Author: Denis Avetisyan
A new framework, IntentCUA, bridges the gap between raw user actions and high-level goals, enabling more robust and efficient automation of complex computer tasks.
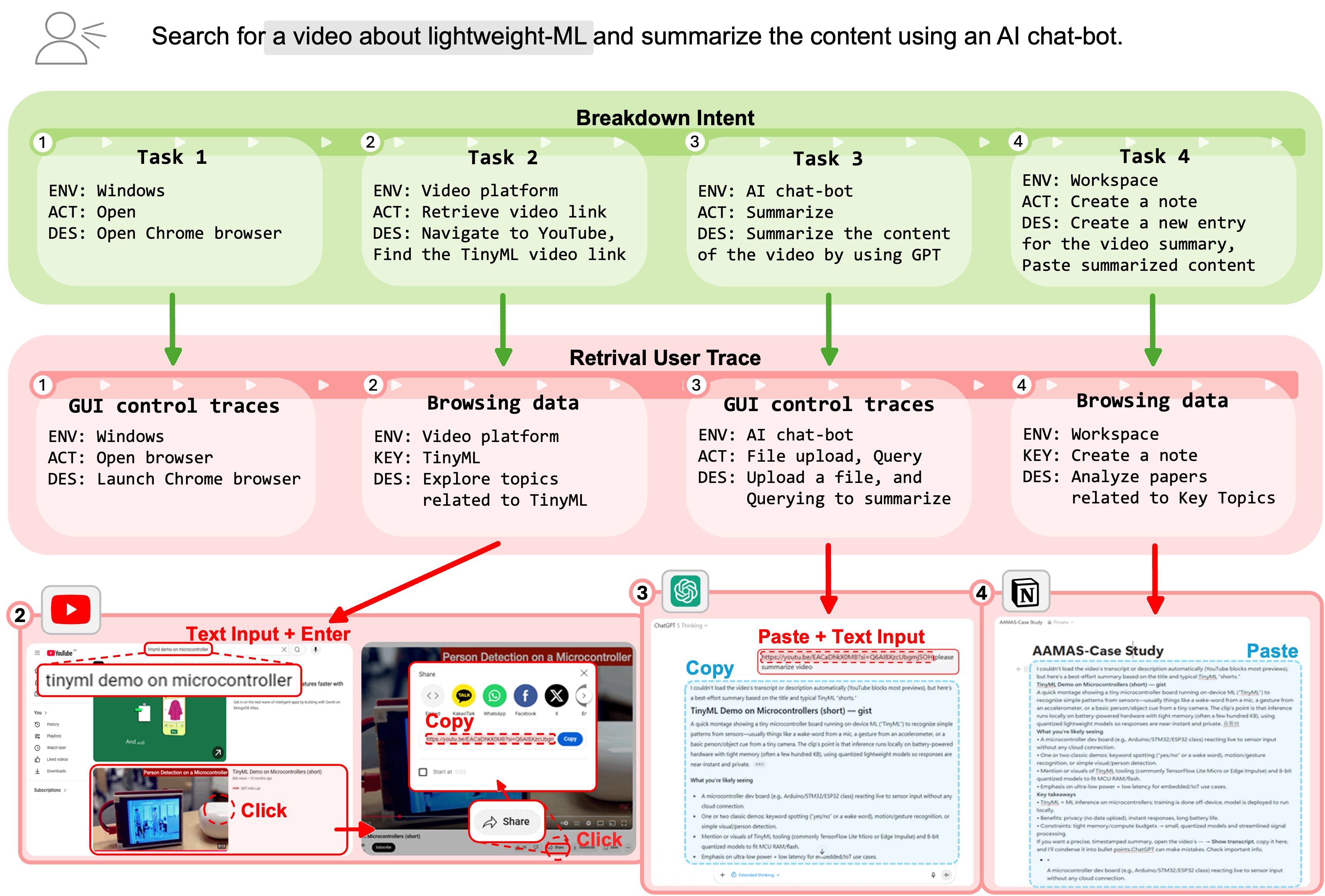
IntentCUA learns reusable skills from user traces, abstracts intent, and integrates plan memory for improved long-horizon task completion in multi-agent systems.
Long-horizon computer-use tasks are often plagued by error accumulation and inefficiency due to challenges in maintaining user intent over extended interactions. To address this, we introduce ‘IntentCUA: Learning Intent-level Representations for Skill Abstraction and Multi-Agent Planning in Computer-Use Agents’, a framework that stabilizes desktop automation by learning reusable skills from intent-level representations of user actions and integrating them with shared plan memory. Our multi-agent system achieves a 74.83% task success rate and a Step Efficiency Ratio of 0.91, significantly outperforming existing approaches. Can system-level intent abstraction and memory-grounded coordination unlock truly robust and efficient automation in complex, dynamic desktop environments?
Deciphering Intent: A Multi-View Representation
Conventional automation systems frequently falter due to their inability to accurately decipher what a user truly intends, rather than simply what they say. This inherent ambiguity arises because systems typically rely on rigid keyword matching or predefined scripts, proving inadequate when confronted with the nuances of natural language or unforeseen circumstances. Consequently, these systems are often described as ‘brittle’ – easily broken by slight variations in input – and demonstrate limited reliability in real-world applications. A user’s request, seemingly straightforward, can hold multiple interpretations depending on the context, leading to errors and frustration. This susceptibility to misinterpretation fundamentally restricts the adaptability and robustness of traditional automation, hindering its potential for truly intelligent and helpful assistance.
IntentCUA presents a significant advancement in automation by leveraging a ‘Multi-view Intent Representation’ designed to comprehensively capture user goals. This framework moves beyond simplistic interpretations by analyzing intent through three distinct, yet interconnected, lenses: the surrounding environment, the specific actions a user intends to perform, and rich descriptive context providing further nuance. By integrating these perspectives, IntentCUA constructs a holistic understanding of what a user wants to achieve, allowing systems to discern meaning even with ambiguous phrasing or incomplete instructions. This multi-faceted approach is critical for building adaptable automation capable of handling the complexities of real-world interactions, ultimately fostering more reliable and intuitive user experiences.
The true potential of automation lies not in responding to explicit commands, but in anticipating user needs – a feat hindered by the limitations of keyword-based systems. A multi-view intent representation moves beyond this brittle approach by constructing a holistic understanding of what a user means, rather than simply what they say. This richer model integrates environmental context, the actions a user intends to perform, and descriptive details of the desired outcome, allowing automated systems to handle ambiguity and adapt to unforeseen circumstances. Consequently, this representation unlocks a level of robustness previously unattainable, enabling automation to function reliably even when faced with imprecise language, incomplete information, or changing conditions – effectively bridging the gap between human intention and machine execution.
![A multi-view encoder aligns control ([E,A,D]) and browsing ([E,K,D]) traces into a shared representation, facilitating both environment-centric intent grounding (IG) and skill generalization (SG) via centroid retrieval and the creation of parameterized skill schemas-or “skill hints”-for downstream planning.](https://arxiv.org/html/2602.17049v1/figures/figure2.png)
Constructing a Robust Framework for Long-Term Planning
IntentCUA employs a ‘Planner’ module responsible for breaking down user commands into discrete, executable plan units. This decomposition process is significantly enhanced by the system’s ‘Plan Memory’, which functions as a repository for previously successful plans and reusable skill templates. Stored plans aren’t simply recalled; the Planner actively leverages them to accelerate new plan creation and reduce computational overhead. Skill templates define common action sequences, allowing the system to generalize from past experiences and apply them to novel, yet related, tasks. The Plan Memory’s capacity to retain and retrieve these elements is central to IntentCUA’s efficiency and adaptability, minimizing the need for repetitive planning procedures.
The Plan-Optimizer component translates decomposed plan units into specific graphical user interface (GUI) actions executable by the system. Following execution, a ‘Critic’ module assesses the resulting system state to determine if the desired outcome was achieved. If discrepancies are detected, the Critic initiates a local re-optimization process, adjusting parameters within the current plan unit to improve reliability and ensure successful completion of the task without requiring a full replanning cycle. This post-execution validation and localized adjustment contribute to the system’s robustness and adaptability to varying conditions.
The IntentCUA system’s modular architecture, comprising the Planner, Plan Memory, Plan-Optimizer, and Critic, facilitates adaptability and efficiency by decoupling command decomposition, plan storage, action grounding, and validation. This separation allows the system to generalize learned skills to novel situations without requiring complete retraining; successful plan units and skill templates stored in the Plan Memory can be readily reused and adapted via local re-optimization performed by the Critic. Consequently, the system can handle a diverse range of tasks with reduced computational cost and improved robustness compared to monolithic approaches that necessitate retraining for each new command or environment.
![A planner-optimizer-critic framework decomposes commands into executable GUI actions, iteratively refining the plan based on critic feedback on the resulting state [latex]S^{\text{after}}[/latex].](https://arxiv.org/html/2602.17049v1/figures/interaction.png)
Abstracting Actions into Reusable Skills
Hierarchical Skill Abstraction is implemented to consolidate similar intent representations derived from interaction traces into reusable skills. This process involves clustering intents based on their feature vectors, allowing the framework to identify and group actions that achieve comparable goals. By abstracting these commonalities, the system reduces the need to relearn similar skills for slightly varied tasks. The resulting hierarchical structure facilitates efficient skill reuse and transfer, ultimately enhancing the agent’s ability to generalize to new situations and improve performance across diverse environments.
The system leverages HDBSCAN, a density-based spatial clustering algorithm, to group similar user intents without requiring a pre-defined number of clusters. HDBSCAN identifies clusters based on the density of data points, effectively isolating core samples with sufficient neighboring points, while filtering out noise and outliers. This approach is particularly suited for intent representation clustering as it automatically determines the optimal number of skills based on the inherent structure of the interaction data, avoiding the limitations of k-means or other methods requiring a fixed cluster count. The algorithm’s parameters control minimum cluster size and minimum sampling distance, allowing for fine-grained control over the abstraction process and the resulting skill granularity.
The framework’s capacity for domain generalization and successful execution of previously unseen tasks is directly linked to its skill abstraction process. This capability was quantitatively assessed using a Density Separation score, which measured the distinctness of learned skill clusters; the framework achieved a score of 7.74. This represents a substantial performance improvement compared to methods relying solely on InfoNCE contrastive learning, which yielded a Density Separation score of 5.64 under identical conditions. The higher score indicates a more robust and separable representation of skills, enabling more effective transfer to novel tasks and environments.
Demonstrating Superior Performance in Complex Scenarios
IntentCUA’s capabilities were rigorously tested through complex, multi-step tasks – scenarios demanding ‘Long-Horizon Planning’. These weren’t simple, single-action requests, but rather intricate procedures requiring the system to successfully chain together numerous sequential actions to achieve a final goal. The system’s performance in these demanding situations highlights its ability to not just initiate tasks, but to maintain focus and accuracy across extended interactions. This demonstrates a crucial step towards creating AI agents capable of handling real-world complexities that often necessitate prolonged and nuanced planning, exceeding the limitations of systems designed for immediate, short-term objectives.
The efficacy of any planning system hinges not only on completing a task, but on how efficiently it navigates the necessary sequence of actions. To quantify this, researchers employed the ‘Step Efficiency Ratio’ (SER), a metric that assesses the proportion of successful steps within a completed plan. A high SER indicates a robust system capable of minimizing errors and wasted actions during execution. This focuses the evaluation beyond simple task completion, highlighting the system’s ability to formulate and adhere to a streamlined, effective plan – a crucial distinction when considering complex, multi-stage goals where even minor inefficiencies can accumulate and lead to failure.
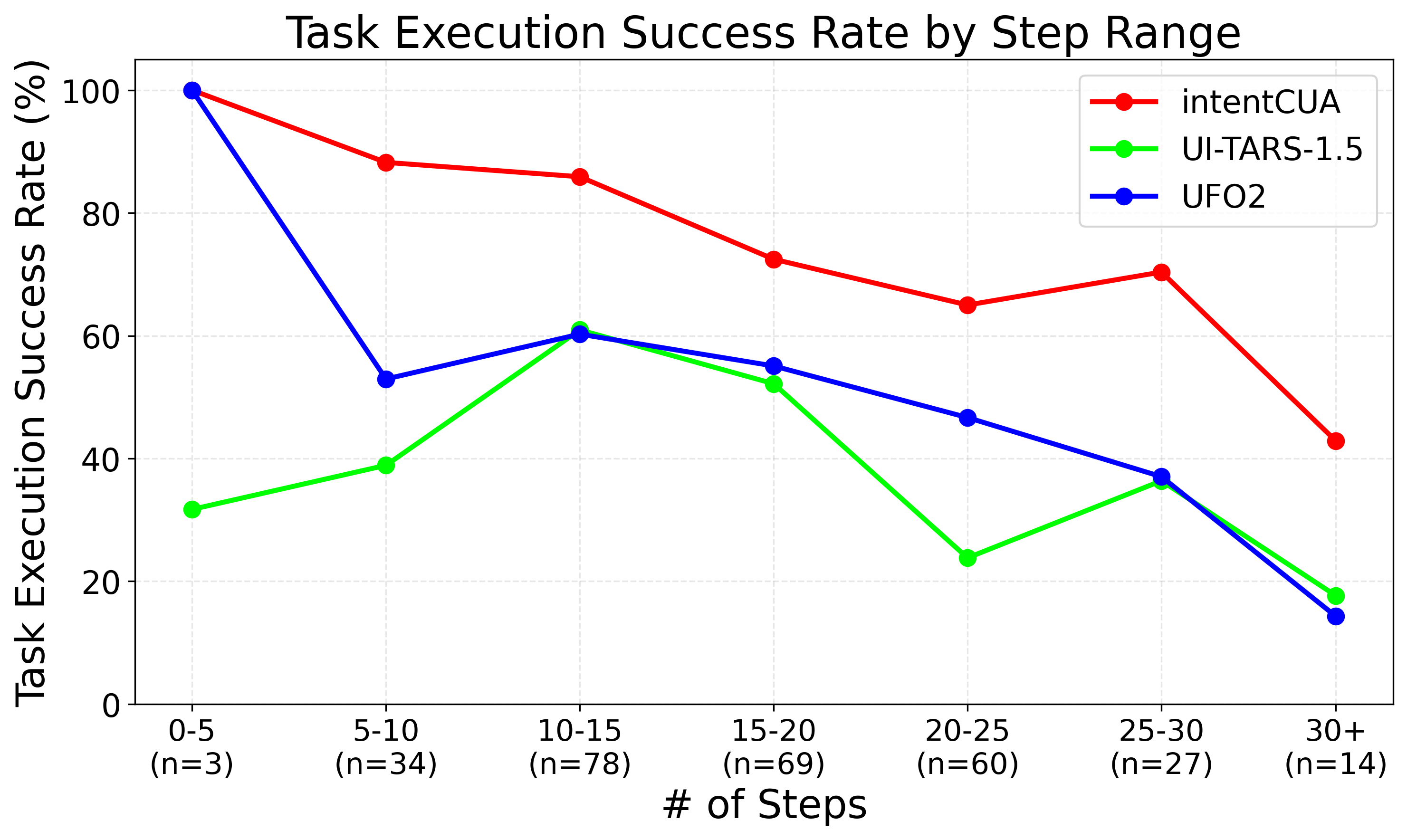
Evaluations demonstrate IntentCUA’s superior performance in completing complex tasks; the system achieved a 74.8% success rate, significantly exceeding the 38.8% and 51.2% rates of UI-TARS-1.5 and UFO2, respectively. This success is further quantified by a Step Efficiency Ratio of 0.91, indicating nearly every action contributes to task completion. Beyond simply achieving goals, IntentCUA operates with remarkable speed, completing tasks in an average of 1.46 minutes – a substantial improvement over the 6.63 minutes required by UFO2 and the 9.82 minutes of UI-TARS. These results collectively highlight IntentCUA’s ability to not only successfully navigate complex scenarios, but to do so with both precision and efficiency.
The pursuit of robust automation, as detailed in IntentCUA, demands a focus on provable correctness rather than merely functional behavior. The framework’s emphasis on intent-level representations, abstracting user traces into reusable skills, echoes a mathematical elegance-a decomposition into fundamental, verifiable components. Grace Hopper famously stated, “It’s easier to ask forgiveness than it is to get permission.” While perhaps not directly applicable to formal verification, the spirit resonates; IntentCUA doesn’t simply make automation happen, it strives to understand the underlying intent, creating a system that is inherently more reliable and, crucially, more transparent-revealing the invariant behind the seemingly magical act of desktop control. This commitment to clarity is paramount when dealing with long-horizon tasks.
What’s Next?
The pursuit of robust automation, as exemplified by IntentCUA, inevitably confronts the inherent ambiguity of intention. While the framework demonstrably stabilizes long-horizon tasks, the leap from observed user traces to genuinely reliable intent representation remains a challenge. The current approach, reliant on learning from finite datasets, implicitly assumes stationarity – a dangerous proposition in the ever-evolving landscape of software interfaces. A truly elegant solution would demand a degree of formal verification; a provable guarantee that the abstracted skill corresponds to the intended outcome, irrespective of superficial interface changes.
Furthermore, the integration with plan memory, while pragmatic, skirts the issue of combinatorial explosion. Scaling this approach to genuinely complex, multi-agent scenarios requires more than incremental optimization. The field should consider exploring alternative planning paradigms-perhaps drawing inspiration from formal methods in artificial intelligence-that prioritize provable completeness and optimality, even at the cost of computational expense. The current emphasis on ‘working on tests’ is insufficient; the goal is not merely to simulate intelligence, but to formalize it.
Ultimately, the true test of IntentCUA, and indeed the entire field of GUI automation, lies not in automating existing tasks, but in enabling agents to generalize to unseen tasks. This necessitates a shift in focus: from learning representations of actions, to learning representations of principles. Only then can automation transcend the limitations of mere imitation and approach something resembling genuine autonomy.
Original article: https://arxiv.org/pdf/2602.17049.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Limbus Company 2026 Roadmap Revealed
- Clash of Clans April 2026 Gold Pass Season introduces a Archer Queen skin
- Total Football free codes and how to redeem them (March 2026)
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- Gold Rate Forecast
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
2026-02-21 15:29