Author: Denis Avetisyan
A new analysis reveals that the surge in artificial intelligence capabilities is demonstrably altering the landscape of federal research investment.
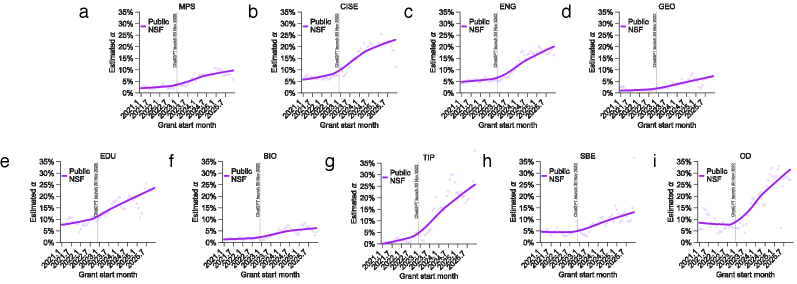
This study examines the influence of large language models on US federal grant proposals, funding rates, and subsequent research outputs across different agencies.
While federal funding is intended to support innovative scientific endeavors, the increasing use of large language models (LLMs) raises questions about their influence on research direction and evaluation. This study, ‘The Rise of Large Language Models and the Direction and Impact of US Federal Research Funding’, examines how LLM involvement correlates with proposal success and downstream research outcomes by analyzing a unique dataset of NSF and NIH submissions and awards. Our findings reveal that LLM use is associated with decreased semantic distinctiveness in proposals and agency-dependent effects-boosting success and publication output at NIH but showing no comparable impact at NSF. Will these trends fundamentally reshape the scientific funding landscape, potentially prioritizing incremental advances over truly novel research?
The High-Stakes Pursuit of Research Funding
The pursuit of research funding from agencies like the National Science Foundation and the National Institutes of Health represents a highly competitive landscape, demanding proposals that transcend mere competence to achieve prominence. Each funding cycle witnesses a substantial influx of applications, often exceeding available resources by a significant margin – sometimes by a factor of ten to one or more. This intense competition necessitates that researchers not only present scientifically rigorous work but also articulate its potential impact with exceptional clarity and persuasiveness. Proposals are evaluated not simply on their inherent merit, but on their ability to distinguish themselves within a vast field of equally qualified submissions, creating a high-stakes environment where meticulous preparation and strategic presentation are paramount for success.
Securing research funding demands more than simply groundbreaking concepts; proposals must actively sell those concepts to reviewers. Researchers increasingly employ what is termed ‘promotional language’ – carefully crafted phrasing that highlights potential impact, emphasizes novelty, and frames the work within currently prioritized research areas. This isn’t merely about exaggeration; it’s a strategic communication tactic, drawing on rhetorical devices to showcase the project’s value and feasibility. Successful proposals demonstrate not only what will be investigated, but why it matters, and how the research will advance the field – often achieved through compelling narratives, vivid descriptions of potential outcomes, and a clear articulation of the broader implications of the findings. This persuasive element, combined with rigorous methodology, significantly increases the likelihood of a proposal standing out amidst intense competition.
Research funding agencies, such as the National Science Foundation and the National Institutes of Health, don’t operate with a blank slate when evaluating proposals; instead, they exhibit discernible patterns in their allocations. These Agency Funding Patterns reflect evolving national priorities, emergent scientific landscapes, and internal strategic goals. Consequently, certain research areas – like artificial intelligence or specific disease mechanisms – may receive disproportionately higher support compared to others, regardless of individual proposal merit. Savvy researchers therefore analyze historical funding data to identify these trends, tailoring their proposals not only to present innovative science but also to align with the agency’s demonstrated preferences regarding research scope, methodology, and even keywords. Understanding these patterns is crucial; a groundbreaking idea that falls outside current agency priorities faces significantly steeper odds, highlighting the importance of strategic alignment in the competitive grant landscape.
Quantifying Novelty: The Measure of Semantic Distinctiveness
Semantic Distinctiveness represents a quantifiable measure of the novelty and uniqueness of a research proposal relative to the existing body of funded projects. This metric assesses how conceptually different a new proposal is from previously awarded grants, effectively gauging its contribution to expanding the current knowledge base. A higher degree of semantic distinctiveness indicates that the proposal addresses a less explored area, potentially offering a significant departure from established research directions. This differentiation is increasingly recognized as a crucial factor in evaluating proposals, influencing their competitiveness for funding opportunities.
Semantic distinctiveness is quantitatively assessed through techniques such as Specter2 Embeddings, a method that transforms proposal text into high-dimensional vector representations. These vectors capture the semantic meaning of the text, allowing for comparisons with vectors representing previously funded research. The process involves training a model on a large corpus of scientific literature to create a semantic space; a proposal’s vector position within this space then indicates its similarity to, or distance from, existing work. Greater distance – represented by lower cosine similarity between vectors – signifies higher semantic distinctiveness and, consequently, a more novel research idea. The resulting numerical score provides an objective measure of a proposal’s originality, facilitating comparative analysis across submissions.
Analysis of National Science Foundation (NSF) and National Institutes of Health (NIH) funding data demonstrates a positive correlation between semantic distinctiveness – a quantifiable measure of the novelty of a research proposal – and the likelihood of securing funding. Proposals exhibiting higher semantic distinctiveness scores, indicating a greater departure from previously funded research, consistently receive more favorable evaluations from grant review panels at both agencies. This suggests that both the NSF and NIH prioritize and reward research that presents genuinely new ideas and approaches, rather than incremental advances on existing work. Statistical modeling confirms this trend, showing a significant association between semantic distinctiveness and funding success rates.
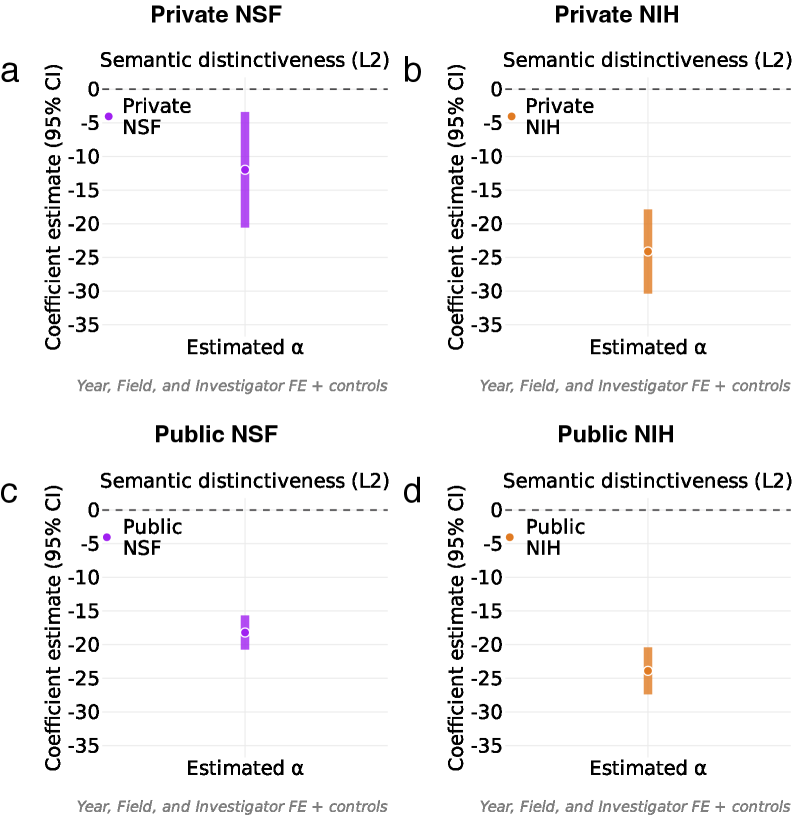
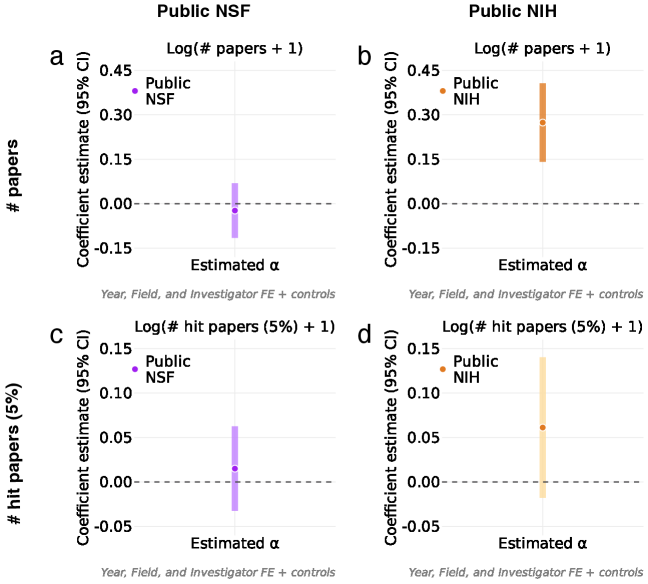
Analysis of research proposal submissions to the National Science Foundation (NSF) and National Institutes of Health (NIH) indicates a correlation between increased utilization of Large Language Models (LLMs) and a reduction in semantic distinctiveness. Specifically, proposals demonstrating greater LLM involvement exhibited, on average, a 5 percentile point decrease in semantic distinctiveness scores compared to those with less LLM assistance. This suggests a potential inverse relationship between the degree of AI-driven content generation and the perceived novelty or originality of research ideas, potentially impacting funding outcomes at these agencies.
The AI Influence: Assessing Authenticity and Proposal Quality
The integration of Large Language Models (LLMs) into scientific writing workflows is occurring at an accelerating rate, evidenced by their increasing presence in grant proposal development. Researchers are utilizing LLMs for tasks ranging from literature reviews and initial drafting to editing and refinement of proposals. This adoption impacts both the process of proposal creation – potentially reducing the time and effort required – and the characteristics of the resulting submissions. The speed of LLM integration necessitates careful consideration of potential consequences, including effects on originality, semantic diversity, and the overall quality of scientific communication, as well as the need for methods to accurately assess the degree of AI assistance in submitted work.
The increasing use of Large Language Models (LLMs) in scientific writing raises concerns about potential reductions in semantic distinctiveness across research proposals. LLMs are trained on vast datasets and tend to generate text based on common patterns and phrasing, which could inadvertently lead to proposals exhibiting greater similarity in language and conceptual approach. This homogenization effect could diminish the novelty and unique contributions of individual research efforts, potentially masking genuinely innovative ideas within a larger pool of increasingly similar submissions. Consequently, assessing the originality and semantic diversity of proposals becomes critical to ensure that funding mechanisms continue to support a broad range of research perspectives.
The increasing use of Large Language Models (LLMs) in scientific writing necessitates methods for quantifying AI assistance in submitted proposals. These ‘LLM Detection Methods’ typically employ techniques like perplexity scoring and analysis of burstiness – variations in sentence length and complexity – to estimate the probability that a text segment was generated by an LLM. The primary goal of these methods isn’t necessarily to penalize LLM use, but rather to provide transparency regarding the level of AI involvement, allowing reviewers to appropriately assess the originality and intellectual contribution of the submitted work. Establishing a baseline understanding of LLM influence is crucial for maintaining the integrity of the scientific review process and ensuring fair evaluation of proposals.
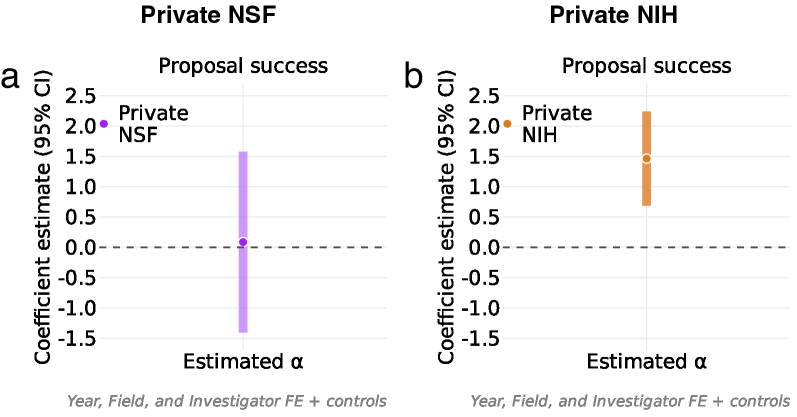
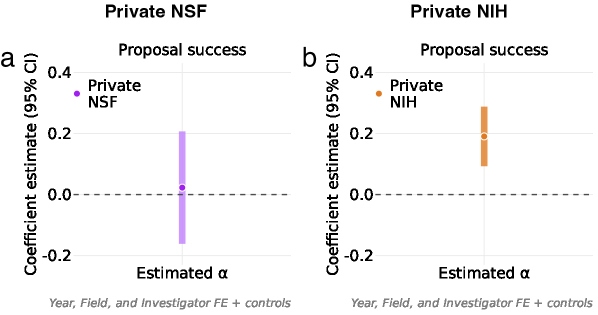
Analysis of National Institutes of Health (NIH) grant submissions indicates a statistically significant correlation between the extent of Large Language Model (LLM) involvement and proposal success rates. Specifically, proposals demonstrating higher levels of LLM assistance exhibited a 4 percentage point increase in funding outcomes compared to those with limited or no detectable LLM use. This suggests, at least within the NIH funding landscape, that leveraging AI tools in proposal development is associated with improved competitiveness, though further research is needed to establish causality and understand the mechanisms driving this correlation.
From Funding to Impact: The Measure of Scientific Progress
The pursuit of scientific advancement extends far beyond the initial allocation of resources; securing funding from organizations like the National Science Foundation and the National Institutes of Health represents merely the foundational step in a complex process. True success is ultimately measured by the dissemination of impactful research, a metric directly reflected in an institution’s ‘Publication Output’. This output isn’t simply a tally of published papers, but rather a demonstrable record of contribution to the scientific body of knowledge. A robust publication record signifies not only active research, but also peer validation and the potential to influence future studies and real-world applications, effectively translating financial investment into tangible progress and innovation.
The true measure of research success extends beyond simply producing a volume of work; it resides in the generation of high-impact publications. These publications are not merely counted, but evaluated by their influence within the scientific community, primarily determined by citation rates – how frequently other researchers reference the work in their own studies. A highly cited paper often signifies a foundational discovery, a novel methodology, or a paradigm-shifting theory, effectively accelerating progress within its field. Consequently, these publications gain prominence, shaping future research directions and often attracting further funding and collaboration, creating a positive feedback loop that amplifies their impact beyond initial findings. The pursuit of such influential work remains a central goal for researchers and a key metric for evaluating the overall effectiveness of the scientific enterprise.
Scientific advancement is inextricably linked to consistent financial support, as demonstrated by a strong correlation between funding from agencies like the National Science Foundation (NSF) and the National Institutes of Health (NIH) and the sheer volume of published research. This relationship underscores the critical role of these agencies in fostering a robust and productive scientific ecosystem. Increased funding enables researchers to pursue investigations, collect and analyze data, and disseminate their findings through peer-reviewed publications, ultimately driving progress across diverse fields. The observed correlation isn’t merely quantitative; it signifies that sustained investment directly translates into a greater body of knowledge, expanding the horizons of scientific understanding and innovation.
Recent analyses reveal a nuanced relationship between the integration of Large Language Models (LLMs) and scientific productivity. While increased LLM involvement correlates with a 5% rise in the sheer volume of published research, this boost doesn’t automatically equate to more groundbreaking work. The data suggests LLMs currently enhance a researcher’s capacity to produce papers, potentially streamlining writing and data analysis, but do not yet demonstrably improve the quality or novelty required for publications to achieve high citation rates and become truly impactful within their respective fields. This indicates that LLMs are, at present, more effective as tools for accelerating the publication process than for fostering the innovative thinking that drives high-impact research.
The study illuminates a shift in scientific productivity, revealing how federal research funding increasingly reflects the influence of large language models. This echoes Robert Tarjan’s sentiment: “A system that needs instructions has already failed.” The inherent promise of these models lies in their ability to distill complex information and accelerate discovery without requiring excessive guidance. However, the agency-dependent effects observed suggest that the current system of research evaluation isn’t adequately equipped to assess the semantic distinctiveness of proposals influenced by these tools. A truly effective system would recognize genuine innovation, not merely reward proposals that conform to easily-processed patterns, thereby removing unnecessary layers of complexity.
Further Lines of Inquiry
The observed agency-dependent effects merit dissection. Funding patterns, predictably, do not shift uniformly. The question is not merely that large language models influence proposal success, but how different missions interpret and prioritize applications leveraging these tools. A simple accounting of dollars awarded obscures the subtle recalibration of research agendas – a shift in emphasis, not necessarily in volume.
Future work should address the semantic distinctiveness of funded proposals. Are language models fostering genuine novelty, or simply refining existing ideas with a veneer of innovation? The study’s reliance on broad metrics of scientific productivity, while pragmatic, leaves open the possibility that a surge in publications masks a corresponding decline in conceptual breakthroughs. Measuring the quality of funded research remains, predictably, the central challenge.
The analysis assumes a relatively stable definition of ‘relevant’ research. This assumption warrants scrutiny. As language models reshape the very process of knowledge creation, the criteria for evaluating proposals will inevitably evolve. The long-term impact may not be a change in what is funded, but in what counts as research itself.
Original article: https://arxiv.org/pdf/2601.15485.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-23 16:03