Author: Denis Avetisyan
A new open-source suite offers unprecedented visibility into the performance, reliability, and economic realities of building applications with large language model agents.
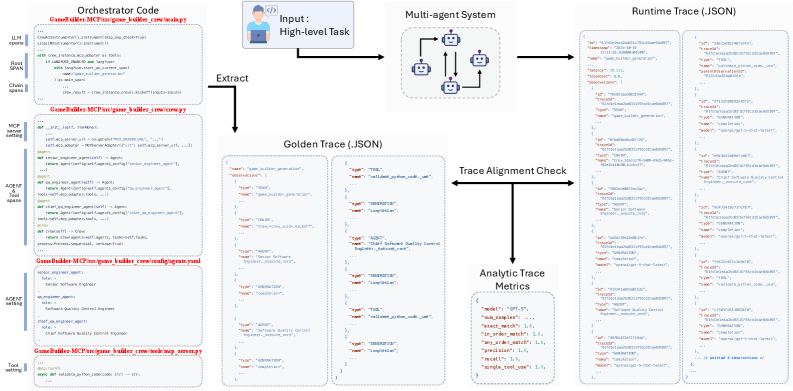
AI-NativeBench provides a white-box benchmark for evaluating agentic services, utilizing distributed tracing to reveal performance bottlenecks and token economics impacts.
Traditional benchmarks struggle to capture the systemic complexities introduced by the shift from deterministic microservices to probabilistic, agentic systems. To address this, we present AI-NativeBench: An Open-Source White-Box Agentic Benchmark Suite for AI-Native Systems, a novel evaluation framework grounded in distributed tracing and designed to analyze the engineering characteristics of LLM-powered agents. Our results, derived from 21 system variants, reveal counterintuitive realities-like lightweight models outperforming larger counterparts in protocol adherence-and highlight costly failure patterns often masked by self-healing mechanisms. Can a white-box approach to benchmarking finally guide the development of truly reliable and economically viable AI-Native systems?
Beyond Determinism: The Rise of AI-Native Systems
The foundations of modern application development – cloud-native architectures – were designed for deterministic systems, where outputs are predictable based on inputs. However, the emergence of artificial intelligence, particularly machine learning, introduces inherent probabilistic behavior that strains these traditional frameworks. Applications increasingly rely on models that estimate outcomes, not calculate them, leading to unpredictable resource demands and performance fluctuations. While cloud-native principles like microservices and containerization remain valuable, they lack the adaptability needed to manage the dynamic and often opaque nature of AI workloads. This mismatch necessitates a rethinking of system design, moving beyond simply scaling infrastructure to actively adapting to the uncertainties introduced by intelligent applications, and ultimately paving the way for AI-native systems built to embrace, rather than resist, probabilistic logic.
The emergence of AI-Native Systems signals a fundamental departure from traditional software architecture, moving beyond deterministic logic to embrace autonomous agents and probabilistic models. While offering unprecedented capabilities in areas like complex problem-solving and adaptation, this paradigm shift introduces significant hurdles in ensuring system reliability and understanding internal states. Unlike conventional applications where behavior is predictable, AI-Native systems operate with inherent uncertainty, making debugging and root cause analysis considerably more difficult. Observability-the ability to monitor and interpret system behavior-becomes paramount, demanding novel techniques to track probabilistic decision-making and agent interactions. Furthermore, resilience-the capacity to recover from failures-requires proactive strategies to anticipate and mitigate unpredictable outcomes, as traditional fault tolerance mechanisms are often insufficient when dealing with systems that learn and evolve independently. Successfully navigating these challenges will be critical to unlocking the full potential of AI-Native applications and building trustworthy, robust AI-driven solutions.
The operational heart of AI-Native systems lies in Large Language Model (LLM) inference – the process of applying a trained model to new data. However, this reliance introduces vulnerabilities distinct from those of traditional software. Unlike deterministic code, LLMs operate on probabilities, meaning identical inputs don’t guarantee identical outputs, creating challenges for debugging and verification. Moreover, adversarial attacks, crafted to subtly manipulate LLM responses, pose a significant threat, potentially leading to inaccurate predictions or malicious outputs. These attacks aren’t simply bugs to be patched; they exploit the very nature of probabilistic reasoning. Consequently, securing AI-Native systems requires novel approaches focused on monitoring not just what the system does, but how it arrives at its conclusions, demanding a shift towards probabilistic testing and continuous validation of model behavior under various conditions.
AI-NativeBench: A System’s Internal Logic Revealed
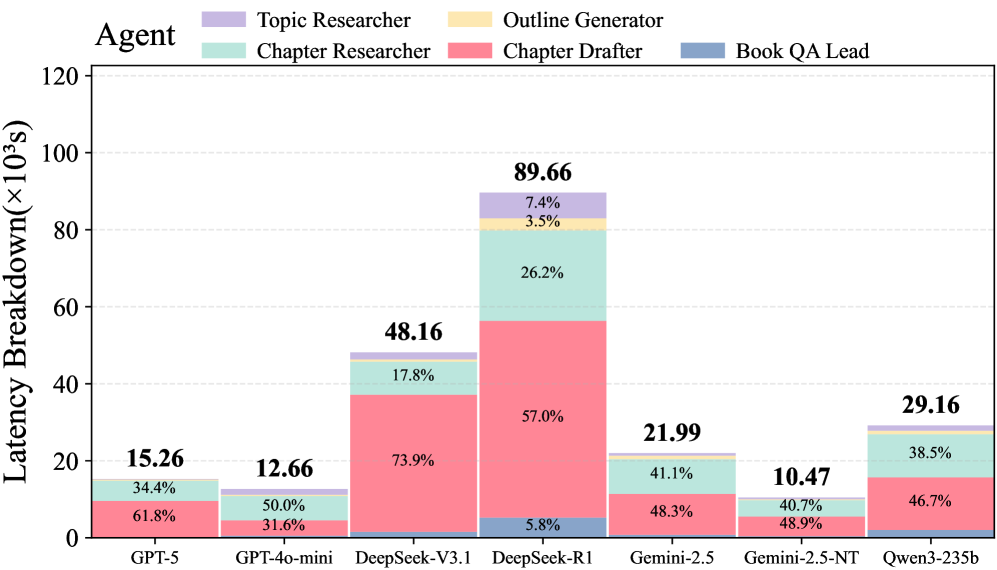
AI-NativeBench introduces a benchmark suite differing from traditional evaluations by providing white-box access to system internals. Existing benchmarks typically employ black-box performance metrics – focusing solely on inputs and outputs without insight into the system’s operational behavior. AI-NativeBench instead emphasizes detailed introspection, allowing researchers and developers to analyze internal states, component interactions, and resource utilization during AI system execution. This approach facilitates granular performance analysis, enabling identification of inefficiencies and bottlenecks beyond what is achievable through conventional, output-focused measurements. The suite is specifically designed for AI-Native Systems, which are characterized by their distributed, componentized architecture and reliance on real-time data processing.
AI-NativeBench leverages Distributed Tracing to provide granular insight into the execution flow of AI-Native Systems. This is achieved through the implementation of industry-standard protocols, specifically Application-to-Application (A2A) tracing and Machine Control Protocol (MCP). A2A tracing captures the propagation of requests across different microservices within the system, while MCP facilitates the monitoring of individual machine operations and resource utilization. By instrumenting the system with these protocols, AI-NativeBench collects detailed timing and dependency information for each component, enabling the reconstruction of execution paths and the identification of latency contributors. This level of visibility extends beyond simple performance metrics to reveal the underlying causes of bottlenecks and inefficiencies.
AI-NativeBench leverages detailed observability data – including timings, dependencies, and resource utilization – to pinpoint performance bottlenecks within AI systems. This is achieved through the capture and analysis of traces as requests propagate through the architecture, allowing developers to identify slow-performing components or inefficient data flows. Furthermore, the benchmark facilitates the validation of resilience strategies by simulating failures and observing how the system responds, assessing the effectiveness of mechanisms like retries, circuit breakers, and fallback procedures in maintaining service availability and data integrity under adverse conditions. The granularity of the observability data allows for precise identification of failure modes and assessment of recovery times, contributing to more robust and reliable AI-driven applications.
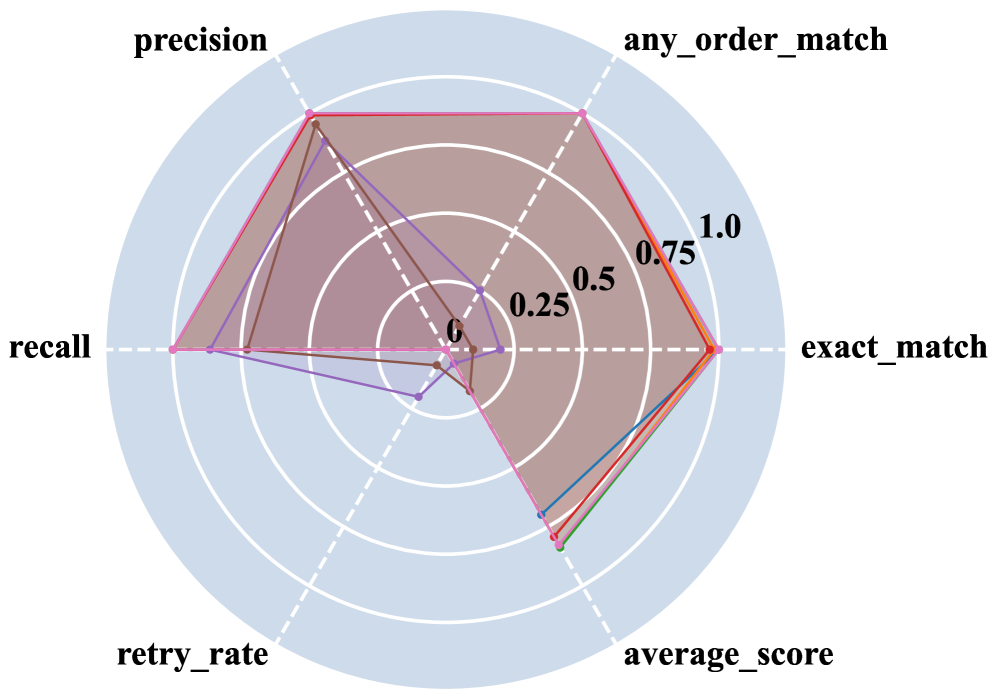
Systemic Paradoxes: Cost, Context, and Heterogeneity
The implementation of self-healing mechanisms within AI-Native Systems, intended to improve reliability, can result in significant cost increases due to extended execution times. Observed in specific workflows, token usage-a primary cost driver in LLM applications-has been shown to increase up to 15.4x when these mechanisms are actively engaged. This phenomenon, termed the Expensive Failure Pattern, arises because repeated attempts to resolve issues, while ultimately successful in some cases, consume substantial computational resources proportional to the number of iterations and the length of the generated tokens. Consequently, systems designed for self-correction may inadvertently incur higher operational expenses than comparable systems without such features, necessitating careful cost-benefit analysis and optimization of failure recovery strategies.
Context pollution in Large Language Models (LLMs) refers to the performance decline resulting from the accumulation of irrelevant or redundant information within the limited context window. As LLMs process sequential data, the context window fills with tokens representing prior interactions and data. This accumulation can dilute the signal from crucial, recent input, hindering the model’s ability to accurately interpret and respond to current queries. Empirical observation indicates that beyond a certain threshold of irrelevant data, response quality deteriorates, and processing time increases due to the model attempting to reconcile conflicting or unnecessary information. Effective memory management strategies, including summarization, retrieval-augmented generation, and context pruning, are therefore critical to mitigate context pollution and maintain optimal LLM performance.
Heterogeneous frameworks, utilizing diverse hardware accelerators like GPUs, TPUs, and specialized ASICs, aim to accelerate the convergence of AI-Native System training and inference. However, the integration of these disparate processing units introduces significant synchronization overhead. This overhead arises from the need to manage data transfer between devices, coordinate execution across different architectures, and handle potential data consistency issues. While individual accelerators may offer performance benefits, the increased communication and synchronization demands can, in certain configurations, negate these gains and even result in slower overall system performance. The extent of this offset is dependent on the workload characteristics, the interconnect bandwidth between devices, and the efficiency of the synchronization mechanisms employed.
Toward Resilience: Adaptive Orchestration and Economic Fail-Fast
Adaptive Orchestration improves Large Language Model (LLM) performance by dynamically allocating tasks to the most appropriate model within a defined hierarchy. This approach moves beyond reliance on a single, generalized LLM by evaluating task requirements and selecting from a suite of models specialized for different functionalities – such as reasoning, summarization, or code generation. The system continuously monitors performance metrics and adjusts the model hierarchy in real-time, potentially promoting more efficient models or re-routing requests to alternative pathways. This dynamic selection process allows for optimized resource utilization and improved accuracy, as tasks are consistently handled by the model best suited to the specific demands of the input data and desired output.
The Economic Fail-Fast strategy enhances AI system resilience by continuously evaluating the ratio of information gain to resource expenditure during execution. This mechanism operates by monitoring key performance indicators related to the value of newly generated information and comparing it against the computational cost-including processing time, energy usage, and data transfer-required to produce that information. When a defined threshold is reached, indicating that resource consumption exceeds the potential benefit of continued execution along a particular path, the system proactively terminates that path. This preemptive termination prevents wasted resources and mitigates the risk of propagating errors or cascading failures, contributing to a more robust and efficient AI system.
Semantic Circuit Breakers enhance AI system robustness by integrating verification modules that actively monitor for violations of predefined logical constraints during execution. These modules operate by assessing intermediate outputs against established rules and, upon detecting inconsistencies or errors indicative of flawed reasoning, trigger an immediate interruption of the current execution path. This preemptive halting prevents the propagation of incorrect information and avoids unnecessary resource expenditure on demonstrably erroneous computations. The implementation relies on formal methods and constraint programming techniques to define and enforce these logical boundaries, ensuring a higher degree of reliability in complex AI workflows.
The Parameter Paradox: Lightweight Models and Engineering Discipline
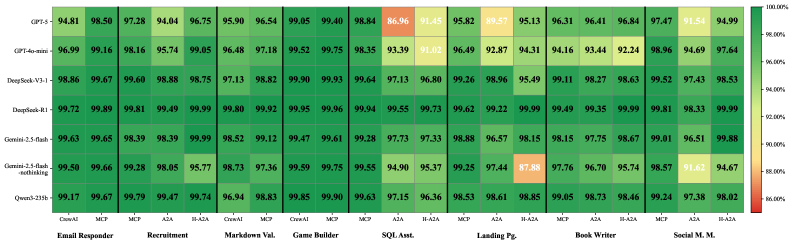
Recent investigations into large language models (LLMs) have revealed a counterintuitive phenomenon – the Parameter Paradox – where smaller, more streamlined models can, in certain contexts, surpass their larger counterparts in rigorously following established engineering protocols. This challenges the dominant assumption that increasing model size invariably leads to improved performance across all metrics. Researchers found that while larger models often exhibit greater general knowledge and creative text generation, they sometimes struggle with consistency and adherence to specific, pre-defined rules crucial for tasks demanding precision and reliability. Lightweight models, deliberately designed with engineering discipline in mind, can excel in these scenarios by prioritizing predictable, rule-based outputs over expansive, but potentially erratic, knowledge recall. This suggests that a focus on efficient model architecture and careful constraint implementation may be as, or even more, valuable than simply scaling up parameter counts.
Current AI-Native systems are overwhelmingly constrained not by data transfer or processing preparation, but by the time required for Large Language Models to generate a response-a phenomenon termed ‘Inference Dominance’. Detailed analysis reveals that LLM inference accounts for an astonishing 86.9% to 99.9% of total end-to-end latency, effectively dwarfing the contribution from network communication and data serialization overhead. This finding fundamentally shifts the focus for performance optimization; improvements to network speeds or data handling offer minimal gains compared to accelerating the core inference process itself. Consequently, research and engineering efforts are increasingly directed toward techniques that reduce inference time, such as model pruning, quantization, and specialized hardware acceleration, to unlock the true potential of AI-driven applications.
Current research indicates a crucial shift in the development of large language models, suggesting that gains achieved through sheer scale are beginning to diminish in practical impact. While the trend has long favored increasing parameter counts, recent studies demonstrate that a focus on efficient inference – minimizing the time it takes for a model to generate outputs – and rigorous engineering discipline in model design can yield more substantial improvements in overall system performance. This isn’t simply about speed; optimizing for inference allows for more responsive AI-native applications and reduces computational costs, potentially unlocking broader accessibility and deployment opportunities. The data suggests that a strategically constrained, well-engineered model can often outperform a larger, less-optimized counterpart, challenging the conventional wisdom that ‘bigger is better’ and pointing towards a more sustainable and impactful path for future AI development.
The pursuit of robust AI-native systems, as detailed in the introduction of AI-NativeBench, demands a foundation built on verifiable truths, not merely observed behaviors. This echoes Alan Turing’s sentiment: “Sometimes people who are unconscious of the possibilities hit upon them by luck.” While AI-NativeBench facilitates a structured evaluation of agentic services-revealing performance bottlenecks and token economics impacts-it’s the formal methodology-the white-box approach-that distinguishes it. The benchmark suite doesn’t simply assess if a system works, but how and why, striving for provable reliability-a principle deeply aligned with a mathematically rigorous approach to computation. This dedication to understanding internal mechanisms, rather than treating systems as opaque black boxes, is crucial for building genuinely dependable AI.
What’s Next?
The introduction of AI-NativeBench represents a necessary, if belated, acknowledgement that the empirical demonstration of LLM-driven systems demands more rigor than mere task completion. The current obsession with benchmark scores, divorced from systemic cost, feels increasingly…optimistic. The suite’s emphasis on white-box analysis-tracing performance bottlenecks and scrutinizing token economics-is a step toward understanding why these systems succeed or fail, rather than simply that they do. Yet, the true challenge remains: formalizing a mathematical framework for agentic reliability. Proving properties like convergence, consistency, and bounded resource consumption requires more than observation; it demands provable algorithms.
Future work must move beyond identifying symptoms of inefficiency and toward establishing invariants. The field currently relies heavily on scaling – throwing more parameters at a problem in the hope of masking fundamental flaws. This approach is unsustainable, both economically and intellectually. A robust theory of agentic systems will necessitate a shift in focus from black-box performance to white-box provability – a demonstrably correct solution, not merely one that appears to work on a limited dataset.
In the chaos of data, only mathematical discipline endures. The current metrics – tokens per second, cost per query – are ephemera. The lasting contribution of work like AI-NativeBench will be its implicit demand for a deeper, more formal understanding of the systems it probes, a foundation built on provable correctness, not empirical happenstance.
Original article: https://arxiv.org/pdf/2601.09393.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- How to find the Roaming Oak Tree in Heartopia
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Best Arena 9 Decks in Clast Royale
- ATHENA: Blood Twins Hero Tier List
- Brawl Stars December 2025 Brawl Talk: Two New Brawlers, Buffie, Vault, New Skins, Game Modes, and more
- Clash Royale Furnace Evolution best decks guide
- Clash Royale Witch Evolution best decks guide
2026-01-15 22:56