Author: Denis Avetisyan
Researchers have introduced a comprehensive benchmark designed to push embodied AI agents beyond basic skills and into the realm of complex, detail-oriented interactions.
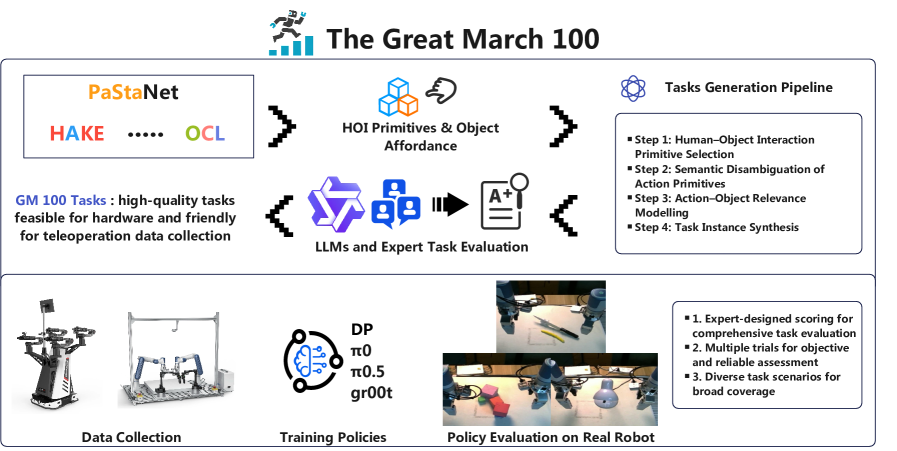
GM-100, a dataset of 100 diverse tasks, addresses the need for more realistic and challenging evaluation of robot learning algorithms, focusing on long-tail distributions and human-object interaction.
Despite rapid advancements in robot learning, current benchmarks often lack the diversity and complexity needed to truly assess embodied AI capabilities and differentiate nuanced performance. To address this, we introduce the Great March 100 (GM-100), a new dataset comprising 100 detail-oriented tasks designed to rigorously evaluate robotic agents across a wide range of interactions and long-tail behaviors. Our work demonstrates that GM-100 provides a challenging yet feasible platform for benchmarking, effectively distinguishing the performance of existing vision-language alignment models. Will this more comprehensive evaluation framework accelerate progress towards truly versatile and robust embodied AI systems?
The Fragility of Robotic Proficiency: A Mathematical Imperative
Robotic systems demonstrate impressive capabilities when confined to structured environments and repetitive actions, frequently surpassing human performance in these limited domains. However, this proficiency sharply declines when robots encounter the inherent unpredictability of the real world – variations in lighting, object pose, or unexpected obstacles can all disrupt performance. This fragility stems from a reliance on training data that, while sufficient for specific scenarios, fails to capture the vast spectrum of possible real-world conditions. Consequently, robots often struggle to generalize learned skills beyond the precise parameters of their training, creating a significant barrier to their deployment in dynamic and unstructured environments where adaptability is paramount.
Robots operating in the real world frequently encounter situations that deviate from their training data – a phenomenon described as the ‘long tail’ of infrequently occurring actions. This presents a significant challenge because, while a robot might perform common tasks with high reliability, its performance degrades unpredictably when faced with rare events. These unusual scenarios, though statistically uncommon, often demand critical safety responses; a self-driving car encountering an unexpected obstacle, or a robotic arm reacting to a tool malfunction, exemplify this issue. Effectively handling this ‘long tail’ requires robots to move beyond memorization of training examples and develop a capacity for generalization – the ability to safely and effectively respond to novel situations without explicit prior experience, a key step toward achieving true autonomy.
The limitations of conventional robotic systems become strikingly apparent when confronted with unpredictable real-world events-those infrequent, yet potentially critical, situations not adequately represented in training data. Current methodologies, often reliant on extensive datasets of common actions, demonstrate a fragility when tasked with handling the ‘long tail’ of rare occurrences. This lack of robustness isn’t merely a matter of performance degradation; it fundamentally impedes the achievement of true autonomy. A robot unable to safely and effectively navigate unforeseen circumstances requires constant human oversight, effectively remaining a sophisticated tool rather than an independent agent. Consequently, advancements in robotic generalization necessitate a shift towards learning paradigms capable of anticipating, adapting to, and even learning from these low-probability, high-impact events – a critical step in realizing robots that can operate reliably in complex, unstructured environments.
GM-100: A Benchmark for Rigorous Robotic Generalization
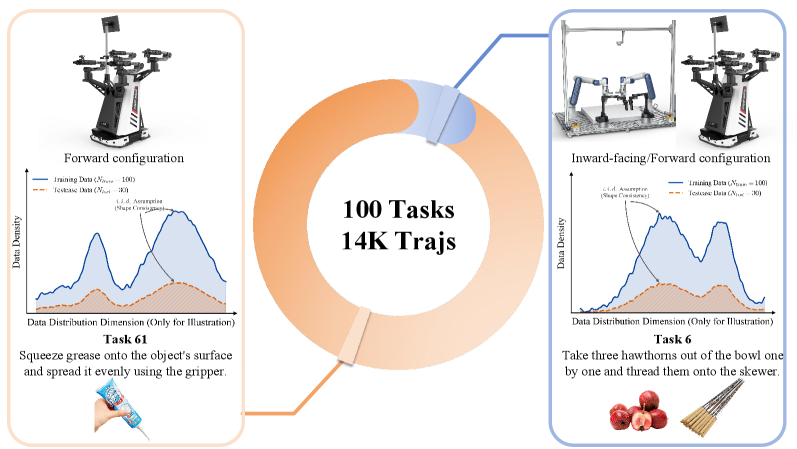
The GM-100 benchmark addresses limitations in existing robotic learning evaluations by providing a dataset of 100 distinct tasks designed to comprehensively assess a robot’s ability to generalize and adapt. Unlike benchmarks focused on repetitive actions, GM-100 emphasizes diversity in task objectives and execution, encompassing a range of common and less frequent human-object interactions. This increased task variety is intended to move beyond simple memorization and encourage the development of robust learning algorithms capable of handling unpredictable real-world scenarios. The benchmark’s scope extends beyond simple binary success/failure, aiming for a more nuanced understanding of robot performance across a broader spectrum of abilities.
The GM-100 benchmark suite is comprised of 100 distinct tasks designed to assess robotic manipulation skills through a focus on human-object interactions. These tasks move beyond simple, repetitive actions by incorporating both frequently occurring interactions, such as placing an object on a surface, and less common scenarios, like carefully stacking irregularly shaped objects. This diversity is intended to challenge robots to generalize their learned skills to a wider range of real-world situations and avoid overfitting to specific, limited training data, thereby requiring more robust and adaptable learning algorithms.
The GM-100 benchmark utilizes the Agilex Cobot Magic and Dobot Xtrainer robotic platforms for data acquisition in real-world conditions. These platforms facilitated the collection of over 13,000 robot trajectories, comprising the dataset used for both training and evaluating learning algorithms. This substantial dataset enables assessment of robot performance across a variety of tasks, moving beyond simulated environments to focus on practical, physical execution. Data collection on physical robots is crucial for addressing challenges related to sensor noise, actuator limitations, and real-world variability.
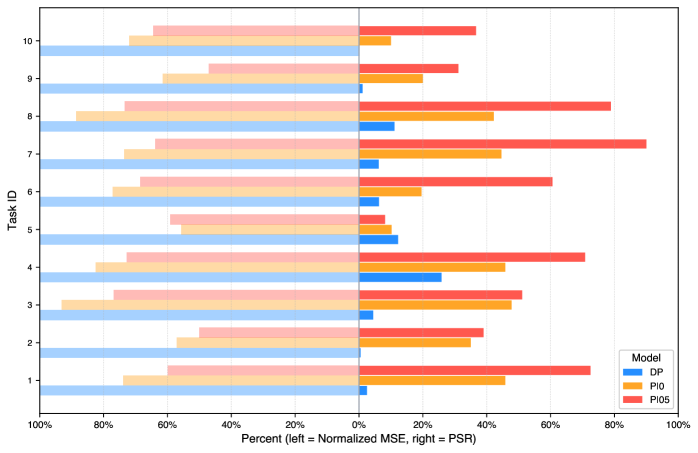
Robot performance on the GM-100 benchmark is quantitatively evaluated using both Success Rate and Partial Success Rate. Success Rate measures the percentage of tasks completed without any external intervention, indicating complete task mastery. Partial Success Rate assesses the percentage of tasks where the robot makes demonstrable progress towards completion, even if full completion isn’t achieved; this is determined by a predefined threshold of task completion criteria. Utilizing both metrics provides a more nuanced understanding of robot capabilities than solely relying on binary success/failure measurements, allowing for detailed analysis of performance across various task difficulties and identifying areas for improvement in robot learning algorithms.
Evaluating Performance: A Comparative Analysis of Vision-Language-Action Models
The GM-100 benchmark was utilized to evaluate the performance of several Vision-Language-Action models, specifically Diffusion Policy, π0, and π0.5, alongside the GR00T model. GM-100 is a dataset designed for assessing robotic manipulation skills based on visual and linguistic instructions. The evaluation involved testing each model’s ability to successfully complete the tasks defined within the GM-100 benchmark, providing a standardized comparison across different architectures and training methodologies. This comparative analysis allows for quantitative assessment of each model’s strengths and weaknesses in performing complex, visually-guided robotic actions.
The adaptation of evaluated Vision-Language-Action models to the GM-100 benchmark leveraged distinct robotic frameworks. Specifically, Diffusion Policy underwent finetuning utilizing the LeRobot Framework, a system designed for robotic learning and control. In contrast, both π0 and π0.5 employed the OpenPi Framework for adaptation, which focuses on enabling robots to learn from human demonstrations and language instructions. This difference in framework implementation represents a key variable in assessing performance and understanding the strengths of each approach within the GM-100 testing environment.
Vision-Language-Action models such as Diffusion Policy, π0, and π0.5 function as essential baselines in robot learning research by providing standardized performance metrics against which new methodologies can be quantitatively compared. Establishing these baselines is critical for determining the incremental improvements offered by novel algorithms and architectures; researchers can directly assess whether a new approach surpasses the capabilities of existing, well-documented models on established benchmarks like GM-100. This comparative analysis facilitates objective evaluation and accelerates progress in the field by providing a common frame of reference for assessing the effectiveness of different robot learning techniques.
Evaluation of leading Vision-Language-Action models – Diffusion Policy, π0, and π0.5 – on the GM-100 benchmark revealed significant performance challenges, even for these state-of-the-art systems. While these models demonstrate capabilities in robotic task execution, the GM-100 dataset’s complexity consistently resulted in sub-optimal performance across all tested approaches. These initial findings underscore the limitations of current methodologies when applied to diverse and realistic robotic scenarios, thereby emphasizing the necessity for continued research and development of more robust and adaptable robot learning techniques.
Towards True Robotic Intelligence: Charting a Path for Generalizable Systems
The GM-100 robot represents a significant step forward in the pursuit of adaptable and broadly capable robotic systems. Unlike many research platforms focused on narrow, pre-defined tasks, GM-100 is specifically designed to address the challenge of ‘long-tail’ behaviors – those infrequent, yet crucial, actions needed for robust real-world performance. This emphasis on adaptability isn’t simply about increasing the number of tasks a robot can perform, but rather ensuring reliable execution across a diverse range of scenarios, including those not explicitly encountered during training. By providing a versatile and accessible platform for investigating these complex behaviors, GM-100 fosters innovation in areas like generalization, few-shot learning, and robust perception – ultimately paving the way for robots that can truly operate seamlessly and safely in unstructured, everyday environments.
Continued advancements in robotic capabilities hinge on refining the methods by which these systems learn and adapt. Current learning algorithms often struggle with the complexities and variations inherent in real-world environments, limiting a robot’s ability to generalize beyond its training data. Consequently, researchers are increasingly focused on sophisticated data augmentation techniques-artificially expanding datasets with modified or synthesized examples-and novel learning paradigms. These include methods designed to improve sample efficiency, enhance robustness to noisy or incomplete data, and facilitate transfer learning, where knowledge gained from one task is applied to new, related challenges. By combining these approaches, the aim is to create robotic systems capable of mastering a wider range of skills and operating reliably in unpredictable circumstances, ultimately bridging the gap between laboratory performance and real-world utility.
Current advancements in robotic intelligence are increasingly focused on models that integrate visual perception, natural language understanding, and action execution – a foundation exemplified by systems like RT-2, OpenVLA, and the Robotics Diffusion Transformer. These models demonstrate the potential to move beyond pre-programmed behaviors by leveraging large datasets of image-language-action pairings, enabling robots to generalize to novel tasks described through simple instructions. RT-2, for instance, utilizes a visual encoder to map images into a latent space, allowing it to interpret and respond to language commands related to those visuals. Similarly, OpenVLA and the Robotics Diffusion Transformer explore different architectures for grounding language in robotic actions, with the latter employing diffusion models to generate diverse and feasible trajectories. Further investigation into these and related architectures promises to unlock more adaptable and versatile robotic systems capable of performing a wider range of tasks in unstructured environments.
The pursuit of truly generalizable robotics centers on developing systems capable of fluid and dependable interaction with the world, extending beyond pre-programmed tasks to encompass the unpredictable nature of daily life. This necessitates a shift from robots excelling in narrow, well-defined scenarios to those that can gracefully handle both frequently encountered situations and the long tail of rare, unforeseen events. Achieving this requires robust perception, adaptable planning, and safe execution, ensuring robots not only complete objectives but also do so without causing harm or requiring constant human intervention. The ultimate benchmark of success will be a robot capable of operating autonomously in complex, unstructured environments, exhibiting the same level of common sense and adaptability as a human navigating a dynamic world.
The creation of GM-100, with its emphasis on 100 detail-oriented tasks, exemplifies a commitment to rigorous evaluation-a principle echoing Barbara Liskov’s assertion: “Programs must be correct; it’s not enough that they work.” This dataset isn’t merely about achieving functionality; it strives for a mathematically sound basis for assessing embodied AI. The long-tail distribution of tasks, intentionally designed to push beyond common scenarios, demands a level of robustness that superficial testing cannot reveal. Just as a theorem must hold true under all valid conditions, so too must these robotic agents demonstrate reliable performance across a diverse and challenging spectrum of human-object interactions. The focus on detail isn’t pedantry, but rather the pursuit of provable correctness in a domain often satisfied with merely ‘working’ solutions.
What Lies Ahead?
The introduction of GM-100, while a necessary expansion of existing benchmarks, merely highlights the fundamental chasm between ‘working’ and ‘understood’. The dataset’s emphasis on long-tail distributions, and the breadth of human-object interaction it attempts to capture, is commendable. However, it is crucial to recognize that increased complexity does not inherently yield increased robustness. A system capable of navigating a thousand scenarios remains fragile if its foundational principles are not demonstrably sound. The pursuit of ever-larger datasets risks becoming a form of empirical obfuscation, masking a lack of theoretical grounding.
Future effort should not center solely on expanding the scope of tasks, but on the development of formal verification methods. To claim genuine progress, robotic agents must not simply perform these actions, but provably satisfy specified constraints. Optimization without analysis is self-deception, a trap for the unwary engineer. The focus must shift from achieving high scores on benchmarks to establishing mathematically rigorous guarantees of behavior.
Ultimately, the true test will not be whether a robot can mimic human actions, but whether it can reason about them. GM-100 provides a richer landscape for exploration, but it is the development of formal languages and verification techniques – a move towards provable intelligence – that will determine whether this exploration yields genuine understanding, or remains a sophisticated exercise in pattern recognition.
Original article: https://arxiv.org/pdf/2601.11421.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- ‘SNL’ host Finn Wolfhard has a ‘Stranger Things’ reunion and spoofs ‘Heated Rivalry’
- M7 Pass Event Guide: All you need to know
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
2026-01-19 11:01