Author: Denis Avetisyan
A new framework, APEX-SQL, improves the accuracy of converting natural language questions into database queries by actively learning and validating its assumptions about the underlying data.
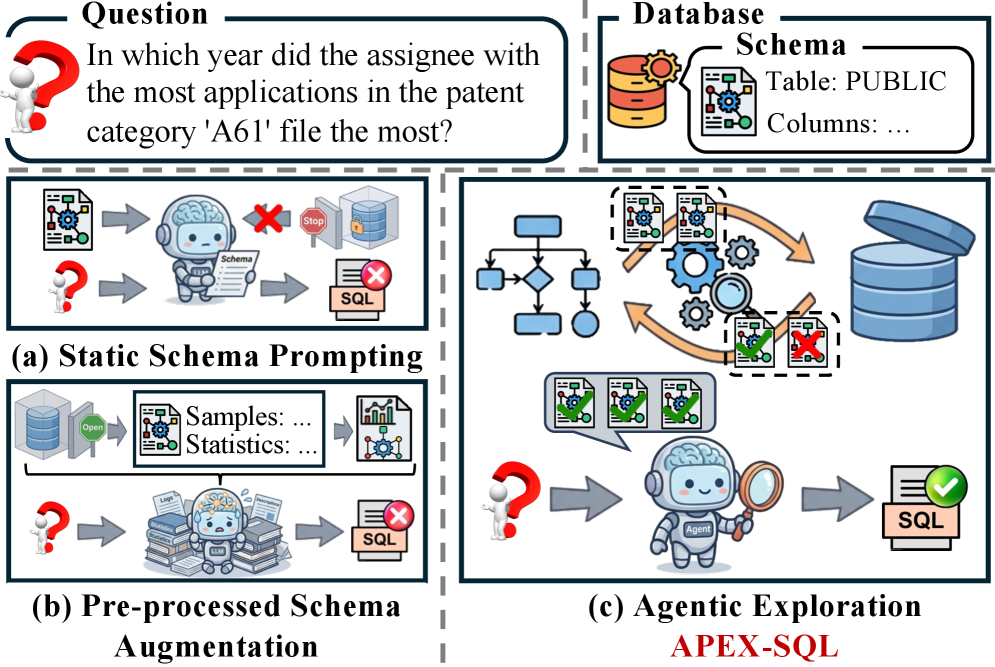
APEX-SQL utilizes agentic exploration, schema linking, and data profiling to enhance Text-to-SQL performance on complex enterprise databases.
Despite advances in Large Language Model-driven Text-to-SQL systems, performance falters when applied to the complexities of real-world enterprise databases. This paper introduces APEX-SQL: Talking to the data via Agentic Exploration for Text-to-SQL, a novel framework that moves beyond passive translation by employing an agentic exploration loop to verify database assumptions and refine query generation. Through logical planning, data profiling, and a deterministic retrieval mechanism, APEX-SQL achieves state-of-the-art results on benchmarks like BIRD and Spider 2.0-Snow, demonstrating a performance multiplier for foundation models. Could this agentic approach unlock more robust and accurate data analysis capabilities across diverse and complex data environments?
The Illusion of Perfect Data
Conventional Text-to-SQL systems often falter when confronted with the intricacies of real-world databases and the subtleties of human language. These systems frequently depend on identifying superficial similarities between the query and the database structure, a method that proves inadequate when schemas are complex – involving numerous tables and relationships – or when a user’s question is open to interpretation. The inherent ambiguity within natural language, combined with the layered nature of many database designs, creates a significant challenge for these systems to correctly parse the user’s intent and translate it into accurate SQL code. Consequently, even minor variations in phrasing or schema complexity can lead to substantial performance drops and inaccurate query results, highlighting the need for more robust and semantically aware approaches to Text-to-SQL conversion.
Traditional Text-to-SQL systems frequently exhibit limitations stemming from a reliance on superficial pattern matching rather than genuine understanding of database structure and query intent. These systems often identify keywords and attempt to map them directly to column names, a process prone to failure when faced with complex schemas or ambiguous phrasing. This approach is particularly vulnerable when data quality is compromised; missing values, inconsistent formatting, or inaccurate entries can disrupt pattern recognition and lead to incorrect SQL generation. Consequently, even slight variations in natural language or minor data imperfections can dramatically reduce performance and reliability, highlighting the need for systems capable of robust reasoning and adaptation beyond simple keyword association.
The effectiveness of automated data querying systems is critically undermined by the pervasive issue of data quality. Missing values, inconsistencies in formatting, and outright errors within databases create substantial obstacles for algorithms designed to translate natural language into precise database queries. These imperfections aren’t merely minor annoyances; they introduce ambiguity that forces systems to make assumptions, frequently leading to inaccurate or incomplete results. Fields intended to represent specific information, such as dates or identifiers, are particularly vulnerable, and their unreliability cascades through the entire query process. Consequently, even sophisticated models struggle to deliver consistent and trustworthy performance when confronted with real-world datasets characterized by these inherent quality flaws, highlighting the need for robust data validation and cleaning techniques.
The reliable interpretation of time-sensitive data presents a significant hurdle for Text-to-SQL systems, largely due to the common occurrence of null values in temporal fields. Fields like `UpstreamPublishedAt`, designed to record crucial timestamps, are often incomplete, introducing ambiguity when translating natural language into precise database queries. This absence of data forces systems to make assumptions or discard potentially relevant information, directly impacting the accuracy and completeness of results. Consequently, queries intended to retrieve data based on specific timeframes-such as “articles published last week”-become prone to errors or require complex workarounds, highlighting the critical need for robust null value handling and temporal reasoning capabilities within these systems.
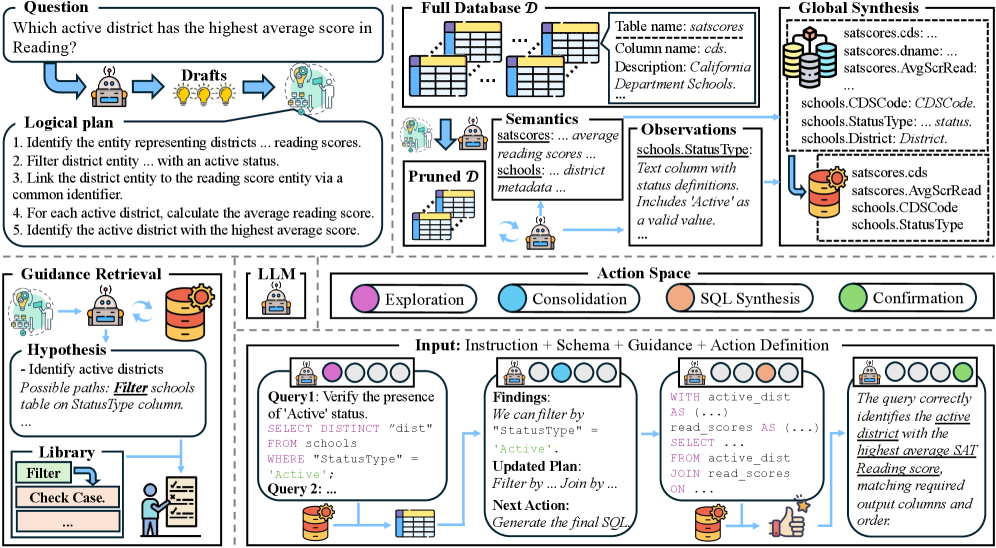
Beyond Passive Interpretation: The Agentic Approach
Agentic Exploration represents a departure from traditional Text-to-SQL methods that rely on passive interpretation of the natural language query and direct schema matching. Instead of solely reacting to the input, this paradigm introduces an active agent capable of independently investigating the database schema to fulfill the query’s requirements. This proactive approach involves the agent formulating hypotheses about relevant schema components, then systematically verifying those hypotheses through interactions with the database itself. The core principle is to move beyond simply perceiving the available data to actively exploring the schema, allowing the system to address ambiguities and incomplete information inherent in both the natural language question and the database structure.
The Hypothesis-Verification Loop functions as the core mechanism for Agentic Exploration. This iterative process begins with the agent formulating a hypothesis regarding the database schema, based on the natural language question and any prior knowledge. This hypothesis is then tested through database queries, specifically designed to validate or refute the initial assumption. The results of these queries are analyzed, and the agent subsequently refines its understanding of the schema, generating a new hypothesis. This cycle of hypothesis formulation, query execution, and analysis continues until the agent has gathered sufficient information to accurately translate the natural language question into a valid SQL query, or until a pre-defined iteration limit is reached. This active schema investigation allows the agent to address ambiguities and incomplete information that would hinder traditional, passive approaches.
Logical planning within the Agentic Exploration paradigm involves decomposing a natural language question into a sequence of discrete, abstract reasoning steps prior to any interaction with the database. This process doesn’t directly translate the question into SQL; instead, it constructs an intermediate representation outlining the necessary logical operations – such as identifying relevant tables, filtering conditions, and aggregation requirements – needed to derive the answer. This decomposition allows the agent to systematically address the question, enabling it to handle complex queries and adapt to schema variations without relying on direct pattern matching or pre-defined SQL templates. The planned steps are then executed through iterative database interactions, verifying each logical component before proceeding to the next.
Agentic Exploration addresses limitations arising from imperfect database documentation or data quality by actively querying the database schema itself. Instead of relying solely on pre-existing metadata, the system formulates and executes schema-level queries – such as retrieving table names, column definitions, and foreign key relationships – to construct a more complete understanding of the database structure. This proactive information gathering allows the agent to identify relevant tables and columns even when the natural language query lacks explicit references or when documentation is inaccurate or incomplete, ultimately improving the accuracy and robustness of Text-to-SQL translations.
Pruning the Search Space: Efficient Schema Linking
Dual-Pathway Pruning is a schema navigation technique designed to reduce computational load during `Schema Linking`. It operates by concurrently identifying both elements demonstrably irrelevant to the query and those potentially relevant. This simultaneous approach contrasts with sequential filtering methods, enabling a more efficient reduction of the search space. Irrelevant elements are immediately excluded, while potentially relevant elements are retained for further evaluation. This parallel pruning significantly accelerates the identification of necessary tables and columns, particularly within complex database schemas containing numerous fields and relationships.
Schema Linking, the identification of relevant database tables and columns for a given task, benefits significantly from a reduced search space. By systematically eliminating irrelevant schema elements, the process avoids exhaustive searches across all available tables and columns. This optimization directly translates to faster query execution times and improved accuracy in identifying the precise data required. The reduction in scope minimizes the potential for misidentification and the associated computational overhead, allowing the system to focus resources on evaluating only the most promising schema components. Consequently, Schema Linking becomes more efficient and reliable, particularly within complex database environments.
The system dynamically adapts to schema complexities by actively exploring data sources and prioritizing information beyond initially apparent fields. When encountering problematic or unreliable fields such as `UpstreamPublishedAt`, the agent utilizes iterative database queries-Exploration Rounds-to identify and leverage alternative data points. Specifically, if `UpstreamPublishedAt` proves unsuitable for schema linking, the system can prioritize and utilize data from fields like `VersionInfo:Ordinal` to establish relationships and accurately identify necessary schema elements. This allows the system to circumvent data quality issues and maintain linking accuracy without relying on potentially flawed information.
The system utilizes iterative database queries, termed `Exploration Rounds`, to progressively build a functional understanding of the target schema. Each round involves the agent formulating and executing a query, then analyzing the results to assess the relevance of schema elements. This process is not a single pass; rather, the agent cycles through multiple rounds, using the evidence gathered from prior queries to refine subsequent query formulations and focus on potentially useful tables and columns. The data obtained during each round informs the agent’s internal schema representation, allowing it to disambiguate relationships and ultimately identify the necessary schema components for linking.
![GPT-4o and DeepSeek-V3.2 exhibit comparable performance scaling on the Spider 2.0-Snow subset ([latex]N=120[/latex]) when utilizing the oracle schema.](https://arxiv.org/html/2602.16720v1/x3.png)
From Theory to Practice: Reliable SQL Generation
The system leverages an innovative approach called Agentic Exploration to generate functional SQL queries, even when confronted with incomplete or flawed data. This method doesn’t rely on pristine datasets; instead, it actively probes and refines potential solutions through a series of intelligently guided steps. By strategically navigating the database schema and employing supporting techniques, the system achieves a substantial 18.33% absolute gain in execution accuracy when tested against real-world, enterprise-grade datasets. This improvement signifies a marked advancement in the robustness and reliability of Text-to-SQL systems, demonstrating an ability to translate natural language into precise database queries with greater consistency and effectiveness, regardless of data imperfections.
The system’s enhanced performance in SQL generation stems from a process called Deterministic Guidance Retrieval, which proactively shapes the exploration phase. Rather than randomly searching for solutions, the system leverages the underlying logical plan of the desired query to generate targeted directives. This allows the agent to focus its efforts on the most promising paths, effectively pruning unproductive search spaces and accelerating convergence towards a correct SQL query. By grounding exploration in the query’s structure, the system exhibits improved efficiency and, crucially, a demonstrable increase in accuracy, particularly when dealing with complex and nuanced database schemas.
Evaluations demonstrate a substantial advancement in SQL generation capability, achieving 70.7% execution accuracy on the BIRD-Dev benchmark-outperforming established systems like OpenSearch-SQL (69.3%) and RSL-SQL (67.2%). This performance extends to more complex scenarios, as evidenced by a 51.0% execution accuracy on the notoriously difficult Spider 2.0-Snow dataset, a significant leap beyond the 35.3% achieved by DSR-SQL. These results indicate a robust system capable of translating natural language into functional SQL queries, even when faced with intricate database schemas and challenging query requirements, marking a considerable step forward in Text-to-SQL technology.
The system achieves a noteworthy 70.20% Pass@8 rate, signifying a substantial leap in the dependability of text-to-SQL translation. This metric indicates that, when presented with a natural language question, the system successfully generates a correct SQL query within eight attempts, consistently outperforming conventional text-to-SQL methods. This enhanced reliability isn’t merely about achieving a higher success rate; it represents a fundamental improvement in the system’s ability to handle the inherent ambiguities and complexities of natural language, and to generate valid and executable SQL even with imperfect or nuanced inputs. The robust performance underscores the effectiveness of the agentic exploration framework in navigating the search space for correct queries, delivering consistently accurate results and minimizing errors.
The pursuit of seamless Text-to-SQL translation, as demonstrated by APEX-SQL’s agentic exploration, inevitably introduces new layers of complexity. This framework attempts to bridge the gap between natural language and database mechanics, actively verifying schema assumptions-a necessary, if temporary, solution. It’s a predictable cycle; the system addresses the shortcomings of prior approaches only to create its own set of maintenance burdens. Donald Davies famously observed, “The computer is a tool, and like any tool, it can be used to solve problems or create new ones.” APEX-SQL exemplifies this truth; while it refines SQL generation through data profiling and schema linking, it simultaneously establishes a more intricate system prone to future fragility. The elegance of the theory will eventually yield to the realities of production.
What’s Next?
The elegance of agentic exploration, as demonstrated by APEX-SQL, will inevitably meet the harsh realities of production data. Schema linking and data profiling are presented as mitigations, but these are merely sophisticated guesses about systems built and maintained by others – systems that often defy internal consistency. The framework addresses a clear need, but each verified assumption represents another potential point of failure when confronted with the inevitable data anomaly or undocumented quirk. Tests, after all, are a form of faith, not certainty.
Future iterations will likely focus on robustness – not on achieving higher scores on benchmark datasets, but on graceful degradation when confronted with messy, incomplete, or deliberately misleading data. The promise of automation is tempting, yet one recalls the scripts that have deleted production databases. A critical area for exploration is the cost of verification; constant validation introduces latency, and the question becomes not whether a system can verify, but whether it should, given the operational overhead.
The real challenge isn’t generating SQL; it’s generating SQL that doesn’t silently return incorrect results. The field will likely see a shift from focusing on linguistic finesse to prioritizing statistical confidence – quantifying the likelihood that a query, even a syntactically correct one, actually answers the intended question. Beauty, in this context, won’t be found in clean code, but in systems that remain operational, even on Mondays.
Original article: https://arxiv.org/pdf/2602.16720.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Last Furry: Survival redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- eFootball 2026 “Countdown to 1 Billion Downloads” Campaign arrives with new Epics and player packs
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Limbus Company 2026 Roadmap Revealed
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
2026-02-21 10:59