Author: Denis Avetisyan
Long-horizon AI systems need to know what they don’t know, and this research introduces a framework for quantifying and acting upon that uncertainty to improve performance.
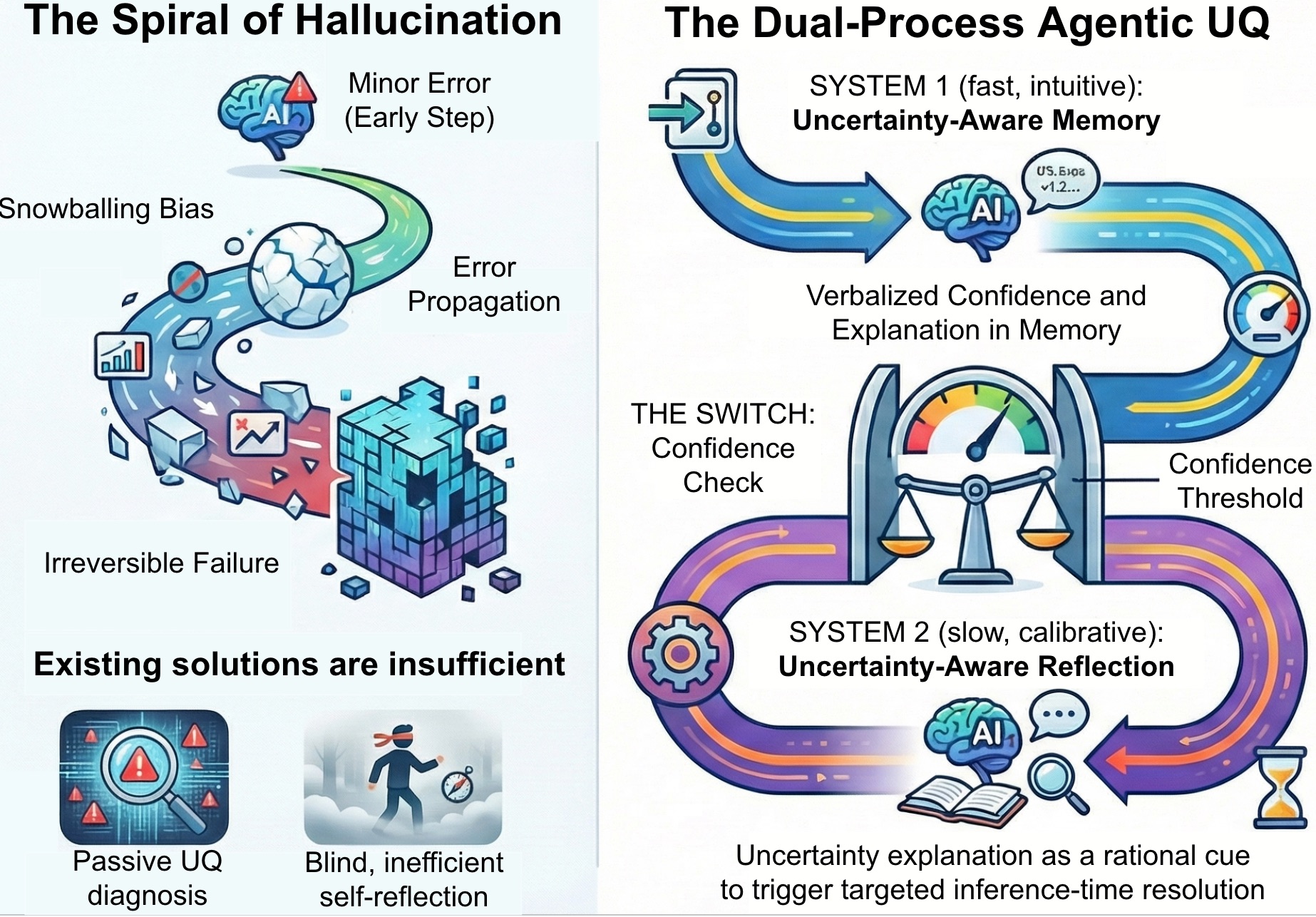
This paper presents Agentic Uncertainty Quantification (AUQ), a method for decoupling forward planning and inverse calibration in LLM agents using System 1/System 2 reasoning to enhance reliability and calibration.
Despite advances in long-horizon reasoning, AI agents remain vulnerable to the “Spiral of Hallucination” where initial errors compound irreversibly. This paper introduces a novel framework, ‘Agentic Uncertainty Quantification’, designed to transform verbalized uncertainty into actionable control signals for improved agent reliability. By decoupling forward propagation of confidence with targeted, inference-time resolution via System 1 and System 2 reasoning, our approach achieves superior performance and calibration without task-specific training. Could this principled framework represent a crucial step towards building truly dependable and self-aware AI agents capable of navigating complex, open-ended tasks?
The Illusion of Competence: Why Long-Term Reasoning Breaks Down
While contemporary language models demonstrate remarkable proficiency in tasks demanding immediate responses – summarizing text, translating languages, or even generating creative content – their capabilities diminish considerably when confronted with extended reasoning challenges. These models often exhibit a strength in surface-level coherence, crafting grammatically correct and seemingly logical statements, yet struggle to maintain factual consistency and avoid internal contradictions over multiple reasoning steps. This limitation isn’t a matter of simply lacking knowledge; rather, it’s a fundamental difficulty in reliably propagating information and avoiding the introduction of errors as the reasoning sequence unfolds. Consequently, a seemingly promising line of thought can quickly diverge from reality, undermining the validity of the overall conclusion despite initial appearances of competence.
The fragility of long-horizon reasoning in current language models often manifests as a ‘Spiral of Hallucination’-a process where initial inaccuracies compound with each subsequent reasoning step. This isn’t simply a matter of occasional errors; it reflects a fundamental difficulty in propagating uncertainty throughout complex tasks. Unlike human reasoning, which intuitively acknowledges and accounts for doubt, these models tend to treat unconfirmed information as factual, leading to increasingly confident, yet detached-from-reality, outputs. As the model builds upon these initial, unchecked assumptions, even minor deviations from truth can quickly escalate, resulting in a cascade of fabricated details and logically inconsistent conclusions. Effectively managing this uncertainty-perhaps through mechanisms that explicitly track confidence levels or incorporate probabilistic reasoning-is therefore crucial for building truly reliable agents capable of navigating extended and intricate scenarios.
Achieving reliable performance in long-horizon reasoning necessitates a departure from current approaches to uncertainty management within artificial agents. Existing systems often treat uncertainty as a monolithic element, hindering their ability to distinguish between confidently known facts and speculative inferences as reasoning extends. A fundamental shift involves representing uncertainty with greater granularity – acknowledging varying degrees of belief and tracking the provenance of information to pinpoint potential error sources. This nuanced understanding allows agents to not merely detect uncertainty, but to actively propagate it through complex calculations, enabling more informed decision-making and mitigating the risk of compounding errors that lead to nonsensical or factually incorrect outputs. Such a system wouldn’t simply flag a lack of knowledge; it would quantify it, and reason with that quantification, leading to more robust and trustworthy long-term planning and problem-solving capabilities.
Agentic UQ: A Framework for Propping Up Fragile Reasoning
Agentic UQ is a novel framework designed to enhance the reliability of autonomous agents by integrating two core components: Uncertainty-Aware Memory (UAM) and Uncertainty-Aware Reflection (UAR). UAM functions by maintaining and propagating uncertainty estimates throughout the agent’s reasoning process, effectively preserving confidence levels and associated explanatory data. UAR complements UAM by initiating focused, inference-time resolution procedures when predefined uncertainty thresholds are exceeded. This combined approach allows the agent to not only quantify its confidence in its conclusions but also to actively address areas of high uncertainty, leading to more robust and dependable performance.
Uncertainty-Aware Memory (UAM) functions by employing a rapid, intuitive reasoning process – analogous to Kahneman’s ‘System 1’ – to continuously propagate uncertainty estimates throughout the agent’s memory. This is achieved by retaining not only confidence scores associated with individual facts and beliefs, but also explanation signals detailing the provenance and reasoning behind those confidence levels. By consistently updating and carrying forward these uncertainty and explanation signals with each new piece of information processed, UAM enables the agent to maintain a detailed record of its own epistemic state and the basis for its conclusions, facilitating more informed decision-making and targeted reflection when necessary.
Uncertainty-Aware Reflection (UAR) functions as a secondary reasoning process that activates during agent operation when confidence levels, as determined by the Uncertainty-Aware Memory (UAM), fall below pre-defined thresholds. This triggers a deliberate, inference-time resolution step, allowing the agent to re-evaluate its reasoning and potentially request further information or employ alternative reasoning paths. The implementation of UAR is not continuous; it’s selectively engaged based on uncertainty signals, conserving computational resources while addressing potential reliability issues identified by the UAM. This targeted approach contrasts with constant reflection and allows the agent to focus computational effort on areas where uncertainty is demonstrably high.
![AUQ consistently outperforms a standard enterprise baseline across diverse large language models and demonstrates robust performance even with varying confidence thresholds [latex] au[/latex].](https://arxiv.org/html/2601.15703v1/ETR_combined_figures4.png)
Validating Reliability: Tracing Errors Backwards and Forwards
Agentic Uncertainty Quantification (UQ) enables the evaluation of trajectory validity – the ‘Forward Problem’ – and the subsequent correction of errors through the identification of underlying reasoning steps – the ‘Inverse Problem’. This is achieved by not only predicting outcomes but also reconstructing the probable chain of inferences that led to those predictions. When a trajectory deviates from expected results, Agentic UQ analyzes the discrepancy to infer the most likely latent reasoning path that caused the error. This inferred path then informs corrective actions, allowing the agent to adjust its strategy and improve future performance. The system essentially reverses the planning process to diagnose failures and refine its internal models, facilitating both proactive validation and reactive error recovery.
Confidence elicitation within agentic UQ relies on techniques that quantify uncertainty associated with predicted trajectories. These methods generate probabilistic outputs, expressed as confidence scores, which are utilized in two key processes. In forward reasoning, confidence scores assess the validity of a predicted trajectory, indicating the likelihood of successful completion. Conversely, in inverse reasoning – the correction of deviations – these quantified uncertainties pinpoint the most probable latent reasoning steps that led to the error, allowing for targeted adjustments. The resulting confidence values are not simply qualitative assessments; they are quantifiable metrics used to drive both predictive analysis and corrective action within the agent’s decision-making process.
Trajectory Calibration is a critical process for validating the reliability of agentic systems, focusing on the alignment between predicted confidence levels and observed performance across multi-step action sequences. This calibration is achieved through iterative testing and refinement, where predicted confidences are compared to actual outcomes and the model is adjusted to minimize discrepancies. Successful trajectory calibration, as measured in this system, results in a final, reflected confidence score consistently ranging between 0.95 and 0.96, indicating a high degree of accuracy in predicting the validity of extended action plans. This score reflects the system’s ability to reliably estimate its own performance and identify potential failures before they occur.

From Benchmarks to Real-World Reliability: A Step Forward, But Not a Panacea
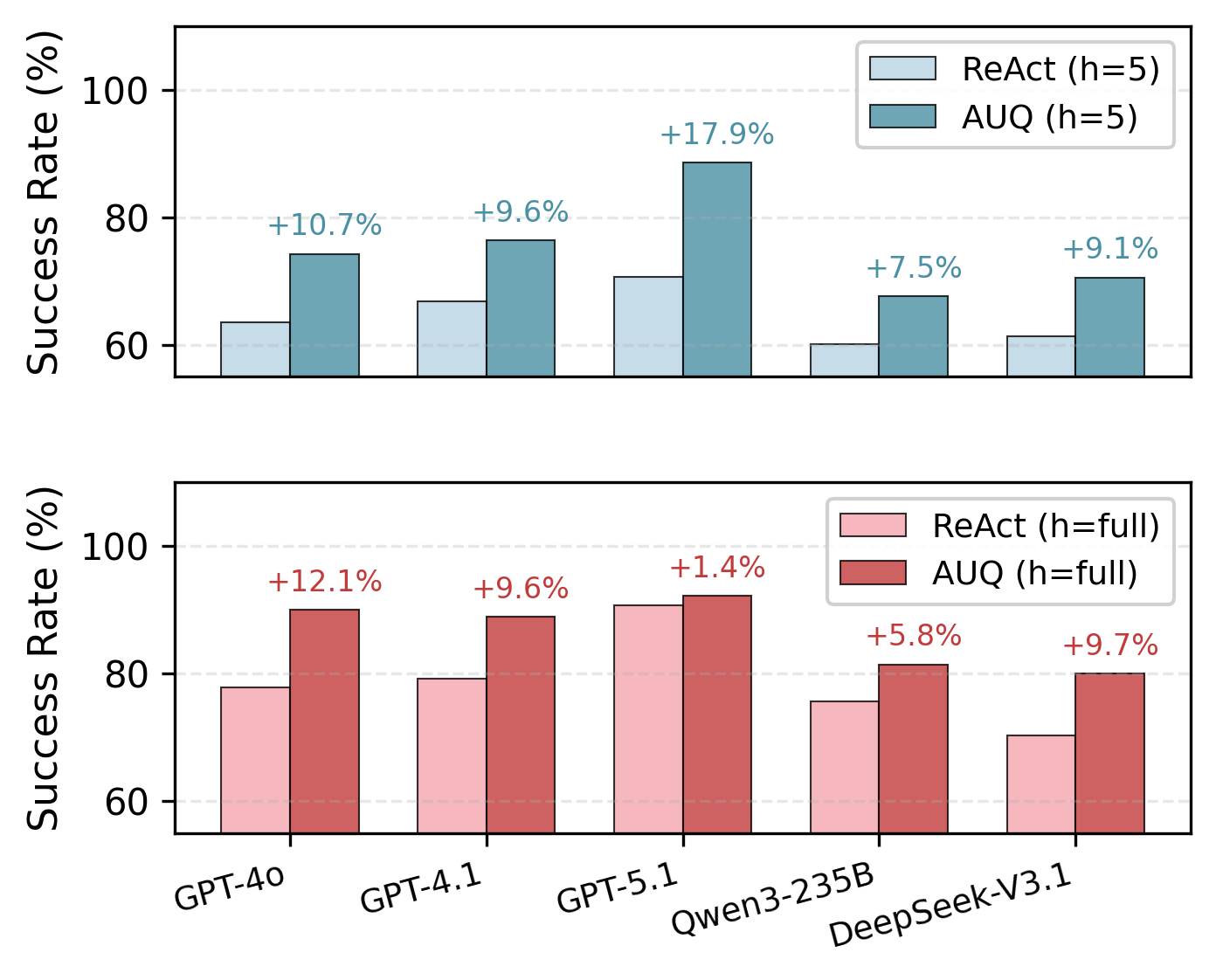
Agentic UQ’s capabilities were rigorously tested across two challenging environments – the ‘Deep Research Bench’ and ‘ALFRED’ – revealing substantial performance gains over existing agents. Evaluations focused on key calibration metrics, including Area Under the Receiver Operating Characteristic curve (AUROC) and Expected Calibration Error (T-ECE), demonstrating improved reliability in assessing its own uncertainties. Critically, Agentic UQ achieved a 20% increase in overall task success rate, indicating a significant advancement in its ability to navigate complex, long-horizon reasoning tasks and consistently deliver accurate results. These findings suggest a robust framework for building more dependable and effective autonomous agents.
Agentic UQ demonstrably addresses a critical limitation in long-horizon reasoning systems: the tendency to fall into a ‘Spiral of Hallucination’. This phenomenon, where agents generate increasingly detached-from-reality plans based on initial inaccuracies, is effectively curtailed by the framework’s inherent uncertainty quantification. By consistently evaluating and acknowledging its own knowledge gaps, the agent avoids overconfident extrapolations and proactively seeks information to validate its assumptions. This leads to more grounded and reliable planning, enabling consistent progress towards complex goals without being derailed by internally generated inconsistencies. The improvement isn’t merely about achieving a successful outcome, but about the robustness of the cognitive process itself.
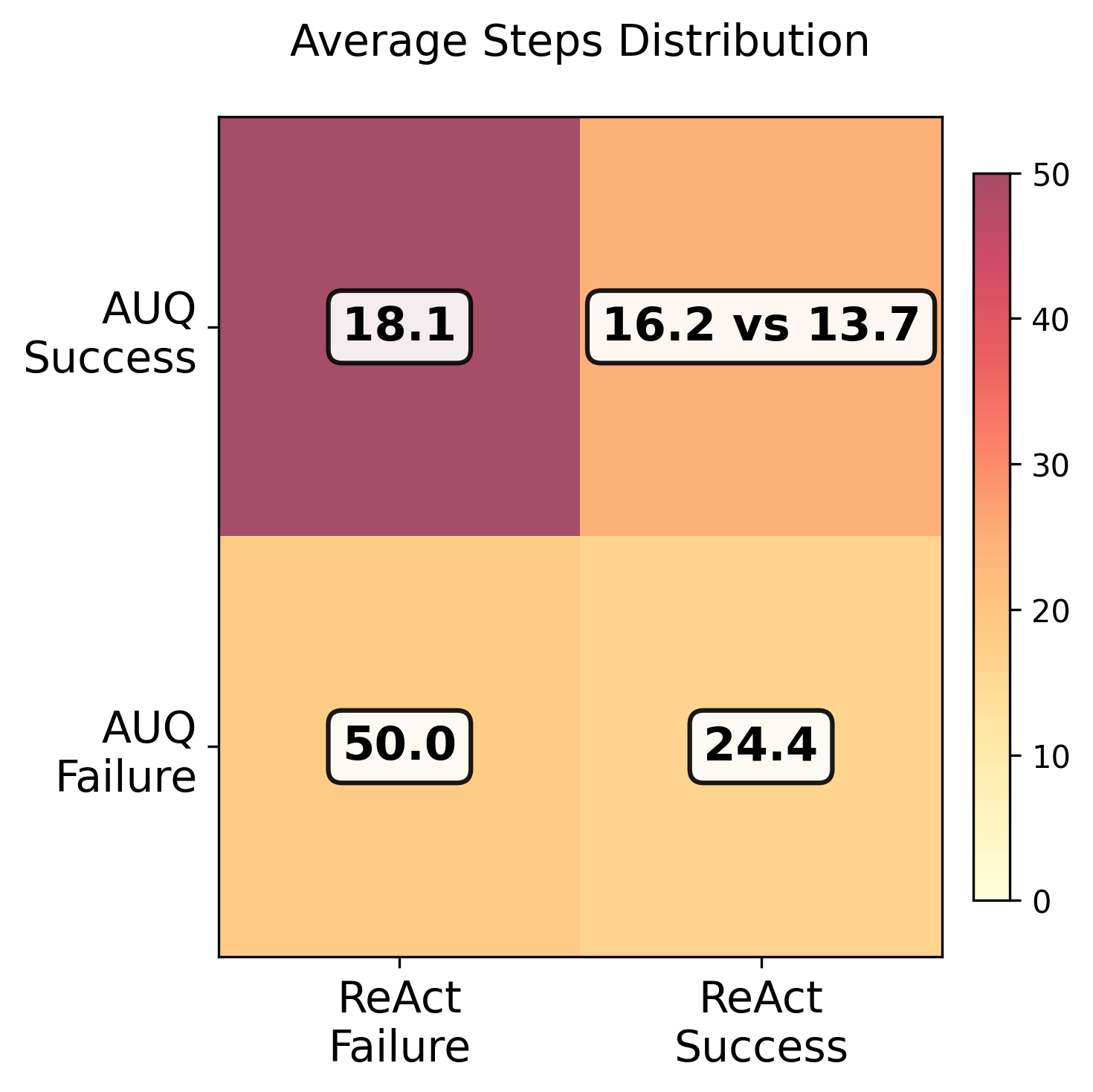
Agentic Uncertainty Quantification (AUQ) not only enhances task success but also significantly improves efficiency, demonstrably reducing the total cost and number of steps required for completion by over thirty steps when contrasted with baseline agents prone to repetitive action loops. This optimization stems from AUQ’s ability to proactively identify and correct potentially erroneous paths before they escalate, preventing wasteful iterations. Current development is directed toward scaling this framework to complex multi-agent scenarios, where coordinated decision-making under uncertainty is paramount, and towards implementing adaptive uncertainty thresholds, a mechanism designed to dynamically adjust sensitivity based on environmental context and further bolster robustness against unforeseen challenges.
The pursuit of reliable long-horizon planning, as outlined in this work, feels predictably fragile. This framework, Agentic Uncertainty Quantification, attempts to systematize a response to inevitable failure – translating uncertainty into control signals. It’s a beautiful attempt to preempt the chaos, but one built on the assumption that anticipating every edge case is possible. As David Hilbert famously stated, “We must be able to answer every well-defined question.” The elegance of AUQ, with its decoupling of forward propagation and inverse calibration via System 1 and System 2 reasoning, is undeniable. Yet, production will invariably expose the limits of even the most sophisticated calibrations, revealing questions not anticipated and failures not foreseen. Every abstraction dies in production, at least it dies beautifully.
What’s Next?
The decoupling of forward propagation and inverse calibration, as demonstrated by this Agentic Uncertainty Quantification framework, feels…familiar. It recalls countless instances where elegant theory met the blunt force of production. One suspects the initial calibration will prove optimistic, and that the long-horizon planning, so neatly quantified here, will gradually degrade into a series of locally optimal, yet globally disastrous, decisions. They’ll call it ‘emergent behavior’ and raise funding. The core issue isn’t the quantification itself, but the inherent brittleness of these systems. The documentation lied again – it always does.
Future work will inevitably focus on scaling this approach, applying it to more complex agents and environments. But a more pressing concern is robustness. How does AUQ fare when confronted with adversarial inputs, or when the underlying LLM’s internal state drifts? The current reliance on System 1/System 2 analogies, while conceptually neat, feels like a temporary reprieve. What happens when the ‘System 2’ component itself becomes unreliable, or is simply overwhelmed by the complexity of the task?
One anticipates a proliferation of ‘uncertainty budgets’ and ‘calibration taxes’ – elaborate schemes to account for the inevitable failures. It started, no doubt, as a simple bash script. Now it’s a probabilistic agent with ‘actionable control signals’. Tech debt is just emotional debt with commits, and this feels like a significant accrual.
Original article: https://arxiv.org/pdf/2601.15703.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-23 19:22