Author: Denis Avetisyan
Researchers have developed a method to seamlessly integrate new features into existing tabular learning models during inference, boosting performance and adaptability.
![The system adapts a pre-trained model θ - initially trained on attribute set <i>X</i> - during inference to incorporate newly discovered attributes [latex]\tilde{X}[/latex], such as YWHAG and MI recently identified as significant factors in Alzheimer’s disease prediction, thereby aiming to enhance predictive performance through incremental knowledge integration rather than complete retraining.](https://arxiv.org/html/2601.15751v1/x1.png)
This work introduces TabII, a technique leveraging information bottleneck principles and contrastive learning for incremental sample condensation in tabular data.
Despite advances in tabular data analysis, standard AI models struggle with dynamically evolving tables where columns change over time. This paper introduces ‘Tabular Incremental Inference’ (TabII), a novel approach enabling trained models to incorporate new columns during inference without retraining. TabII frames this as an optimization problem guided by information bottleneck theory-minimizing mutual information between data and representation while maximizing it between representation and task labels-and implements this using Large Language Model placeholders, Pretrained TabAdapters, and Incremental Sample Condensation. Demonstrating state-of-the-art performance across eight public datasets, can TabII unlock more adaptable and robust tabular learning in real-world scenarios with constantly changing data landscapes?
The Inevitable Drift: When Tables Refuse to Stay Still
Conventional tabular learning models often exhibit a significant limitation: a difficulty in accommodating new attributes after the initial training phase. These models typically require complete retraining whenever the data schema evolves – meaning a new column, or feature, is added to the dataset. This inflexibility poses a challenge in real-world applications where data is rarely static; business metrics change, sensor networks expand, and user behaviors shift, all leading to evolving data structures. Consequently, models struggle to maintain performance as the data they are tasked with analyzing becomes increasingly different from what they were originally trained on, hindering their long-term utility and necessitating costly and time-consuming model updates.
The real-world utility of many machine learning models is often compromised by their inability to handle evolving data landscapes. Traditional tabular learning systems are typically designed with a fixed input schema, meaning any addition of new attributes or features post-deployment necessitates costly and time-consuming retraining. This inflexibility presents a significant challenge in dynamic environments – such as financial markets, fraud detection, or sensor networks – where data characteristics are rarely static. As new information becomes available, models struggle to incorporate it effectively, leading to performance degradation and a diminished capacity to make accurate predictions on evolving datasets. Consequently, the inability to seamlessly adapt to schema changes restricts the deployment of these models in many practical, real-time applications that demand continuous learning and responsiveness.
A significant hurdle in applying machine learning to real-world tabular data stems from the challenge of continuous adaptation. Existing models often exhibit ‘catastrophic forgetting’ – a rapid decline in performance on previously learned tasks when exposed to new information. Completely retraining a model from scratch with each schema update is computationally expensive and impractical for many applications. The core difficulty, therefore, isn’t simply learning new attributes, but doing so without disrupting the knowledge already encoded within the model’s parameters. This necessitates the development of techniques that can selectively integrate new information while preserving the integrity of previously learned patterns, effectively balancing plasticity and stability within the learning process. Addressing this problem is crucial for deploying robust and adaptable tabular learning systems in dynamic environments.
Tabular Incremental Inference presents a compelling pathway for machine learning models to continuously learn from evolving datasets, yet its successful implementation demands a delicate equilibrium. The challenge isn’t simply adding new attributes to a tabular structure; it’s doing so without disrupting the knowledge the model has already acquired – a phenomenon known as catastrophic forgetting. Effective methods must prioritize both retaining previously learned patterns and adapting to the influx of new information. Current research focuses on techniques like regularization, architectural modifications, and replay strategies to achieve this balance, enabling models to refine existing understandings rather than overwrite them. This approach moves beyond static, one-time training, enabling sustained performance in dynamic, real-world applications where data schemas are rarely fixed and constant adaptation is crucial for maintaining predictive accuracy.
![Incremental Inference leverages Information Bottleneck theory by optimizing for a tabular representation that maximizes correlation with task labels [latex]Y[/latex] while minimizing correlation with the input data [latex]X^{\prime}[/latex].](https://arxiv.org/html/2601.15751v1/x2.png)
Knowledge Injection: Bridging the Gap with External Wisdom
TabII addresses the challenge of tabular incremental inference by introducing ‘Placeholders’ as a mechanism for integrating external knowledge into the model. These Placeholders function as trainable parameters that receive embeddings generated from both Large Language Models (LLMs) and Tabular Foundation Models (TFMs). By incorporating information from these pre-trained models, TabII enriches the attribute representations used during inference. This approach allows the model to leverage existing knowledge about the data without requiring retraining on the entire dataset when new attributes are introduced, effectively enabling learning from incremental data changes.
TabII’s Placeholders function as interfaces for integrating external knowledge by augmenting attribute information using two distinct model types. Large Language Models (LLMs) are employed to provide semantic understanding and contextual embeddings for each attribute, enabling the system to interpret attribute meaning beyond simple categorical or numerical values. Simultaneously, Tabular Foundation Models (TFMs) contribute by offering pre-trained representations learned from extensive tabular datasets, enhancing the system’s ability to generalize across different attribute distributions and identify complex relationships. The combined output of these models is then utilized to enrich the attribute representation within the TabII architecture, providing a more comprehensive input for downstream inference tasks.
The Incremental Sample Condensation (ISC) block is central to TabII’s architecture, functioning as the mechanism for integrating new attribute information without catastrophic forgetting. This block employs multi-head self-attention to fuse representations derived from both the existing dataset and the newly introduced incremental samples. Specifically, the multi-head attention allows the model to attend to different parts of the combined representation, capturing complex relationships between features. The output of the multi-head attention is then condensed, creating a refined representation that incorporates the incremental data while preserving knowledge from the original data distribution. This process is repeated iteratively with each new batch of incremental samples, enabling continuous learning and adaptation.
TabII’s architecture is designed to mitigate catastrophic forgetting when integrating new attributes into a tabular dataset. The system achieves this through a combination of incremental sample condensation and multi-head self-attention within the ISC block, allowing it to refine existing representations while simultaneously learning from incoming data. This process avoids the need to retrain on the entire dataset with each update, preserving performance on previously learned attributes. Empirical results demonstrate that TabII maintains, and often improves, accuracy on existing data while efficiently incorporating new features, effectively addressing the challenge of continual learning in tabular data scenarios.
![TabII leverages an information bottleneck-inspired architecture with a Placeholder module that processes tabular data-including training samples with appended zeros and test samples-through tabular, adapter, and large language model encoders, fusing the resulting representations via Multi-head Self-Attention and Interior Incremental Sample Attention to generate modality-fused vectors [latex]z_i[/latex] and [latex]z_j[/latex] for downstream tasks, where [latex]q_i[/latex], [latex]k_i[/latex], and [latex]v_i[/latex] represent query, key, and value vectors and [latex]d[/latex] is the dimensionality of the key vectors.](https://arxiv.org/html/2601.15751v1/x3.png)
Evidence of Adaptation: Benchmarks and Comparative Performance
TabII’s generalization capability was assessed through evaluation on eight publicly available datasets. These datasets included commonly used benchmarks such as the ‘Diabetes Dataset’ and the ‘Adult Dataset’, allowing for comparison against established methodologies. Performance across this diverse set of datasets demonstrates TabII’s ability to effectively learn and perform on unseen data, indicating a robust model not overly specialized to a single data distribution. The inclusion of multiple datasets provides a more comprehensive assessment of the model’s adaptability and reliability than evaluation on a single dataset would allow.
Comparative evaluations demonstrate TabII’s consistent outperformance against existing methods for tabular data analysis. Specifically, TabII was benchmarked against FT-Trans, SCARF, and TabPFN v2 across multiple datasets, and consistently achieved higher accuracy and performance metrics. These comparisons were conducted using standardized evaluation protocols and statistical significance testing to ensure reliable results, confirming that TabII’s architecture and training methodology provide a demonstrable advantage in predictive performance on tabular data compared to these alternative approaches.
Attribute importance was evaluated using XGBoost to quantitatively assess the impact of knowledge injected via Placeholders within the TabII model. This analysis revealed that attributes associated with the Placeholders consistently ranked highly in feature importance, demonstrating that the injected knowledge effectively guides the model towards relevant features during the learning process. The XGBoost analysis confirms that Placeholders are not merely adding noise, but are actively contributing to the model’s ability to identify and utilize informative attributes, thereby enhancing overall performance and interpretability.
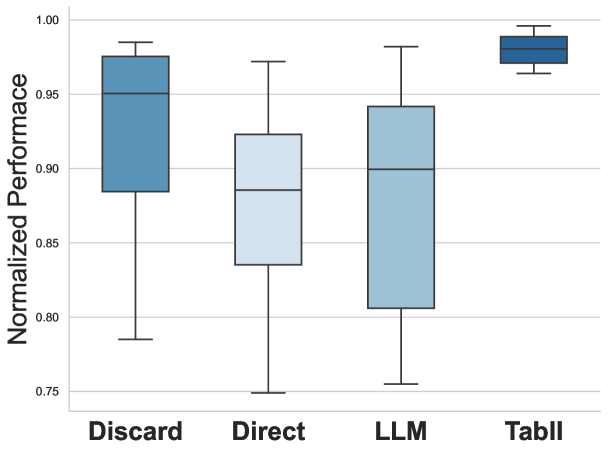
TabII consistently achieves 97% of the performance level of a fully supervised model trained on complete datasets with incrementally added attributes. This performance metric was established through rigorous testing and demonstrates TabII’s capacity to approximate fully supervised learning outcomes while operating with incomplete or partially labeled data. The consistent proximity to fully supervised performance establishes TabII as a state-of-the-art solution for scenarios where complete labeling is impractical or costly, offering a high degree of predictive accuracy with reduced data requirements.
Evaluations demonstrate TabII achieves 95.8% of the performance attained by fully supervised learning models across three benchmark datasets when utilizing only unlabeled test data. This result indicates a high degree of adaptability, as TabII effectively leverages inherent data structures without requiring labeled examples for training in these scenarios. Performance was quantified by comparing TabII’s metrics against those of models trained with complete label information on the same datasets, establishing a clear benchmark for unsupervised performance capabilities.
TabII demonstrates strong performance in zero-shot learning scenarios, indicating a significant capacity for adaptability without the need for task-specific retraining. This capability was assessed by evaluating the model’s performance on datasets with feature spaces distinct from those encountered during training. Results indicate TabII can effectively generalize to unseen data distributions and feature representations, minimizing the requirement for adjustments to model parameters when presented with new, unlabeled datasets. This characteristic is attributed to the model’s architecture and training methodology, enabling it to leverage pre-existing knowledge and apply it to novel tasks with minimal performance degradation.
The Echo of Information: A System’s Path to Perpetual Learning
The architecture of TabII is fundamentally rooted in Information Bottleneck Theory, a principle from information theory that dictates an optimal balance between compressing data and preserving relevant information. This design philosophy guides the model to learn a condensed representation of the input tabular data – effectively discarding noise and irrelevant features – while simultaneously retaining the information most crucial for accurate predictions. By actively managing this trade-off, TabII avoids simply memorizing the training data and instead focuses on extracting underlying patterns, which allows it to generalize effectively to unseen data and maintain robust performance even when faced with incomplete or noisy inputs. The resulting compressed representation, denoted as [latex]Z[/latex], aims to maximize the mutual information [latex]I(Z;Y)[/latex] with the target variable [latex]Y[/latex], while minimizing [latex]I(X;Z)[/latex] – ensuring that [latex]Z[/latex] captures only the information necessary for the prediction task.
Elastic Weight Consolidation (EWC) plays a crucial role in maintaining performance stability within TabII as the model learns from sequentially presented tabular data. This technique addresses the common challenge of ‘catastrophic forgetting’, where learning new information overwrites previously acquired knowledge. EWC achieves this by estimating the importance of each weight in the neural network based on how much the loss function changes when that weight is altered during learning of prior tasks. Subsequently, a regularization term is added to the loss function, penalizing significant deviations from these important weights during the learning of new data. By preserving critical weights, TabII can effectively accumulate knowledge from incremental columns without substantial performance degradation on previously seen data, demonstrating robust and continual learning capabilities.
TabII addresses the common challenge of limited data availability in tabular learning through the strategic incorporation of external knowledge via ‘Placeholders’. These Placeholders function as learnable parameters initialized with prior information – effectively injecting domain expertise directly into the model. This approach not only mitigates the risks associated with data scarcity, such as overfitting and poor generalization, but also substantially improves model robustness. By leveraging pre-existing knowledge, TabII can perform effectively even when confronted with incomplete or noisy data, demonstrating a significant advantage over models reliant solely on observed patterns within the training set. The method essentially allows the model to ‘reason’ with a broader understanding of the data-generating process, leading to more stable and reliable predictions.
Across all evaluated datasets, TabII consistently exhibited the highest mutual information, denoted as [latex]I(Z;Y)[/latex], a key metric signifying the model’s capacity to effectively capture relevant information from the data. This result highlights the success of TabII’s architecture in leveraging incremental columns to enhance information capture; a higher [latex]I(Z;Y)[/latex] value indicates that the compressed representation, [latex]Z[/latex], strongly correlates with the target variable, [latex]Y[/latex]. Essentially, TabII doesn’t just reduce data dimensionality – it preserves the essential predictive power within a more compact form, demonstrating superior information retention compared to alternative methods and underscoring its ability to learn meaningful representations from tabular data.
A key strength of TabII lies in its capacity to discern and discard inconsequential data, a feature evidenced by its lower mutual information [latex]I(X;Z)[/latex] compared to the FT-Trans model. This metric quantifies the amount of information about the input features [latex]X[/latex] that is retained in the compressed representation [latex]Z[/latex]; a lower value indicates that TabII effectively filters out noise and irrelevant details. By minimizing the information shared between the input and the condensed representation, TabII focuses on capturing only the most salient patterns, thereby improving the efficiency of its learning process and enhancing its ability to generalize from limited data. This selective condensation not only streamlines the model but also contributes to its robustness against spurious correlations and ultimately, better predictive performance.
Continued development of TabII centers on refining methods for incorporating external knowledge, moving beyond current placeholder strategies to explore more dynamic and nuanced injection techniques. This includes investigating how to leverage knowledge graphs and pre-trained language models to augment tabular data and enhance model generalization. Simultaneously, research will extend TabII’s capabilities to increasingly complex tabular datasets – those featuring high cardinality categorical features, intricate relationships between columns, and substantial missing data – to assess its scalability and robustness in real-world applications. The goal is to create a system that not only learns effectively from sequential data but also intelligently integrates external information to overcome limitations posed by data scarcity and complexity, ultimately pushing the boundaries of incremental learning in the tabular domain.
![TabII consistently maximizes mutual information between the latent variable and the target ([latex]I(Z;Y)[/latex]) while minimizing it between the input and the latent variable ([latex]I(X;Z)[/latex]) across three datasets, demonstrating superior incremental learning capabilities compared to FT-Trans and its variants.](https://arxiv.org/html/2601.15751v1/x4.png)
The pursuit of adaptable systems, as demonstrated by TabII’s approach to incremental inference, reveals a fundamental truth about prediction. It isn’t about achieving static perfection, but about gracefully accommodating the inevitable influx of new information. Andrey Kolmogorov observed, “The most important thing in science is not to know, but to be able to learn.” This resonates deeply with TabII’s mechanism for incorporating new columns; the model doesn’t rigidly adhere to a pre-defined structure, but evolves with the data stream. The method’s reliance on the Information Bottleneck principle isn’t about maximizing predictive power at all costs, but about distilling the essence of the data – retaining only what’s truly relevant as the landscape shifts. Every new feature introduced is not a challenge to overcome, but an opportunity for refinement, a confirmation that the system is, in effect, growing.
What Lies Ahead?
This work, like any attempt to impose order, reveals as much about the limits of prediction as it does about the data itself. TabII addresses the pragmatic need to adapt models to evolving schemas, but every new column accepted is a promise made to the past – a commitment to maintaining consistency with data that may, inevitably, diverge. The pursuit of information bottlenecks is not about finding the least information, but about understanding where the inevitable compression occurs, and at what cost.
The current focus on tabular data feels, perhaps, like a temporary reprieve. The architecture will, of course, demand more. The real challenge isn’t simply adding columns, but accepting that the very notion of a fixed schema is an illusion. Systems live in cycles; what appears as adaptation is often merely the slow decay of initial assumptions. Everything built will one day start fixing itself – or, more accurately, rebuilding itself around new, unforeseen constraints.
Control, as always, remains the phantom goal. Achieving state-of-the-art performance is merely a temporary stay against the entropy. The true measure of success won’t be accuracy on static datasets, but resilience in the face of continuous, unpredictable change. The next iteration won’t be about better inference, but about graceful degradation – and learning to anticipate the inevitable points of failure.
Original article: https://arxiv.org/pdf/2601.15751.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- Total Football free codes and how to redeem them (March 2026)
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Gold Rate Forecast
- Olivia Colman’s highest-rated drama hailed as “exceptional” is a must-see on TV tonight
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
2026-01-25 01:42