Author: Denis Avetisyan
A new framework aims to imbue artificial intelligence with the ability to adapt not just its knowledge, but also the very processes it uses to reason and solve problems.
This review details a human-inspired approach to continuous learning, focusing on the development of adaptive cognitive systems that evolve internal reasoning processes alongside task execution.
While artificial intelligence excels at task-specific performance, a critical gap remains in its ability to fundamentally improve how it thinks. This paper, ‘Human-Inspired Continuous Learning of Internal Reasoning Processes: Learning How to Think for Adaptive AI Systems’, addresses this limitation by introducing a novel framework enabling AI systems to learn and refine their internal reasoning processes alongside task execution. The core innovation lies in treating these internal ‘thinking’ steps as primary learning objects, allowing the system to optimize not only what it knows, but also how it reasons and acts. Could this approach unlock truly adaptive cognitive architectures capable of sustained performance in complex, dynamic environments?
Deconstructing the Oracle: Limits of Pattern Recognition
Despite their remarkable ability to generate human-quality text and perform various language-based tasks, current Large Language Models (LLMs) frequently falter when confronted with problems demanding intricate, multi-step reasoning. These models, trained primarily on vast quantities of text, excel at pattern recognition and statistical correlations, but often lack the capacity for genuine causal inference or systematic problem decomposition. While they can convincingly simulate reasoning, their performance degrades rapidly as the number of necessary steps increases, or when tasks require planning, hypothetical thinking, or the integration of diverse pieces of information. This isn’t simply a matter of needing more data; even models with billions of parameters demonstrate limitations in tackling challenges that require more than superficial understanding, suggesting a fundamental constraint within their architectural design and training paradigms.
Despite the impressive performance gains achieved by increasing the size of large language models, a persistent challenge remains: simply adding more parameters doesn’t guarantee improved reasoning ability. Research indicates that beyond a certain point, scaling yields diminishing returns, suggesting a fundamental limitation in the current architectural approach. This isn’t a matter of insufficient knowledge; models possess vast amounts of information. Instead, the bottleneck lies in their capacity to effectively utilize that knowledge for complex problem-solving. The issue isn’t about what the model knows, but how it processes information and chains together logical steps – a capability not directly addressed by simply increasing model size. This suggests a need for architectural innovations that go beyond brute-force scaling, focusing on mechanisms for structured reasoning and improved cognitive control.
The limitations in complex reasoning exhibited by current Large Language Models aren’t simply a matter of insufficient data or model size; rather, they reveal a fundamental architectural gap in how these models handle information processing. Unlike human cognition, which actively maintains and updates an internal ‘workspace’ to track progress and relevance, LLMs often treat each input token in isolation, lacking a dedicated mechanism to preserve and prioritize crucial information across multiple reasoning steps. This absence of explicit state management leads to difficulties in tasks requiring sustained attention, contextual recall, and the ability to effectively filter out irrelevant details – essentially, the core components of deliberate, multi-step problem-solving. Consequently, even with vast knowledge stores, the model struggles to synthesize information in a coherent and goal-directed manner, hindering performance on challenges demanding more than simple pattern recognition or information retrieval.
True reasoning transcends mere information retrieval; it demands a dynamic process of action scheduling and continuous adaptation. Investigations reveal that simply possessing vast knowledge stores is insufficient for solving intricate problems, as models often fail to determine the optimal sequence of steps required. Instead, effective reasoning necessitates the ability to prioritize relevant information, formulate a plan of action, and revise that plan based on intermediate results. This mirrors cognitive processes observed in biological systems, where agents continuously assess their environment, predict outcomes, and adjust their behavior accordingly. Consequently, advancements in artificial reasoning hinge not only on expanding knowledge bases, but also on developing architectures that enable models to actively manage their internal state and learn from experience – effectively transforming them from passive responders to proactive problem-solvers.
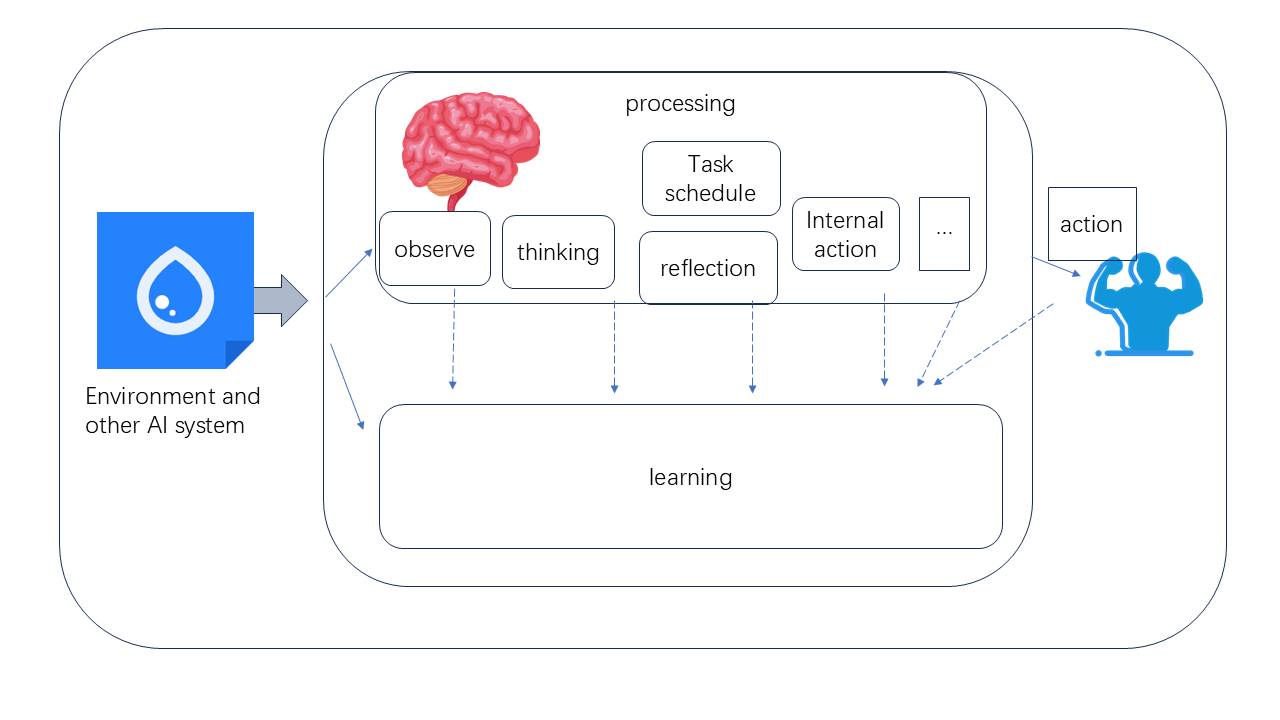
Re-Engineering Cognition: The Continuous Learning Framework
The Continuous Learning Framework is designed to replicate aspects of human cognitive function by consolidating internal reasoning, action execution, and learning processes within a single, integrated system. Unlike conventional approaches that treat these functions as separate modules, this framework emphasizes their interconnectedness. Specifically, the system allows for dynamic allocation of resources between reasoning about a problem, taking actions in an environment, and updating its internal knowledge base based on the outcomes of those actions. This unification aims to improve adaptability and efficiency by enabling the system to learn from its experiences and refine its decision-making processes in real-time, mirroring the iterative cycle observed in human cognition.
The Continuous Learning Framework incorporates explicit mechanisms for action scheduling and prioritization of internal reasoning. This is achieved through a control module that manages a queue of potential reasoning activities and actions, assigning priority based on factors such as urgency, relevance to current goals, and resource availability. The system dynamically adjusts these priorities based on feedback from both internal state and external observations. Specifically, the framework utilizes a weighted scoring system to determine the order in which reasoning tasks – including planning, problem-solving, and knowledge retrieval – are executed, ensuring that the most critical cognitive processes receive immediate attention and resources. This allows the framework to simulate selective attention and focus, key components of human cognition, and to efficiently allocate computational resources.
The Continuous Learning Framework utilizes a dual-process approach to information processing, employing both sequential reasoning and parallel learning mechanisms. Sequential reasoning enables deliberate, step-by-step planning and problem-solving, allowing the framework to establish and execute complex strategies. Complementing this is parallel learning, which facilitates rapid adaptation to dynamic environments by simultaneously evaluating multiple inputs and adjusting internal parameters without requiring explicit, pre-defined plans. This combination allows the framework to address both well-defined tasks requiring foresight and unpredictable situations demanding immediate response, increasing overall robustness and efficiency.
Traditional Large Language Models (LLMs) are fundamentally stateless, processing each input independently and lacking persistent memory of prior interactions or reasoning steps. The Continuous Learning Framework addresses this limitation by incorporating an external memory module that serves as a dedicated space for storing and retrieving internal state information. This explicit state management allows the framework to maintain context across multiple interactions, enabling more complex reasoning and planning capabilities. By decoupling state from the model’s parameters, the framework avoids the computational cost and limitations associated with attempting to encode long-term dependencies within the LLM itself, and facilitates efficient knowledge retention and recall beyond the confines of a fixed context window.
Adaptive Intelligence: The Art of Self-Refinement
The Continuous Learning Framework utilizes meta-learning techniques, specifically “learning to learn,” to dynamically refine its own learning algorithms. This is achieved by treating the learning process itself as an optimization problem, where the framework adjusts hyperparameters and internal strategies based on performance feedback. Rather than relying on fixed learning rules, the agent develops the capacity to autonomously improve its ability to acquire and generalize knowledge over time. This involves identifying and exploiting patterns in learning experiences to optimize future learning episodes, leading to increased efficiency and adaptability in novel situations. The framework effectively learns how to learn, allowing it to surpass the limitations of static learning methodologies.
Process supervision within the adaptive intelligence framework involves evaluating the correctness of intermediate reasoning steps, rather than solely assessing the final outcome. This granular assessment enables targeted optimization of specific reasoning components, improving overall performance and efficiency. By providing feedback at each stage of the process, the framework mitigates catastrophic forgetting – the abrupt loss of previously learned information – as adjustments are localized and do not require wholesale retraining of the entire system. This approach allows the agent to refine its reasoning processes incrementally, retaining existing knowledge while acquiring new capabilities, and ensures that errors are identified and corrected during computation, rather than only after completion.
Parameter-efficient fine-tuning within the adaptive intelligence framework utilizes techniques such as low-rank adaptation (LoRA) and adapters to modify only a small subset of the model’s parameters during adaptation to new tasks or domains. This approach drastically reduces the computational cost and memory requirements compared to full fine-tuning, which updates all model parameters. By freezing the majority of the pre-trained model weights and introducing a limited number of trainable parameters, the framework can achieve performance comparable to full fine-tuning while requiring significantly fewer computational resources and storage space. This is particularly beneficial when deploying the adaptive intelligence system on resource-constrained devices or when dealing with a large number of diverse tasks, as it allows for rapid adaptation without incurring prohibitive computational overhead.
Fixed code replacement within the adaptive intelligence framework facilitates the integration of new functionalities and knowledge without requiring extensive retraining of the core model. This is achieved by defining modular code blocks that correspond to specific procedures or knowledge components. When an update or new capability is required, the corresponding code block is replaced with a revised version, effectively altering the agent’s behavior. This approach minimizes computational overhead and prevents catastrophic forgetting, as only the modified component undergoes adaptation, leaving the established knowledge base intact. The framework utilizes a defined interface for these code blocks, ensuring compatibility and seamless integration with existing systems.
Real-World Impact: Monitoring the Infrastructure
The architecture’s capacity for sophisticated reasoning becomes strikingly apparent when applied to the challenge of sensor abnormality detection. By moving beyond simple threshold-based alerts, the framework can analyze intricate patterns within sensor data-considering historical trends, correlations with other sensor readings, and even contextual information-to accurately pinpoint malfunctioning devices. This isn’t merely about identifying outliers; it’s about understanding why a sensor reading deviates, enabling proactive maintenance and preventing cascading failures in complex systems. The system effectively mimics a human expert’s diagnostic process, weighing multiple factors before arriving at a conclusion, and crucially, refining its reasoning abilities with each new observation, resulting in more reliable and efficient infrastructure monitoring.
The framework demonstrates a robust capacity for pinpointing device malfunctions within sensor networks by intelligently consolidating data from multiple sources, notably temperature sensors. This isn’t simply a matter of registering temperature fluctuations; the system correlates readings with other relevant data-such as historical performance, environmental factors, and readings from neighboring sensors-to establish a baseline of normal operation. Deviations from this learned baseline, even subtle ones, trigger a diagnostic process, allowing the framework to accurately identify and flag malfunctioning devices. This integrated approach significantly reduces false positives and enhances the reliability of anomaly detection, proving vital for maintaining the efficiency of systems reliant on continuous data streams and prompting timely interventions before minor issues escalate into critical failures.
The framework’s adaptability extends beyond theoretical computation, offering tangible benefits to the operation of critical infrastructure. By continuously learning and refining its reasoning processes, the system minimizes downtime and optimizes performance in real-world deployments. This proactive approach to maintenance, demonstrated through applications like temperature sensor abnormality detection, allows for the identification of failing components before they cause significant disruptions. Consequently, industries reliant on consistent operation – including power grids, manufacturing plants, and transportation networks – stand to gain substantially from increased reliability, reduced operational costs, and improved overall efficiency through the integration of this intelligent system.
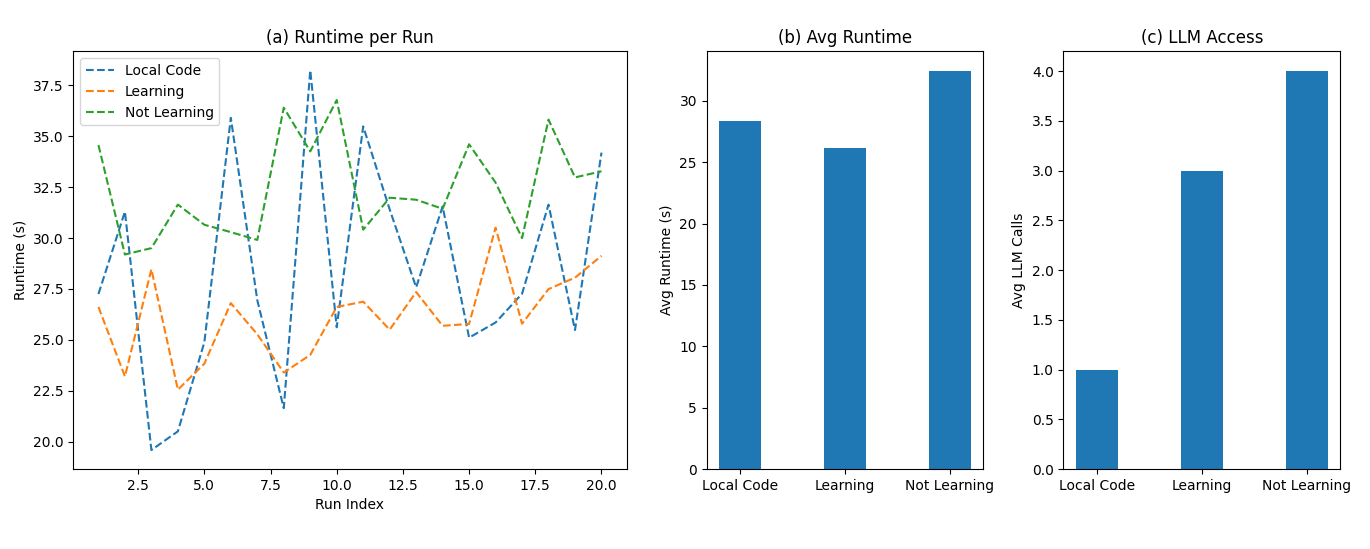
A significant benefit of the developed continuous learning framework lies in its demonstrable efficiency gains when applied to practical tasks. Specifically, when tasked with identifying anomalies from temperature sensor data, the framework achieved a 23.9% reduction in average runtime. This translates to a decrease from an initial processing time of 32.42 seconds to a more streamlined 26.16 seconds. This improvement isn’t simply a matter of faster processing; it stems from the framework’s capacity to learn and refine its internal reasoning processes, enabling it to more quickly and accurately pinpoint malfunctioning devices within a sensor network. The ability to adapt and optimize its approach represents a key advancement, suggesting substantial potential for real-time monitoring and control applications where rapid response is crucial.
Beyond Simulation: The Future of Agent Intelligence
The emergence of truly intelligent agents hinges on systems capable of more than just responding to prompts; they require a capacity for sustained learning and adaptive problem-solving. Recent advancements have converged on the Continuous Learning Framework, which integrates techniques like ReAct – reasoning and acting in a loop – and Toolformer, enabling agents to utilize external tools. This synergistic approach moves beyond static knowledge, allowing agents to refine their understanding and capabilities through ongoing interaction with dynamic environments. By seamlessly blending reasoning, action execution, and learning, these agents demonstrate a capacity to tackle complex challenges, not simply by recalling information, but by actively constructing solutions and improving performance over time – a crucial step toward artificial general intelligence.
Intelligent agents are evolving beyond simple task completion to exhibit a unified capacity for reasoning, action, and continuous learning, allowing them to tackle increasingly complex challenges within unpredictable settings. This integration isn’t merely about chaining together separate processes; rather, it represents a synergistic approach where each component informs and enhances the others. An agent equipped with this capability can, for example, analyze a situation, formulate a plan, execute steps, and then critically evaluate the outcome – not just to correct errors, but to refine its understanding of the environment and improve future performance. Consequently, these agents demonstrate resilience and adaptability, moving beyond pre-programmed responses to navigate novel situations and solve problems that demand genuine cognitive flexibility, mirroring-though not replicating-elements of human intelligence in dynamic real-world scenarios.
Advancing agent intelligence necessitates a deeper understanding of human cognitive processes, specifically how humans simulate potential outcomes and adapt to unforeseen circumstances. Current artificial intelligence often struggles with nuanced situations requiring common sense or intuitive leaps, areas where human simulation excels. Researchers are now exploring methods to imbue agents with similar predictive capabilities, allowing them to not merely react to stimuli, but to anticipate consequences and proactively adjust strategies. This pursuit involves modeling human decision-making under uncertainty, incorporating elements of embodied cognition, and developing algorithms that prioritize exploration and learning from limited data. Successfully replicating these human traits promises agents capable of navigating complex, real-world scenarios with a level of adaptability and resourcefulness previously unattainable, moving beyond simple task completion towards genuine intelligence.
A newly developed continuous learning framework demonstrably improves the efficiency of large language model (LLM) interactions. Rigorous testing revealed a reduction in the average number of LLM queries required to complete a task, decreasing from four interactions in a baseline assessment to just three. This optimization isn’t merely anecdotal; statistical analysis confirms the runtime reduction is statistically significant, with a p-value of less than 0.05. Such gains represent a crucial step towards more practical and scalable agent intelligence, suggesting a pathway for complex problem-solving with reduced computational cost and increased speed.
The pursuit of adaptive AI, as detailed in this work, necessitates a departure from static intelligence. The system’s capacity to not merely learn but to refine its own reasoning-to evolve how it thinks-is the crucial innovation. This mirrors a fundamental principle of robust systems: continuous self-assessment and structural adaptation. As Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” This echoes the core concept of the reasoning-action loop; the system can only improve its thought processes based on the feedback derived from executing tasks-it doesn’t invent new logic, but optimizes existing pathways. Every iteration is a test, every successful adaptation a tacit admission that prior structure wasn’t perfect, and a refinement toward greater efficiency.
Beyond the Algorithm: Future Directions
The pursuit of adaptive AI necessitates a dismantling of the static model. This work, by focusing on the evolution of internal reasoning itself, correctly identifies that intelligence isn’t merely data accumulation, but the refinement of the processing architecture. However, the true test lies in scalability. Current frameworks excel in constrained environments; the leap to genuinely unpredictable, real-world scenarios demands a reckoning with the inherent messiness of information. A system that learns how to think must also learn when to unthink, to discard previously valuable heuristics as conditions shift.
A critical, often overlooked limitation is the definition of ‘good’ reasoning. The evaluation metrics, while functional, remain tethered to pre-defined task success. Future work should explore intrinsic motivation – can an AI system develop an internal compass for evaluating the elegance or efficiency of its own thought processes, independent of external reward? The long-term goal isn’t to mimic human cognition, but to surpass it-and that requires an embrace of fundamentally different, potentially non-biological, modes of reasoning.
Ultimately, the field must confront the question of control. A system that self-modifies its reasoning processes is, by definition, less predictable. True security isn’t achieved through complex obfuscation, but through radical transparency – a complete understanding of the system’s internal logic, even as that logic evolves. Only then can one confidently claim to have built, not merely programmed, an intelligent agent.
Original article: https://arxiv.org/pdf/2602.11516.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Total Football free codes and how to redeem them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Gold Rate Forecast
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
- Nicole Kidman and Jamie Lee Curtis elevate new crime drama Scarpetta, which is streaming now
2026-02-14 00:06