Author: Denis Avetisyan
A new study reveals that code produced by AI agents often contains significantly more duplicated code than human-written software, creating a potential maintenance burden.
Research demonstrates that reviewers frequently fail to identify increased code redundancy in AI-generated pull requests, leading to the accumulation of silent technical debt.
While large language models (LLMs) accelerate software development, their impact on long-term code quality remains unclear. This paper, ‘More Code, Less Reuse: Investigating Code Quality and Reviewer Sentiment towards AI-generated Pull Requests’, examines the characteristics of code generated by LLM agents, revealing a tendency towards increased redundancy compared to human-authored code. Surprisingly, despite these quality concerns, reviewers often express more positive sentiment towards AI-generated contributions. This disconnect suggests that superficial plausibility may mask accumulating technical debt-but can we develop strategies to foster more effective human-AI collaboration and mitigate these risks?
The Shifting Sands of Software Creation
The landscape of software development is undergoing a rapid transformation with the increasing adoption of Large Language Models (LLMs) for automated code generation. This shift is strikingly visible in the growing number of Agentic-PRs – pull requests created by AI agents capable of independently proposing and implementing code changes. These agents, powered by LLMs, can autonomously address issues, add features, and even refactor existing codebases, dramatically accelerating development cycles. While still in its early stages, this trend represents a fundamental change in how software is built, moving from a primarily human-driven process towards a collaborative human-AI partnership. The proliferation of Agentic-PRs isn’t simply about automating repetitive tasks; it suggests a future where AI actively participates in the design and implementation of complex software systems.
The accelerating adoption of AI-driven code generation, while promising increased development velocity, presents a significant risk of accumulating technical debt. Automated solutions, focused on functional correctness, may prioritize expedient solutions over maintainability, scalability, or adherence to established architectural principles. This can manifest as convoluted logic, duplicated code, or a lack of comprehensive testing, creating a backlog of future rework. Consequently, teams may find themselves burdened with a codebase that is increasingly difficult and costly to modify, ultimately negating the initial gains in efficiency. The potential for suboptimal code isn’t a matter of malicious intent, but rather a consequence of AI prioritizing ‘working’ code over ‘well-crafted’ code, demanding careful oversight and robust code review processes to mitigate long-term consequences.
Assessing the quality of code produced by artificial intelligence demands a shift beyond conventional software metrics. While measures like Cyclomatic Complexity and Lines of Code offer insights into code structure and size, they prove inadequate for evaluating the nuanced characteristics of AI-generated solutions. These traditional metrics often fail to capture aspects such as semantic similarity to optimal solutions, the presence of hidden bugs requiring extensive testing, or the maintainability of code that, while functionally correct, might deviate significantly from established coding conventions. Consequently, researchers are actively developing new evaluation criteria focusing on aspects like code efficiency – measured not just in execution time but also in resource utilization – and the ‘cognitive load’ imposed on developers tasked with understanding and modifying the AI’s output. The goal is to establish a more holistic understanding of code quality, recognizing that functionally correct code isn’t necessarily good code, and that AI-generated solutions require specialized evaluation frameworks to ensure long-term software health.
The Shadow of Semantic Similarity
Existing code clone detection techniques primarily rely on syntactic matching, which compares code based on textual similarity. This approach proves inadequate when identifying instances where code performs the same function but is implemented with different variable names, control flow structures, or commenting styles. Consequently, these methods frequently fail to detect semantic clones – code fragments that are functionally equivalent despite having dissimilar syntax. This limitation results in a significant underestimation of code redundancy, hindering efforts to improve code maintainability, reduce bugs, and optimize software development processes. The inability to accurately identify semantic similarity leads to missed opportunities for refactoring and reuse, increasing technical debt and development costs.
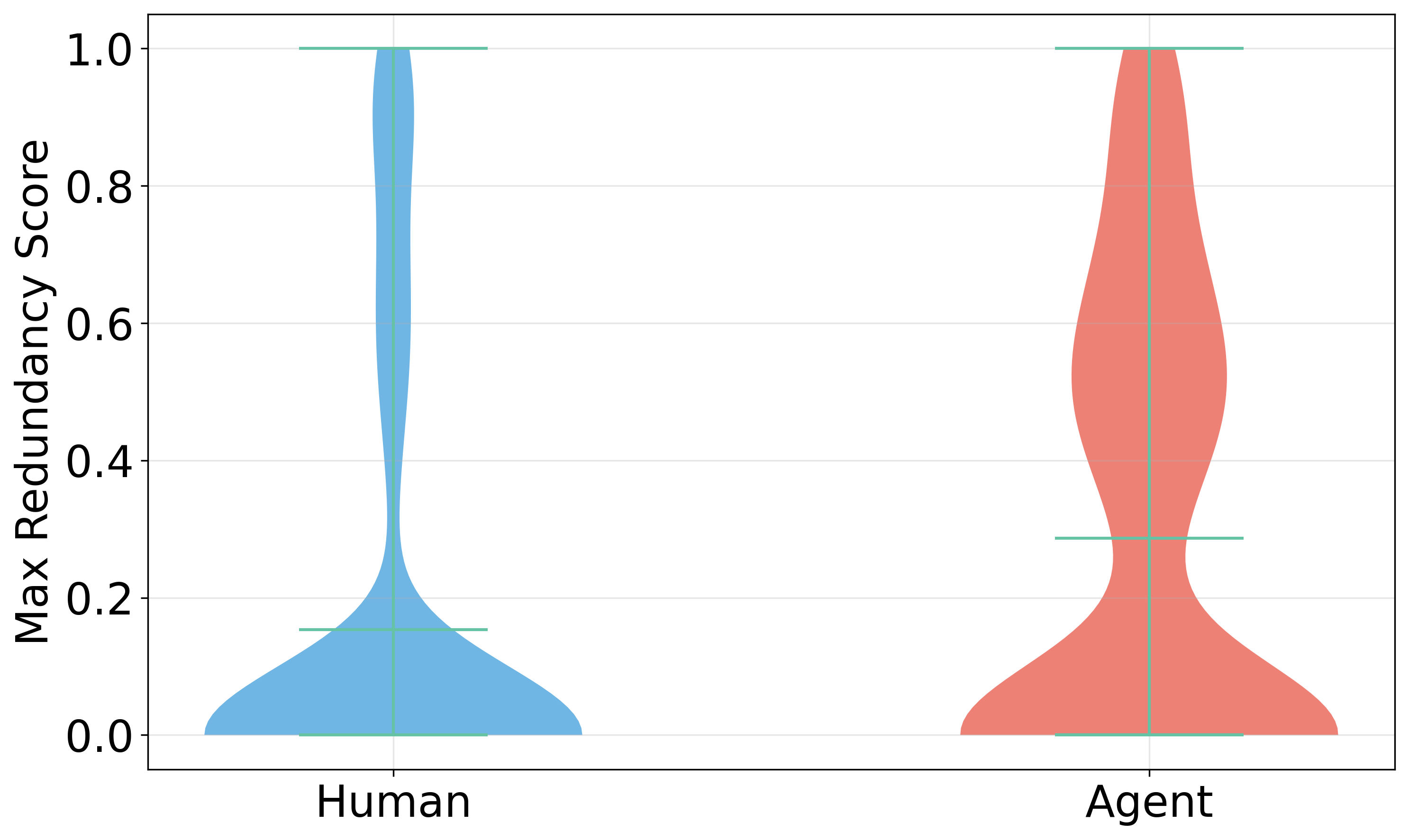
The Max Redundancy Score is a metric designed to quantify code redundancy based on functional equivalence, addressing limitations of syntax-based clone detection. It utilizes the CodeSage-Large language model to assess semantic similarity, enabling the identification of code clones even when they exhibit significant syntactic differences. The score is derived from the maximum similarity identified between code fragments when analyzed by CodeSage-Large, providing a numerical value representing the degree of functional overlap. This approach allows for the detection of code clones that traditional methods, reliant on textual matching, would miss, offering a more comprehensive assessment of code duplication.
The Max Redundancy Score incorporates PyRef, a program analysis tool, to refine redundancy assessments by specifically excluding code movements that do not impact functional equivalence. PyRef identifies and filters out refactoring operations – such as variable or function renaming, or reordering of independent statements – that alter the code’s surface form without changing its behavior. This filtering process prevents these irrelevant syntactic changes from falsely inflating redundancy scores, thereby ensuring the metric accurately reflects genuine code duplication based on semantic similarity rather than superficial resemblance. The use of PyRef focuses the analysis on substantial code overlap that represents actual redundancy, improving the precision of the Max Redundancy Score.
Mapping the Contributions: The AIDev Dataset
The AIDev Dataset is a publicly available collection of pull requests sourced from GitHub, specifically designed to enable comparative analysis between code written by human developers and that generated by artificial intelligence. This dataset includes a substantial number of pull requests, encompassing a variety of programming languages and project types, and is meticulously labeled to identify the authorship of each code contribution. Crucially, the dataset provides the raw code changes, commit metadata, and author information necessary for quantitative and qualitative assessment of code characteristics, allowing researchers to rigorously evaluate qualities such as code complexity, style, functionality, and the presence of code clones. Its scale and detailed labeling facilitate statistically significant comparisons and contribute to a more objective understanding of the strengths and weaknesses of AI-generated code.
Analysis of the AIDev Dataset using the Max Redundancy Score indicates a disproportionate occurrence of Type-4 code clones within AI-generated pull requests. Type-4 clones are defined as sections of code that perform the same function but are implemented using different syntactic structures. This suggests AI models, when generating code, frequently utilize alternative, yet semantically equivalent, implementations instead of directly reusing existing code patterns. The prevalence of these semantic clones with differing syntax contributes to the higher overall redundancy observed in AI-generated code compared to human-authored code, indicating a potential area for improvement in code generation efficiency and readability.
Analysis of the AIDev dataset using the Max Redundancy Score metric demonstrates a statistically significant increase in semantic redundancy within AI-generated code compared to human-authored code. The Average Max Redundancy (AMR) for AI-generated pull requests was calculated at 0.2867, while human developers exhibited an AMR of 0.1532. This represents an 87% increase in redundancy for AI-generated code – almost 1.87 times greater – and the observed difference is statistically significant with a p-value less than 0.001, indicating a low probability that this result occurred by chance.
The Human Element: Gauging Reviewer Sentiment
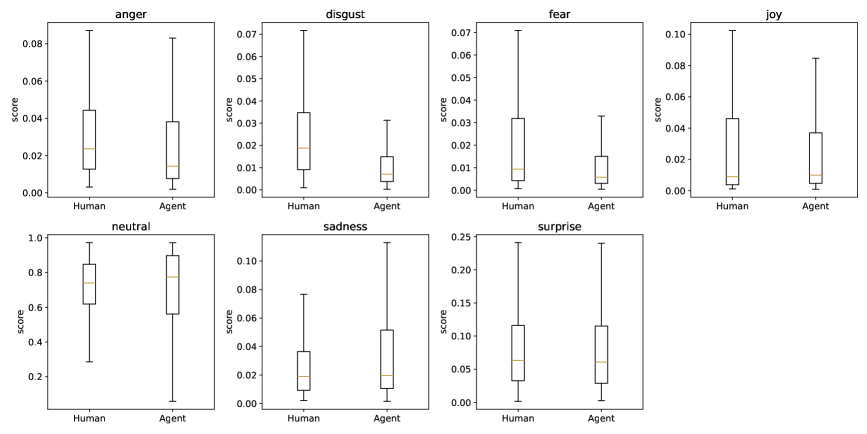
Reviewer sentiment acts as a crucial barometer for evaluating code contributions, extending beyond simple functional correctness to encompass aspects of quality and long-term maintainability. A positive emotional response from experienced developers suggests code that is not only effective but also readily understandable and adaptable for future modifications. Conversely, negative sentiment – indicated by expressions of confusion, frustration, or concern – often signals potential issues with code clarity, complexity, or adherence to established coding standards. Consequently, gauging these emotional reactions offers valuable insight into the true impact of code changes, providing a more nuanced understanding of their overall value beyond merely passing tests or fulfilling immediate requirements. This approach highlights the inherently social nature of software development, where perceptions of quality are as important as technical accuracy.
To gauge the qualitative reception of code contributions, a sentiment analysis was performed on reviewer comments. This analysis leveraged the Emotion English DistilRoBERTa-base model, a sophisticated natural language processing tool capable of discerning emotional undertones within text. By applying this model to comments associated with both human-authored and AI-generated code changes, researchers were able to quantify the emotional reactions – such as joy, sadness, anger, or neutrality – expressed by reviewers. This approach moved beyond simple acceptance or rejection metrics, providing a nuanced understanding of how developers perceive the quality, clarity, and maintainability of code originating from different sources. The resulting sentiment scores offered valuable insights into the subjective experience of reviewing code, complementing traditional code quality measurements.
A comparative analysis of code contributions indicates a substantial difference in refactoring behavior between human developers and AI agents. Human developers, on average, remove 26.26 lines of code per contribution, a figure significantly higher than the 8.47 lines removed by AI agents. This disparity suggests that human developers engage in more extensive code optimization and refactoring practices, focusing not only on adding functionality but also on improving the existing codebase’s clarity, efficiency, and maintainability. While AI agents demonstrate proficiency in generating code, this data implies a current limitation in their capacity for holistic code improvement, which often necessitates substantial restructuring and simplification beyond mere functional addition.
The study illuminates a predictable, yet disheartening, trend: increased code redundancy in AI-generated pull requests. This accumulation of silent technical debt isn’t merely a quantitative issue; it’s a temporal one. As systems grow, even subtle inefficiencies compound, accelerating their eventual decay. This resonates with the observation of Henri Poincaré: “It is through science that we arrive at certainty, and through art that we arrive at truth.” While AI offers the certainty of rapid code generation, the truth lies in understanding that improvements-like AI assistance-age faster than expected. The failure of reviewers to detect code clones suggests a systemic blindness to the long-term implications of present gains, highlighting the inevitable entropy inherent in all complex systems.
What Lies Ahead?
The findings suggest a curious paradox: automation, intended to accelerate development, may instead be seeding future fragility. Versioning is a form of memory, and this work indicates that current AI agents possess a poor one, repeatedly generating code fragments already present within the system. The acceptance of these redundant blocks by reviewers is not merely an oversight, but a symptom of a deeper challenge – the difficulty of perceiving entropy in the face of novelty. The arrow of time always points toward refactoring, yet this study suggests that some tools are accelerating the need for it.
A critical next step lies in refining the metrics used to evaluate code quality. Traditional measures often fail to capture the subtle costs of redundancy, focusing instead on superficial complexity. Future research should investigate how these silent debts accumulate, and how they impact long-term maintainability. The focus must shift from simply producing code to curating a codebase-recognizing that software, like all systems, degrades, and graceful aging requires proactive intervention.
Ultimately, the challenge isn’t about perfecting the AI, but about understanding its limitations. These agents aren’t replacing developers; they’re amplifying existing tendencies. The true test will be whether the field can develop tools and processes that acknowledge the inevitable decay of software, and allow for its managed evolution, rather than attempting to halt it altogether.
Original article: https://arxiv.org/pdf/2601.21276.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Limbus Company 2026 Roadmap Revealed
- EMEA Masters Winter 2026 introduces official Qualifier for Esports World Cup
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Total Football free codes and how to redeem them (March 2026)
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
2026-02-02 05:05