Author: Denis Avetisyan
New research introduces a comprehensive benchmark for evaluating AI assistants that learn from user behavior over time to provide truly helpful, proactive support.
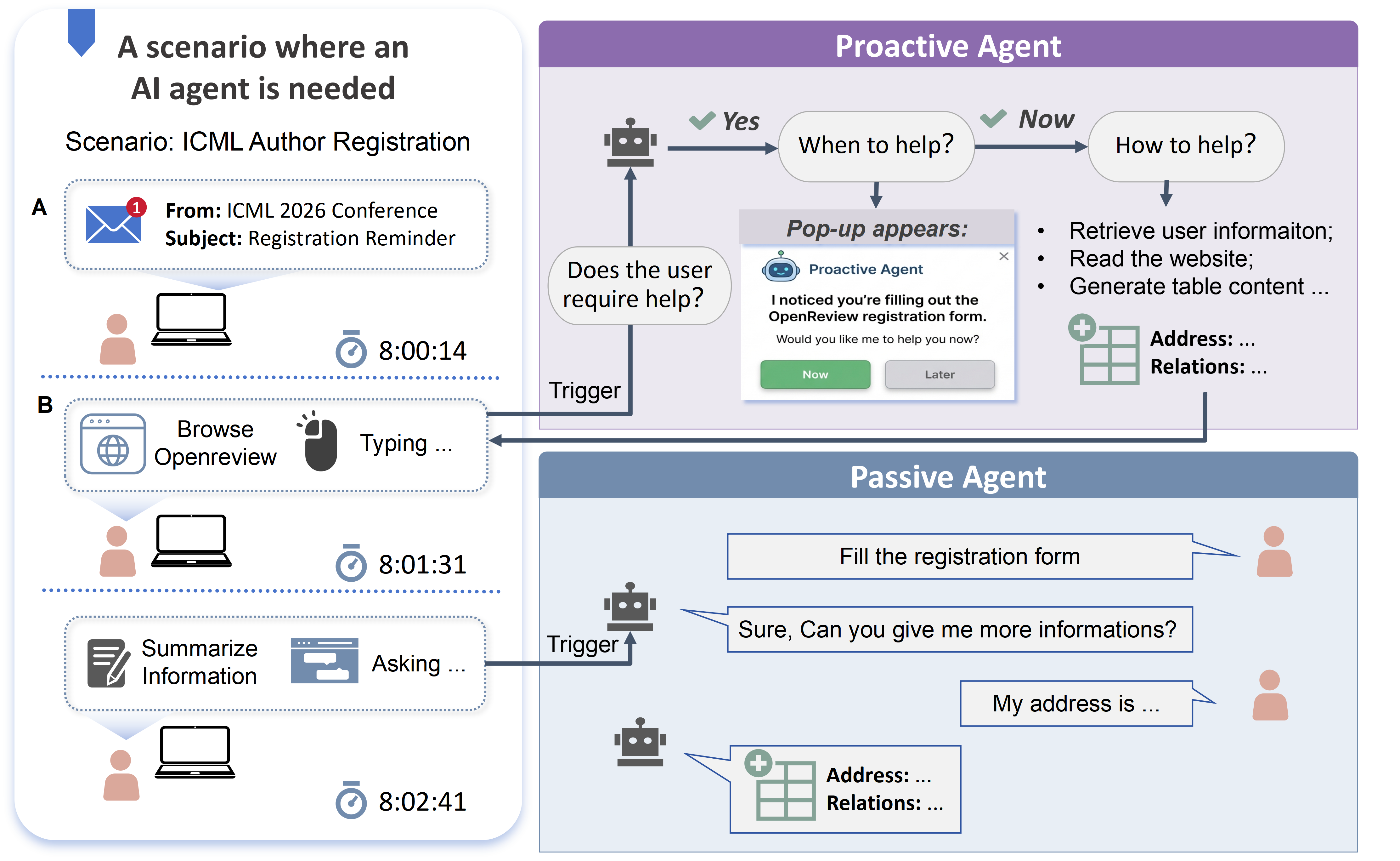
ProAgentBench, a new dataset and benchmark, facilitates the development and evaluation of AI agents leveraging long-term user context and visual-language models while prioritizing user privacy.
Existing benchmarks for proactive agents often rely on synthetic data and isolated tasks, failing to capture the nuances of authentic human-computer interaction and long-term behavioral context. To address this, we introduce ProAgentBench, a new dataset and evaluation framework detailed in ‘Proactive Agents, Long-term User Context, VLM Annotation, Privacy Protection, Human-Computer Interaction’, comprising over 28,000 real-user events collected across 500+ hours of sessions while prioritizing user privacy. Our analysis demonstrates that incorporating long-term memory and training on real-world data significantly enhances proactive assistance prediction accuracy compared to synthetic alternatives. Will these findings pave the way for more intuitive and effective AI agents capable of seamlessly anticipating and supporting user needs within complex workflows?
Beyond Reactivity: The Emergence of Anticipatory Agents
Current artificial intelligence systems are often fundamentally reactive, meaning they respond only after a user explicitly requests assistance or encounters a problem. This approach frequently results in a frustrating user experience, as individuals are left to navigate challenges independently before the AI can intervene. Unlike a helpful assistant who anticipates needs, these systems demand users articulate their difficulties, creating a barrier to seamless interaction. The limitations of this reactive paradigm highlight a critical gap in current AI capabilities – the inability to foresee user intentions or proactively offer support, ultimately hindering the potential for truly intuitive and efficient human-computer collaboration.
A fundamental shift in artificial intelligence is occurring with the development of proactive agents, systems designed to move beyond simply reacting to user requests. These agents continuously observe user behavior – patterns in application usage, data input, and even subtle delays – to anticipate needs before they are explicitly stated. This constant monitoring allows for timely assistance, offering relevant information or completing tasks automatically, thereby streamlining the user experience. Rather than waiting for a command, a proactive agent functions as a digital assistant capable of learning preferences and offering support precisely when it would be most beneficial, ultimately bridging the gap between technology and intuitive usability.
The efficacy of truly helpful proactive agents rests on their ability to predict not only if a user will require assistance, but also precisely when and how to offer it – a challenge addressed by recent model development. Evaluations demonstrate a promising capacity for such prediction, achieving an F1 score of 67.4% and an accuracy of 53.0% even in zero-shot settings, meaning the models could generalize to unseen situations without prior training on those specific contexts. This performance suggests a viable path toward systems that anticipate user needs and deliver timely support, moving beyond the limitations of reactive assistance and fostering a more seamless, intuitive user experience. The ability to function effectively in zero-shot scenarios is particularly noteworthy, indicating a robust understanding of underlying user behavior and a potential for broad applicability across diverse tasks and platforms.
![Performance on both identifying assistance opportunities ([latex]F_1[/latex] score) and predicting the correct assistance type (intention accuracy) improves with a larger historical context window, up to 10 minutes.](https://arxiv.org/html/2602.04482v1/figures/time_window_intention_acc.jpg)
Deconstructing User Behavior: The TemporalSnapshotSequence
A TemporalSnapshotSequence is a fundamental data structure for proactive agents, enabling the representation of user activity as a time-ordered series of visual and contextual data. This sequence comprises discrete screenshots captured at regular or event-driven intervals, coupled with associated metadata detailing the system state at the time of capture. Metadata includes, but is not limited to, application focus, window titles, active controls, and timestamps, providing a comprehensive record of the user’s interaction with the computing environment. The granularity and frequency of snapshots within the sequence directly impact the agent’s ability to accurately reconstruct and interpret user behavior over time, necessitating a balance between data fidelity and storage requirements.
User input for behavioral analysis is not limited to a single modality; the system accepts both MultiModalInput, which integrates visual screenshot data with accompanying text extracted from the screen, and TextOnlyInput, representing data derived solely from optical character recognition (OCR) performed on screenshots. This flexibility allows for operation even when visual information is insufficient or unavailable, and facilitates scalability across diverse environments. The system is designed to process either data stream independently or to leverage the combined information for a more comprehensive understanding of user activity.
Data collection for the development of proactive agents necessitates robust privacy safeguards. Our approach utilizes a `PrivacyCompliantDataCollection` pipeline incorporating both automated anonymization techniques and manual review processes to protect user information. This pipeline facilitated the capture of a substantial dataset comprising over 500 hours of continuous user working sessions, representing more than 28,000 distinct events. These events are logged while adhering to strict privacy protocols, ensuring ethical data handling and compliance with relevant regulations.
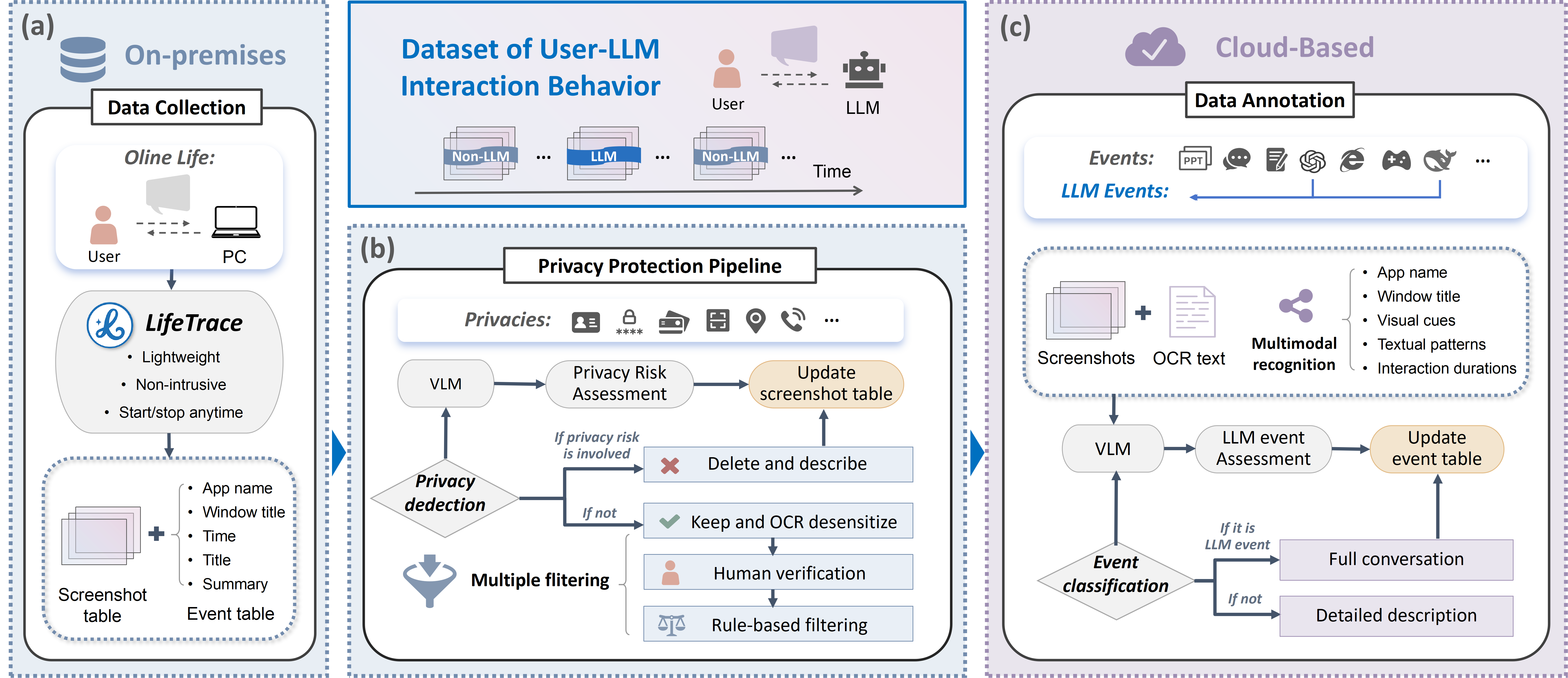
Orchestrating Proactivity: The Role of Large Language Models
Large Language Models (LLMs) function as the core cognitive engine within proactive agent architectures, enabling capabilities essential for independent operation. These models process information to perform reasoning tasks, such as inferring user intent and planning subsequent actions. Predictive capabilities allow LLMs to anticipate future needs or events, facilitating preemptive interventions. Furthermore, LLMs generate diverse content formats – including text, code, and structured data – to communicate with users, execute tasks, and maintain internal state. The ability to integrate these functions-reasoning, prediction, and content creation-within a single model is fundamental to building agents capable of autonomous and contextually relevant behavior.
Prompt engineering significantly impacts the performance of Large Language Models (LLMs) in proactive agent applications. ChainOfThoughtPrompting encourages the LLM to articulate its reasoning process step-by-step, improving accuracy in complex tasks. SelfConsistencyPrompting enhances result stability by generating multiple responses to a single prompt and selecting the most consistent answer. Conversely, ZeroShotPrompting allows the LLM to make predictions or complete tasks without any prior task-specific training examples, relying instead on its general knowledge base; this is particularly useful for rapid prototyping and generalization to novel situations.
To enhance the performance of large language models in proactive agent applications, several techniques are employed to provide contextual information and personalize responses. Retrieval-Augmented Generation (`RAG`) integrates external knowledge sources into the generation process, while utilizing `KnowledgeGraph` representations structures information for more effective reasoning. User behavior is summarized through `ClusterBasedPersona` methods, allowing the model to tailor its interactions. Critically, evaluation demonstrates that models trained on real-world data consistently outperform those trained on synthetically generated data, indicating the necessity of authentic data for achieving optimal results in proactive applications.
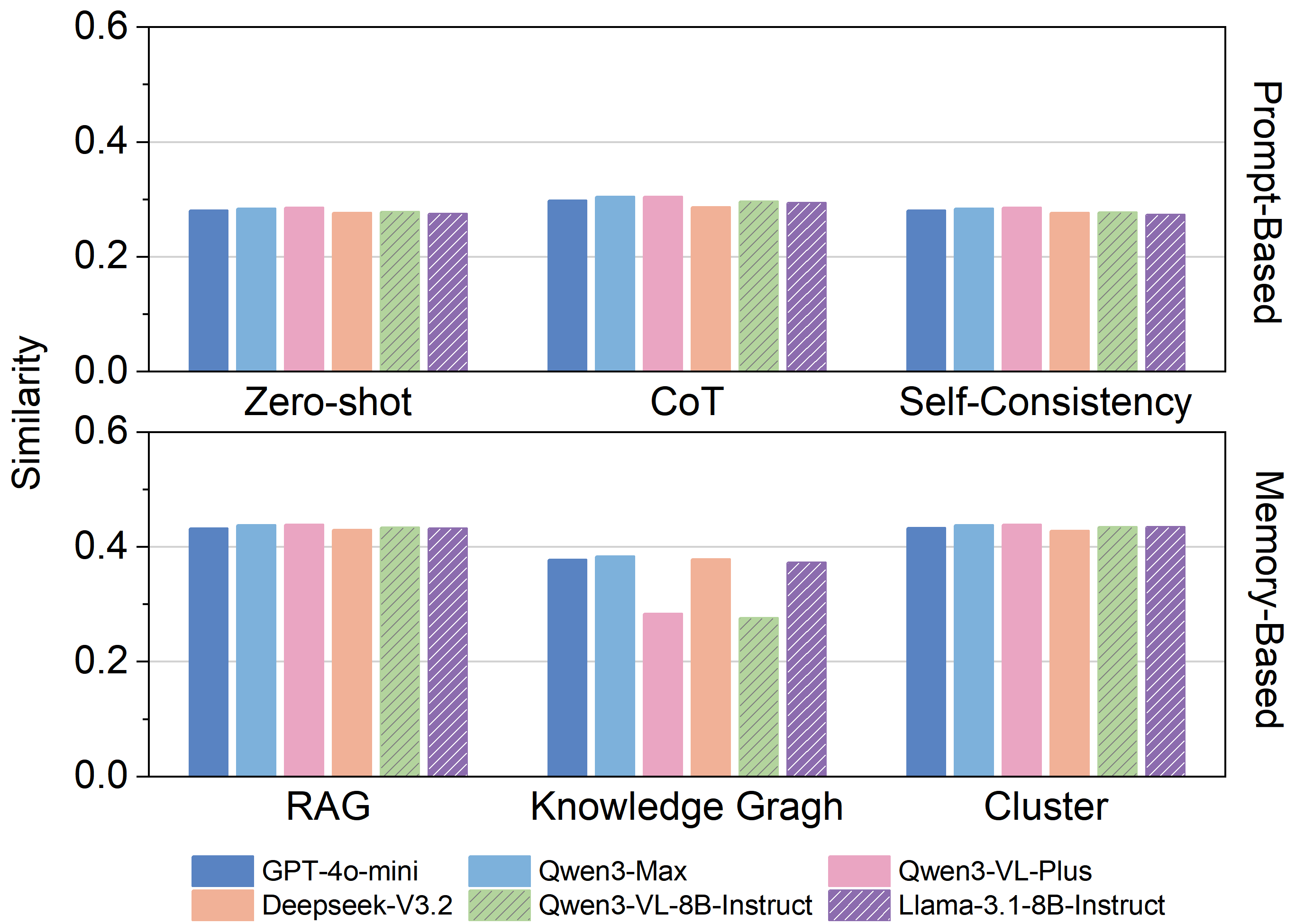
Benchmarking Proactive Intelligence: Establishing Rigorous Evaluation
The development of truly helpful proactive agents demands more than just theoretical capabilities; it requires rigorous testing within environments mirroring real-world complexities. The ProAgentBench benchmark addresses this need by providing a standardized and robust framework for evaluating these agents across a diverse array of realistic working scenarios. Unlike simplified laboratory settings, ProAgentBench presents agents with tasks that demand nuanced understanding, adaptation to unpredictable user behavior, and efficient resource management. This benchmark isn’t merely about assessing whether an agent can perform a task, but rather how effectively it integrates into a dynamic workflow, anticipating needs and providing assistance without disruption - ultimately paving the way for seamless and genuinely helpful AI collaboration.
Evaluating proactive agents necessitates a focus on practical performance metrics, extending beyond simple accuracy to encompass the speed and resourcefulness of intervention. Key indicators such as timing and overall efficiency are paramount, with InferenceLatency – the time taken for the agent to process information and formulate a response – proving especially critical for applications demanding real-time interaction. Recent studies utilizing the ProAgentBench framework demonstrate that most models achieve an inference latency of under five seconds, signifying a substantial step towards deployable, responsive agents capable of seamless integration into dynamic work environments and user experiences. This performance level suggests a viable pathway for building proactive systems that can offer timely assistance without introducing disruptive delays.
User interactions rarely unfold with consistent, predictable timing; instead, they exhibit periods of intense activity followed by relative calm – a phenomenon known as burstiness. Recognizing this pattern is paramount when designing proactive agents intended to assist users. An agent that intervenes consistently, regardless of user activity, risks becoming disruptive and annoying. Conversely, an agent that fails to recognize bursts of activity may miss critical opportunities to provide timely assistance. Therefore, optimizing intervention timing requires a nuanced understanding of burstiness, allowing agents to anticipate user needs during peak activity and remain unobtrusive during periods of quiet focus, ultimately fostering a more seamless and positive user experience.
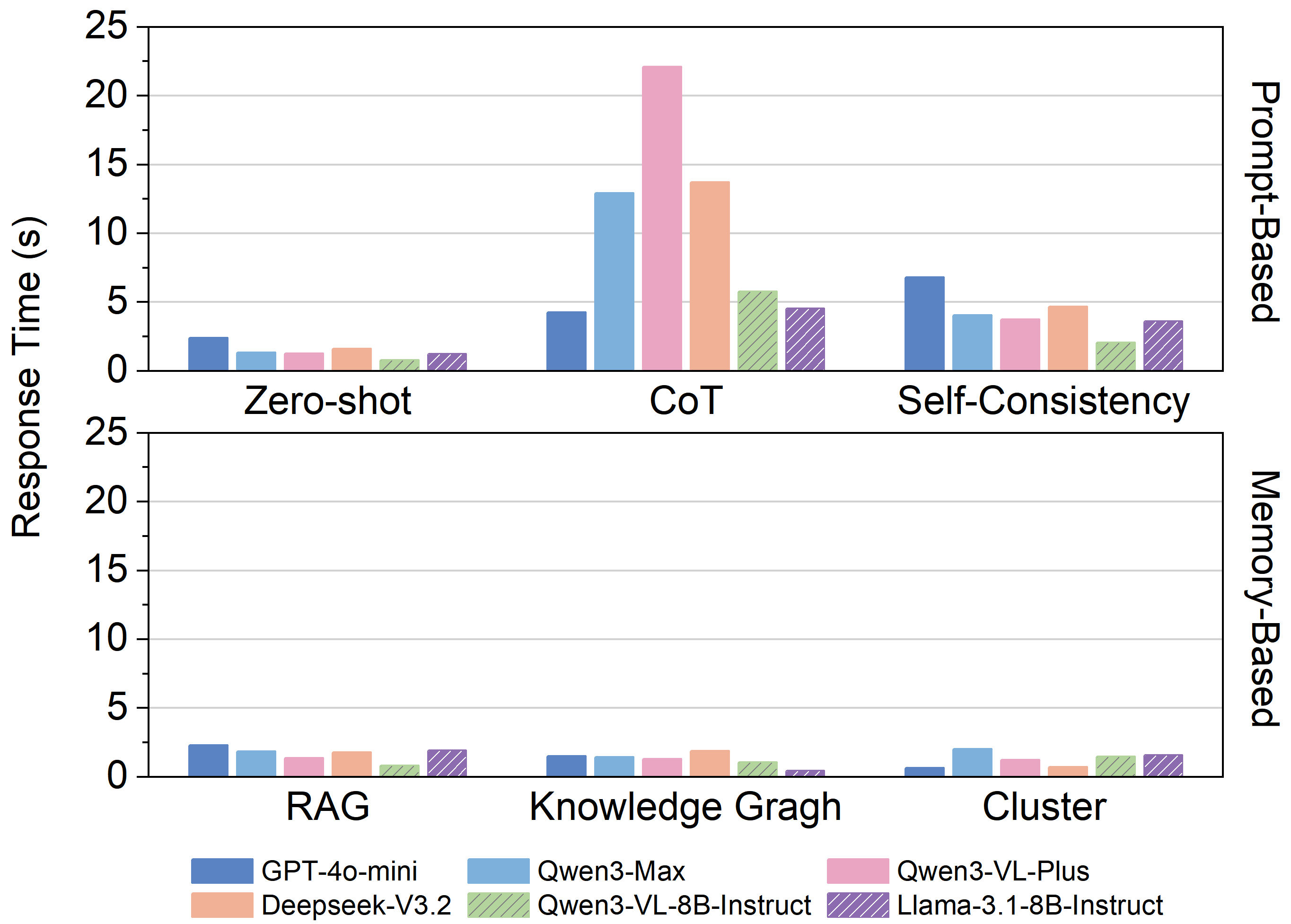
The development of ProAgentBench, as detailed in the article, necessitates a rigorous approach to evaluating proactive agent behavior. This echoes Robert Tarjan’s sentiment: “Programmers often spend more time debugging than writing code.” The benchmark isn’t simply about whether an agent appears helpful, but whether its actions are consistently correct and grounded in a genuine understanding of long-term user context. A superficial ‘working’ agent, lacking provable correctness in its proactive suggestions, is merely a conjecture-a potentially frustrating experience for the user. The dataset’s focus on real-world user behavior demands an emphasis on verifiable, logically sound algorithmic foundations for these agents, mirroring the need for meticulous debugging and a commitment to mathematical purity in code.
What’s Next?
The construction of ProAgentBench, while a necessary step, merely formalizes a pre-existing chaos. The true challenge does not lie in measuring proactive assistance, but in establishing a mathematically rigorous definition of ‘relevance’ itself. Current evaluations rely on proxy metrics – click-through rates, task completion – all ultimately subjective and vulnerable to manipulation. The field requires a shift toward provable guarantees: can an agent demonstrably minimize user effort, or maximize information gain, under defined conditions? Such proofs necessitate a formalization of user intent, a task bordering on the philosophical.
Furthermore, the long-term context component introduces an inherent instability. User behavior is not static; preferences drift, needs evolve. An agent optimized for past behavior may quickly become a hindrance. The ideal solution isn’t simply ‘learning’ from history, but predicting future needs with quantifiable accuracy. This demands a deeper integration of predictive modeling, perhaps leveraging techniques from control theory, rather than solely relying on the inductive biases of large language models.
Finally, the emphasis on privacy – laudable as it is – introduces another layer of complexity. Differential privacy, while mathematically sound, invariably introduces noise, potentially degrading performance. The future lies in developing algorithms that are intrinsically privacy-preserving, not merely retrofitted with obfuscation techniques. In the chaos of data, only mathematical discipline endures.
Original article: https://arxiv.org/pdf/2602.04482.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Gold Rate Forecast
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- ‘Project Hail Mary’s Soundtrack: Every Song & When It Plays
- All Mobile Games (Android and iOS) releasing in April 2026
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- Top 5 Best New Mobile Games to play in April 2026
2026-02-05 22:20