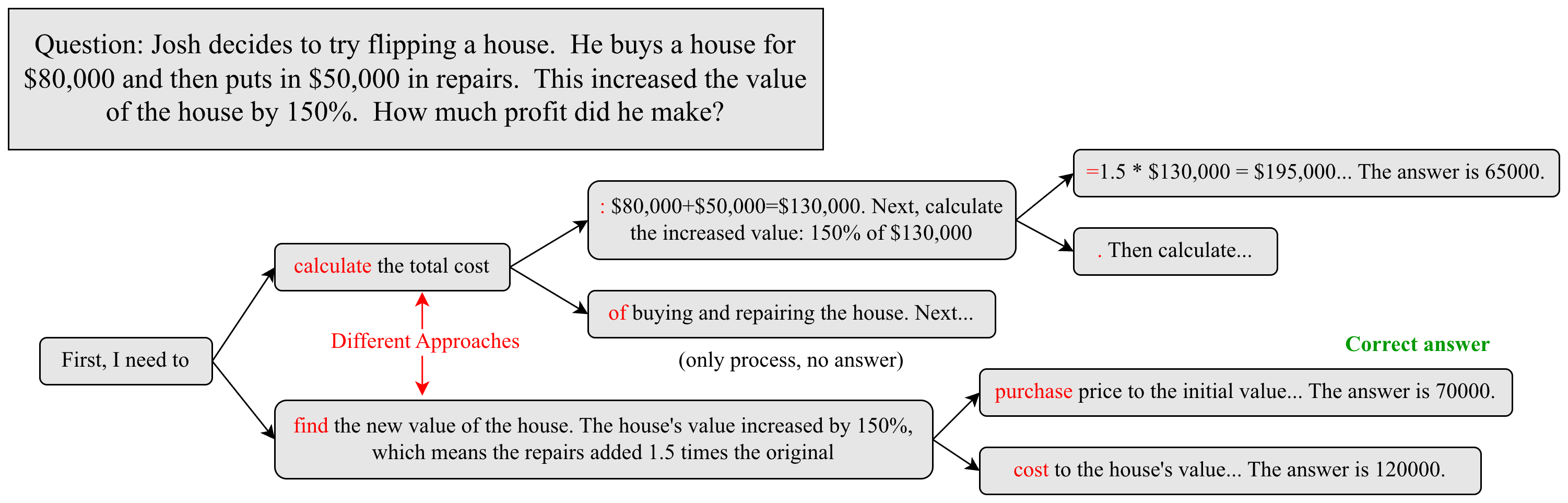
Quantifying the Unknown: A Deep Dive into Entropy
Token Entropy, calculated during autoregressive decoding, quantifies the probability distribution over the next token in a sequence. Specifically, it measures the uncertainty associated with the model’s prediction; a higher entropy value indicates a more uniform distribution and thus greater uncertainty. This metric is computed as [latex] -\sum_{i=1}^{V} p_i \log p_i [/latex], where [latex] p_i [/latex] represents the predicted probability of the i-th token in the vocabulary. High token entropy points during decoding are then flagged as potential branching opportunities, indicating locations where the model is less confident and alternative continuations should be explored to generate diverse and potentially more optimal outputs.
Predictive Entropy quantifies the uncertainty in a model’s output distribution, offering a comprehensive assessment of confidence beyond simple point predictions. This is often implemented using Bayesian Neural Networks (BNNs), which, instead of producing single weight values, output probability distributions over weights; this allows the model to express uncertainty in its parameters. Calculating the entropy of the predicted probability distribution – [latex]H(p) = – \sum_{i} p(i) \log p(i)[/latex] – provides a scalar value representing the degree of uncertainty; higher entropy indicates greater uncertainty. Unlike methods focused solely on decoding-time branching, Predictive Entropy considers the entire predictive distribution, reflecting inherent model ambiguity and enabling more robust uncertainty estimation for downstream tasks like active learning or anomaly detection.
Semantic Entropy builds upon traditional entropy measurements by factoring in semantic equivalence when evaluating solution diversity. Rather than treating all variations as equally uncertain, it assesses whether different outputs convey the same meaning. This is achieved by employing techniques that map outputs to a semantic space, allowing for the identification of solutions that are semantically similar but lexically distinct. By discounting these equivalent variations, Semantic Entropy focuses exploration on genuinely novel and potentially valuable solution paths, improving the efficiency of decoding algorithms and reducing redundancy in generated outputs. This refined measure provides a more accurate representation of true uncertainty, particularly in tasks where multiple phrasings can express the same intent.
Demonstrating Robustness: Empirical Validation and Performance Gains
Rigorous experimentation utilizing the Qwen2.5 series of language models establishes that Entropy-Tree Decoding represents a significant advancement over conventional decoding techniques. This method consistently delivers improved performance across a spectrum of generative tasks, demonstrably enhancing the quality and accuracy of outputs. The core of its success lies in a novel approach to sampling, prioritizing tokens based on predictive entropy and thereby steering the generation process toward more probable and coherent sequences. Results indicate that Entropy-Tree efficiently explores the solution space, requiring fewer samples to achieve comparable-and often superior-results to established methods like multi-chain sampling, signifying a substantial gain in computational efficiency and a step toward more practical large language model applications.
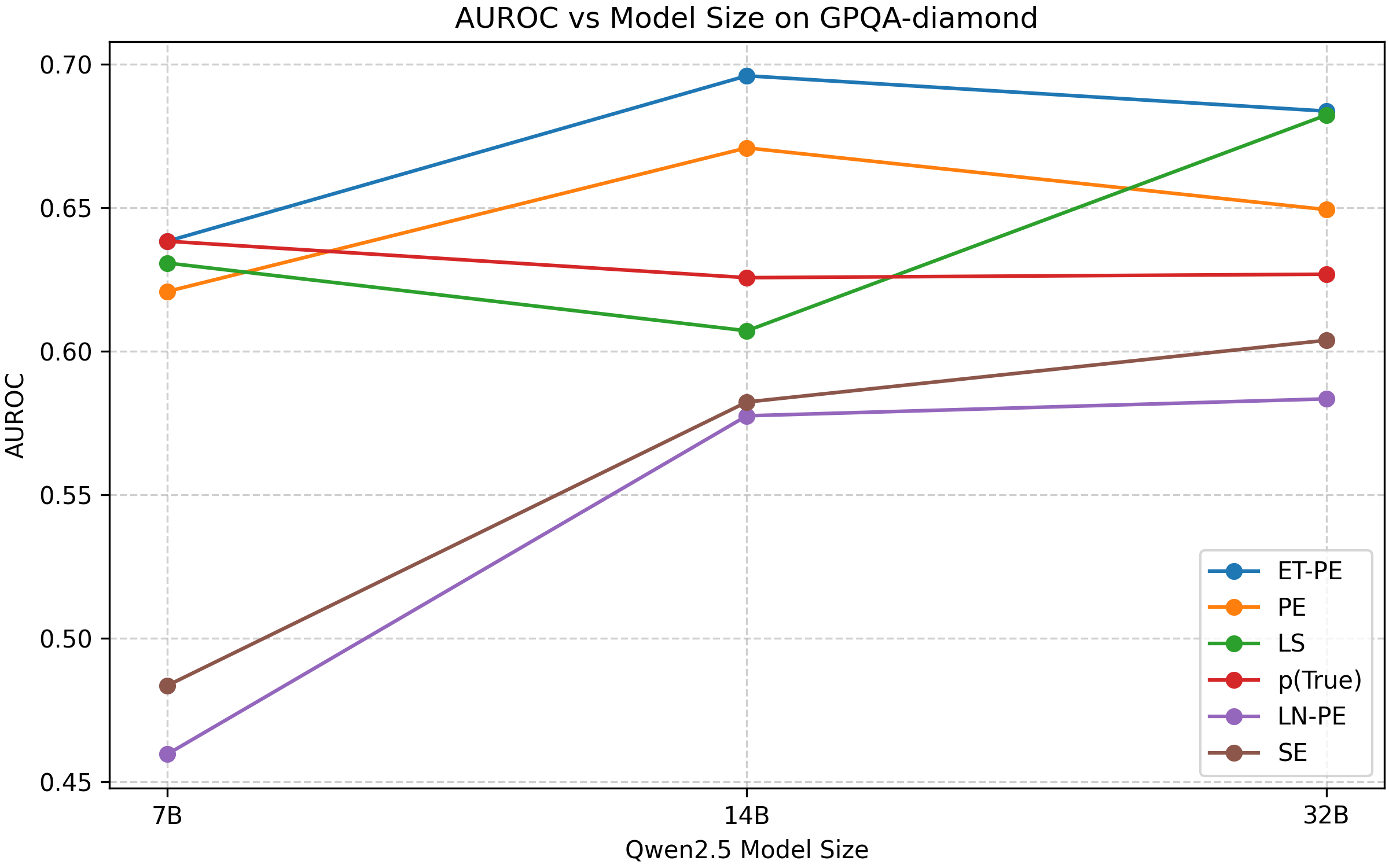
Rigorous evaluation using both Pass@K and Area Under the Receiver Operating Characteristic curve (AUROC) metrics demonstrates the efficacy of this novel decoding method in generating outputs that are not only more accurate but also better calibrated in their probabilistic predictions. Pass@K, which measures the probability of a correct answer appearing within the top K generated tokens, consistently showed improvements, indicating a higher likelihood of relevant responses. Simultaneously, high AUROC scores confirm the model’s ability to differentiate between correct and incorrect answers with greater confidence, suggesting a refined understanding of uncertainty. This combination of enhanced accuracy and well-calibrated probabilities is crucial for applications demanding reliable and trustworthy outputs, such as complex reasoning tasks and critical decision-making processes.
Evaluations reveal a significant efficiency advantage with Entropy-Tree Decoding; it achieves performance comparable to Multi-chain sampling while requiring substantially fewer computational resources. Specifically, the method consistently attains similar Pass@K scores – a metric assessing the probability of a correct prediction within the top K samples – using approximately two-thirds the sample size. This translates to a [latex]k[/latex] value of 13 for Entropy-Tree, compared to the [latex]k=20[/latex] required by Multi-chain sampling to reach equivalent accuracy. This reduction in necessary samples not only accelerates the decoding process but also lowers associated computational costs, making Entropy-Tree a particularly attractive option for resource-constrained environments or large-scale language generation tasks.
Investigations into predictive entropy reveal that the Entropy-Tree method consistently surpasses both semantic entropy and traditional predictive entropy approaches across a diverse range of language models and datasets. This superior performance stems from Entropy-Tree’s capacity to more accurately estimate the uncertainty inherent in sequential decoding, allowing it to prioritize the most promising continuation candidates. Unlike methods that rely on semantic similarity or conventional probability estimations, Entropy-Tree leverages the tree-like structure of potential outputs to dynamically refine its predictions, resulting in a more nuanced and reliable assessment of predictive entropy. Consequently, this optimized entropy calculation translates into demonstrably improved generation quality, as evidenced by gains in metrics like Pass@K and AUROC, showcasing its robustness and generalizability.
Rigorous evaluation reveals that Entropy-Tree Decoding consistently enhances the accuracy of language models across a diverse range of datasets and model architectures. Performance metrics, specifically Pass@10 and Pass@20, demonstrate a significant advantage for Entropy-Tree over Multi-chain sampling. These results indicate that Entropy-Tree not only generates more plausible outputs but also exhibits a heightened capacity to produce correct and relevant responses, even when evaluating only a limited number of generated samples. The consistent improvement across various conditions suggests that Entropy-Tree offers a robust and generalizable approach to enhancing the reliability and quality of language model outputs.
The pursuit of efficient decoding strategies, as demonstrated by Entropy-Tree, aligns with a fundamental principle of simplification. This work prioritizes exploration guided by information content-high-entropy tokens-rather than exhaustive search. It echoes Gauss’s sentiment: “If I have seen further it is by standing on the shoulders of giants.” Each refinement builds upon prior knowledge, but true progress demands distillation-removing the superfluous to reveal the underlying structure. The method’s focus on uncertainty quantification, achieved through targeted exploration, is not merely about generating text; it’s about revealing the inherent limitations of the model itself, a clarity often obscured by complexity.
Where Do the Branches Lead?
The pursuit of generative accuracy often obscures a more fundamental concern: knowing what is not known. Entropy-Tree represents a modest step toward acknowledging this uncertainty, directing search toward tokens where the model itself signals hesitation. This is not, however, a resolution. The quantification of uncertainty remains an imprecise science, and reliance on entropy as a proxy for genuine epistemic ambiguity carries its own risks. Future work must grapple with the limitations of this signal, perhaps by integrating alternative measures of model confidence or by explicitly modeling the source of the uncertainty.
A more pressing question concerns scalability. While the approach demonstrates improved calibration, the computational cost of tree search is inherently prohibitive. The benefits of exploring high-entropy branches diminish rapidly with depth. Thus, refinement of the search algorithm-pruning strategies, efficient parallelization, or approximations of the entropy function-will be crucial if Entropy-Tree is to move beyond a research curiosity.
Ultimately, the true value of this work may lie not in improved performance metrics, but in a shift in perspective. The goal is not simply to generate plausible text, but to generate honest text – outputs that reflect, rather than conceal, the inherent limitations of the underlying model. The branches of the Entropy-Tree, therefore, point toward a future where artificial intelligence is less concerned with appearing intelligent, and more concerned with acknowledging what it does not know.
Original article: https://arxiv.org/pdf/2601.15296.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Total Football free codes and how to redeem them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
- Gold Rate Forecast
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
2026-01-25 15:14