Author: Denis Avetisyan
New research reveals that large neural networks self-organize during training, opening the door to more efficient and scalable artificial intelligence.
![The system’s foundational principle centers on restructuring inference to achieve a cohesive and adaptable framework, where alterations to one component necessitate a comprehensive understanding of the interconnected whole to maintain systemic integrity and predictable behavior - a concept akin to biological organisms where structure fundamentally governs function [latex] S = f(I, R) [/latex], indicating structure (S) as a function of inference (I) and restructuring (R).](https://arxiv.org/html/2601.15871v1/G11.png)
Post-training restructuring leverages inherent structural sparsity to consolidate learned dependencies in large-scale models.
Despite increasing parameter counts, the computational cost of inference in large AI models remains a significant limitation, seemingly independent of achieved capacity. This paper, ‘Why Inference in Large Models Becomes Decomposable After Training’, reveals that training induces inherent structural organization within these models, leading to a surprising degree of post-training decomposability. By analyzing gradient update dynamics, we demonstrate that learned dependencies are non-uniform and often sparse, allowing for the identification and consolidation of stable substructures without altering model functionality. Could this observation unlock truly scalable and efficient inference systems by exploiting the latent structure already present in trained large models?
Unveiling the Hidden Order: Parameter Efficiency in Deep Learning
The remarkable capabilities of deep learning models are increasingly hampered by a fundamental challenge: parameter efficiency. While achieving state-of-the-art results across numerous domains, these models often require an enormous number of parameters – sometimes billions – to function effectively. This presents significant hurdles as models scale, demanding substantial computational resources for both training and inference. The sheer size of these networks increases energy consumption, limits deployment on edge devices, and creates a bottleneck for further progress. Researchers are actively exploring methods to reduce this parameter burden without sacrificing performance, recognizing that the current trajectory of simply increasing model size is unsustainable. The pursuit of parameter efficiency isn’t merely about optimization; it represents a critical step towards building more accessible, scalable, and environmentally responsible artificial intelligence.
Recent investigations into deep learning models reveal a phenomenon termed ‘effective sparsity’, challenging the assumption that all parameters contribute equally to a network’s learning capacity. Observations consistently demonstrate that a surprisingly small subset of weights often dominates predictive performance, suggesting an inherent redundancy within these complex systems. This isn’t simply random noise; rather, the selective activation of parameters points toward underlying structural principles governing how information is represented and processed. Researchers hypothesize that these principles, potentially rooted in the data’s intrinsic dimensionality or the task’s inherent complexity, allow models to achieve impressive results with far fewer active connections than initially anticipated. Understanding and harnessing this effective sparsity promises not only more efficient models – reducing computational cost and memory requirements – but also a deeper insight into the fundamental mechanisms of learning itself, potentially paving the way for architectures that more closely mimic the elegance and efficiency of biological neural networks.
The prevailing gradient update mechanism in deep learning, while demonstrably successful in training complex models, often operates with a degree of inefficiency. Instead of concentrating adjustments on the most salient parameters – those genuinely driving learning – the process tends to distribute changes broadly across the network. This diffuse updating stems from the mechanism’s reliance on averaging gradients across all parameters, obscuring the underlying structural redundancies within the model. Consequently, valuable opportunities to refine the network’s inherent organization are missed, leading to models that require significantly more parameters than theoretically necessary to achieve comparable performance. Research suggests that focusing updates on a structurally informed subset of parameters could dramatically improve parameter efficiency and unlock a more elegant and interpretable representation of learned knowledge.
The Logic of Local Interactions: Co-occurrence and Network Refinement
The co-occurrence relation defines the probability of two neuronal states being active at the same time during processing. This relation is foundational for identifying locally meaningful interactions because it directly reflects which connections are consistently engaged when the system processes specific inputs or performs certain tasks. By quantifying how frequently states activate together, the co-occurrence relation provides a statistical measure of their interdependence, allowing for the isolation of relevant connections from the broader network. This localized perspective is crucial, as it avoids global updates and instead focuses refinement on connections demonstrably involved in concurrent activity, effectively capturing the structure of learned representations.
Local gradient updates operate by limiting parameter adjustments to only those components that exhibit concurrent activation, as defined by the co-occurrence relation. This contrasts with traditional gradient descent which modifies all parameters based on global error signals. By identifying actively participating units – those that fire together during a specific task or input – the learning process focuses on strengthening or weakening the connections between them. The magnitude of the parameter change is then calculated based on the error signal and the activation level of these co-occurring components. This localized approach reduces computational cost and, critically, promotes the development of sparse and efficient neural networks by prioritizing refinement of only the most relevant connections.
The principle of learning through strengthened task-relevant interactions posits that neural network adaptation is not a global process, but rather a localized refinement of connections activated during specific tasks. This means that only those connections involved in processing current input and generating output are subject to modification via gradient descent. By restricting weight updates to these active components, the network prioritizes reinforcing pathways directly engaged in successful task completion. This contrasts with methods that modify all weights regardless of activity, potentially disrupting established, irrelevant connections and leading to slower or less stable learning. The strength of a connection is thus directly proportional to its frequency of use during task performance, effectively implementing a form of synaptic plasticity driven by co-occurrence statistics.
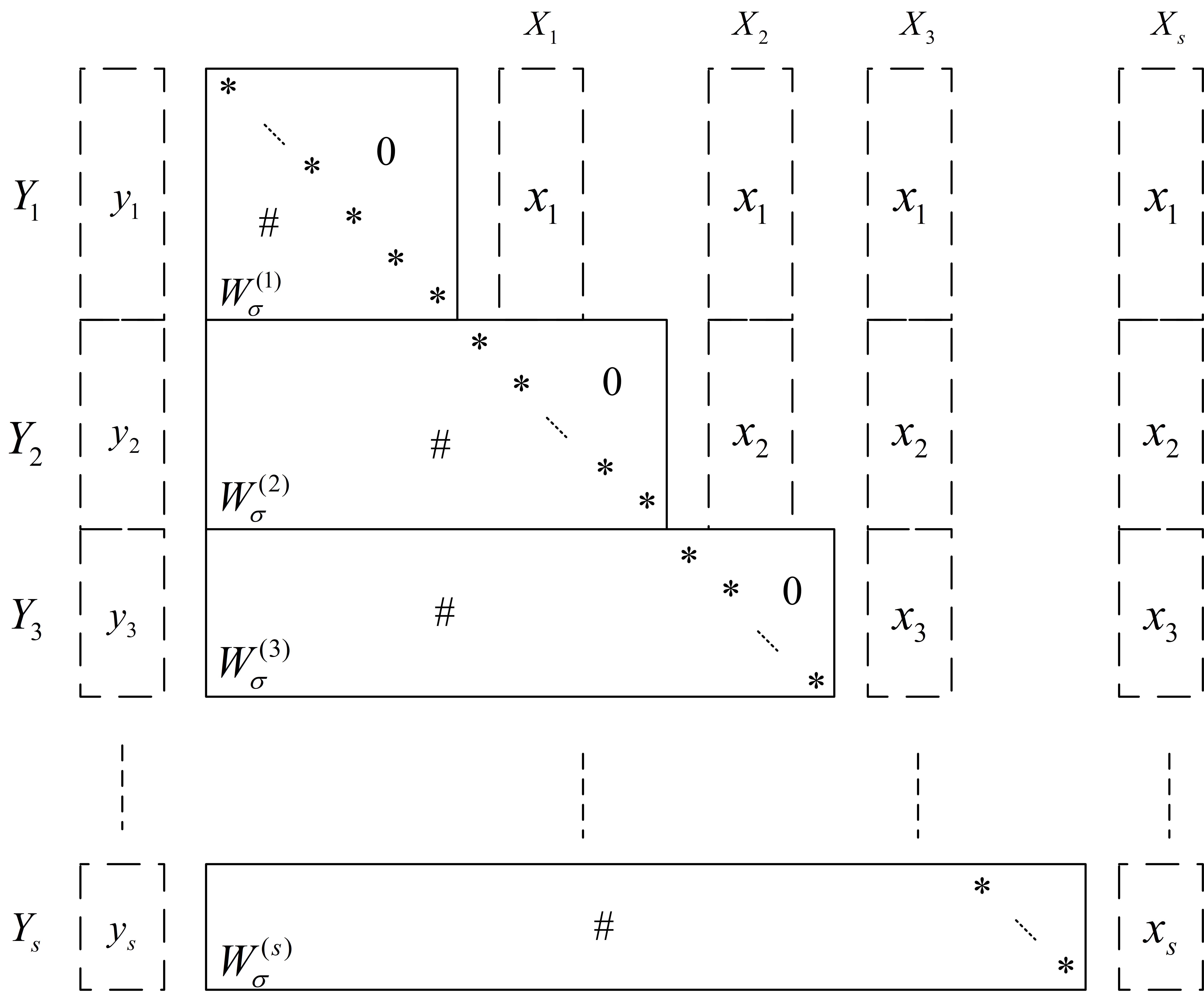
Revealing Modular Structure: Consolidation and the Co-occurrence Coupling Relation
The Co-occurrence Coupling Relation is a method for identifying functional modules within a system by analyzing the relationships between states. It is derived from the co-occurrence relation, which quantifies how frequently pairs of states appear together during system operation. This relation is then processed using principles of Equivalence Relation theory – specifically, determining which state pairs exhibit statistically significant co-occurrence patterns. States demonstrating strong and consistent co-occurrence are grouped together, forming clusters that are hypothesized to represent distinct functional modules responsible for specific system behaviors. The resulting groupings provide insights into the system’s internal organization and potential areas of functional independence.
Block-diagonal structure in parameter matrices arises when significant couplings exist within localized groups of states, while couplings between these groups are minimal. This manifests as non-zero values concentrated along the diagonal blocks of the matrix, and near-zero values in the off-diagonal blocks. Mathematically, if [latex] \mathbf{W} [/latex] represents the parameter matrix, a block-diagonal form implies it can be expressed as [latex] \mathbf{W} = \begin{bmatrix} \mathbf{A} & \mathbf{0} \\ \mathbf{0} & \mathbf{B} \end{bmatrix} [/latex], where [latex] \mathbf{A} [/latex] and [latex] \mathbf{B} [/latex] are sub-matrices representing internal connections within distinct sub-systems, and the zero matrices indicate limited interaction between them. The presence of this structure suggests the system can be decomposed into relatively independent functional units, simplifying analysis and potentially improving computational efficiency.
Structural Consolidation is a Post-Training Static Analysis technique employed to reinforce identified dependencies within a model’s parameter matrices. This process involves analyzing the trained weights to locate and stabilize the block-diagonal structure revealed by techniques like Co-occurrence Coupling Relation analysis. By explicitly strengthening the relationships within these functional modules, Structural Consolidation reduces interference between sub-systems and improves the overall robustness of the model to perturbations. The technique doesn’t alter the trained weights themselves, but rather establishes constraints that preserve the modular structure during subsequent operations or fine-tuning, leading to increased stability and predictability of the model’s behavior.
Distilling Significance: Statistical Annealing and Effective Network Structure
Statistical Annealing is a post-training procedure used to determine which parameters within a neural network exhibit statistically significant influence on the network’s output. This method operates under the premise of the Random-Walk Noise Hypothesis, which posits that many parameters are effectively random and contribute only noise. By iteratively perturbing parameters and observing the resulting changes in performance, Statistical Annealing identifies groupings of parameters whose collective behavior deviates significantly from random chance. This allows for the differentiation of meaningful parameters – those crucial to the network’s function – from those that can be considered redundant or noisy, forming the basis for subsequent network compression and improved generalization capabilities.
The Neyman Significance Test is implemented to assess the statistical robustness of identified parameter dependencies within a neural network following the application of Statistical Annealing. This test determines whether observed relationships between parameters are likely due to genuine dependencies or random noise. A significance level of p < 0.01 is used as a threshold; parameters exhibiting a p-value less than 0.01 are considered statistically significant, indicating a low probability that the observed connection occurred by chance. Consequently, these parameters are retained as representative of robust network structure, while those exceeding the threshold are considered noise and are pruned, facilitating network compression and improved generalization.
Parameter selection based on statistical significance, as determined by the Neyman Significance Test with a threshold of p < 0.01, facilitates network compression by identifying and retaining only those parameters demonstrably contributing to the model’s performance. This focused approach reduces the number of trainable parameters without compromising accuracy, as irrelevant or noisy parameters are effectively discarded. Consequently, models with fewer parameters exhibit improved generalization performance on unseen data due to a reduced risk of overfitting, leading to more efficient and robust predictive capabilities.
Towards Scalable Intelligence: The Promise of Structural Awareness
Recent advances in deep learning suggest that the computational demands of large-scale foundation models may be substantially reduced without sacrificing performance. Investigations reveal these systems do not necessarily require the traditional approach of fully dense parameter matrices-where every neuron connects to every other in the subsequent layer. Instead, these models can effectively operate through a modular execution style, guided by an underlying, discoverable structure within the parameters themselves. This means computation can be focused on relevant modules, drastically cutting down on unnecessary calculations and memory access. The implications are significant; it demonstrates that intelligent design isn’t solely reliant on brute-force scaling, and opens pathways to creating powerful AI systems with increased efficiency and reduced hardware requirements.
The discovery of block-diagonal structure within large neural networks presents significant opportunities for optimizing existing pruning and compression techniques. Traditionally, these methods treat network parameters uniformly, indiscriminately removing or reducing the precision of weights across the entire model. However, recognizing inherent block-diagonal patterns allows for a more targeted approach; parameters within identified blocks can be preserved for crucial computations, while those connecting disparate blocks – often representing redundant or less impactful connections – become prime candidates for pruning or quantization. This selective refinement promises substantial reductions in computational cost and memory footprint, as operations can be focused on the essential, structurally significant portions of the network, ultimately leading to more efficient and scalable deep learning models without significant performance degradation.
Deep learning models are increasingly moving beyond simply scaling up parameters; a shift towards acknowledging and leveraging inherent structural organization is proving critical for advancements in efficiency, robustness, and interpretability. Recent research indicates that analyzing parameter sequences – particularly those of length 8 – reveals underlying block-diagonal structures within these networks. This intrinsic organization suggests that fully dense parameter matrices aren’t necessarily required for high performance; modular execution guided by these discovered structures offers a computationally lighter path. By embracing this inherent organization, models can become more resilient to noise and adversarial attacks, while simultaneously providing opportunities for greater insight into the learned representations – ultimately leading to deep learning systems that are not only powerful but also understandable and resource-conscious.
The pursuit of efficient large-scale AI systems, as detailed in the study, reveals an inherent tendency towards organization. Trained networks aren’t chaotic; they develop discernible structure, allowing for targeted post-training restructuring. This echoes Claude Shannon’s observation: “The most important thing in communication is to convey the message, not to transmit it.” Similarly, the goal isn’t simply to scale models, but to efficiently represent learned dependencies. The paper’s focus on identifying and consolidating these dependencies-through techniques like edge-wise annealing-demonstrates a commitment to conveying the essential ‘message’ of the data with minimal redundancy, mirroring Shannon’s principle of effective communication and highlighting the power of structural sparsity.
What Lies Ahead?
The observation that large networks develop internal structure during training is less a surprise than a necessary correction. For too long, the field operated under the assumption that scale alone would yield emergent capabilities, dismissing organization as a secondary concern. This work suggests a different path: that the way a network scales-its inherent architecture-is as important as the scale itself. The challenge now isn’t simply building larger models, but understanding how to cultivate and exploit this naturally occurring structure. If a design feels clever, it’s probably fragile.
A critical limitation remains the reliance on post-hoc restructuring. While effective, this approach feels inherently reactive. Future work must address the question of inducing this desirable organization during training. Can architectural constraints, informed by the dynamics of gradient updates and co-occurrence relations, guide the network toward more efficient and decomposable solutions from the outset? A truly elegant system anticipates its own simplification.
Ultimately, this line of inquiry points toward a deeper understanding of generalization itself. Decomposability isn’t merely an optimization trick; it’s a reflection of how the network represents and reasons about the world. A model that can cleanly separate concerns-that embodies structure-is more likely to be robust, interpretable, and capable of true intelligence. The goal isn’t simply to mimic behavior, but to replicate the underlying principles of efficient design.
Original article: https://arxiv.org/pdf/2601.15871.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-24 09:13