Author: Denis Avetisyan
New research reveals that expert data scientists aren’t defined by what tools they use, but by how they approach problem-solving within computational notebooks.
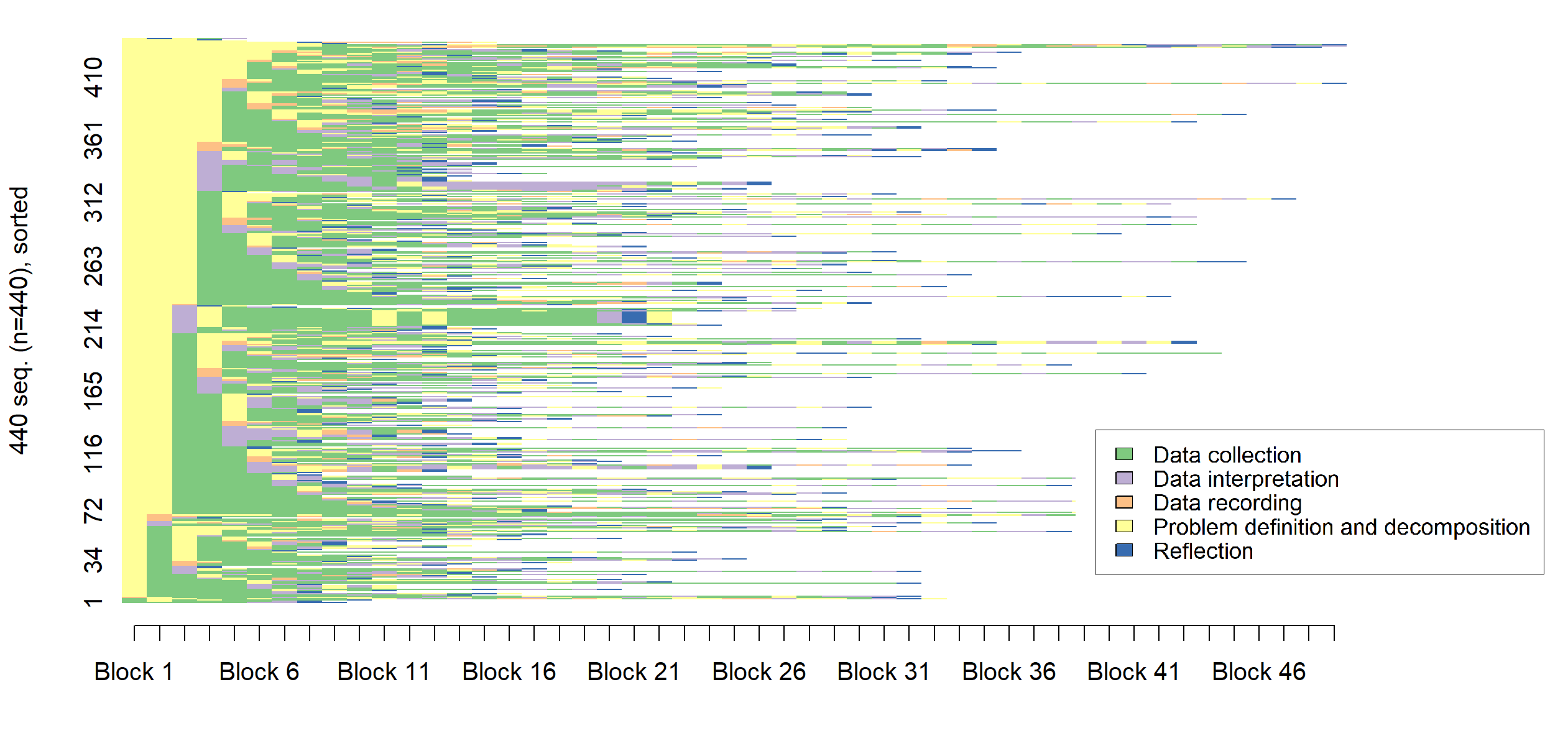
A sequence analysis of data science notebooks demonstrates that expertise is characterized by flexible iteration and efficient workflow, with critical implications for data science education in the age of generative AI.
Despite the growing demand for data science skills, understanding how expertise develops remains a persistent challenge. This study, titled ‘What makes an Expert? Comparing Problem-solving Practices in Data Science Notebooks’, addresses this gap by empirically comparing the problem-solving workflows of novices and experts through sequence analysis of Jupyter notebooks. Our findings reveal that expertise isn’t defined by fundamentally different phases of work, but rather by how those phases are enacted-specifically, through shorter, more iterative processes and efficient action sequences. As data science increasingly integrates with AI tools, can we leverage these insights to design educational approaches that prioritize flexible thinking over rote memorization?
The Illusion of Mastery: Why Skills Decay Faster Than They’re Taught
Contemporary data science curricula frequently emphasize the acquisition of specific tools and technologies-programming languages, statistical packages, and machine learning algorithms-often at the expense of cultivating fundamental problem-solving abilities. This emphasis, while intending to provide immediately applicable skills, inadvertently creates a demonstrable skills gap within the field. Many graduates, though proficient in technical execution, struggle when confronted with ill-defined, novel challenges that require critical thinking, creative decomposition, and the ability to formulate appropriate analytical strategies. The result is a workforce capable of applying solutions, but less adept at defining the problems themselves, hindering innovation and limiting the effective application of data science to increasingly complex real-world scenarios.
Effective data science transcends mere tool proficiency; the ability to dissect intricate challenges into smaller, resolvable components is paramount. A skilled data scientist doesn’t simply apply algorithms, but rather systematically deconstructs a broad problem – perhaps optimizing a supply chain or predicting customer behavior – into a series of focused analytical tasks. This decomposition requires identifying key variables, formulating testable hypotheses for each sub-problem, and selecting appropriate methodologies. Without this skill, even the most sophisticated techniques can be misapplied or yield irrelevant results, highlighting that a capacity for analytical dissection is a defining characteristic of impactful data science practice.
Contemporary challenges, ranging from climate modeling to pandemic response, rarely present as neatly defined problems amenable to straightforward algorithmic solutions. Instead, these issues are characterized by interconnectedness, incomplete data, and evolving circumstances, necessitating a departure from rigid, pre-defined analytical pathways. A truly effective data scientist must therefore embrace an iterative approach, skillfully framing initial hypotheses, rapidly prototyping solutions, and continuously refining models based on feedback and new information. This demands not just technical proficiency, but a capacity for flexible thinking – the ability to decompose complex systems, identify critical variables, and adapt strategies as understanding deepens and unforeseen complications arise. Ultimately, success hinges on a willingness to experiment, learn from failures, and view analysis not as a linear process, but as a continuous cycle of exploration and refinement.
Deconstructing the Workflow: A Necessary Illusion of Control
The Multi-Level Framework for data science proposes a decomposition of the workflow into three distinct levels of analysis. The overall process level provides a holistic view of the project lifecycle, from initial problem definition to final deployment and monitoring. Phase transitions represent the key shifts between stages – such as data acquisition, cleaning, modeling, and evaluation – and are characterized by specific criteria for advancement. Finally, the individual actions level details the granular tasks performed within each phase, including specific code implementations, data manipulations, and model parameter adjustments; this allows for detailed tracking and optimization of each step within the broader workflow.
The Multi-Level Framework emphasizes the interconnectedness of data handling stages within a data science project. Effective data collection practices, encompassing source identification and sampling methods, directly inform the subsequent data recording process, which prioritizes metadata documentation and data validation to ensure data integrity and reproducibility. This recorded data then undergoes insightful data interpretation, leveraging statistical analysis and domain expertise to identify patterns, draw conclusions, and ultimately support informed decision-making; the framework posits that deficiencies in any one of these areas – collection, recording, or interpretation – will negatively impact the overall project outcome and necessitate iterative refinement.
Reflection practices within the Multi-Level Framework involve systematic evaluation of each iterative cycle, focusing on data sources, methodologies, and model outputs. This isn’t limited to post-hoc analysis; rather, embedded reflection points occur at phase transitions and after individual actions, prompting consideration of assumptions, potential biases, and alternative approaches. Documented reflection facilitates knowledge transfer, allowing teams to learn from both successes and failures, and ensures continuous refinement of the solution by directly informing subsequent iterations and adjustments to the workflow. This process includes assessing the impact of each action on the overall project goals and identifying opportunities for optimization and improvement in data handling and analytical techniques.
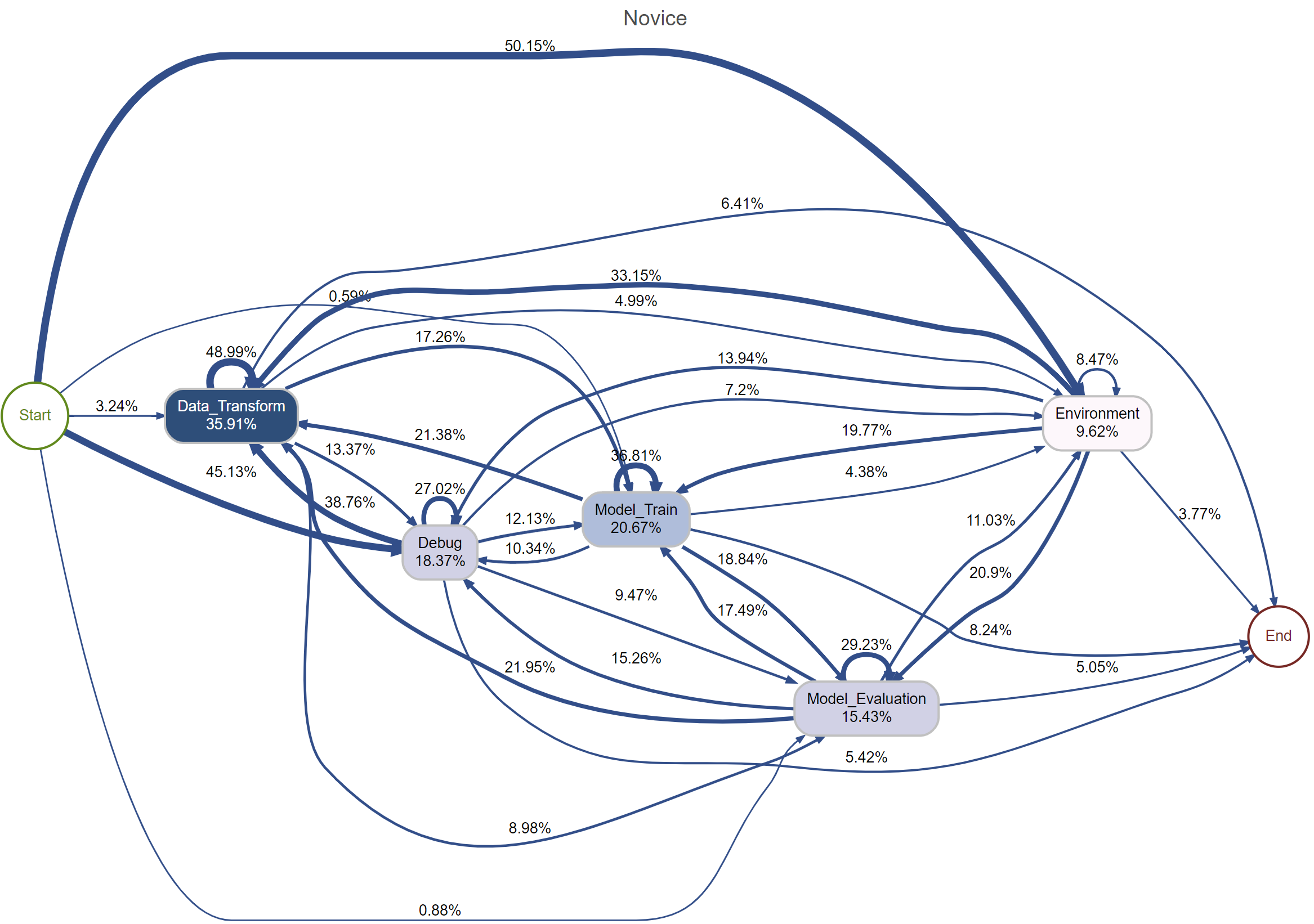
Expertise Under the Microscope: Patterns in a Sea of Code
Sequence analysis, when applied to Jupyter Notebooks, utilizes computational techniques to identify recurring patterns in the order of code cells and their associated actions within a data science workflow. This methodology treats each cell execution as an event in a sequence, allowing for the quantification of workflow characteristics such as length, branching, and iterative loops. By representing workflows as sequences, researchers can employ statistical methods – including cluster analysis and association rule mining – to compare the practices of different data scientists and uncover distinctions related to expertise or problem-solving strategies. The technique moves beyond simple code analysis to capture the process of data science, providing insights into how, not just what, practitioners accomplish.
The Code4ML dataset utilized in this analysis comprises 1,393 Jupyter Notebooks sourced from Kaggle competitions and datasets. Each notebook is labelled with the self-reported expertise level of its author – novice, competent, or expert – as indicated by their Kaggle profile. The dataset includes notebooks addressing a diverse range of machine learning tasks, including classification, regression, and natural language processing, providing a broad representation of typical data science workflows. Notebooks were filtered to include those with at least 10 executable cells to ensure sufficient workflow complexity for analysis, resulting in a final dataset of 1,047 notebooks suitable for sequence analysis and comparative study of workflow patterns.
Analysis of Jupyter Notebook workflows from the Code4ML dataset demonstrates statistically significant differences in structure between novice and expert data scientists. Experts consistently exhibit shorter workflows, indicating greater efficiency, and a more iterative approach characterized by frequent cycling between code execution and modification. While discernible patterns exist, the Silhouette Width score of 0.28 suggests that clustering of these workflows based solely on structural features is weak, implying overlap and a lack of strong separation between the groups. This indicates that workflow structure, while a differentiating factor, is not a definitive indicator of expertise level in isolation.
A Chi-squared test was conducted to determine the relationship between data science workflow structure and the expertise level of the practitioner. The analysis yielded a statistically significant result, [latex]χ² = 11.85[/latex], with a p-value of 0.0027. This indicates a less than 0.27% probability of observing the obtained association if there were no true relationship between workflow characteristics and expertise. Therefore, the data supports the conclusion that differences in workflow structure are significantly associated with varying levels of expertise in data science.
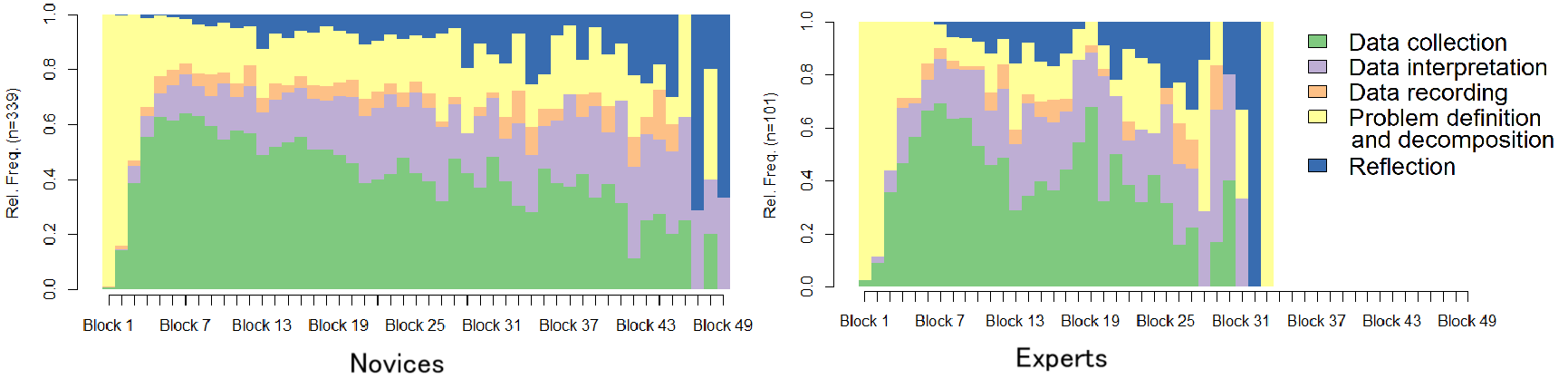
The Illusion of Progress: Why Iteration, Not Tools, Defines Mastery
Research consistently demonstrates that expert data scientists are not defined solely by technical proficiency, but crucially by their mastery of the iterative process. These professionals exhibit a remarkable capacity to continuously cycle through phases of hypothesis formation, model building, rigorous evaluation, and subsequent refinement – a dynamic workflow that prioritizes learning and adaptation over rigid adherence to pre-defined plans. This cyclical approach allows them to effectively navigate the inherent ambiguity of real-world datasets and complex problems, transforming initial explorations into robust and reliable solutions. The ability to embrace failure as a learning opportunity and iteratively improve models is, therefore, a hallmark of exceptional performance in the field, exceeding the importance of simply possessing knowledge of specific algorithms or tools.
Expert data scientists are distinguished not by exhaustive pre-planning, but by a fluid capacity to move between experimentation, refinement, and evaluation. These practitioners consistently formulate hypotheses, rapidly prototype solutions, and rigorously assess outcomes – not as sequential steps, but as interwoven phases of a continuous loop. This iterative approach allows for early detection of flawed assumptions and unexpected insights, fostering a dynamic process where each evaluation informs subsequent experimentation. Rather than adhering to rigid methodologies, these individuals prioritize learning from each cycle, skillfully adjusting their strategies and techniques to converge on optimal solutions – a characteristic that proves more predictive of success than any single technical skill.
The modern data science landscape increasingly prioritizes practical application over sheer technical knowledge. Expertise is no longer solely defined by familiarity with algorithms or programming languages, but by the capacity to integrate these tools within a dynamic, iterative process. Data scientists now excel by skillfully adapting their approach based on evolving data, unexpected results, and shifting project goals. This demands a flexible framework where experimentation, refinement, and continuous evaluation are central, allowing practitioners to navigate complexity and deliver impactful insights even when faced with imperfect or incomplete information. The ability to thoughtfully apply the right tool, at the right time, within this adaptive cycle, is becoming the hallmark of truly effective data science professionals.
The pursuit of defining ‘expertise’ feels perpetually Sisyphean. This research, charting problem-solving sequences in data science notebooks, confirms a grim suspicion: it’s not about arriving at a ‘correct’ path, but navigating the chaos. The study highlights how experienced practitioners iterate and adapt, a messy reality often obscured by idealized curricula. As Claude Shannon observed, “The most important thing in communication is to reduce uncertainty.” Ironically, data science expertise isn’t about eliminating uncertainty – it’s about becoming proficient at managing it, a skill generative AI may automate, but never truly replicate. Tests are, after all, a form of faith, not certainty.
What’s Next?
This work clarifies that data science proficiency isn’t about a prescribed sequence of operations, but rather a fluid adaptation to the inevitable chaos of real-world data. The observation feels almost…tautological. Yet, the continued pursuit of ‘best practices’ in education suggests the lesson hasn’t fully landed. The current excitement around generative AI tools adds another layer of complexity. These tools promise to automate ‘steps,’ but they also risk obscuring the crucial skill of knowing which steps are worth automating, and when to abandon them entirely.
Future research should resist the urge to define ‘expertise’ as simply ‘prompt engineering.’ It’s easy to imagine a future where notebooks are filled with flawlessly generated code that fails spectacularly in production. The real challenge lies in understanding how experts diagnose and recover from those failures – a messy, iterative process that’s difficult to capture in a tidy sequence analysis. A focus on error recovery, debugging strategies, and the ability to critically evaluate automated suggestions feels far more valuable.
Ultimately, this line of inquiry highlights a fundamental truth about complex systems: elegance is the enemy of robustness. If a data science workflow looks too perfect, it probably hasn’t met a real dataset yet. The field should embrace the inherent messiness, and focus on building learners who are comfortable navigating it.
Original article: https://arxiv.org/pdf/2602.15428.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Total Football free codes and how to redeem them (March 2026)
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
2026-02-18 23:20