Author: Denis Avetisyan
New research explores how large language models can move beyond simply answering questions to actively seeking clarification, dramatically improving their performance on complex reasoning tasks.

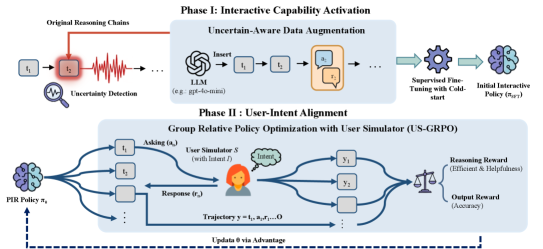
This paper introduces a framework for proactive inquiry in large language models, enabling them to detect uncertainty, formulate clarifying questions, and refine their reasoning through iterative interaction.
Despite recent advances in reasoning-oriented Large Language Models (LLMs), a fundamental limitation remains: their tendency to perform extensive internal reasoning even when faced with incomplete or ambiguous information. This work, ‘Reasoning While Asking: Transforming Reasoning Large Language Models from Passive Solvers to Proactive Inquirers’, introduces Proactive Interactive Reasoning (PIR), a paradigm shift that transforms LLMs from passive solvers into proactive inquirers capable of seeking clarification. By equipping models with uncertainty detection and interactive capabilities-achieved through supervised fine-tuning and reinforcement learning with a user simulator-PIR demonstrably improves accuracy and efficiency across mathematical reasoning, code generation, and document editing tasks. Could this approach of enabling LLMs to ‘ask for help’ unlock a new era of more reliable and resource-conscious artificial intelligence?
The Inherent Opacity of Passive Systems
Despite their remarkable ability to generate human-quality text and solve complex problems, current large language models (LLMs) frequently function as opaque ‘black boxes’. This lack of transparency stems from the intricate network of parameters learned during training, making it difficult to discern how a particular conclusion was reached. While an LLM might confidently provide an answer, the underlying reasoning process remains hidden, precluding any meaningful assessment of its reliability or identification of potential biases. This poses a significant challenge for applications demanding accountability, such as medical diagnosis or legal analysis, where understanding the rationale behind a decision is as crucial as the decision itself. The inability to inspect the model’s thought process limits trust and hinders efforts to refine and improve these powerful, yet ultimately inscrutable, systems.
Current large language models, despite their impressive capabilities, exhibit a significant vulnerability termed ‘Blind Self-Thinking’. This phenomenon describes the models’ tendency to proceed with reasoning even when presented with incomplete or ambiguous information, rather than acknowledging the need for clarification or additional data. The models effectively lack a metacognitive awareness of their own knowledge limitations, generating outputs that appear logical but are ultimately unreliable due to a flawed foundation. This isn’t a matter of simply being incorrect; it’s a failure to recognize the possibility of error stemming from insufficient evidence, leading to confidently stated, yet potentially baseless, conclusions. Consequently, applications demanding high degrees of certainty – such as medical diagnosis or legal analysis – are particularly susceptible to the risks posed by this inherent blind spot in the reasoning process.
The capacity of current large language models to perform complex reasoning falters when tasks demand sequential thought. While adept at single-step inferences, their performance degrades as the number of necessary reasoning steps increases, revealing a limitation in sustaining logical coherence over extended cognitive chains. This isn’t merely a matter of computational resources; rather, the models struggle with maintaining contextual relevance and avoiding the accumulation of errors across multiple inferences. Consequently, their application to real-world problems – such as detailed diagnostic reasoning, long-term planning, or intricate problem-solving – is significantly hindered, as these domains inherently require robust, multi-step reasoning capabilities that surpass the current limitations of these systems.
![Using a preference-informed reasoning process, the PIR LLM efficiently solves the mathematical problem of maximizing [latex]x-y[/latex] given the constraint [latex]2(x^2+y^2) = x+y[/latex], demonstrating superior performance compared to a self-thinking approach.](https://arxiv.org/html/2601.22139v1/x4.png)
From Reactive Response to Proactive Inquiry
The Proactive Inquiry Reasoning (PIR) framework represents a departure from standard Reasoning Language Model (LLM) operation by enabling models to actively solicit clarifying information during the reasoning process. Instead of passively accepting input and attempting to derive an answer, PIR equips LLMs with the capacity to identify gaps in understanding and formulate targeted questions to resolve ambiguities. This is achieved through a defined process where the model, upon encountering insufficient information to confidently proceed, generates a specific inquiry directed towards an external source or user. The subsequent integration of the response into the reasoning chain allows for a more informed and accurate conclusion, effectively transforming the LLM from a reactive responder to a proactive inquirer.
The Proactive Inquiry Reasoning (PIR) framework utilizes an ‘Uncertainty Detection’ mechanism to monitor the confidence level of the Language Learning Model (LLM) throughout the reasoning process. This detection isn’t a simple probability score; rather, it analyzes the internal representations and activation patterns within the LLM to assess the model’s conviction in its intermediate conclusions. When this confidence dips below a predetermined threshold – calibrated during training – the system automatically generates a clarification request. This request is specifically formulated to target the ambiguous or uncertain element hindering confident reasoning, allowing the model to actively seek the necessary information before finalizing its response. The threshold is dynamically adjusted based on the complexity of the reasoning task and the observed performance of the LLM.
Traditional reasoning Language Learning Models (LLMs) operate on a passive input-output paradigm, generating a single answer based solely on the provided prompt without seeking additional information. This contrasts with Proactive Reasoning (PIR), which actively identifies ambiguities or low-confidence states during the reasoning process and requests clarification before finalizing an answer. By soliciting necessary information, PIR mitigates the impact of incomplete or unclear inputs, reducing errors and increasing the overall reliability of conclusions. This active inquiry component enables the model to function more effectively in complex scenarios where initial prompts lack sufficient detail or contain inherent uncertainties, resulting in more accurate and dependable outputs compared to passive LLMs.
Validating Proactive Reasoning Through Rigorous Interaction
Evaluation of Proactive Reasoning (PIR) incorporated a range of publicly available datasets to ensure comprehensive performance assessment. These included ‘Math-Chat’, focusing on mathematical problem-solving via dialogue; ‘BigCodeBench-Chat’, a multi-turn conversation benchmark for code generation and explanation; and ‘DocEdit-Chat’, designed to evaluate editing and revision capabilities in a conversational context. Utilizing these diverse datasets allowed for the measurement of PIR’s abilities across varied task types, including mathematical reasoning, code-related discussions, and document modification, providing a robust evaluation of its generalizability and practical application.
The Interactive Reasoning Dataset was specifically constructed to evaluate a model’s capacity for engaging in clarifying dialogue to resolve ambiguities and incomplete information. This dataset moves beyond static question-answering by requiring the model to actively solicit necessary details from a simulated user. The dataset’s design focuses on scenarios where initial prompts lack sufficient context for a correct response, forcing the model to formulate relevant clarification questions. This approach allows for a direct measurement of the model’s interactive reasoning abilities, distinguishing it from models that rely solely on pattern matching or pre-existing knowledge, and providing a more robust assessment of its problem-solving skills in dynamic, real-world situations.
The evaluation methodology incorporated a Dynamic User Simulator to generate responses to clarification requests posed by the Proactive Reasoning (PIR) model. This simulator leveraged Large Language Models, specifically Llama-3.1-8B-Instruct and gpt-4o-mini, to produce realistic and contextually relevant user feedback. By simulating interactive exchanges, the system was able to assess PIR’s ability to effectively identify information gaps and request necessary details to arrive at correct solutions, providing a robust testing environment beyond static datasets.
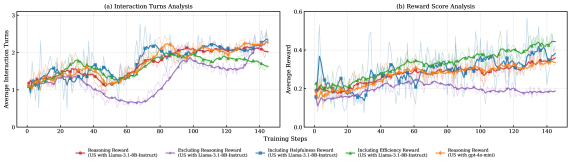
Missing Premise Testing was conducted to specifically evaluate the model’s capacity to recognize and resolve information deficits during reasoning. Results from this testing indicate a 9.8% improvement in overall accuracy when utilizing the Proactive Reasoning (PIR) system. Furthermore, the pass rate increased by 3.2%, demonstrating enhanced success in completing tasks requiring missing information. Quantitative evaluation using the BLEU score yielded a 13.36 point improvement, indicating a greater similarity between the model’s output and reference solutions when addressing incomplete information scenarios.
Proactive Interactive Reasoning (PIR) demonstrates improved computational efficiency by reducing the token count required per task by approximately 2,000 tokens. This reduction in computational load is coupled with a halving of unnecessary interaction turns during task completion. These metrics indicate that PIR streamlines the reasoning process, requiring fewer computational resources and minimizing the back-and-forth exchanges typically needed to arrive at a solution, thereby increasing overall processing speed and reducing costs.

Implications for the Future of Intelligent Systems
The advent of Proactive Information Retrieval (PIR) signals a fundamental change in the methodology of Reasoning Language Models. Traditionally, these models functioned as passive recipients of information, delivering solutions based solely on the data provided within a given prompt. PIR, however, empowers the model to actively seek out relevant information before attempting to solve a problem. This shift transforms the LLM from a reactive solver into an inquisitive agent, formulating clarifying questions and independently gathering necessary context. By proactively addressing knowledge gaps, PIR not only enhances the accuracy and reliability of responses but also fosters a more robust and trustworthy artificial intelligence capable of navigating complex challenges with greater autonomy and insight.
The shift towards proactive reasoning, as exemplified by models employing the PIR framework, fundamentally bolsters the reliability and trustworthiness of artificial intelligence in domains where accuracy is paramount. Traditional AI often delivers solutions without articulating the rationale behind them, hindering verification and increasing the risk of undetected errors. By actively seeking clarifying information and explicitly outlining its reasoning process, a proactive system allows for human oversight and validation at each step. This transparency is especially crucial in scientific discovery, where novel hypotheses require rigorous scrutiny, and in critical decision-making scenarios-such as medical diagnoses or financial modeling-where flawed conclusions can have significant consequences. The ability to not only arrive at an answer, but to demonstrably justify it, establishes a new level of confidence in AI’s capabilities and paves the way for its responsible deployment in high-stakes applications.
Ongoing research endeavors are directed towards extending the capabilities of Proactive Information Retrieval (PIR) to increasingly intricate challenges, moving beyond initial demonstrations to tackle real-world problems demanding nuanced understanding. A key avenue of exploration involves synergizing PIR with Chain-of-Thought (CoT) reasoning, potentially allowing AI systems to not only actively seek relevant information but also articulate a transparent, step-by-step rationale for their conclusions. This integration promises to amplify the reliability and interpretability of AI decision-making, as the combination of proactive inquiry and deliberate reasoning could mitigate biases and enhance the robustness of solutions. Ultimately, scaling PIR and fostering its compatibility with other advanced techniques represents a crucial step towards building AI systems capable of genuinely intelligent and trustworthy performance across a broad spectrum of applications.
The principles underpinning Proactive Information Retrieval (PIR) extend far beyond current Large Language Models, offering a pathway towards more broadly intelligent artificial systems. Rather than being limited to text-based applications, the core idea of actively seeking clarifying information before attempting a solution can be adapted to models processing diverse data types – images, audio, or even sensor data. This adaptability stems from PIR’s focus on how a system reasons, not simply what it knows. By prioritizing knowledge gap identification and targeted inquiry, the framework allows AI to move beyond pattern recognition and towards a more robust, human-like understanding of complex problems, ultimately enabling the development of systems capable of genuine insight and reliable performance across a multitude of domains.
The pursuit of robust reasoning systems, as detailed in this work concerning Proactive Inquiry, echoes a fundamental truth about all complex architectures: they are inherently transient. This paper’s focus on enabling Large Language Models to detect uncertainty and solicit clarification isn’t merely about improving accuracy; it’s acknowledging the inevitable limitations of any system facing incomplete information. As Paul Erdős observed, “A mathematician knows a lot of things, but he doesn’t know everything.” Similarly, these models, even with their impressive capabilities, benefit from acknowledging what they don’t know and proactively seeking the information needed to navigate complexity. The PIR framework, therefore, doesn’t strive for perfect solutions, but for graceful adaptation within the bounds of incomplete data – a hallmark of enduring systems.
What Lies Ahead?
The transformation of reasoning large language models into proactive inquirers, as demonstrated by this work, feels less like an arrival and more like a version update. The system gains a capacity-the ability to admit its own gaps in knowledge-but this admission itself introduces new vulnerabilities. Uncertainty detection, while valuable, is merely the first step in a protracted negotiation with incomplete information. The architecture must now account for the cost of inquiry – each question posed is a temporal expenditure, a divergence from the most direct path to a solution.
Future iterations will inevitably grapple with the paradox of self-awareness in these systems. A model that understands its limitations is, in a sense, aware of its own decay – the inevitable drift from perfect information. The challenge isn’t simply to minimize uncertainty, but to manage it gracefully. User simulation, as a training ground for proactive inquiry, is a necessary but limited construct. The true test will lie in unpredictable, real-world interactions, where the arrow of time consistently points toward refactoring and adaptation.
Ultimately, the pursuit of proactive reasoning is a search for a more resilient intelligence-one that doesn’t merely solve problems, but learns how to learn, and accepts that the map will never perfectly reflect the territory. The current framework offers a glimpse of this potential, but the path forward is marked not by elimination of error, but by the elegant accommodation of it.
Original article: https://arxiv.org/pdf/2601.22139.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- EMEA Masters Winter 2026 introduces official Qualifier for Esports World Cup
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Total Football free codes and how to redeem them (March 2026)
2026-01-31 22:45