Author: Denis Avetisyan
Researchers have developed a new framework that allows four-legged robots to navigate challenging environments by intelligently perceiving their surroundings and planning stable footholds.
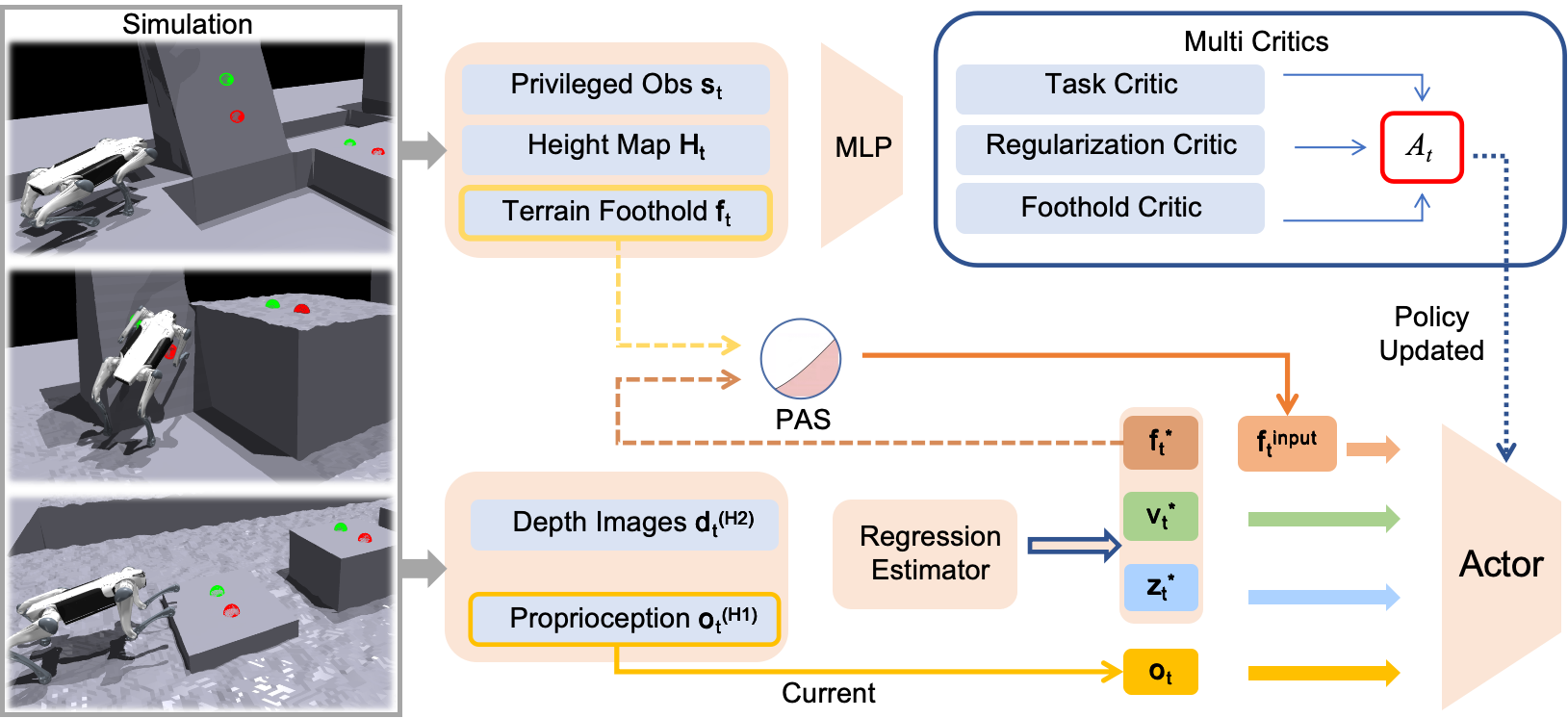
PUMA leverages perception-driven, egocentric foothold priors to improve mobility and sim-to-real transfer for quadruped robots performing parkour-like maneuvers.
While quadruped robots show promise for agile locomotion, replicating the perceptual reasoning of human athletes when navigating complex terrains remains a significant hurdle. This paper introduces ‘PUMA: Perception-driven Unified Foothold Prior for Mobility Augmented Quadruped Parkour’, a novel end-to-end learning framework that integrates visual perception with egocentric foothold priors to guide robot motion. By learning to estimate these priors from terrain features, PUMA enables robust and adaptable parkour performance in both simulation and real-world environments. Could this approach unlock truly autonomous navigation for legged robots across previously inaccessible landscapes?
The Fragility of Static Systems: Beyond Pre-Programmed Locomotion
Conventional quadruped robots often stumble when faced with the unpredictable challenges of real-world environments. Unlike their biological counterparts – animals capable of fluid parkour movements – these machines typically rely on pre-programmed gaits and meticulously mapped terrain. This approach proves brittle when confronted with uneven ground, unexpected obstacles, or dynamic changes in the landscape. The rigidity stems from a dependence on precise motor control and a limited ability to perceive and react to the environment in real-time; a simple gap or displaced rock can disrupt the entire sequence. This limitation highlights a significant gap between robotic locomotion and the remarkable adaptability demonstrated by creatures navigating complex, unstructured terrains with apparent ease, demanding a paradigm shift in how robots perceive, plan, and execute movement.
Conventional robotic locomotion often relies on meticulously planned trajectories, proving brittle when confronted with the unpredictable nature of real-world environments. To achieve genuinely dynamic and robust movement, robots must transition from executing pre-programmed sequences to actively perceiving their surroundings in real-time. This necessitates an ability to process sensory input – visual, tactile, and inertial – and instantaneously adjust movement parameters. Instead of simply following a pre-determined path, the robot dynamically generates and modifies its gait, selecting foot placements and body configurations based on the immediate environment. This shift towards reactive control enables navigation across uneven terrain, obstacle negotiation, and adaptation to unforeseen challenges, mirroring the agility observed in natural parkour practitioners and ultimately unlocking more versatile robotic capabilities.
To navigate the unpredictable challenges of complex terrains, robotic systems require a cohesive framework where environmental perception directly informs and adjusts motor control. This integrated approach moves beyond sequential processing – where a robot first sees an obstacle and then calculates a response – toward a unified system capable of instantaneous adaptation. Such a framework allows the robot to not merely react to unforeseen obstacles, but to proactively modify its trajectory and foot placement in real-time, based on continuous sensory input. By fusing perception and control, researchers aim to create robots that exhibit the fluid, adaptable movement seen in natural parkour, effectively allowing them to ‘read’ the environment and dynamically adjust their locomotion strategy for robust and efficient navigation.
Robotic foot placement, as currently implemented, frequently struggles when confronted with environments differing even slightly from those used during training; a robot expertly navigating a simulated obstacle course may falter on a real-world surface with minor variations in texture or unexpected debris. This limitation stems from a reliance on pre-programmed responses or reactive control loops that lack the foresight to anticipate and adapt to novel situations. Researchers are therefore shifting focus toward proactive footstep planning, incorporating predictive models of terrain stability and robot dynamics to enable robots to intelligently select and adjust foot placements before contact. This demands a more sophisticated understanding of the interplay between perception, prediction, and control, moving beyond simple obstacle avoidance toward a system capable of reasoned decision-making regarding optimal foot placement for robust and efficient traversal of complex, unstructured landscapes.

PUMA: A Framework for Unified Perception and Control
PUMA employs an egocentric polar coordinate system to define potential footholds for locomotion planning. This representation defines each landing site relative to the robot’s current position and orientation, simplifying the search space for stable and reachable locations. The polar coordinates consist of a radial distance and an angle, enabling efficient discretization of the surrounding terrain and rapid evaluation of prospective steps. By framing footholds in this robot-centric manner, PUMA reduces computational complexity and facilitates real-time adaptation to dynamic environments, as the system only needs to consider locations reachable within a defined radius and angular range.
The PUMA framework employs a hierarchical architecture to decouple perception and control functions, enhancing robustness and adaptability in challenging terrains. This separation allows the perception module to independently process sensor data – such as depth images from the Intel RealSense D435i – and generate a real-time environmental understanding without being directly constrained by control requirements. Conversely, the control module receives high-level representations of the environment from the perception layer, enabling it to plan and execute locomotion strategies optimized for stability and efficiency. This modularity facilitates independent development and refinement of each component, and allows the system to readily adapt to changes in the environment or robot configuration, ultimately improving performance compared to tightly coupled approaches.
PUMA utilizes data from depth sensors, specifically the Intel RealSense D435i, to construct a dynamic representation of the surrounding terrain. The D435i provides real-time depth images which are processed to identify walkable surfaces and potential obstacles. This perception pipeline generates a cost map representing terrain traversability, factoring in slope, roughness, and obstacle proximity. The resulting terrain understanding is continuously updated, enabling the robot to adapt its gait and path planning to navigate challenging and unstructured environments. This real-time perception capability is critical for robust locomotion, allowing PUMA to react to unforeseen changes in the terrain and maintain stability.
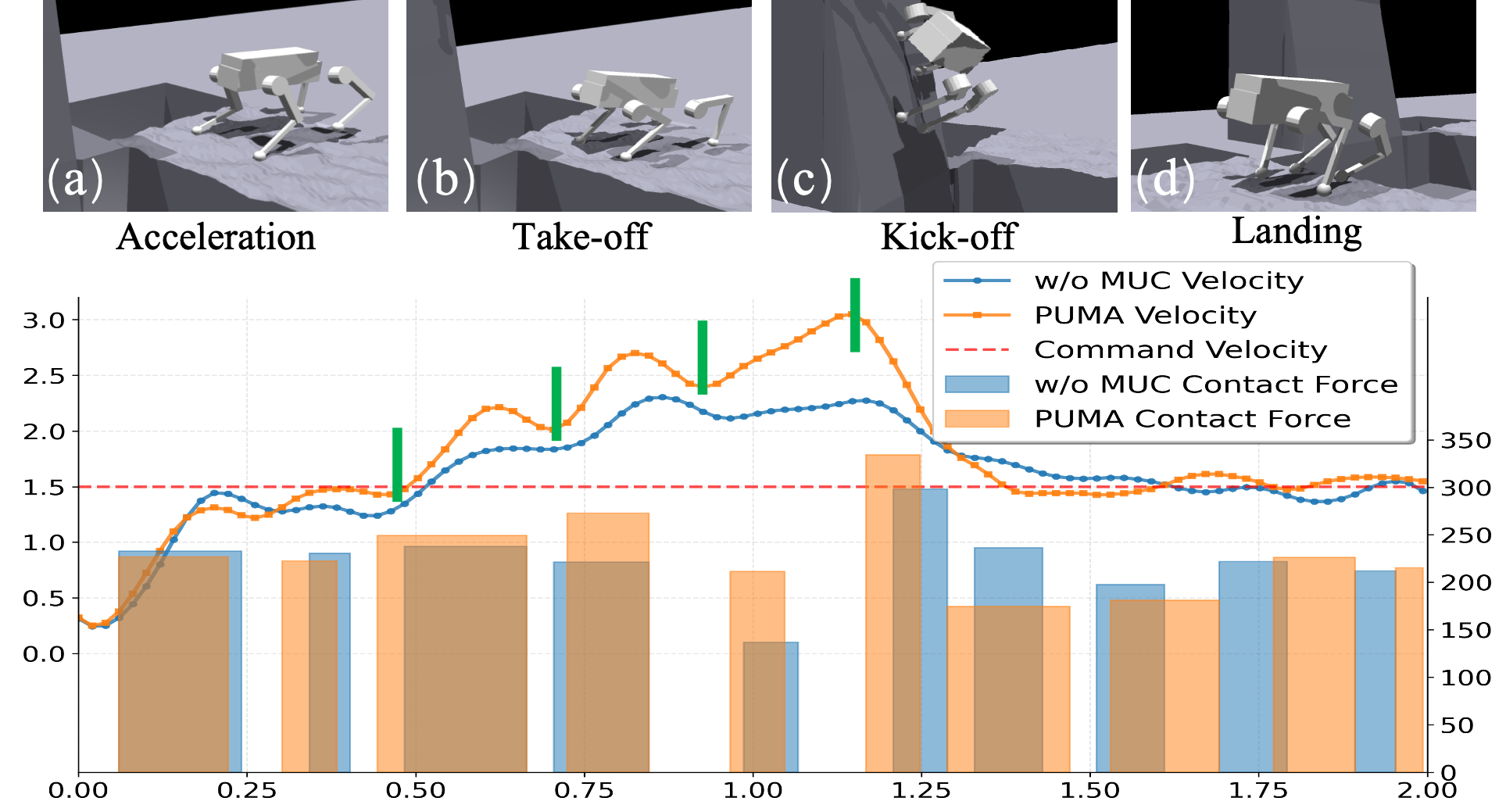
The PUMA framework employs velocity tracking to maintain desired speeds during locomotion, coupled with reinforcement learning algorithms to adapt gait parameters for improved stability and efficiency. This optimization process allows the robot to learn optimal foot placement and body posture based on real-time terrain feedback. Comparative testing demonstrates a statistically significant improvement in locomotion success rates across diverse terrains – including rocky, uneven, and sloped surfaces – when compared to traditional control methods and baseline gait implementations. The reinforcement learning component iteratively refines the control policy, maximizing forward progress and minimizing instances of falls or recovery failures.
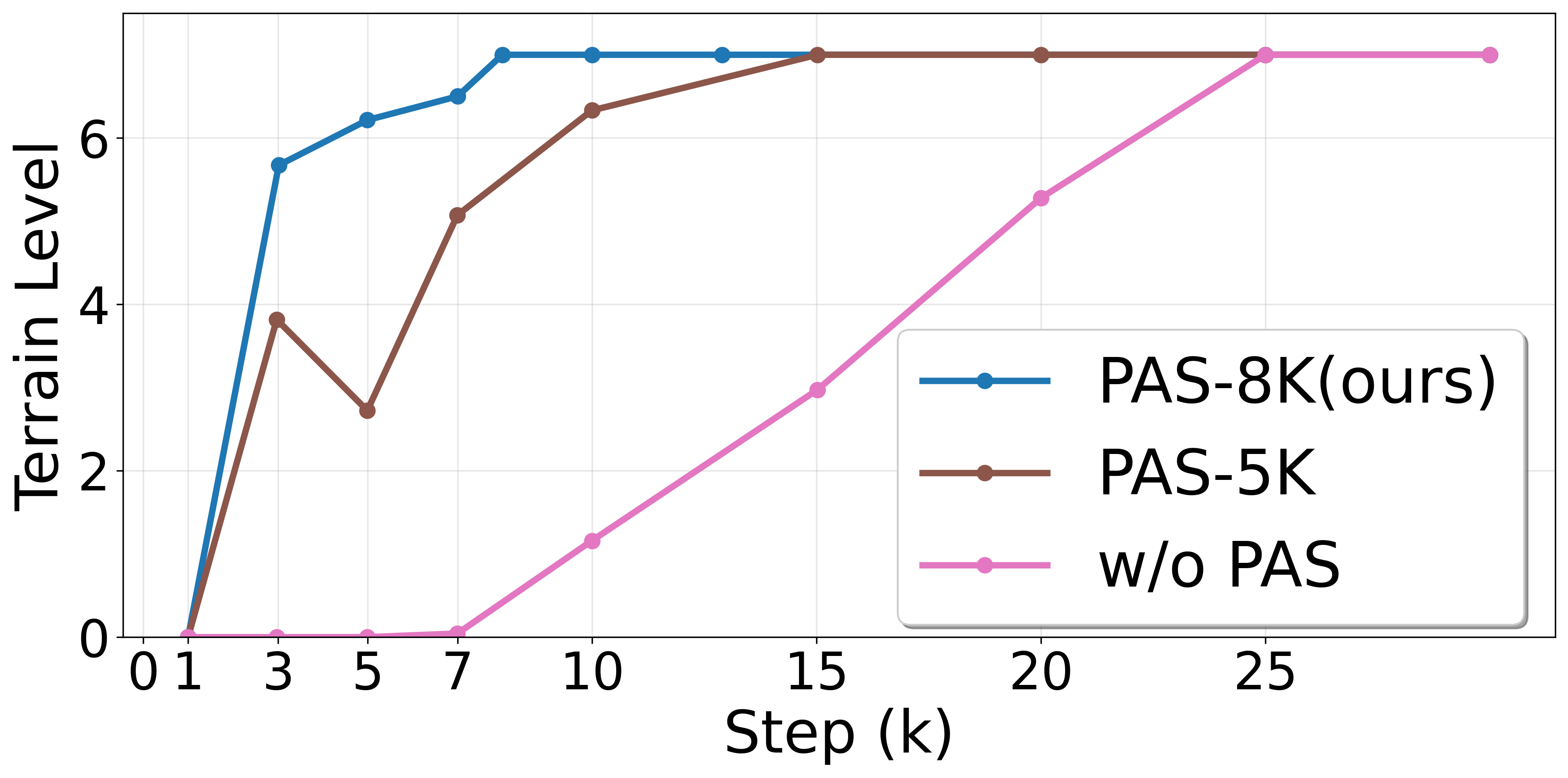
From Simulation to Reality: Bridging the Gap with Asymmetric Learning
The robot’s policy is trained using an asymmetric actor-critic architecture, wherein a single actor network learns the optimal policy and multiple critic networks evaluate the actions taken by the actor. This multi-critic approach enhances learning stability and performance by reducing the variance in the estimated value function. The asymmetry refers to the actor and critic networks having differing structures and roles; the actor proposes actions, while the critics assess their quality based on the current state. This configuration allows for more robust and efficient policy optimization within the simulation environment, facilitating the robot’s ability to learn complex behaviors.
Domain randomization leverages the capabilities of the Isaac Gym simulation environment to enhance the transfer of learned policies to real-world robotic systems. This technique involves systematically varying simulation parameters – including, but not limited to, friction coefficients, mass distributions, and visual textures – during training. By exposing the learning agent to a wide range of randomized environments, the resulting policy becomes more robust to discrepancies between the simulation and the real world, effectively minimizing the sim-to-real gap. This approach reduces the need for precise system identification and allows for the deployment of policies trained solely in simulation onto physical robots with improved generalization performance.
The robot’s initial policy development is accelerated through the incorporation of reference trajectories and imitation learning techniques. Pre-defined, successful trajectories provide a supervisory signal, enabling the agent to learn from demonstrated behavior and rapidly acquire a functional baseline policy. This approach circumvents the challenges associated with sparse reward functions often encountered in reinforcement learning, particularly in complex robotic manipulation tasks. By mimicking expert demonstrations, the agent quickly establishes a viable starting point, which is then refined through subsequent reinforcement learning iterations, resulting in improved sample efficiency and faster convergence to an optimal policy.
Validation of the PUMA framework was performed using the DeepRobotics Lite3 robot, assessing its performance in complex obstacle navigation. Testing demonstrated the robot’s capacity for agile and precise movement during these trials. Quantitative analysis revealed a statistically significant reduction in Mean Square Error (MSE) for foothold regression when compared to both explicit and implicit Cartesian prior methodologies. This improvement in foothold prediction directly correlates to increased stability and accuracy during locomotion and obstacle negotiation.
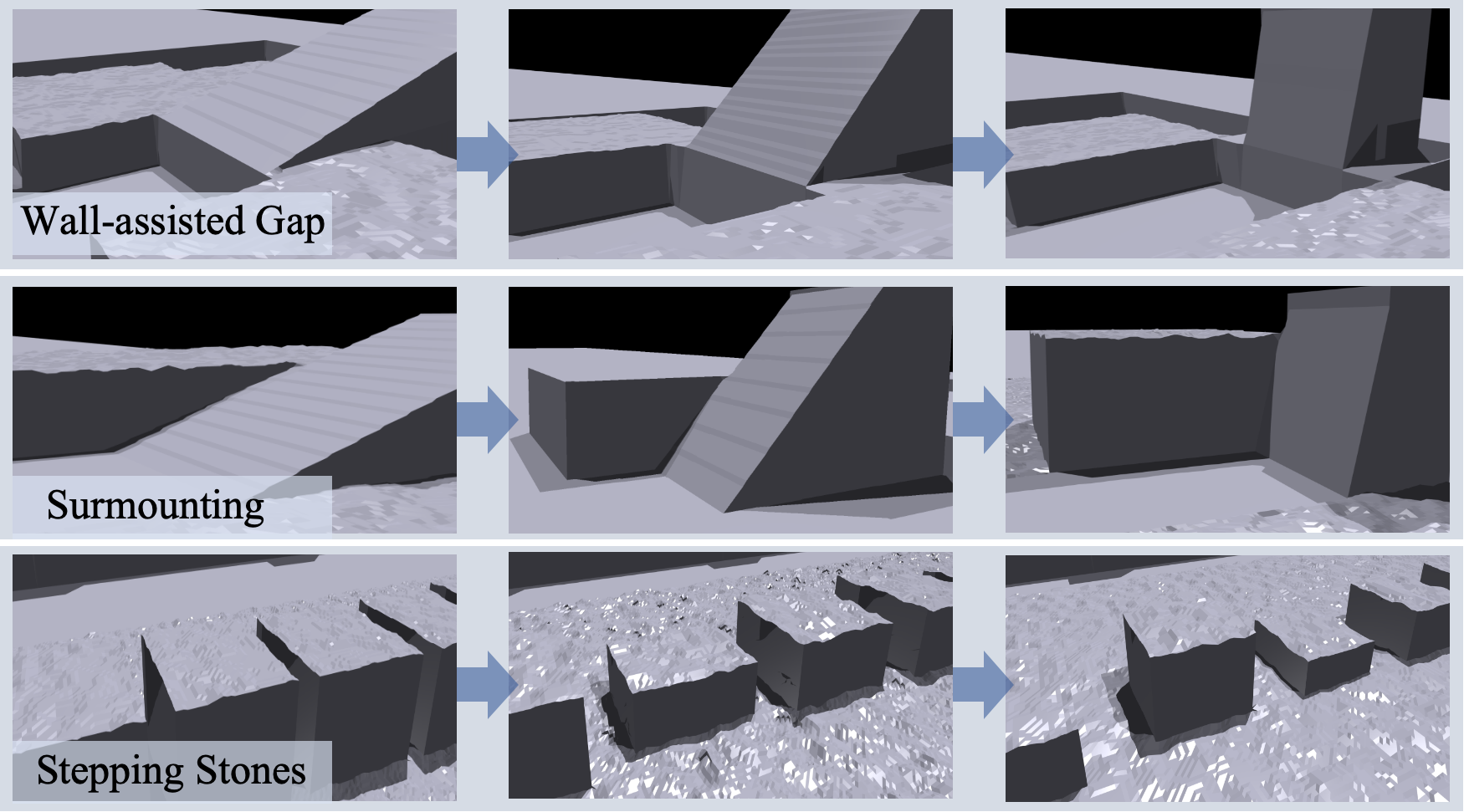
Beyond Navigation: The Implications of Adaptive Robotics
The convergence of perception and control within the PUMA framework unlocks significant advancements for robots operating in critical scenarios. By seamlessly interpreting sensor data and dynamically adjusting movements, robots can now navigate complex, unstructured environments such as those encountered during search and rescue operations, or within the aftermath of a disaster. This integrated approach is particularly valuable for exploration, allowing robots to independently assess stability, identify potential hazards, and chart efficient paths through previously inaccessible terrain. The ability to react in real-time to unforeseen obstacles and changing conditions not only enhances operational efficiency but also minimizes the need for constant human intervention, enabling robots to perform tasks in environments too dangerous or remote for human access.
The PUMA framework distinguishes itself through a deliberate design prioritizing adaptability and robustness, crucial attributes for operation in unpredictable environments. Unlike systems reliant on precise pre-programmed maps or idealized conditions, PUMA incorporates mechanisms for real-time environmental assessment and dynamic adjustment of locomotion strategies. This allows the robot to maintain stability and progress even when confronted with unexpected obstacles, shifting terrain, or incomplete sensory data. The system’s ability to rapidly re-plan and execute movements based on current observations, rather than solely on pre-existing models, is particularly valuable in scenarios like disaster response or extraterrestrial exploration, where conditions are inherently uncertain and constantly evolving. This inherent resilience not only enhances operational success but also reduces the risk of failure or damage in challenging and dynamic surroundings.
The development of PUMA signifies a crucial step toward robots that interact with humans in a more seamless and understandable manner. Traditionally, robots have operated with a distinct separation between seeing the world – perception – and deciding what to do – motion planning. PUMA collapses this division, allowing the robot to dynamically adjust its plans based on immediate sensory input, much like a human does. This unification enables more responsive and predictable behavior, fostering trust and ease of collaboration. Instead of requiring precise pre-programming for every scenario, PUMA’s framework allows a robot to interpret ambiguous cues, adapt to unexpected changes, and ultimately, engage with people in a way that feels less mechanical and more intuitive – envisioning robots that can assist in homes, hospitals, or even complex assembly lines with a level of finesse previously unattainable.
The foundational principles underpinning PUMA’s success aren’t limited to a single robotic design; they represent a broadly applicable framework for achieving robust and adaptable locomotion. Researchers anticipate these concepts will translate effectively to diverse robotic platforms, including legged machines, aerial vehicles, and even underwater robots, fostering innovation across the field. Crucially, the integration of the Probability Annealing Selection (PAS) method accelerates the learning process, allowing robots to quickly adapt to new terrains and challenges. This faster convergence is particularly valuable in dynamic and unpredictable environments, promising significant advancements in robotic agility and resilience – enabling more effective deployment in complex real-world scenarios and accelerating the development of truly autonomous systems.
The pursuit of robust quadrupedal locomotion, as demonstrated by PUMA, echoes a fundamental truth about complex systems. Just as structures inevitably succumb to the effects of time, robotic systems operating in unpredictable environments must adapt and refine their approach to maintain stability. Vinton Cerf observed, “Any sufficiently advanced technology is indistinguishable from magic.” PUMA’s ability to learn from terrain perception and utilize egocentric foothold priors – essentially anticipating and responding to the environment – feels akin to imbuing the robot with an intuitive understanding. The framework doesn’t attempt to eliminate the challenges of complex terrain, but rather to gracefully navigate them, learning to age gracefully within the dynamic medium of its operational environment.
What Lies Ahead?
The framework detailed within offers a temporary reprieve from the inevitable challenges of robotic locomotion, a bolstering of stability before the eventual entropic slide. PUMA, in its focus on perception-driven priors, does not so much solve the problem of complex terrain traversal as it defers it. The robot learns to anticipate, to select from a limited set of possibilities, but the universe offers an infinite capacity for the unexpected. Each successful negotiation of an obstacle is simply a postponement of encountering one for which no prior exists.
Future work will undoubtedly center on expanding the scope of “perception.” However, increasing sensory fidelity merely shifts the problem; a more detailed map of the present does not grant foresight into the future. The true limitation lies not in seeing the world, but in accurately modeling its inherent instability. A focus on robust adaptation – on graceful failure – may prove more fruitful than striving for perfect prediction.
Ultimately, the pursuit of robotic parkour, like all engineering endeavors, is a localized battle against the second law. PUMA represents a tactical victory, a momentary slowing of decay. The question is not whether the system will ultimately fail – it will – but how elegantly it does so. And how long the delay before that inevitable outcome.
Original article: https://arxiv.org/pdf/2601.15995.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-24 07:14