Author: Denis Avetisyan
Researchers have developed a novel approach that generates realistic and controllable animations by simultaneously learning the underlying skeletal structure and movement dynamics from video data.

RigMo unifies rig and motion learning in a self-supervised framework to generate 4D animation from raw mesh sequences without manual annotation.
Despite advances in 4D animation, learning realistic and controllable motion typically treats skeletal rigging and dynamic simulation as separate, often cumbersome, processes. This work introduces RigMo: Unifying Rig and Motion Learning for Generative Animation, a novel framework that jointly learns both rig structure and motion directly from raw mesh sequences, eliminating the need for human-provided annotations. By encoding deformations into compact latent spaces-one for rig definition and another for time-varying motion-RigMo enables feed-forward inference of animatable meshes with explicit structure and coherent dynamics. Could this unified approach unlock new possibilities for scalable and interpretable 3D character animation and dynamic modeling?
The Challenge of Bridging Realism and Efficiency in Animation
The creation of compelling 3D animation has long been hampered by the labor-intensive process of rigging, where digital “skeletons” are meticulously crafted and bound to a character’s mesh. This traditionally requires skilled animators to define the character’s range of motion, painstakingly adjusting countless parameters to achieve realistic deformation and prevent unnatural distortions. While essential for believability, manual rigging represents a substantial bottleneck in content creation pipelines, demanding significant time and resources – especially as projects grow in complexity and require a greater volume of animated assets. This dependence on manual effort not only limits production speed but also necessitates highly specialized expertise, restricting access to animation capabilities for smaller teams or independent creators.
Current animation rigging techniques often falter when applied beyond their specifically designed parameters. A character meticulously rigged for realistic human locomotion may exhibit distorted or unnatural movements when attempting more dynamic actions like acrobatics or fantastical flight. This limitation stems from the fact that each rigging solution is largely tailored to a particular mesh – the digital skeleton overlaid on a 3D model – and a predefined style of motion. Consequently, animators frequently face the laborious task of creating entirely new rigs for each asset, or even for variations in a single character’s performance, dramatically increasing production time and cost. The inability of existing systems to adapt to different shapes and movement patterns represents a significant hurdle in achieving efficient and scalable 3D animation workflows.
The pursuit of automated 3D animation hinges on developing computational models that effectively capture the interplay between an articulated character’s underlying skeletal structure and the complex dynamics of its movements. Current research emphasizes learning these representations directly from data, moving beyond manually defined constraints and kinematic hierarchies. This involves algorithms that can discern not just the arrangement of bones, but also the subtle correlations between joint angles, muscle activations, and resulting motion patterns. Successfully encoding both anatomy and dynamics promises a future where animation software can intelligently adapt to diverse character designs and generate realistic, nuanced movements with minimal human intervention, vastly expanding creative possibilities and reducing the time-consuming labor traditionally associated with rigging and keyframing.
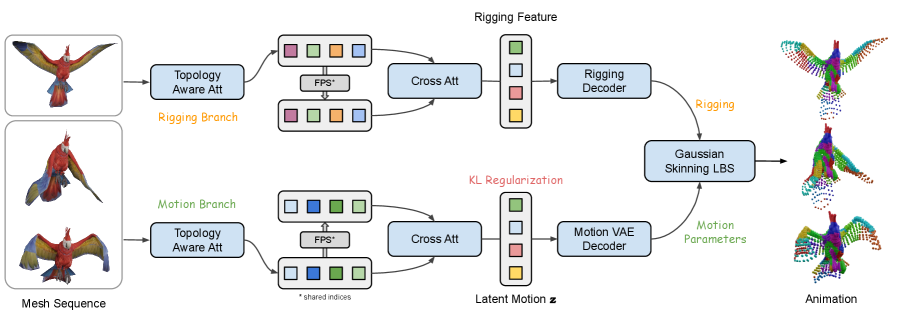
RigMo: A Self-Supervised Approach to Rigging and Motion
RigMo leverages self-supervised learning to bypass the need for manually annotated datasets, a significant limitation in traditional rigging and motion capture pipelines. This approach allows the framework to train directly on extensive, readily available datasets of unlabeled 3D mesh sequences, such as the Objaverse-XL dataset which contains over 800,000 3D assets. By formulating learning as a reconstruction task – predicting future states of a mesh sequence given its past – RigMo automatically discovers the underlying relationships between geometry and motion without explicit supervision. This is achieved by creating a training signal intrinsic to the data itself, enabling the model to scale to large datasets and generalize to novel, unseen meshes and motions.
RigMo-VAE is a generative model designed to concurrently learn both skeletal structure and motion characteristics from input data. The model represents the skeleton using Gaussian\ Bones, which are parameterized by mean and covariance, allowing for probabilistic representation and smooth interpolation of bone poses. Simultaneously, RigMo-VAE learns the dynamic relationships between these bones over time, effectively capturing the motion patterns exhibited within the training data. This simultaneous learning approach enables the model to generate realistic and coherent animations by jointly reasoning about both the skeletal configuration and its temporal evolution, without requiring explicit motion capture data or predefined kinematic constraints.
The Topology-Aware Encoder within RigMo is designed to extract both geometric features and connectivity information from input meshes. This is achieved through a dedicated processing pathway that explicitly considers the relationships between vertices and faces, rather than treating the mesh as a simple point cloud. By encoding this topological data, the model gains the ability to generalize to meshes with differing structures and numbers of vertices or faces. This allows RigMo to effectively learn and transfer rigging and motion skills across a wider range of 3D assets without requiring retraining for each unique topology.
Linear Blend Skinning (LBS) is employed as the deformation method within RigMo to generate mesh movement from learned bone transformations. LBS functions by representing a mesh as a weighted sum of influences from multiple bones; each vertex is associated with a set of Skinning Weights that determine the contribution of each bone to its final position. When a bone undergoes a transformation (rotation and translation), the weighted average of these transformations is applied to each influenced vertex, deforming the mesh. This process allows for realistic and controllable mesh animation based on the learned skeletal structure and motion dynamics, offering computational efficiency as it requires only matrix multiplications for deformation.
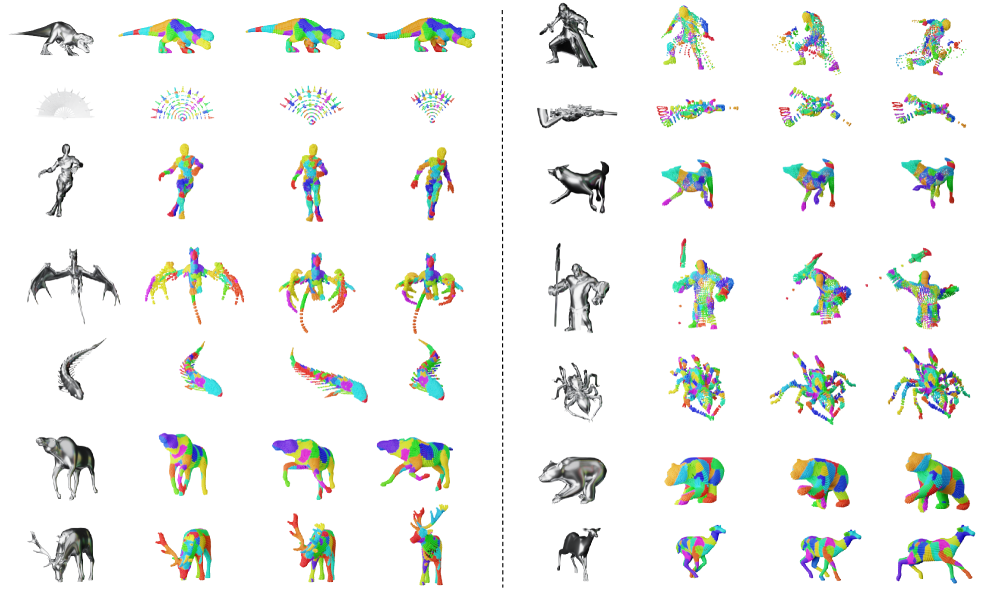
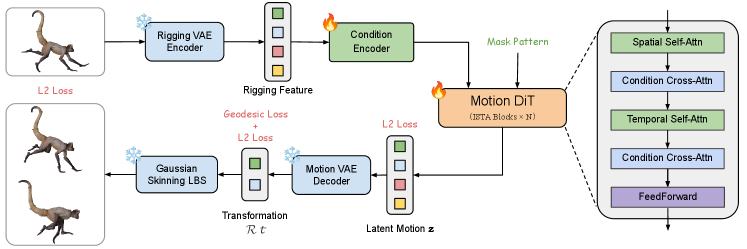
MotionDiT: Steering Animation with Diffusion in Latent Space
MotionDiT utilizes a diffusion transformer architecture operating within the motion latent space learned by RigMo, a dimensionality reduction technique for human motion data. This approach allows for high-dimensional motion control by manipulating the latent representation rather than directly generating joint angles. The diffusion process, conditioned on user-defined inputs, iteratively refines a randomly initialized latent vector into a coherent motion sequence. By operating in the latent space, MotionDiT reduces computational complexity and improves the stability of motion generation, enabling precise control over generated poses and trajectories with a lower dimensional parameter space than direct kinematic control.
MotionDiT facilitates detailed manipulation of generated motion by incorporating desired characteristics directly into the diffusion process. This conditioning allows users to specify target poses, trajectories, or other kinematic properties, influencing the generated animation at a fine-grained level. Rather than generating motion from random noise, the diffusion model is guided by these user-defined parameters, enabling precise control over the output. The system achieves this by modulating the denoising steps of the diffusion process based on the specified motion characteristics, resulting in animations that adhere to the desired kinematic constraints with a high degree of accuracy and granularity.
MotionDiT utilizes a Frame Mask to selectively condition the diffusion process on observed frames of an input sequence. This mask functions as a spatial and temporal guide, informing the diffusion model which frames contain valid motion data and which should be generated or completed. By explicitly specifying observed frames, the framework mitigates error propagation and maintains temporal consistency throughout the generated animation. The Frame Mask effectively focuses the diffusion process on completing missing or corrupted portions of the motion sequence, rather than generating the entire sequence from noise, resulting in more accurate and coherent motion synthesis.
Quantitative evaluation of MotionDiT utilizes Chamfer Distance as a primary metric to assess the fidelity and realism of generated animations. Results demonstrate that MotionDiT consistently outperforms state-of-the-art baseline methods in minimizing Chamfer Distance, indicating a closer correspondence between generated and ground truth motion data. Specifically, lower Chamfer Distance scores correlate with higher accuracy in pose estimation and trajectory reproduction. Furthermore, the framework’s performance in this metric directly validates its ability to maintain temporal coherence throughout the generated animation sequences, ensuring smooth and realistic movements.
Towards a Future of Versatile and Accessible 3D Animation
The creation of compelling 3D animation has historically demanded extensive manual effort, requiring skilled animators to painstakingly define the movement of each virtual character or object. RigMo and MotionDiT represent a considerable advancement by automating key stages of this process, effectively reducing the time and expertise needed to produce high-quality animations. This framework intelligently generates animation rigs – the digital skeletons that control a 3D model – and subsequently applies motion capture data or procedural controls to bring these models to life. By streamlining the traditionally laborious tasks of rigging and animation, this technology not only accelerates content creation but also opens doors for a broader range of creators to participate in the field, fostering innovation and accessibility within 3D animation.
The advent of RigMo and MotionDiT signifies a shift towards democratizing 3D animation by removing traditional barriers to entry. Previously, creating compelling 3D content demanded specialized skills in both character rigging – building the digital skeleton – and animation itself. This framework bypasses the need for bespoke rigging for each model and motion, enabling users to apply learned movements to a wide variety of shapes and forms. Consequently, individuals without extensive technical training can now readily prototype and generate animations, fostering creativity and innovation across diverse fields – from independent game development and virtual reality experiences to educational content and personalized storytelling. The ability to generalize across meshes and styles effectively lowers the threshold for participation in 3D content creation, empowering a broader audience to realize their visions.
Traditionally, 3D animation demands meticulous, sequential work – first building a digital skeleton (rigging) and then bringing it to life with movement (animation). RigMo disrupts this process by separating these two stages. This decoupling allows creators to quickly test ideas and refine animations without repeatedly revisiting the foundational rigging. Designers can now iterate on motion designs and visual styles with unprecedented speed, effectively accelerating the entire creative workflow. The ability to rapidly prototype and visualize changes fosters experimentation, allowing animators to explore a wider range of possibilities and ultimately deliver more polished and expressive results with significantly reduced development time.
The RigMo framework distinguishes itself through remarkable efficiency in 3D animation generation, achieving performance on par with, or even exceeding, existing methods that rely on substantially larger latent token counts – often exceeding 512 – while operating with a significantly reduced set of just 48 or 128 latent tokens. This streamlined approach not only accelerates processing but also minimizes computational demands, opening possibilities for wider accessibility and real-time applications. Current development is directed toward expanding RigMo’s capabilities to encompass more intricate interactions and realistic physics simulations, promising to deliver even more compelling and lifelike animated content in the future.
The RigMo framework, as presented in this work, prioritizes a holistic understanding of animation-not merely surface-level motion, but the underlying skeletal structure that governs it. This echoes Donald Knuth’s sentiment: “Premature optimization is the root of all evil.” RigMo avoids optimizing for specific motions in isolation; instead, it learns a unified representation of both rig and motion. By jointly learning these aspects from raw data, the system fosters a more robust and adaptable generative model. The elegance of RigMo lies in its ability to derive complex behavior from simple, foundational principles, creating a system where the structure inherently dictates the possibilities of animation.
Future Directions
The decoupling of rig definition from animation-a practice historically dictated by human artistry-reveals a fundamental truth: structure and behavior are not merely linked, but co-defined. RigMo’s success in learning both simultaneously from raw data suggests a broader principle. Future work should explore whether this joint learning paradigm extends to other domains where dynamic systems are defined by underlying architectures. One anticipates, however, that simply scaling the approach will not be sufficient. The inherent complexity of mesh data demands a critical assessment of representational capacity; a more elegant encoding of geometric priors may prove vital.
A pressing limitation remains the implicit assumption of consistency within the training data. Real-world motion is rarely pristine. The introduction of noise, occlusion, or stylistic variation-elements easily dismissed as imperfections-will inevitably test the robustness of learned representations. Addressing these challenges requires not simply more data, but a deeper understanding of how the framework interprets and extrapolates from incomplete or ambiguous signals. The pursuit of truly generative animation necessitates a system capable of gracefully handling the unexpected.
Ultimately, the value of RigMo, and similar approaches, lies not in automating existing techniques, but in uncovering new principles. The framework offers a glimpse of a future where animation arises not from explicit design, but from the emergent properties of learned systems. The question then becomes: what other constraints, currently imposed by human convention, might be relaxed-or even discarded-to unlock truly novel forms of dynamic expression?
Original article: https://arxiv.org/pdf/2601.06378.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- How to find the Roaming Oak Tree in Heartopia
- M7 Pass Event Guide: All you need to know
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
2026-01-18 04:40