Author: Denis Avetisyan
Researchers have developed a new AI system that allows drones to autonomously navigate complex environments and respond to human needs using only visual input.
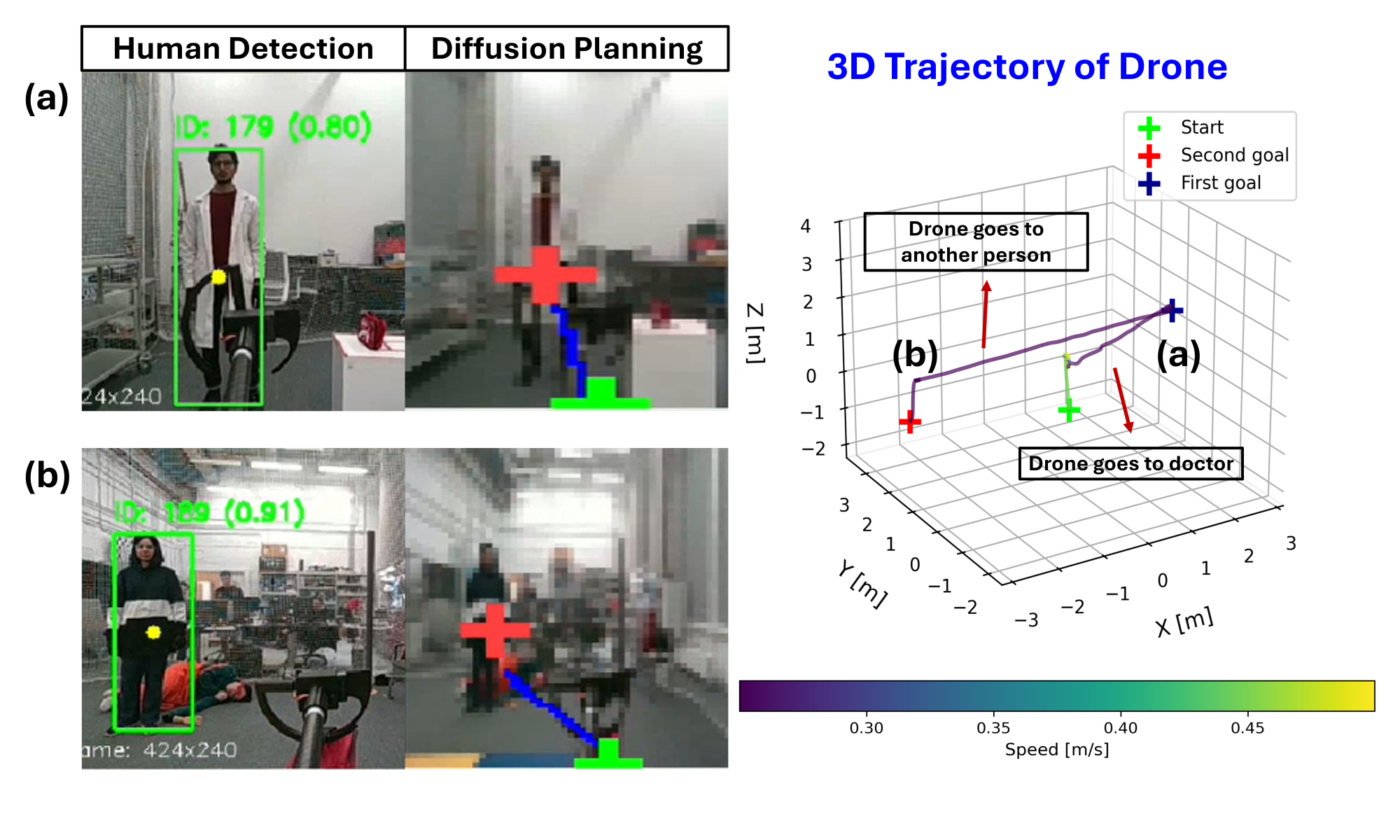
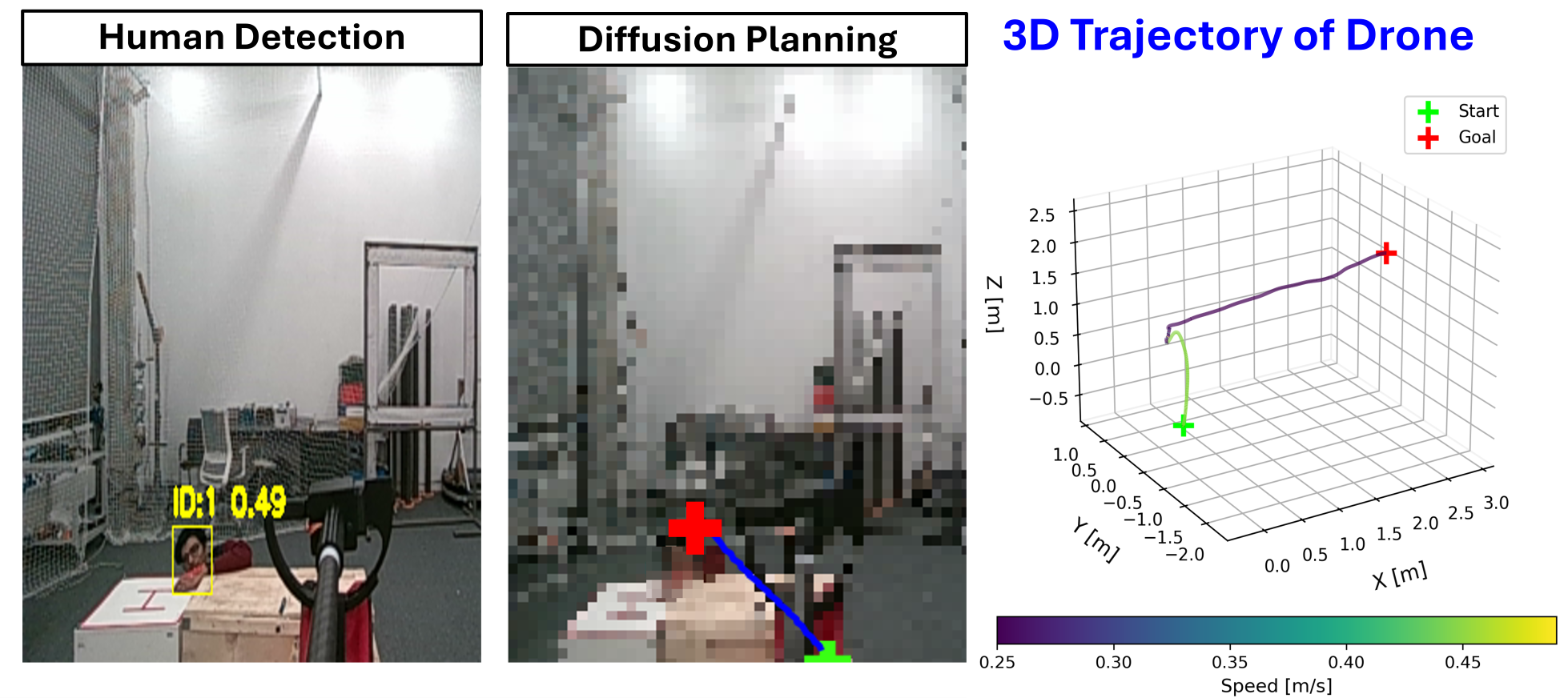
HumanDiffusion leverages diffusion models and object detection to generate safe and effective trajectories for unmanned aerial vehicles in dynamic search and rescue scenarios.
Effective human-robot collaboration in dynamic, real-world scenarios demands autonomous systems capable of both perceiving and proactively navigating around people. This paper introduces ‘HumanDiffusion: A Vision-Based Diffusion Trajectory Planner with Human-Conditioned Goals for Search and Rescue UAV’, a lightweight system that generates safe, human-aware navigation trajectories directly from RGB imagery using diffusion models and YOLO-based human detection. By predicting trajectories in pixel space, HumanDiffusion enables a quadrotor to autonomously approach and assist individuals without relying on pre-existing maps or computationally expensive planning pipelines. Could this approach unlock more robust and intuitive human-UAV interactions in critical applications like search and rescue?
The Inevitable Imperfection of Maps
Conventional search and rescue missions frequently contend with conditions that drastically impede effectiveness. Limited visibility, stemming from darkness, dense foliage, inclement weather, or the very nature of disaster scenes, severely restricts the scope and speed of operations. This is compounded by the critical need for a rapid response – the window for successful rescue diminishes rapidly with each passing moment. Human search teams, while highly skilled, are often constrained by these environmental factors and logistical challenges, requiring extensive resources and posing significant risks to their own safety. The urgency inherent in SAR scenarios demands a swift and thorough assessment of affected areas, a task made exceptionally difficult when visibility is poor and time is of the essence, highlighting the need for innovative solutions to overcome these persistent limitations.
The limitations of pre-built maps pose a significant challenge to deploying autonomous systems in real-world search and rescue scenarios. Conventional robotic navigation frequently depends on detailed, prior knowledge of the environment – a static map outlining traversable paths and obstacles. However, disaster zones and remote wilderness areas are rarely accurately mapped, and even when maps exist, they quickly become obsolete due to shifting debris, changing weather conditions, or the dynamic nature of the search itself. This reliance on pre-existing data restricts a robot’s ability to operate effectively in unfamiliar or rapidly evolving landscapes, hindering its capacity to independently explore and locate individuals in need of assistance. Consequently, a critical need exists for navigation technologies that can function reliably without pre-programmed environmental information, allowing for true autonomy in unpredictable conditions.
Successfully deploying robotic assistance in search and rescue scenarios demands more than simple path planning; robots must actively interpret complex visual environments to pinpoint human targets, even under challenging conditions. Current research focuses on equipping these systems with advanced computer vision capable of identifying individuals obscured by debris, foliage, or low lighting. This isn’t merely object recognition, but a nuanced understanding of form and movement, allowing the robot to differentiate a person from background clutter. The difficulty lies in the inherent variability of real-world disaster zones – unpredictable layouts, dynamic obstacles, and the critical need for real-time processing to ensure swift location of those in need. Consequently, algorithms are being developed to prioritize partial observations and probabilistic reasoning, enabling robots to confidently identify and track individuals despite incomplete visual data, ultimately improving response times and increasing the likelihood of successful rescues.
The demand for truly effective robotic search and rescue hinges on the development of navigation systems that don’t require pre-existing maps. Unlike systems reliant on detailed blueprints of an environment, a map-free approach allows robots to operate immediately in disaster zones or unfamiliar terrain. This necessitates advanced algorithms capable of processing real-time sensor data – visual, thermal, and potentially auditory – to build a dynamic understanding of surroundings while simultaneously searching for human subjects. Crucially, these systems must not only detect individuals, but also maintain continuous tracking, even amidst obstructions or challenging conditions, requiring a sophisticated interplay between robust localization, perception, and motion planning to ensure a swift and successful rescue operation.
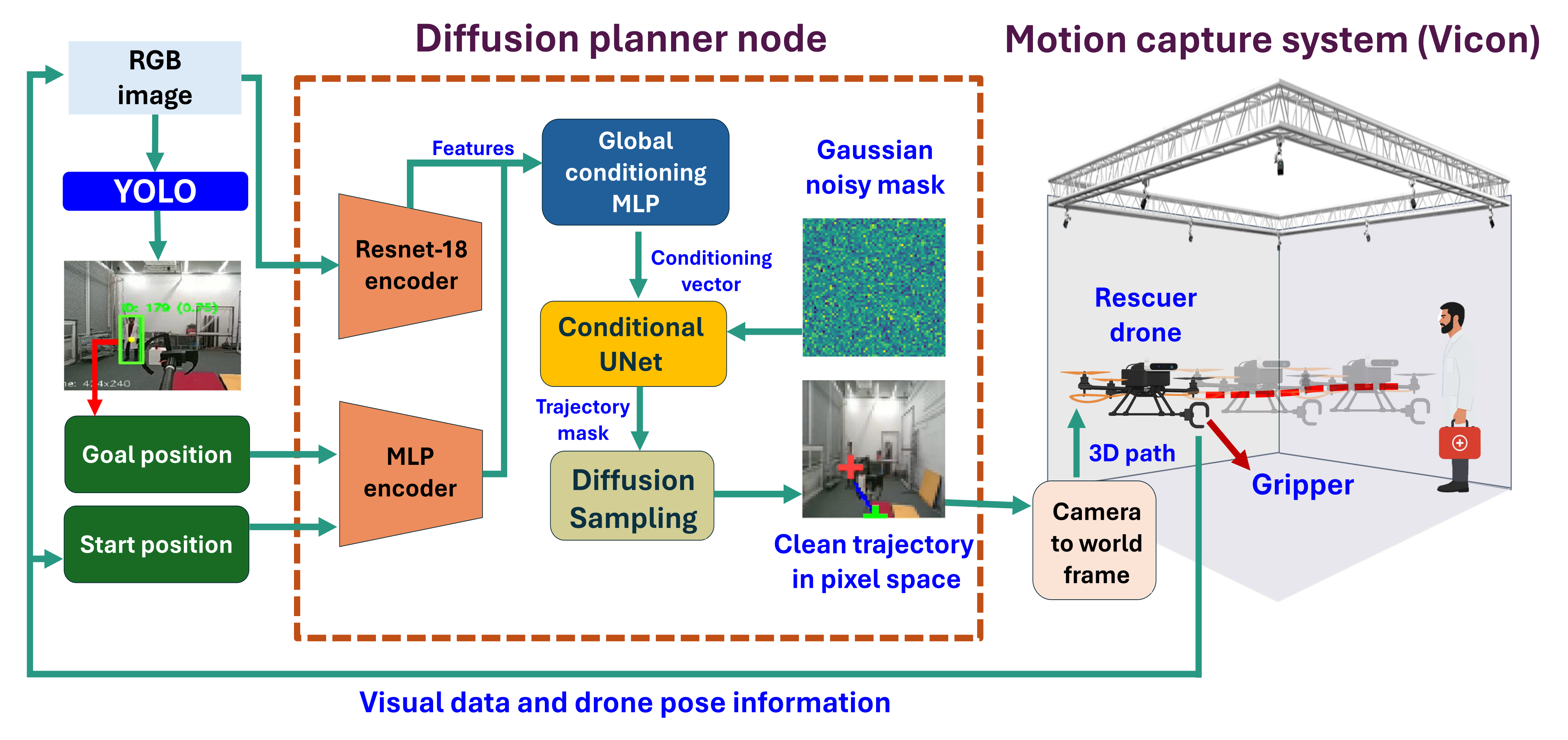
Predicting the Unpredictable: A Diffusion-Based Approach
The proposed trajectory prediction system employs a conditional UNet-based diffusion model that directly outputs future trajectory pixels from RGB image inputs. This model operates by learning to reverse a diffusion process, starting from random noise and iteratively refining it into a plausible trajectory prediction. The UNet architecture, commonly used in image segmentation, is adapted to predict future pixel locations representing the trajectory. Conditioning the diffusion process on the input RGB image allows the model to incorporate visual context into the trajectory prediction, enabling it to anticipate the movement of agents within the scene and generate a distribution over possible future paths rather than a single deterministic trajectory.
The trajectory prediction model incorporates YOLO-11, a real-time object detection system, to locate humans within the RGB image input. YOLO-11 identifies bounding boxes around detected individuals, providing the model with positional data regarding potential rescue targets. This information is then used as a conditional input to the diffusion model, biasing the predicted trajectories towards navigating in the direction of the identified humans. The system is capable of simultaneously detecting multiple humans, enabling it to plan paths towards the nearest or most critical target based on the specific application requirements.
The diffusion model employed generates multiple plausible trajectories rather than a single deterministic path. This probabilistic approach allows for robust path planning because the model learns a distribution over potential future states, accounting for inherent uncertainties in dynamic environments and sensor data. Consequently, the system can adapt to unforeseen obstacles or changes in the environment by sampling from this distribution and selecting trajectories that remain feasible and goal-oriented, even in previously unencountered scenarios. This distribution-based prediction facilitates more reliable navigation compared to methods that rely on a single predicted path, improving performance in complex and unpredictable surroundings.
The trajectory prediction model builds upon standard diffusion model architectures by incorporating a conditional input mechanism. Specifically, the output of a human detection module, YOLO-11, which provides bounding box coordinates for identified individuals, is fed into the UNet as a conditional input. This allows the diffusion process to be guided towards generating trajectories that terminate near the detected human locations. The conditioning is implemented by concatenating the human detection output as additional feature channels to the UNet’s intermediate layers, effectively biasing the denoising process to favor paths leading to the specified targets. This conditional approach enables the model to generate diverse, yet goal-oriented, trajectories in response to dynamic human positions within the input RGB image.
Quantitative Evidence of Navigational Proficiency
Model performance was quantitatively assessed by calculating the Mean Squared Error (MSE) between predicted trajectory masks and corresponding ground-truth data, both represented in pixel space. The resulting MSE value of 0.02 indicates a low average difference between predicted and actual trajectories. This metric was used to evaluate the accuracy of the diffusion model’s output, providing a numerical measure of its ability to generate accurate trajectory predictions. Lower MSE values correlate with higher prediction accuracy, demonstrating the model’s efficacy in reconstructing plausible future paths.
A planning was implemented as a comparative baseline to assess the diffusion model’s navigational capabilities in challenging environments. This established pathfinding algorithm, known for its optimality and completeness, provided a benchmark against which the diffusion model’s performance could be objectively measured. Comparative analysis demonstrated that the diffusion model achieved competitive results with A planning, particularly in scenarios involving dynamic obstacles and complex spatial arrangements. While A* planning guarantees an optimal path given sufficient computation, the diffusion model exhibited comparable success rates with potentially reduced computational cost in these complex environments, indicating its viability as an alternative navigation strategy.
The Intel RealSense D455 depth camera was integrated into the system to provide three-dimensional spatial data used for the generation of 3D waypoints. These waypoints served as intermediate goals for the navigation system, supplementing the 2D trajectory prediction with height information. By incorporating depth data, the model was able to predict more realistic and physically plausible trajectories, accounting for obstacles and varying terrain heights, which ultimately contributed to improved navigation performance and a more robust system in complex environments.
Evaluation of the diffusion model’s navigational capabilities was conducted across both simulated and real-world environments to assess performance in approaching humans. These experiments yielded an overall success rate of 80%, indicating the model’s effectiveness in reaching designated human targets. Success was defined by the robot reaching a predefined proximity to the human subject without collision. Data was collected from multiple trials, accounting for variations in environmental complexity and human movement patterns, to establish a robust performance metric.

Towards a Future of Resilient Human-Robot Collaboration
The capacity for robots to navigate without pre-existing maps represents a significant leap forward in human-robot collaboration, particularly within unpredictable and dynamic environments. Traditional robotic navigation relies heavily on detailed maps, limiting functionality in scenarios where maps are unavailable, outdated, or impractical to create – such as disaster zones or rapidly changing industrial sites. This research showcases a novel approach, allowing robots to autonomously explore and navigate towards humans based on real-time sensory input and learned behaviors, rather than static spatial data. This map-free capability not only broadens the scope of potential applications for robotic assistance, but also enhances adaptability and resilience in complex, real-world situations, paving the way for more effective and intuitive human-robot partnerships.
The demonstrated efficacy of this map-free navigation system extends to critical real-world applications, notably search-and-locate missions and simulated accident response scenarios. Testing revealed a robust ability to autonomously reach designated human targets, achieving a 90% success rate – completing nine out of ten trials – in the more demanding accident response simulation. While performance was slightly lower in the search-and-locate scenario, still yielding a 70% success rate over ten trials, these results collectively underscore the versatility of the approach. This adaptability suggests a promising pathway toward deploying robots in dynamic and unpredictable environments where pre-mapped solutions are impractical or unavailable, ultimately enhancing operational effectiveness and potentially saving lives.
The capacity for robots to autonomously navigate toward and assist humans holds substantial promise for transforming Search and Rescue (SAR) operations. Currently, these missions often place first responders in considerable danger while facing time constraints and limited situational awareness. By deploying robots capable of independent navigation, even in complex or map-less environments, rescuers can gain critical insights into disaster zones remotely. This approach not only minimizes risk to human personnel, but also accelerates the process of locating and aiding those in need. The technology effectively extends the reach and capabilities of SAR teams, potentially increasing survival rates and improving overall mission effectiveness through faster response times and enhanced information gathering.
Ongoing research endeavors are directed towards broadening the scope of this navigational model to encompass increasingly intricate and dynamic environments, including those with unpredictable obstacles and varying lighting conditions. A key focus involves transitioning from simulated trials to practical implementation by integrating the algorithms into physical robotic systems. This integration necessitates addressing challenges related to sensor noise, computational constraints, and the complexities of real-world locomotion. Ultimately, the goal is to create a robust and adaptable system capable of seamlessly collaborating with humans in a diverse range of applications, from disaster relief and search operations to industrial inspection and autonomous exploration – paving the way for truly versatile robotic assistance.
The presented work on HumanDiffusion subtly echoes a principle of resilient systems. It acknowledges that environments, particularly those involving human interaction during search and rescue, are inherently unpredictable-a constant source of potential ‘incidents’ requiring adaptive responses. As Barbara Liskov observed, “Programs must be designed with change in mind.” This system, by generating trajectories directly from visual input and conditioning goals on human presence via YOLO detection, doesn’t attempt to eliminate uncertainty but rather to navigate it. The diffusion model’s probabilistic approach allows the UAV to gracefully adjust to evolving conditions, embodying the idea that systems don’t simply age; they demonstrate maturity through their capacity to absorb and respond to change-treating time not as a metric of decay, but as the medium within which adaptation occurs.
What’s Next?
The elegance of HumanDiffusion lies in its translation of visual input into actionable trajectories. However, every bug is a moment of truth in the timeline; the system, presently, operates within a constrained reality. The fidelity of YOLO detection, while improving, remains a brittle point of failure-a single misidentified object could cascade into a flawed path. Future iterations must confront not simply what the UAV sees, but how it interprets ambiguity, acknowledging that perfect perception is a phantom.
More fundamentally, this work highlights the inherent tension between planning and improvisation. A diffusion model generates a likely future, but real-world search and rescue is defined by the unexpected. The system’s current architecture treats the environment as a static backdrop for trajectory generation. A truly robust solution will require a feedback loop, where the UAV’s actions subtly reshape the probabilistic landscape guiding future planning-a recognition that the present is always negotiating with the past.
Technical debt is the past’s mortgage paid by the present. The current framework, while promising, is built upon established methods. The next step isn’t merely refinement, but a willingness to challenge the underlying assumptions. The question isn’t simply whether the UAV can find a person, but whether it can adapt to a world actively resisting its search-a world where the very act of observation alters the observed.
Original article: https://arxiv.org/pdf/2601.14973.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-23 05:59