Author: Denis Avetisyan
As artificial intelligence systems become increasingly capable, a critical challenge is emerging: ensuring their behavior is consistent, robust, and predictable.
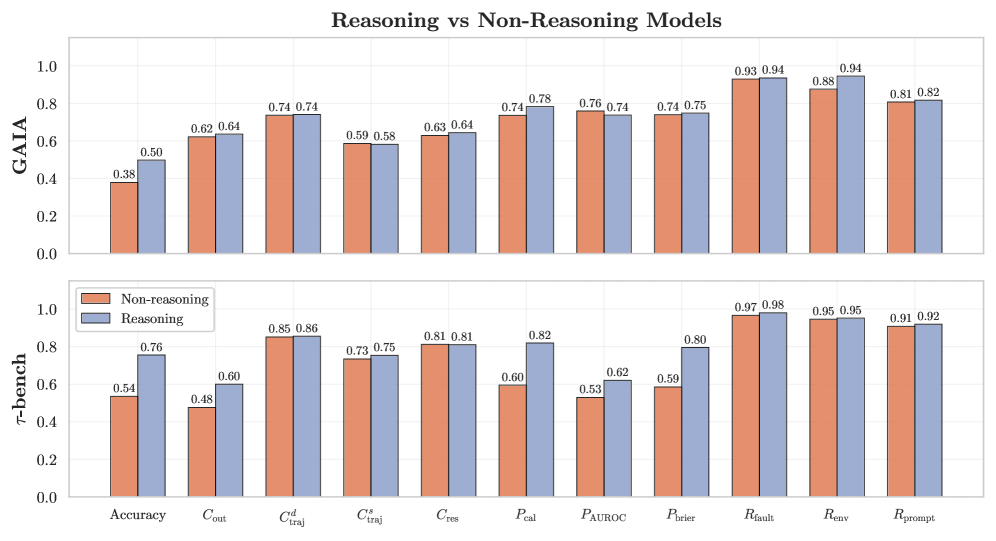
![Despite gains in model utility, reliability metrics demonstrate limited overall improvement, with predictability and safety on [latex]\tau\tau[/latex]-bench, and robustness on GAIA, standing as notable exceptions to this trend.](https://arxiv.org/html/2602.16666v1/x9.png)
This review highlights the growing disparity between AI agent capability and reliability, arguing for new evaluation metrics and a shift in development priorities to address this crucial issue.
Despite increasing accuracy on benchmark tasks, current AI agents often exhibit unpredictable failures in real-world deployments, revealing a critical gap between capability and reliable performance. This discrepancy motivates the work ‘Towards a Science of AI Agent Reliability’, which introduces a holistic framework for evaluating agents beyond simple success rates. By decomposing reliability into four key dimensions-consistency, robustness, predictability, and safety-and proposing twelve concrete metrics, the authors demonstrate that recent gains in agent capability have not translated to commensurate improvements in these crucial characteristics. Can a more nuanced understanding of agent failure modes pave the way for truly trustworthy and dependable AI systems?
The Illusion of Intelligence: Why Scaling Isn’t Enough
Despite their remarkable ability to generate human-quality text, current large language models frequently falter when confronted with reasoning tasks requiring multiple sequential steps. This isn’t simply a matter of needing more data or larger networks; the very architecture of these models-primarily focused on pattern recognition within vast datasets-proves intrinsically limited in handling complex logic. While proficient at identifying correlations, these models struggle with causation and often produce plausible-sounding but ultimately incorrect answers when required to synthesize information and draw inferences across multiple stages of reasoning. This suggests a fundamental constraint: scaling up the size of these models, while providing incremental improvements, won’t overcome the limitations inherent in an architecture that prioritizes statistical relationships over explicit knowledge representation and manipulation. The inability to reliably perform multi-step reasoning highlights a critical need for novel approaches that move beyond simply predicting the next token and instead focus on building models capable of genuinely ‘thinking’ through problems.
Despite continued advancements in model size and training data, current large language models frequently encounter limitations when tasked with complex reasoning-problems demanding multiple sequential inferences. Research indicates that simply increasing the scale of these models-adding more parameters and data-yields diminishing returns in tackling such challenges. The core issue isn’t a lack of data or computational power, but rather an architectural one; these models implicitly learn relationships within data instead of explicitly representing and manipulating knowledge. A paradigm shift is therefore necessary, focusing on the development of systems capable of constructing internal knowledge representations – symbolic structures or knowledge graphs – and employing reasoning mechanisms to operate on them, mirroring the cognitive processes observed in human problem-solving and offering a path beyond the limitations of purely statistical language modeling.
The Promise of Self-Awareness: Knowing What You Don’t Know
Predictability in autonomous agents refers to the capacity to assess the likelihood of successfully completing a task prior to execution. This isn’t simply about reporting a binary success/failure outcome, but rather providing a probabilistic estimate of performance. Accurate pre-action assessment allows agents to avoid attempting tasks where failure is highly probable, conserve resources, and strategically allocate effort to achievable goals. The development of robust predictability mechanisms is therefore a key differentiator in advanced agent architectures, enabling more efficient and reliable operation in complex environments. This capability moves beyond reactive behavior toward proactive planning and informed decision-making.
AgentCalibration and AgentDiscrimination are key components enabling self-awareness in AI agents. AgentCalibration allows the system to output confidence scores that correlate with the probability of successful task completion; recent Claude models demonstrate significantly improved calibration, meaning reported confidence levels more accurately reflect actual performance. AgentDiscrimination refers to the agent’s ability to reliably identify tasks that fall outside its capabilities, preventing attempts that are likely to fail. This dual capability – accurate self-assessment of both potential success and task solvability – is crucial for responsible and effective autonomous operation.
Agent calibration testing reveals a significant correlation between predicted confidence scores and actual task success rates in recent models. Specifically, these agents demonstrate an improved ability to accurately assess the likelihood of success before initiating an action, avoiding the overconfidence observed in competing architectures. This means that a higher reported confidence level is now more reliably indicative of a higher probability of successful task completion, and conversely, lower confidence scores more accurately reflect a greater risk of failure. Quantitative results show a demonstrable reduction in the gap between predicted confidence and observed performance, suggesting improved reliability in agent self-assessment.
![Claude models demonstrate better calibration, accurately reflecting task success with their confidence scores, while GPT-4 Turbo excels at discerning task difficulty, highlighting these as separate strengths, though both struggle with multi-step self-assessment as evidenced by reduced predictability on agentic [latex] au[/latex]-bench tasks.](https://arxiv.org/html/2602.16666v1/x17.png)
Benchmarking Reality: The Limits of Simulated Worlds
Evaluative benchmarks such as GAIA and TauBench are critical for assessing the capabilities of large language models (LLMs) when applied to intricate tasks demanding multi-step reasoning. These benchmarks move beyond simple question-answering to simulate realistic customer service scenarios, requiring agents to maintain context across multiple conversational turns and resolve complex user requests. The design of these benchmarks prioritizes evaluating an agent’s ability to not only provide accurate information but also to navigate ambiguous or incomplete prompts, and to demonstrate coherent and logical thought processes throughout extended interactions. This focus on complex, interactive tasks provides a more nuanced understanding of LLM performance than traditional single-turn evaluations.
Evaluations using benchmarks like GAIA and TauBench quantify agent behavior across three key dimensions: Consistency, Robustness, and Safety. Robustness, specifically, measures the model’s ability to maintain performance despite variations in input phrasing or context; current evaluations indicate a relatively stable average robustness score of 80-90% across different models tested. Consistency assesses the internal logical coherence of the agent’s responses, while Safety evaluates the presence of harmful or inappropriate outputs. The combined assessment of these three areas provides a comprehensive performance profile, enabling detailed comparison and identification of areas for improvement in agent design and training.
Analysis of the original TauBench benchmark revealed a slight increase in safety violation rates during evaluation. This increase is attributed to inaccuracies and inconsistencies within the benchmark’s ground truth data, specifically flawed annotations regarding acceptable and unacceptable responses in simulated customer service interactions. These data quality issues directly impacted the assessment of agent safety, demonstrating that the reliability of safety evaluations is contingent on the accuracy and completeness of the reference data used for comparison. Consequently, benchmark developers are prioritizing data curation and validation processes to mitigate the influence of flawed ground truth on model performance metrics.
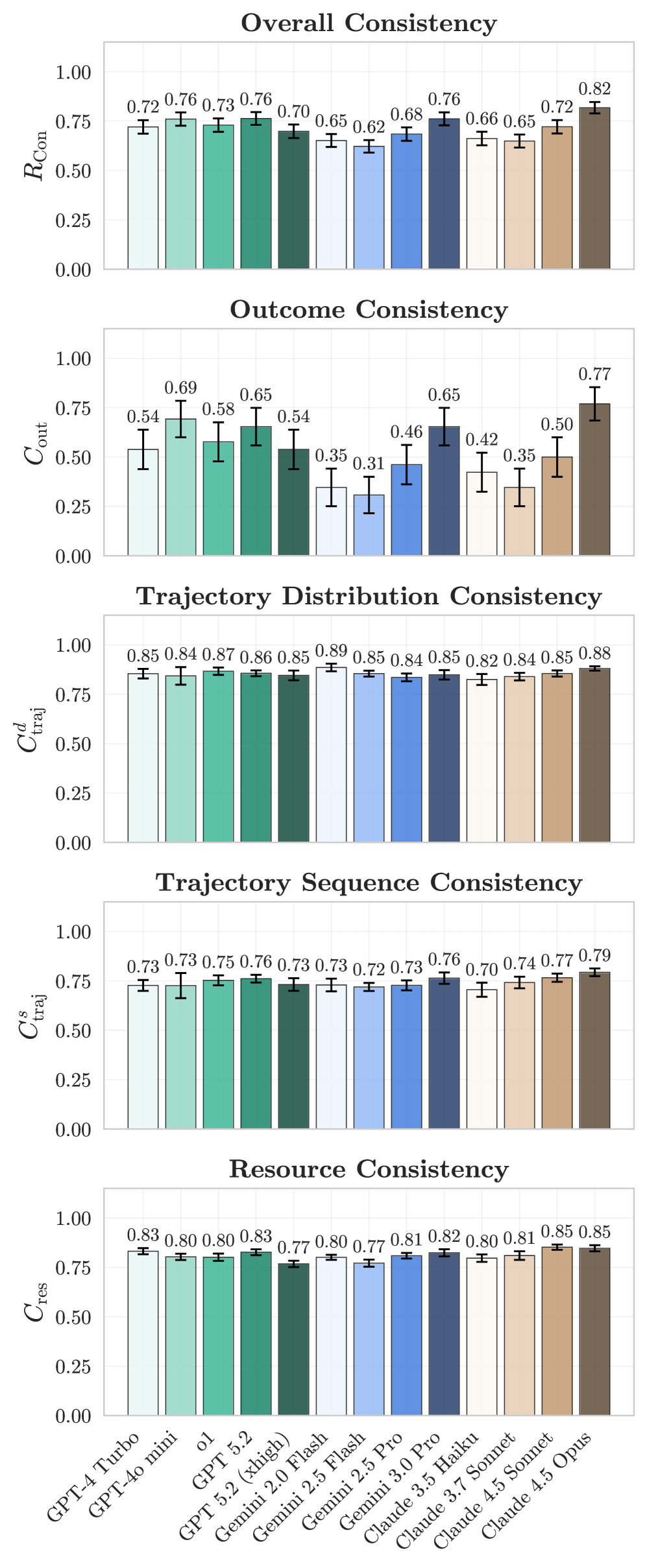
![Performance on the [latex] au[/latex]-bench consistency benchmark reveals a notable decline in outcome consistency across agents, while other consistency metrics remain largely unaffected.](https://arxiv.org/html/2602.16666v1/x29.png)
The Illusion of Reliability: Why Consistent Errors Are Still Errors
The bedrock of a dependable artificial intelligence lies in consistency, a trait demonstrated through two key facets. First is ActionSequenceConsistency, wherein the AI rigorously adheres to a predetermined series of steps when completing a task – essentially, ‘doing things the same way every time’. Complementing this is OutcomeConsistency, which ensures the AI consistently delivers correct or expected results. Both are vital because predictable behavior builds trust, especially in applications where errors can have significant consequences; a consistent AI, even if not always perfect, is far more reliable than one prone to unpredictable shifts in its process or performance. This dual consistency isn’t merely about repeating actions, but about establishing a dependable link between procedure and result, forming the basis of a truly trustworthy agent.
The dependable performance of artificial intelligence agents hinges significantly on consistency, especially when deployed in applications where safety is paramount. Consistent behavior isn’t simply about repeating actions; it’s about reliably achieving correct outcomes, fostering user confidence and minimizing potential risks. In fields like autonomous driving, medical diagnosis, or automated manufacturing, even occasional inconsistencies can have severe consequences, eroding trust and hindering adoption. Therefore, ensuring that an AI agent consistently delivers accurate and predictable results isn’t merely a technical challenge, but a fundamental prerequisite for building systems that can be safely and effectively integrated into critical aspects of human life. The ability to consistently perform as expected is, ultimately, the foundation upon which reliance-and genuine progress-in AI is built.
Achieving reliable outcomes remains a substantial hurdle in the development of advanced AI agents. Current evaluations, as measured by the GAIA benchmark, demonstrate that even state-of-the-art models only achieve Outcome Consistency – the ability to consistently produce correct results – around 60 to 70% of the time. This performance level suggests a significant gap between current capabilities and the level of dependability required for deployment in real-world applications, particularly those where errors could have serious consequences. While progress is being made, improving this fundamental consistency is critical for fostering trust and ensuring the safe and effective integration of AI into increasingly complex systems.
Current evaluations on the GAIA benchmark reveal that leading AI models achieve approximately 60-70% accuracy through a technique known as selective accuracy. This approach doesn’t focus solely on always providing an answer, but instead prioritizes correctness by allowing the model to abstain from responding when it lacks sufficient confidence. The demonstrated performance suggests a significant pathway for improvement; rather than forcing a prediction, models can enhance overall reliability by recognizing their limitations and opting for non-response in ambiguous scenarios. This strategic abstention, therefore, isn’t a failure, but a calculated move toward delivering more trustworthy and accurate outcomes, particularly crucial in applications demanding high precision.
The Pursuit of Predictability: Minimizing the Unexpected
The reliable operation of artificial intelligence agents hinges on consistently adhering to established constraints – predefined rules governing acceptable actions and states. A ‘ConstraintViolation’ occurs when an agent breaches these boundaries, potentially leading to unpredictable, and even unsafe, outcomes. This presents a significant challenge, particularly as agents are deployed in increasingly complex and dynamic environments where unforeseen circumstances can easily trigger such violations. Preventing these breaches requires robust mechanisms for both proactive constraint satisfaction – designing agents to inherently respect the rules – and reactive mitigation – identifying and correcting deviations in real-time. Current research explores techniques like formal verification, runtime monitoring, and reinforcement learning strategies specifically tailored to minimize the probability of constraint violations, ultimately striving for AI systems that are not only capable but also demonstrably safe and predictable.
Advancing the capabilities of artificial intelligence necessitates a concentrated effort on bolstering agent safety and predictability, especially as these systems operate within increasingly intricate and ever-changing environments. Current research aims to move beyond static, controlled settings, exploring techniques like reinforcement learning with safety constraints and robust perception systems capable of handling noisy or incomplete data. A critical area of investigation involves developing algorithms that allow agents to anticipate potential hazards and proactively adjust their behavior, rather than simply reacting to immediate threats. This includes exploring methods for formal verification of agent behavior and the creation of interpretable models that reveal the reasoning behind an agent’s actions, ultimately fostering trust and enabling seamless human-agent collaboration in real-world applications.
Realizing the full capabilities of artificial intelligence hinges on establishing unwavering trust in its actions. Prioritizing safety and predictability in AI agent design isn’t merely a technical challenge; it’s a fundamental requirement for widespread adoption and integration into daily life. Systems that consistently operate within defined boundaries and demonstrate understandable behavior foster confidence, allowing humans to collaborate effectively and leverage AI’s power without apprehension. This focus unlocks possibilities across diverse fields, from autonomous vehicles navigating complex urban landscapes to robotic assistants providing reliable care, ultimately shaping a future where AI enhances, rather than disrupts, human endeavors.
![Removing noisy data from [latex] au[/latex]-bench significantly improves agent accuracy, reliability, and-most notably-predictability across multiple dimensions.](https://arxiv.org/html/2602.16666v1/x7.png)
The pursuit of increasingly capable AI agents, as detailed in the study, feels less like progress and more like accruing technical debt. The paper highlights a widening gap between capability and reliability – agents can do more, but predictably and consistently doing the right thing remains elusive. It’s a familiar pattern. Barbara Liskov observed, “It’s one thing to make a program work, and another thing to make it work reliably.” This distinction resonates deeply; the bug tracker, predictably, fills faster than any feature request backlog. The focus on raw capability feels…optimistic. The inevitable result isn’t innovation, but firefighting. They don’t deploy – they let go.
What’s Next?
The demonstrated divergence between AI agent capability and reliability isn’t surprising. Each increment in ‘intelligence’ merely exposes a wider surface area for failure. The pursuit of accuracy, divorced from consistent performance, feels…familiar. It’s a recurring pattern: build something that works, then discover it works only when conditions align with the developer’s optimism. The field now faces a predictable crisis – agents that dazzle in demos and collapse in production. Expect a flurry of papers proposing ‘reliability taxes’ on model size, or increasingly baroque methods for certifying behavior. Documentation remains a myth invented by managers.
Future work will undoubtedly focus on metrics. The current obsession with single-number performance scores will be replaced by…more numbers. Consistency, robustness, and predictability are not unitary properties; they’re constellations of edge cases. The true cost will be borne by the engineers tasked with wrangling these complex systems. CI is their temple – they pray nothing breaks.
Ultimately, the problem isn’t a lack of clever algorithms; it’s the illusion of control. Any system that promises to simplify life adds another layer of abstraction, and each layer is a potential point of catastrophic failure. The research will proceed, of course. It always does. But the fundamental tension between ambition and fragility will remain.
Original article: https://arxiv.org/pdf/2602.16666.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Total Football free codes and how to redeem them (March 2026)
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
2026-02-19 16:24