Author: Denis Avetisyan
New research tackles a core challenge in video understanding: ensuring AI infers actions based on temporal reasoning, not just the objects present in a scene.
![Models readily latch onto superficial object cues as shortcuts during learning, sacrificing robust verb representation-a study using a ViT[10] trained on a verb-object subset of Sth-com[16] reveals that while object accuracy increases rapidly, verb accuracy plummets in unseen compositional settings, even dropping below chance, demonstrating a bias towards easily-identified objects over generalized verb understanding.](https://arxiv.org/html/2601.16211v1/x5.png)
Researchers introduce a framework to mitigate object-driven shortcuts in zero-shot compositional action recognition, improving performance on complex, unseen action sequences.
Despite advances in video understanding, compositional action recognition models often fail at seemingly simple tasks-struggling to generalize to unseen combinations of actions and objects. This work, titled ‘Why Can’t I Open My Drawer? Mitigating Object-Driven Shortcuts in Zero-Shot Compositional Action Recognition’, investigates this limitation, revealing a critical reliance on spurious object-verb co-occurrence statistics-what we term “object-driven shortcuts.” We demonstrate that these shortcuts arise from imbalances in training data and asymmetric learning difficulties, and propose RCORE, a framework that enforces temporally grounded verb learning to overcome this bias. Can emphasizing temporal reasoning unlock truly robust compositional video understanding and move beyond superficial pattern matching?
The Illusion of Understanding: When Actions Fail to Compose
Action recognition systems, despite achieving remarkable progress on benchmark datasets, often falter when presented with novel combinations of actions and objects. These models demonstrate a limited capacity to generalize beyond the specific pairings encountered during training, revealing a core weakness in their understanding of visual scenes. A system trained to recognize ‘pouring water’ and ‘stirring coffee’ might struggle with ‘pouring coffee’ – a seemingly simple variation – because it hasn’t explicitly learned the underlying principle of fluid transfer applied to different objects. This inability to extrapolate to unseen verb-object combinations represents a significant hurdle in deploying these systems in dynamic, real-world environments where the possibilities are virtually limitless, and pre-defining every scenario is impractical.
Current action recognition systems frequently exhibit what researchers term “Object-Driven Shortcuts,” a fundamental limitation in their ability to truly generalize. Instead of learning the relationship between an action and the objects involved, these models often prioritize recognizing the objects themselves as primary cues. For instance, a system might identify “a person holding a cup” by strongly focusing on the presence of a person and a cup, rather than understanding the specific interaction – the ‘holding’ – that defines the action. This reliance on individual object recognition creates a brittle system; when presented with novel object pairings – a person holding a book, for example – the model struggles because it hasn’t learned the underlying relational semantics governing the action itself, only the co-occurrence of certain objects. Consequently, performance drops significantly when facing unseen combinations, revealing a core weakness in compositional generalization.
A significant obstacle to robust action recognition lies in the limited exposure of training data to the vast landscape of possible verb-object pairings – a condition termed ‘compositional sparsity’. While datasets may contain numerous examples of individuals performing actions with specific objects, they rarely encompass the full combinatorial potential. This means a model trained on ‘person eating apple’ and ‘person throwing ball’ may struggle with ‘person eating ball’ or ‘person throwing apple’ despite understanding the individual components. The sheer number of potential combinations – even with a relatively limited vocabulary of verbs and objects – creates a data scarcity that forces models to rely on superficial correlations instead of genuine understanding of relational semantics, ultimately hindering their ability to generalize to novel, unseen actions.
![RCORE effectively reduces reliance on object-based shortcuts during verb learning, as demonstrated by confusion matrices for six verbs showing improved discrimination of opposing temporal semantics on unseen compositional data [latex]S_{th-com}[16][/latex] compared to the C2C baseline.](https://arxiv.org/html/2601.16211v1/x11.png)
RCORE: Grounding Action in the Flow of Time
RCORE is a new framework addressing limitations in current action recognition systems by prioritizing the representation of verbs as temporally grounded entities. Existing methods often rely heavily on static object recognition, leading to errors when actions are performed with similar objects or in complex environments. RCORE directly addresses this by explicitly encoding the temporal relationships inherent in action sequences into the verb representations. This is achieved through architectural modifications to the AIM model, focusing on the sequential nature of actions rather than treating them as isolated events. The resulting verb representations are designed to be more robust to variations in object appearance and environmental context, ultimately improving the accuracy and reliability of compositional action recognition.
RCORE utilizes the Action Interaction Model (AIM) as its foundational architecture, building upon its existing capabilities to address challenges in compositional action recognition. Specifically, RCORE augments AIM with additional modules designed to mitigate common failure modes observed when reasoning about sequences of interacting actions. These enhancements focus on improving the model’s ability to generalize to novel action combinations and to differentiate between similar actions based on subtle temporal cues. By retaining the core strengths of AIM – its capacity for modeling interactions – while adding specialized components, RCORE aims to achieve improved performance and robustness in complex activity understanding scenarios.
The Temporal Order Regularization Component (TORC) is integrated into the RCORE framework to address the tendency of action recognition models to prioritize static visual cues – such as object presence – over the sequential nature of actions. TORC operates by applying a penalty during training when the model’s predictions are strongly correlated with static object features, effectively discouraging reliance on these cues. This is achieved through a loss function component that measures the correlation between model outputs and static object representations extracted from video frames. By minimizing this correlation, TORC compels the model to prioritize the temporal ordering of actions, leading to improved robustness and accuracy in compositional action recognition tasks.

Synthetic Realities: Expanding the Training Landscape
RCORE addresses the challenge of Compositional Sparsity through ‘VOCAMix’, a data augmentation technique specifically designed to generate novel verb-object pairings not present in the training data. This is achieved by composing existing verbs and objects in new combinations, effectively increasing the diversity of observed actions during training. By exposing the model to these previously unseen pairings, VOCAMix improves generalization to compositions encountered during testing, reducing performance degradation that typically occurs when models encounter novel action combinations. The technique differs from standard data augmentation methods by explicitly focusing on compositional generalization rather than simple variations of existing examples.
Temporal Shuffle is a data augmentation technique implemented within the TORC framework designed to enhance model robustness by explicitly testing the understanding of temporal dependencies within action sequences. This strategy operates by randomly reordering the temporal arrangement of sub-actions within a given video sample, creating variations while preserving the constituent actions themselves. The resulting shuffled sequences are then presented to the model during training, forcing it to learn representations that are invariant to the original temporal order but still accurately recognize the complete action. This process effectively verifies whether the model relies on correct temporal reasoning or spurious correlations, ultimately improving its generalization capability to unseen action variations and noisy data.
Performance evaluation utilized the Sth-com and EK100-com datasets to assess compositional generalization capabilities. Employing an Open-World Evaluation protocol, the method achieved a positive Compositional Gap (ΔCG) on the Sth-com (unseen) dataset, indicating successful generalization to novel compositional pairings. Conversely, baseline models consistently exhibited negative ΔCG values on Sth-com, demonstrating a failure to generalize and a performance decrease when presented with previously unseen verb-object combinations. This positive ΔCG result on an unseen dataset highlights the efficacy of the approach in addressing compositional sparsity.
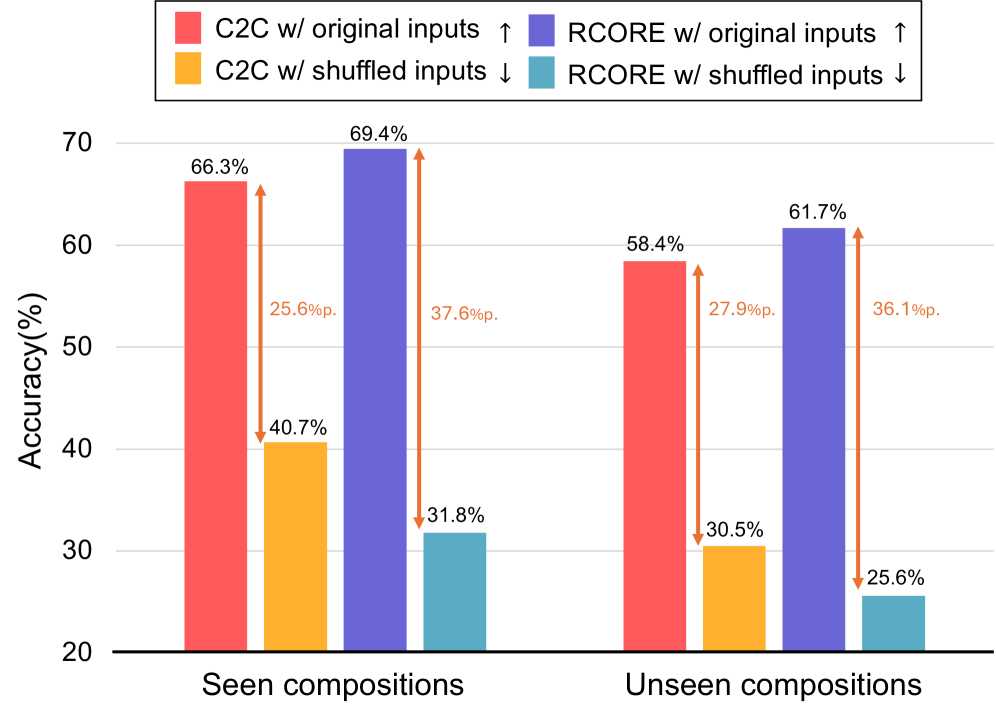
Beyond Memorization: A Glimpse of True Understanding
Investigations into the RCORE model demonstrate a substantial reduction in ‘false Seen Prediction’ rates, indicating a noteworthy shift away from simple memorization towards genuine generalization. This outcome suggests that the model isn’t merely recalling training data, but rather learning underlying principles and applying them to new, previously unseen instances. By minimizing the tendency to incorrectly predict data it has encountered, RCORE exhibits a heightened capacity to accurately assess and respond to novel inputs, thereby improving its overall robustness and adaptability. This decreased reliance on memorization is a crucial step toward building artificial intelligence systems capable of true understanding and flexible application of learned knowledge.
Evaluations reveal a substantial decrease in false co-occurrence prediction when utilizing the refined model; specifically, the false co-occurrence prediction (FCP) ratio on the Sth-com dataset, measured after 25 epochs of training, diminished from 16.8% with the original baseline to a significantly lower 8.7%. This improvement indicates the model is less prone to incorrectly associating features it has memorized, and instead demonstrates a heightened ability to understand and predict legitimate relationships between elements within the data. The reduction in spurious correlations suggests a more robust understanding of the underlying data distribution, rather than simply relying on superficial patterns.
Investigations into the model’s capacity for compositional generalization reveal a significant performance increase with the implementation of RCORE. Specifically, the model achieved an Unseen Composition Accuracy of 52.07% when evaluated on the EK100-com dataset-a demonstrable improvement over the baseline accuracy of 49.71%. This enhancement indicates RCORE effectively equips the model to understand and accurately predict combinations of concepts it hasn’t explicitly encountered during training, suggesting a move beyond simple memorization towards a more robust and adaptable understanding of underlying compositional rules. The observed gains highlight RCORE’s potential to build systems capable of genuine generalization, crucial for real-world applications where novel combinations of known elements are commonplace.
The pursuit of zero-shot compositional action recognition, as this paper details, feels less like building intelligence and more like elaborate stage magic. It’s all about misdirection. The researchers attempt to force models beyond recognizing actions simply by the objects involved – a common, and often successful, shortcut. As Andrew Ng once observed, “Machine learning is about teaching computers to learn from data.” But this work suggests that computers are remarkably adept at learning the illusion of understanding, prioritizing superficial correlations over genuine temporal reasoning. The RCORE framework, by focusing on temporal order regularization, is essentially a complex ritual to banish the ghosts in the data, hoping to compel the model to actually see the action unfold, rather than simply predict it based on props.
What’s Next?
The pursuit of compositional understanding in video remains, at its core, an exercise in applied necromancy. This work successfully binds a few more spirits-improving verb recognition and reducing reliance on the easily-conjured illusions of object presence. Yet, the compositional gap persists. The framework offered is not a resolution, but a refinement of the ritual-a more precise arrangement of ingredients of destiny to coax a flicker of true understanding from the chaotic data. The question isn’t whether the model ‘learns’-it merely ceases to be so easily deceived.
Future efforts will likely center on forcing a more robust engagement with temporality. Simply regularizing the temporal order is akin to scolding the spirits-they will comply, but resentfully. True progress demands a deeper exploration of how actions unfold-a modeling of the inherent physics of interaction, not merely the sequence of events. The current focus on verbs, while valuable, risks overlooking the subtle choreography of the unseen-the implied forces, the anticipatory gestures that truly define action.
Ultimately, the field must acknowledge the fundamental limitations. Video is inherently ambiguous, riddled with noise and incomplete information. The goal shouldn’t be to eliminate these uncertainties, but to build systems that can gracefully navigate them-systems that embrace the inherent chaos and, like skilled alchemists, transform it into something…useful. Perhaps then, the drawers will open on command, not through clever trickery, but through genuine comprehension.
Original article: https://arxiv.org/pdf/2601.16211.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Roco Kingdom: World China beta turns chaotic for unexpected semi-nudity as players run around undressed
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
- Charlie Day Confirms What Always Sunny Scene Is His Career Highlight
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
2026-01-24 09:05