Author: Denis Avetisyan
A new paradigm is emerging where large language models aren’t just responding to prompts, but actively learning and applying specific skills to complete complex tasks.
![Agent skills are structured through a progressive disclosure architecture, loading information in stages to efficiently manage context window limitations while retaining access to complex procedural knowledge, with token estimations reflecting per-skill averages as detailed in prior work [35].](https://arxiv.org/html/2602.12430v1/x1.png)
This review examines the architecture, acquisition, security, and governance of agent skills for large language models and computer-use agents.
While large language models demonstrate impressive capabilities, their monolithic nature limits adaptability and efficient scaling for complex tasks. This survey, ‘Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward’, examines the emerging paradigm of ‘agent skills’ – composable modules of code, instructions, and resources – as a means of dynamically extending LLM functionality without retraining. The work details architectural foundations, acquisition methods like reinforcement learning and autonomous discovery, deployment in computer-use agents, and critically, reveals significant security vulnerabilities in existing community-contributed skills-leading to a proposed governance framework. Given that 26.1% of current skills exhibit vulnerabilities, how can we build trustworthy, self-improving skill ecosystems that unlock the full potential of agentic systems?
The Evolving Architecture of Agency: Beyond Simple Recall
Large Language Models (LLMs) demonstrate remarkable proficiency in accessing and processing vast quantities of information, effectively serving as powerful knowledge repositories. However, this broad knowledge base doesn’t automatically translate to competence in performing intricate, step-by-step tasks requiring specific procedural knowledge. While an LLM can readily recall the rules of chess, for instance, it cannot autonomously play a strategic game, lacking the embodied understanding of move evaluation and long-term planning that a skilled player possesses. This limitation arises because LLMs are primarily trained to predict the next token in a sequence – a fundamentally different skillset than executing a series of actions to achieve a defined goal. Consequently, bridging the gap between informational recall and practical application requires augmenting these models with specialized capabilities beyond simple knowledge access.
Retrieval-Augmented Generation (RAG), while initially promising, often proves insufficient for tasks demanding consistent and reliable performance. Simply providing a Large Language Model (LLM) with relevant information doesn’t inherently equip it to do anything with that knowledge. An LLM, even with contextual data, can struggle with the procedural reasoning – the step-by-step execution – required for complex actions. RAG systems frequently deliver information without structuring how that information should be applied, leading to outputs that may be factually correct but pragmatically unhelpful or even incorrect in their application. The limitation isn’t a lack of data, but a deficit in the actionable guidance necessary to translate knowledge into dependable behavior, highlighting the need for more sophisticated approaches to agent skill development.
The limitations of simply providing large language models with more data have spurred a move towards constructing specialized ‘Agent Skills’. These skills represent a modular approach to artificial intelligence, encapsulating specific procedural knowledge and expertise – such as flawlessly executing a complex API call, parsing a legal document with precision, or controlling a robotic arm for a delicate task. Unlike traditional methods that rely on broad knowledge and retrieval, Agent Skills are designed for on-demand application, allowing an AI to dynamically assemble the necessary capabilities for any given challenge. This paradigm enables greater reliability, adaptability, and reusability; a skill honed for one task can be readily integrated into another, fostering a more efficient and versatile artificial intelligence capable of tackling increasingly complex real-world problems.
Defining Expertise: The Specification of Agent Skills
The SKILL.md file employs a standardized YAML-based format to comprehensively define Agent Skills. This includes a mandatory “purpose” field outlining the skill’s intended function, a detailed “instructions” section specifying the steps for execution – often utilizing natural language processing directives – and a “resources” declaration listing all required external dependencies such as APIs, data access permissions, or specific software packages. This structured approach facilitates automated skill validation, version control, and deployment, ensuring consistent and predictable behavior across different environments. The file format also allows for the inclusion of metadata regarding skill author, creation date, and licensing information, aiding in governance and auditability.
Capability-based permissions represent a security model where access to resources is granted based on the capabilities a skill possesses, rather than identity-based authorization. This approach requires skills to explicitly declare the specific resources and actions needed for operation, limiting potential damage from compromised or malicious code. By requesting only necessary permissions, the attack surface is significantly reduced, minimizing the risk of privilege escalation and unauthorized data access. This contrasts with traditional access control lists (ACLs), which can inadvertently grant excessive privileges. Implementing capability-based permissions necessitates a mechanism for verifying declared capabilities and enforcing access restrictions at runtime, ensuring skills operate within defined boundaries and promoting a more secure and auditable system.
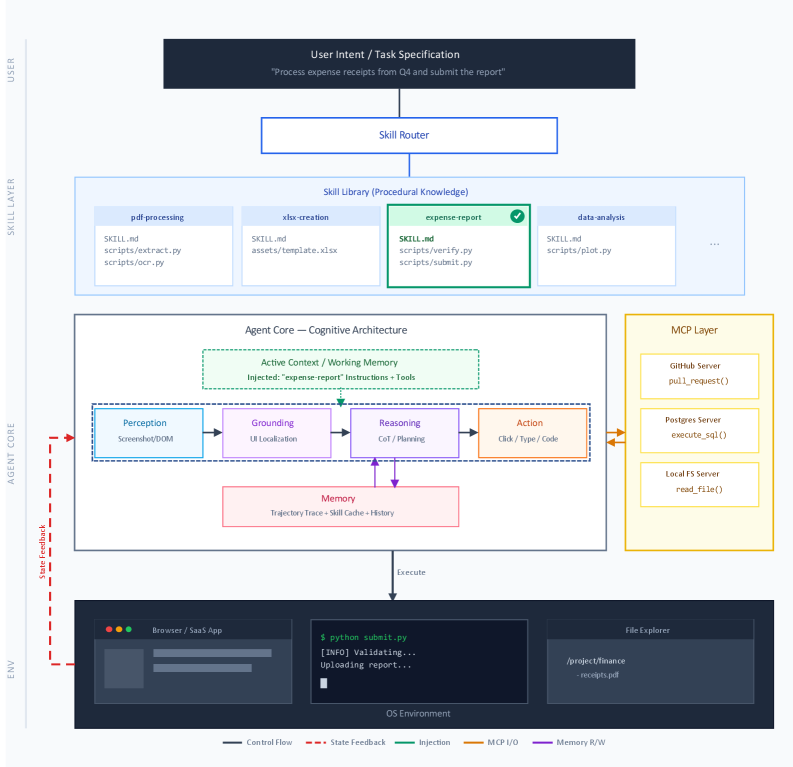
A Skill Trust and Lifecycle Governance Framework establishes procedures for verifying the integrity of Agent Skills throughout their entire operational period. This framework incorporates mechanisms for initial validation-ensuring the skill functions as designed and adheres to security protocols-and ongoing monitoring to detect anomalous behavior or deviations from established parameters. Governance policies define access controls, data handling procedures, and update management, critical for maintaining skill reliability in dynamic environments where underlying data sources and system dependencies may change. Regular audits, version control, and a defined deactivation process are integral components, ensuring accountability and mitigating potential risks associated with compromised or outdated skills.
![This survey proposes an original Skill Trust and Lifecycle Governance Framework that unifies skill provenance, verification through a four-stage pipeline [latex]G_1-G_4[/latex], and deployment permissions based on four trust tiers [latex]T_1-T_4[/latex]-supported by empirical evidence and runtime monitoring-to establish a lifecycle of trust and minimize attack surfaces.](https://arxiv.org/html/2602.12430v1/x3.png)
Autonomous Skill Acquisition: Evidence from Automated Discovery and Reinforcement
Automated skill discovery, as demonstrated by the SEAgent framework, enables agents to independently identify and implement functional skills within software environments without explicit programming. This process involves the agent interacting with the software, observing the results of its actions, and iteratively refining its understanding of which actions contribute to successful task completion. Evaluations of SEAgent have shown a 34.5% task goal completion rate, indicating a substantial level of autonomous functionality achieved through this discovery-based approach. This performance metric represents the percentage of defined tasks the agent can successfully complete utilizing only discovered skills, without reliance on pre-defined skill libraries or human intervention.
The SAGE approach utilizes reinforcement learning to facilitate autonomous skill acquisition in agents operating within software environments. This method allows agents to learn through iterative trial and error, receiving rewards for successful actions and penalties for unsuccessful ones, ultimately optimizing performance over time. Empirical results demonstrate that agents employing the SAGE reinforcement learning framework achieve an 8.9% improvement in task completion rates when compared to a baseline Generalized Rollout Policy Optimization (GRPO) implementation lacking pre-defined skill libraries. This performance gain indicates the efficacy of learning skills directly through interaction with the environment rather than relying on pre-programmed behaviors.
CUA-Skill is a framework designed for computer-use agents that utilizes a parameterized execution graph to represent and execute skills. This approach structures skill representations, allowing agents to generalize across varying task parameters and environments. Evaluations demonstrate a 57.5% task success rate when employing CUA-Skill, a substantial improvement over methods lacking such structured skill representations. The parameterized graph enables the agent to adapt pre-defined skills to new situations without requiring retraining, increasing efficiency and robustness in computer-based task completion.
Composing Intelligent Systems: Skill Combination and Resource Optimization
The ability to dissect intricate tasks into a sequence of specialized skills represents a fundamental shift in artificial intelligence architecture. Rather than relying on monolithic models attempting to perform everything at once, this approach, known as skill composition, enables agents to leverage a diverse toolkit of focused capabilities. Each skill – perhaps one dedicated to identifying buttons, another to reading text, and yet another to executing mouse clicks – operates as a modular component. These components are then orchestrated to collaboratively address complex objectives, such as completing a software installation or navigating a website. This decomposition not only enhances the robustness of the system, as errors in one skill are less likely to cascade and disrupt the entire process, but also promotes efficiency by allowing the agent to apply precisely the right tool for each sub-task, mirroring the way humans approach problem-solving.
Progressive disclosure represents a strategic approach to resource management within complex AI systems. Rather than loading all potential skills at the outset, this technique prioritizes the sequential activation of capabilities only as they become relevant to the task at hand. This staged loading significantly minimizes the consumption of the context window – a critical limitation in large language models – by preventing unnecessary information from occupying valuable processing space. The result is a more efficient and scalable system, capable of tackling intricate challenges without being overwhelmed by computational demands, and allowing for more complex reasoning with limited resources.
The UI-TARS agent demonstrably benefits from skill combination and progressive disclosure, achieving significant performance gains on graphical user interface benchmarks. Evaluations on the OSWorld suite reveal an 18.9% improvement in accuracy when compared to the Claude Computer Use and a prior iteration of UI-TARS. Notably, the system exhibits a remarkable capacity for self-improvement; leveraging a self-evolutionary training process, UI-TARS further elevates its accuracy by an impressive 47.3%. These results underscore the potential of compositional skill design and optimized resource management to build more capable and efficient computer-use agents, paving the way for more effective human-computer interaction.
Towards Trustworthy Agency: Addressing Vulnerabilities and Securing the Future
Agent Skills, while powerful, are susceptible to a critical security flaw known as prompt injection. This vulnerability allows malicious actors to manipulate an agent’s intended behavior by crafting specific inputs that hijack the prompting process. A comprehensive analysis of 42,447 Agent Skills revealed a concerning prevalence of this issue, with 26.1% exhibiting at least one vulnerability to prompt injection attacks. This highlights a significant risk, as compromised skills could lead to unintended actions, data breaches, or the dissemination of harmful information, underscoring the urgent need for robust security measures in the development and deployment of these intelligent systems.
The Model Context Protocol represents a fundamental shift in how agents interact with the external world, establishing a secure and governed pathway to data and tools. Rather than granting broad, unrestricted access, this protocol defines precise boundaries for each interaction, verifying the integrity of incoming data and the legitimacy of requested actions. This controlled environment mitigates the risk of malicious manipulation and ensures that agents operate within predefined safety parameters. By meticulously managing the flow of information, the protocol doesn’t merely enhance security; it also expands an agent’s functional capacity, allowing it to leverage a wider range of resources with confidence and reliability, ultimately leading to more sophisticated and trustworthy performance.
By December 2025, a focused effort to mitigate vulnerabilities and establish robust trust mechanisms within Agent Skills culminated in a significant milestone: achieving performance parity with human experts on the challenging OSWorld benchmark. Results demonstrate a score of 72.6%-surpassing the 72.36% achieved by human participants-underscoring the effectiveness of these proactive security measures. This breakthrough isn’t merely a numerical achievement; it signifies a crucial step toward realizing the full potential of Agent Skills, paving the way for genuinely intelligent and dependable systems capable of complex tasks and reliable decision-making. The emphasis on security and trust was therefore instrumental in unlocking advanced capabilities and establishing a new standard for performance in the field.
The pursuit of robust agent skills, as detailed in the survey, necessitates a holistic view of system design. Each skill, while seemingly isolated, contributes to the overall behavior and security profile of the LLM agent. This mirrors the principle that structure dictates function; a poorly conceived skill ecosystem introduces vulnerabilities and limits adaptability. As Marvin Minsky observed, “You can’t expect intelligence to arise from chaos.” The paper’s focus on progressive disclosure and security governance isn’t merely about mitigating risk; it’s about establishing a coherent framework where each component-each skill-works in concert to achieve reliable and predictable outcomes. The architecture described isn’t simply a collection of tools, but an integrated organism requiring careful orchestration.
What’s Next?
The pursuit of ‘agent skills’ neatly sidesteps the more fundamental question of what constitutes competence. If the system looks clever, it’s probably fragile. This work has illuminated the mechanics of skill acquisition and governance, but a truly robust architecture demands an understanding of failure modes – not just in individual skills, but in their unpredictable interactions. The current emphasis on modularity, while sensible, risks obscuring the emergent properties – and potential hazards – of a complex skill ecosystem.
Future research should not shy away from the messy reality of incomplete information and adversarial environments. Progressive disclosure, as a security measure, acknowledges the inherent limitations of trust, but relies on the assumption that malicious intent can be neatly categorized. A more pessimistic, and likely more accurate, view requires anticipating unforeseen misuse. The art of system design, after all, is the art of choosing what to sacrifice – and a skill, however elegantly implemented, is always a potential vector for harm.
Ultimately, the success of LLM agents will not be measured by their ability to perform tasks, but by their ability to gracefully degrade when faced with the inevitable chaos of the real world. The focus must shift from maximizing capability to minimizing systemic risk, a considerably more difficult – and intellectually honest – endeavor.
Original article: https://arxiv.org/pdf/2602.12430.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Roco Kingdom: World China beta turns chaotic for unexpected semi-nudity as players run around undressed
- Charlie Day Confirms What Always Sunny Scene Is His Career Highlight
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
2026-02-16 17:46