Author: Denis Avetisyan
Researchers have developed a new framework that empowers agents to ‘imagine’ potential scenarios, dramatically improving their ability to understand complex human-object interactions.

ImagineAgent combines generative modeling, tool-augmented reasoning, and reinforcement learning for state-of-the-art open-vocabulary HOI detection.
Despite advances in multimodal large language models, robust visual reasoning-particularly in open-vocabulary human-object interaction (HOI)-remains challenged by cross-modal ambiguities and hallucinations. This work, ‘What if Agents Could Imagine? Reinforcing Open-Vocabulary HOI Comprehension through Generation’, introduces ImagineAgent, a novel framework that leverages cognitive reasoning and generative imagination to address these limitations. By constructing cognitive maps and dynamically invoking tools like diffusion models, ImagineAgent achieves state-of-the-art HOI detection with significantly less training data. Could this approach to tool-augmented reasoning unlock more human-like understanding in artificial intelligence systems?
Decoding Interaction: The Challenge of Open-World Perception
Current Human-Object Interaction (HOI) detection systems, while proficient at identifying commonly observed actions like “person holding cup” or “person riding bicycle,” falter when presented with novel interactions. This limitation stems from their reliance on pre-defined categories; any interaction not explicitly included in the training data is often misclassified or ignored, severely restricting their usefulness in dynamic, real-world scenarios. Imagine a robotic assistant encountering someone skillfully juggling oranges – a system trained solely on standard manipulation verbs would struggle to interpret this action, hindering its ability to effectively navigate and interact with its environment. The inability to generalize to unseen interactions represents a significant bottleneck in achieving truly adaptable and intelligent systems capable of understanding the full spectrum of human behavior.
Current approaches to understanding human-object interaction often depend on pre-defined lists of actions and objects, creating a significant bottleneck in real-world applications. These “fixed vocabulary” methods struggle when encountering novel interactions – a person using an object in an unanticipated way, or a completely new object entering the scene. This limitation arises because the system hasn’t been “taught” these possibilities, hindering its ability to generalize beyond the training data. Consequently, a robot or AI trained on a limited set of interactions may fail to correctly interpret even simple, everyday actions that fall outside its pre-programmed understanding, demonstrating a critical need for more flexible and adaptable systems capable of reasoning about an open range of possibilities.
Effective interaction with real-world environments demands more than simply identifying visible actions; it necessitates a system’s ability to infer relationships when objects are hidden from view or when an action’s intent is unclear. Research indicates that humans readily utilize contextual cues and prior knowledge to resolve such ambiguities, a capability currently lacking in most automated systems. For instance, a partially obscured hand reaching towards a doorknob is readily understood as an opening attempt, even if the full hand isn’t visible. Similarly, discerning between someone handing an object to another person versus simply holding it requires interpreting subtle cues and understanding the broader scene context. Consequently, advancements in robust reasoning about occluded objects and ambiguous interactions are crucial for developing truly intelligent systems capable of navigating the complexities of everyday life, moving beyond superficial visual recognition towards genuine environmental understanding.

ImagineAgent: A Framework for Robust Reasoning
ImagineAgent achieves robust open-vocabulary Human-Object Interaction (HOI) detection by integrating three core components: cognitive reasoning, generative imagination, and tool-augmented reinforcement learning. Cognitive reasoning provides a structured approach to understanding detected entities and their potential interactions, while generative imagination allows the agent to hypothesize about unobserved states and interactions. This is further enhanced by tool-augmented reinforcement learning, which dynamically invokes external tools to gather supporting evidence and refine the agent’s understanding of the scene. The combined effect is an HOI detection system capable of generalizing to novel objects and interactions not explicitly seen during training, leading to improved robustness and performance in complex, real-world scenarios.
Cognitive Mapping within ImagineAgent establishes a structured representation of the environment and potential interactions. This is achieved by constructing a graph where nodes represent detected entities and their attributes, and edges define relationships and possible actions between them. Specifically, the agent maintains a knowledge base detailing object properties, spatial arrangements, and affordances – what actions can be performed on or with those objects. This graph-based representation allows for efficient inference through symbolic reasoning and enables the agent to predict outcomes of actions, evaluate potential plans, and ultimately select the most appropriate course of action given the observed scene and defined goals. The Cognitive Map is dynamically updated as new information is gathered through perception and tool usage, refining the agent’s understanding and improving its decision-making capabilities.
Tool Augmenting within ImagineAgent enables the framework to overcome limitations in its internal knowledge by dynamically invoking external tools during the HOI detection process. These tools, which can include knowledge bases, visual search engines, or specialized APIs, are queried to gather supporting evidence related to detected entities and potential interactions. The agent formulates queries based on the current scene understanding and utilizes the returned data to refine its reasoning, validate hypotheses, and ultimately improve the accuracy and robustness of HOI detection, particularly in open-vocabulary scenarios where pre-existing knowledge is insufficient.
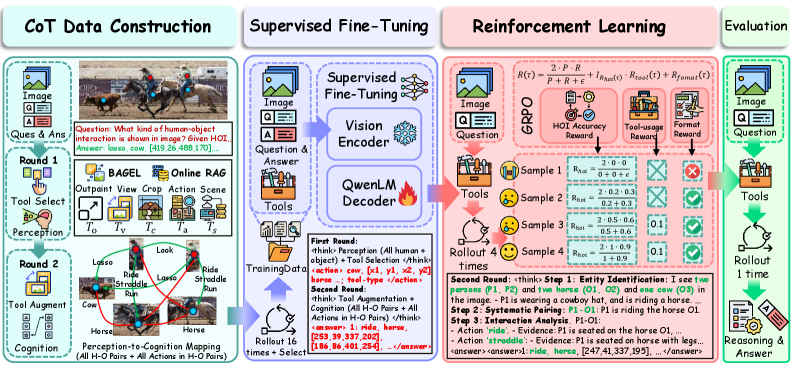
Constructing Reality: Generative Imagination for Ambiguity
ImagineAgent utilizes Generative World Modeling to mitigate the effects of occlusion and ambiguity by creating statistically probable reconstructions of obscured or uncertain scene elements. This process involves the agent learning a distribution over possible scene configurations, enabling it to infer likely content behind occluding objects or resolve ambiguous visual cues. The system doesn’t simply “fill in” missing data; instead, it generates novel views consistent with the observed evidence and its learned world model, allowing for reasoning about hypothetical scenarios and improved understanding of the complete scene. This generative approach allows the agent to predict plausible states of the environment even with incomplete information, supporting robust perception and decision-making.
Viewpoint Transform and Outpainting are employed within ImagineAgent to address incomplete scene information. Viewpoint Transform synthetically generates a scene’s appearance from a novel perspective, effectively revealing objects or areas previously obscured. Outpainting extends the boundaries of an existing image by algorithmically generating content beyond the original frame, thereby reconstructing occluded portions or providing context for ambiguous regions. Both techniques leverage the Generative World Model to ensure synthesized content is plausible and consistent with the observed scene, facilitating the reconstruction of hidden interactions and a more complete understanding of the environment.
The Image Crop Tool functions by allowing users to define rectangular regions within the high-resolution input image for isolated analysis. This capability is essential for detailed inspection of specific areas, particularly where occlusion or ambiguity exists, as it reduces computational load and focuses processing on relevant visual data. Cropped regions are then processed independently, enabling more accurate feature extraction and reasoning about object states and interactions within that defined area. The tool supports variable crop sizes and aspect ratios, accommodating diverse analytical needs and facilitating granular examination of complex scenes.
![Our framework enhances an agent's ability to resolve ambiguities in images by providing a tool library including generative imagination ([latex]BAGEL[/latex] model with Outpaint and Viewpoint Transform), online reasoning via the [latex]Qwen[/latex] API with Action and Scene Explanation, and focused image cropping.](https://arxiv.org/html/2602.11499v1/x4.png)
Validating ImagineAgent’s Capabilities: Empirical Findings
ImagineAgent’s performance was evaluated using the SWIG-HOI and HICO-DET datasets, which present significant challenges in human-object interaction (HOI) detection. On the SWIG-HOI benchmark, ImagineAgent achieved a mean Average Precision (mAP) of 17.75%. Evaluation on the HICO-DET dataset yielded a mAP of 28.96%. These results demonstrate the framework’s ability to effectively address the complexities of HOI detection in visually challenging scenarios, indicating a substantial level of accuracy in identifying and classifying interactions between humans and objects.
ImagineAgent incorporates an Action Explanation Tool to improve the transparency and comprehensibility of its decision-making process. This tool provides justifications for predicted human-object interactions by generating natural language explanations detailing the reasoning behind each prediction. The explanations are derived from the model’s internal state and focus on the contextual factors influencing the predicted action. By providing these explanations, the framework moves beyond simply outputting a prediction and offers users insight into why a particular interaction was identified, facilitating trust and allowing for more effective debugging and refinement of the model.
ImagineAgent enhances robustness by incorporating an active imagination process, simulating alternative scene states to reduce dependence on flawless perceptual data. This proactive approach allows the framework to maintain performance even with incomplete or noisy input. Quantitative results demonstrate a 5.84% performance increase over prior state-of-the-art methods when evaluated on the HICO-DET dataset, indicating a significant improvement in handling imperfect perceptual information through imagined scene variations.

Towards Embodied Intelligence: Future Directions
ImagineAgent signifies a notable advancement in the pursuit of artificial intelligence that doesn’t just process information, but actively experiences and interacts with its environment. This framework moves beyond traditional AI by integrating perceptual input with a reasoning engine, allowing the agent to form internal representations of the world and make informed decisions based on those representations. Unlike systems confined to static datasets, ImagineAgent can navigate dynamic and unpredictable scenarios, demonstrating a capacity for robust reasoning even when faced with incomplete or ambiguous information. The architecture’s strength lies in its ability to ground abstract knowledge in concrete experience, effectively bridging the gap between simulated intelligence and genuine embodied cognition – a crucial step towards creating AI systems capable of truly understanding and responding to the complexities of the real world.
The current ImagineAgent framework demonstrates promising reasoning capabilities, but truly robust intelligence necessitates proactive engagement with the environment. Future development will center on integrating active perception and planning modules, allowing the agent to not simply react to sensory input, but to strategically seek out information that reduces uncertainty and informs decision-making. This involves equipping the agent with the ability to formulate ‘information-gathering’ actions – for instance, physically moving to obtain a clearer view of an obscured object or requesting specific data from external sources. By actively shaping its perceptual experience, the agent can move beyond passive observation and build a more complete and reliable internal model of the world, ultimately enhancing its capacity for complex problem-solving and adaptation in dynamic, real-world scenarios.
The ongoing development of this framework prioritizes expansion to more complex scenarios and real-world implementations. Researchers are actively working to increase the scale of the system, allowing it to process larger datasets and operate within more intricate environments. This scaling effort is directly linked to explorations in robotics, where the framework could provide a sophisticated control system for autonomous robots navigating and interacting with unpredictable surroundings. Beyond robotics, potential applications extend to assistive technology, offering personalized support for individuals with disabilities through intelligent interfaces and adaptive tools. Ultimately, this research aims to move beyond simulation and demonstrate the framework’s efficacy in tangible, beneficial applications, paving the way for a new generation of intelligent systems capable of addressing real-world challenges.
The pursuit of ImagineAgent, as detailed in the study, inherently demands a consideration of what lies beyond immediate perception. The framework’s reliance on generative imagination to reinforce open-vocabulary HOI comprehension echoes Fei-Fei Li’s assertion: “AI is not about replacing humans; it’s about augmenting human capabilities.” This aligns directly with the paper’s core idea of extending the agent’s understanding through simulated experiences – essentially augmenting its ‘vision’ beyond the directly observed data. The system doesn’t merely detect; it imagines possibilities, a process fundamentally linked to expanding its comprehension of human-object interactions and navigating the boundaries of its knowledge. This proactive exploration of potential scenarios addresses the inherent challenge of incomplete data, fostering a more robust and adaptable system.
What’s Next?
The pursuit of agents that “imagine” – or, more accurately, internally simulate potential interactions – reveals a fundamental challenge: discerning genuine comprehension from sophisticated pattern completion. The ImagineAgent framework demonstrates a compelling step forward, yet each successful generation masks underlying dependencies still begging for elucidation. The current emphasis on open-vocabulary HOI detection, while valuable, risks treating the detection as the goal, rather than a proxy for understanding the causal structure of the physical world. Future work must move beyond simply identifying interactions to modelling why those interactions occur, and what constraints govern them.
A crucial, and often overlooked, limitation lies in the grounding of these generative models. While large language models excel at manipulating symbols, those symbols remain detached from embodied experience. The next iteration of this research must grapple with the problem of sensorimotor integration – how can an agent’s imagined scenarios be reliably connected to its perceptual reality? This necessitates a shift towards more robust and generalizable representations, moving beyond pixel-level features to abstract relational structures.
Ultimately, the true measure of success will not be benchmark scores, but the emergence of genuinely interpretable models. It is not enough to build agents that can imagine; the focus must be on building agents whose imagination is transparent, allowing for diagnostic analysis of their reasoning processes. Only then can the illusion of understanding be replaced with a verifiable, mechanistic account of intelligence.
Original article: https://arxiv.org/pdf/2602.11499.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- Total Football free codes and how to redeem them (March 2026)
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
- Olivia Colman’s highest-rated drama hailed as “exceptional” is a must-see on TV tonight
- Gold Rate Forecast
2026-02-13 15:23