Author: Denis Avetisyan
A new approach to composed image retrieval leverages probabilistic learning and uncertainty modeling to deliver more accurate and interpretable search results.
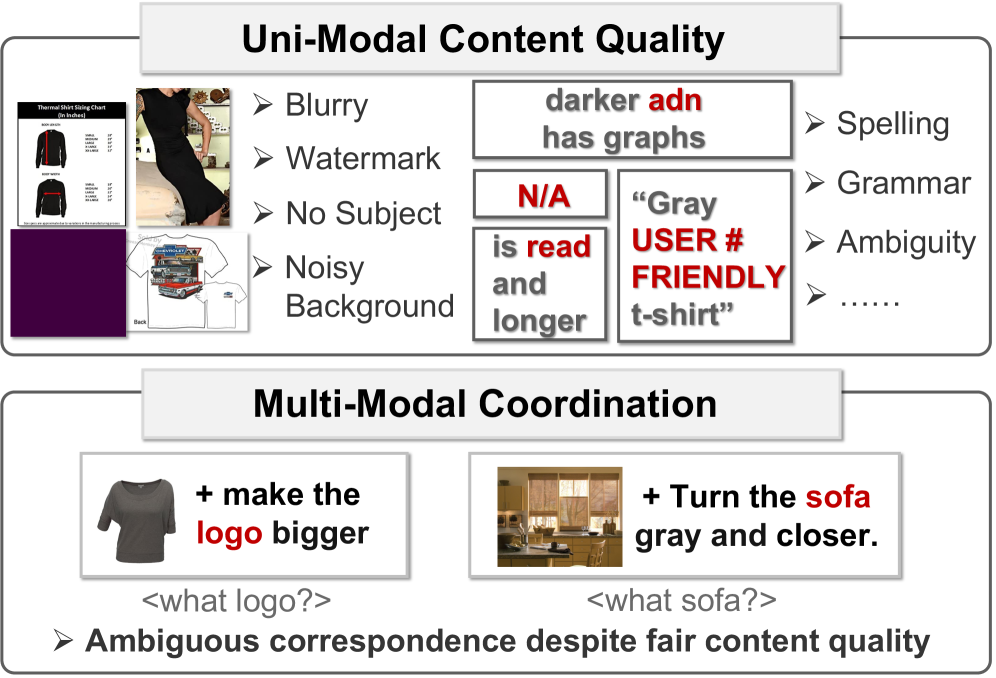
This work introduces a Heterogeneous Uncertainty-Guided (HUG) paradigm for improved multi-modal coordination and fine-grained representation learning in composed image retrieval.
Existing composed image retrieval methods struggle with the inherent noise and uncertainty present in multi-modal queries and uni-modal targets, limiting robust search performance. This paper introduces a novel paradigm, ‘Heterogeneous Uncertainty-Guided Composed Image Retrieval with Fine-Grained Probabilistic Learning’, which addresses these limitations through fine-grained probabilistic representations and customized uncertainty modeling. By representing queries and targets as Gaussian embeddings and dynamically weighting uncertainties based on both content quality and multi-modal coordination, we enhance discriminative learning via uncertainty-guided contrastive objectives. Does this approach unlock more faithful and interpretable composed image retrieval systems capable of navigating complex search intents?
The Nuances of Visual Distinction
Conventional image retrieval systems frequently encounter difficulties when discerning subtle visual distinctions and comprehending the arrangement of elements within a scene. These systems typically rely on broad feature matching – identifying overall colors or dominant objects – which proves inadequate when searching for images based on intricate details or specific spatial relationships. For instance, a query for “a red car behind a blue truck” often yields results simply containing both vehicles, irrespective of their relative positioning. This limitation stems from a reliance on global image descriptors, rather than a granular analysis of both object attributes and their compositional interplay, hindering the precision of searches requiring a deeper understanding of visual context.
Current image retrieval systems often treat visual attributes – such as color, texture, and shape – as independent features, overlooking their intricate interplay within a scene. This simplification hinders precise retrieval because recognizing an object frequently depends on how these attributes relate to one another. For example, distinguishing a “red car” from a “car with red accents” requires understanding the spatial arrangement and proportional contribution of color; a system focused solely on the presence of “red” will inevitably yield irrelevant results. Consequently, existing methods struggle with fine-grained distinctions, returning images that contain the requested attributes but lack the specific compositional characteristics defining the desired object or scene. Addressing this limitation necessitates developing techniques capable of modeling these complex relationships, moving beyond isolated attribute detection towards a more holistic understanding of visual content.

Distilling Visual Essence with Q-Former
The Q-Former is utilized as a learnable mechanism for extracting dense vector representations from input images. This architecture consists of a fixed number of learnable query tokens which are processed by a transformer network, attending to visual features extracted from the image. Through this attention mechanism and subsequent non-linear transformations, each query token aggregates information from across the entire image, resulting in a fixed-length vector. The final output is a set of these learned query vectors, representing a distilled, fine-grained mean vector embedding of the original image suitable for downstream tasks.
The Q-Former utilizes initialization with the BLIP-2 model, a pre-trained vision-language model, to accelerate learning and improve the quality of extracted visual features. BLIP-2 provides a strong foundation by offering pre-learned knowledge of visual concepts and their relationships to language. This transfer of knowledge reduces the amount of data required to train the Q-Former and results in enhanced performance on downstream tasks requiring fine-grained visual understanding. Specifically, the weights of the Q-Former are initialized using the weights from BLIP-2, allowing the model to leverage existing feature representations and quickly adapt to the specific requirements of extracting mean vectors from images.
The creation of a Fine-Grained Representation is achieved through the Q-Former’s ability to distill image information into attribute-level details. This representation allows for a more nuanced understanding of visual content than traditional methods, enabling improved retrieval performance by focusing on specific characteristics within an image. Rather than treating an image as a single vector, the Q-Former facilitates the encoding of distinct attributes – such as color, shape, or texture – into separate feature vectors, increasing the precision of similarity searches and content-based image retrieval systems. This detailed encoding is crucial for applications requiring precise visual discrimination and analysis.

Refining Perception Through Uncertainty
The Uncertainty-Aware Contrastive Loss functions by incorporating uncertainty estimations directly into the contrastive learning process. This is achieved by weighting the contribution of each sample pair based on the model’s confidence in its similarity assessment; pairs with higher uncertainty receive reduced weighting, minimizing their impact on the overall loss calculation. This approach allows the model to prioritize learning from reliable comparisons and effectively downplay noisy or ambiguous data points. The loss function builds upon the standard contrastive loss by modifying the weighting factor to reflect the estimated uncertainty, thereby enhancing the robustness and accuracy of the learned image representations for improved discriminative matching.
The Uncertainty-Aware Contrastive Loss builds upon the established Sigmoid Contrastive Loss by incorporating uncertainty estimations into the comparison of image representations. The Sigmoid Contrastive Loss traditionally calculates similarity based on a fixed distance metric; however, this new loss function modulates the contribution of each comparison based on the estimated uncertainty associated with the representations. Specifically, higher uncertainty reduces the weight of that particular comparison, mitigating the impact of potentially noisy or unreliable feature pairings. This adaptive weighting scheme results in a more robust comparison process, as it prioritizes reliable feature matches and downplays less confident ones, ultimately leading to more accurate image representations for retrieval tasks. The weighting is applied during the calculation of the contrastive penalty, influencing the magnitude of the loss based on representation confidence.
The implemented retrieval system demonstrates enhanced performance through its capacity to differentiate nuanced variations in image representations. This capability stems from the model’s ability to identify subtle similarities and differences that are often missed by conventional methods. Quantitative evaluations indicate that this approach achieves state-of-the-art results on benchmark datasets, establishing a new performance paradigm for image retrieval tasks and surpassing existing methodologies in both precision and recall metrics. The improvements are particularly noticeable in scenarios requiring fine-grained discrimination, such as identifying similar images with minor variations in pose, lighting, or occlusion.
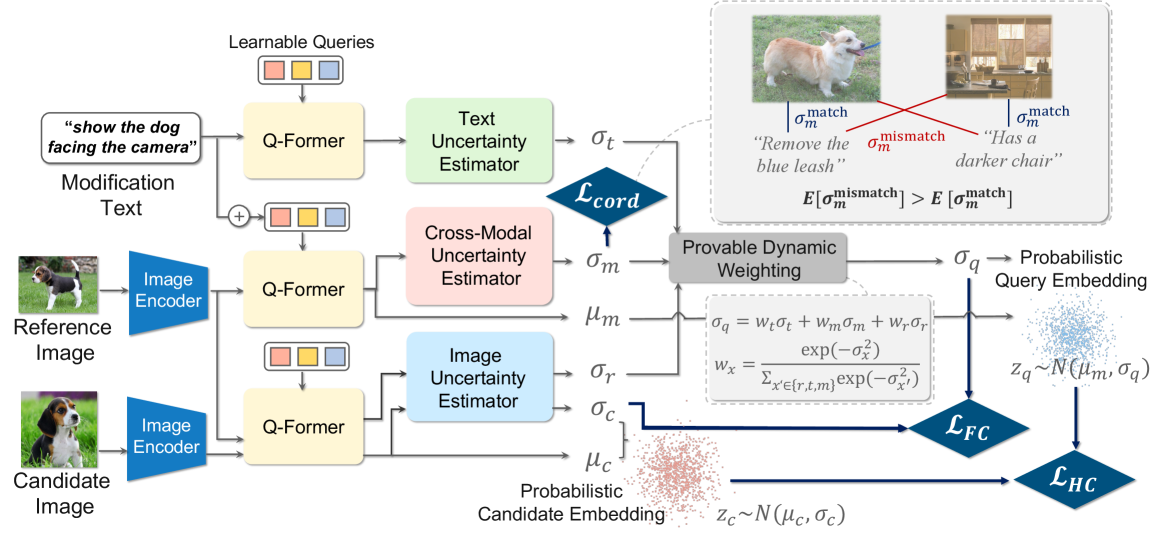
Demonstrating Broad Applicability and Impact
The model’s capacity for broad application was confirmed through evaluation on two distinct datasets: CIRR and Fashion-IQ. CIRR, a large-scale dataset of general-domain images, presented a challenge in retrieving relevant images across diverse visual content, while Fashion-IQ focused specifically on the fashion domain, demanding nuanced understanding of style and attributes. Achieving strong performance on both datasets indicates the model isn’t limited by domain-specific features; rather, it learns robust visual representations applicable to a wide range of image types. This generalizability stems from the model’s architecture and training methodology, allowing it to effectively transfer learned knowledge across different visual contexts and retrieve relevant images regardless of content.
The model’s efficacy was rigorously evaluated utilizing the Recall@K metric, a standard measure of information retrieval performance. This assessment revealed state-of-the-art results on both the CIRR and Fashion-IQ datasets, demonstrably surpassing the performance of existing methodologies. Specifically, the approach consistently retrieved relevant images with greater accuracy, indicating a significant advancement in visual search capabilities. This achievement highlights the model’s ability to generalize across diverse image types and underscores its potential for real-world applications requiring robust and precise image retrieval, confirming its position as a leading solution in the field.
Evaluations reveal substantial gains in image retrieval accuracy, demonstrating the efficacy of the proposed uncertainty-aware contrastive learning approach. Performance was quantified using the Recall@K metric, consistently achieving higher scores at both K=10 and K=50, indicating improved precision in identifying relevant images within the top ten and fifty results. Furthermore, analysis of the CIRR dataset through the Recalls_subset@K metric highlights the model’s ability to effectively retrieve images from specific subsets, confirming its nuanced understanding of image characteristics and its capacity to navigate complex visual data. These results collectively establish a new benchmark in retrieval performance, surpassing existing methodologies and offering a robust solution for image-based search and analysis.
The pursuit of robust composed image retrieval, as detailed in this work, demands a nuanced understanding of how systems represent and reason about uncertainty. This aligns perfectly with the sentiment expressed by David Marr: “A good theory should not only explain the data but also predict what will happen next.” The HUG paradigm, by embracing heterogeneous learning and fine-grained probabilistic embeddings, doesn’t simply locate images; it attempts to understand the contributing factors and their associated confidence levels. This thoughtful approach, mirroring Marr’s emphasis on predictive power, moves beyond mere pattern matching toward a more elegant and insightful system – one where form and function harmoniously converge to deliver both accuracy and interpretability.
Beyond the Composition
The pursuit of composed image retrieval, as exemplified by this work, often feels like chasing a ghost – the perfect alignment of semantic fragments. This paradigm, while yielding demonstrable improvements through heterogeneous uncertainty modeling, merely refines the question, rather than resolving it. A truly elegant system shouldn’t need to explicitly quantify uncertainty; the retrieval should simply feel correct, an instinctive resonance between query and result. The current reliance on probabilistic embeddings, while technically sound, hints at an underlying difficulty in capturing the holistic nature of visual understanding.
Future investigations should consider moving beyond purely data-driven approaches. The field needs to interrogate the why behind successful compositions, not just the what. Can principles of visual balance, symmetry, and the Gestalt principles be integrated into the learning process? Furthermore, the evaluation metrics remain stubbornly focused on precision and recall – metrics that, while useful, fail to capture the subjective experience of aesthetic coherence. A good interface is invisible to the user, yet felt; similarly, a successful retrieval system should operate with an understated confidence, rather than a clamorous display of probabilistic calculations.
Perhaps the most significant challenge lies in defining “composition” itself. The current framework assumes a relatively static definition. However, visual meaning is fluid and context-dependent. A truly intelligent system must be capable of interpreting composition, not just recognizing pre-defined elements. Every change should be justified by beauty and clarity; the field must strive for a system that not only finds images, but understands what makes them visually meaningful.
Original article: https://arxiv.org/pdf/2601.11393.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Best Arena 9 Decks in Clast Royale
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- World Eternal Online promo codes and how to use them (September 2025)
- JJK’s Worst Character Already Created 2026’s Most Viral Anime Moment, & McDonald’s Is Cashing In
- ‘SNL’ host Finn Wolfhard has a ‘Stranger Things’ reunion and spoofs ‘Heated Rivalry’
- M7 Pass Event Guide: All you need to know
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
2026-01-20 17:12