Author: Denis Avetisyan
This review details a software engineering framework for creating AI agents that effectively leverage codified knowledge from human experts to tackle complex tasks.
![The framework proposes that durable software systems aren’t constructed, but cultivated from the ongoing codification of knowledge-a process inherently anticipating eventual obsolescence and demanding continuous adaptation rather than striving for a mythical state of completion [latex] \rightarrow \in fty [/latex].](https://arxiv.org/html/2601.15153v1/framework.png)
A novel approach to augmenting large language models with structured domain expertise for automated data analysis and visualization.
Critical domain knowledge often resides with a limited number of experts, creating scalability bottlenecks and hindering effective decision-making; this research, presented in ‘How to Build AI Agents by Augmenting LLMs with Codified Human Expert Domain Knowledge? A Software Engineering Framework’, addresses this challenge by introducing a novel software engineering framework for building AI agents. The core contribution is an agent-augmenting a Large Language Model with codified expert rules and a [latex]RAG[/latex] system-that demonstrably achieves expert-level performance in generating simulation data visualizations. Does this framework represent a viable path toward systematically capturing and deploying tacit expertise across complex engineering domains, empowering non-experts to tackle specialized tasks?
The Inevitable Expertise Bottleneck
Interpreting data generated by complex simulations-spanning fields like mechanical engineering, electromagnetism, and electrochemistry-historically necessitates a deep understanding of the underlying scientific principles and the nuances of the simulation itself. This is because the raw output from these models isn’t directly interpretable; it often manifests as vast datasets of numerical values or intricate visualizations requiring specialized knowledge to decode. Consequently, extracting meaningful insights relies heavily on experts capable of connecting simulation results back to the physical phenomena being modeled, assessing the validity of the data, and identifying key trends. The intricacy of these systems and the sophistication of the simulations demand not only computational power but also a skilled human interpreter to translate complex data into actionable knowledge, creating a significant hurdle to broader accessibility and faster innovation.
The extraction of meaningful insights from complex simulations is frequently hampered by a critical impediment: the ‘Expert Bottleneck’. This arises because interpreting the vast datasets generated by models of mechanical, electromagnetic, and electrochemical systems necessitates highly specialized domain knowledge. Consequently, a limited number of experts become essential for translating raw simulation outputs into actionable understanding. This dependence creates a significant delay in the analytical process and restricts the scale at which these simulations can be effectively utilized; the rate of discovery is fundamentally bound by the availability of those possessing the necessary expertise. Without addressing this bottleneck, organizations struggle to fully capitalize on their investment in sophisticated modeling and analysis, hindering innovation and delaying critical decision-making.
The interpretation of data generated by complex simulations hinges critically on effective visualization, yet transforming raw numerical outputs into readily understandable graphics is frequently a laborious, manual undertaking. While simulations can rapidly generate vast datasets detailing the behavior of intricate systems, the process of crafting informative plots, charts, and animations often demands significant time and specialized skill in data processing and graphical design. This disconnect between simulation speed and visualization creation presents a substantial obstacle to efficient analysis; researchers can find themselves spending more time preparing data for review than actually gaining insights from it. Consequently, advancements in automated visualization techniques are crucial for unlocking the full potential of complex simulations and accelerating discovery across fields like engineering, materials science, and beyond.
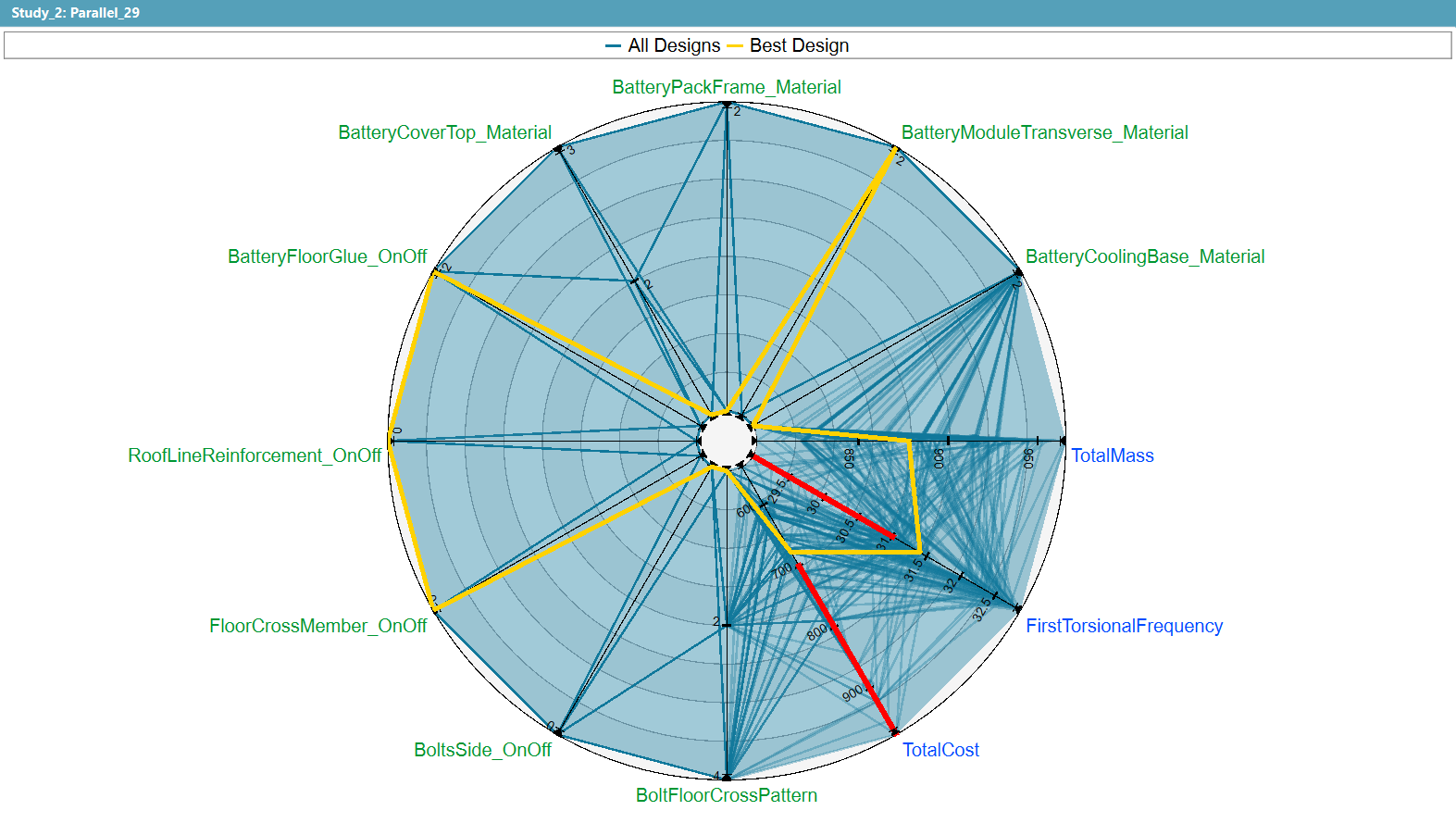
Automated Insight: A System Forged From Data
The Automated Visualization Generation agent is an artificial intelligence system built upon a Large Language Model (LLM) and designed to independently produce visualizations directly from simulation data. This agent accepts simulation outputs as input and, without requiring manual intervention, generates appropriate visual representations of the data. The system aims to streamline the visualization process, reducing the time and expertise traditionally needed to create informative and accurate graphical depictions of simulation results. Its autonomous functionality allows for rapid exploration of simulation data and facilitates quicker identification of key trends and insights.
The AI agent employs a Retrieval-Augmented Generation (RAG) system to integrate relevant domain-specific knowledge into the visualization generation process. This system functions by first retrieving information from a knowledge base-containing data on simulation parameters, variable types, and appropriate visualization techniques-based on the characteristics of the input simulation data. The retrieved information is then incorporated as context for the Large Language Model (LLM), enabling it to generate visualization instructions that are informed by established domain expertise and tailored to the specific data being analyzed. This approach avoids reliance solely on the LLM’s pre-trained knowledge, mitigating potential inaccuracies and enhancing the relevance and interpretability of the generated visualizations.
The AI agent’s output quality is maintained through the implementation of codified ‘Expert Rules’. These rules represent established visualization best practices, covering aspects such as appropriate chart selection for data types, effective color palettes for clarity, and labeling conventions for axis and data points. Furthermore, the system incorporates convergence checking rules, which automatically assess simulation data for stability and validity before generating visualizations; this prevents the creation of misleading or inaccurate graphics derived from incomplete or unstable simulations. These codified rules are applied during the visualization generation process to ensure adherence to established standards and enhance the reliability of the resulting output.
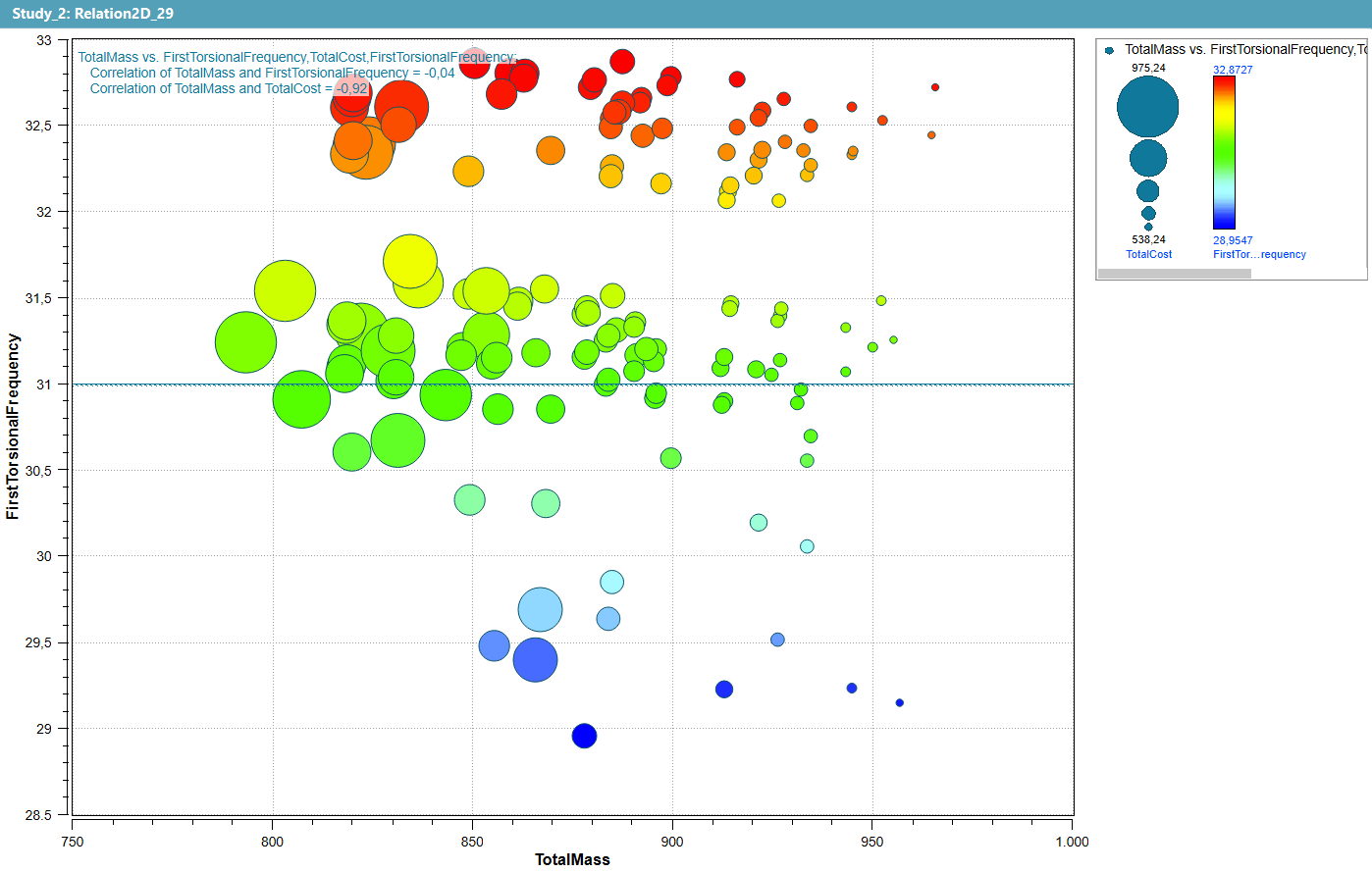
The Proof: Code and Visual Fidelity Assured
The research prioritizes the generation of syntactically and logically correct Python code for visualization creation. This focus on ‘Code Correctness’ is crucial as errors in the generated code directly impact the reliability and reproducibility of the resulting visualizations. Evaluation metrics assess the code’s functionality, ensuring it executes without errors and accurately implements the intended visualization logic. Standard deviation measurements, ranging from 0.29 to 0.58, demonstrate a statistically significant improvement in code correctness compared to baseline models, which exhibited a standard deviation of 0.67-1.24. This improved reliability minimizes the need for manual debugging and ensures consistent visualization outputs.
Evaluations demonstrate a substantial improvement in the quality of generated visualizations, with the system achieving a mean score of 2.60 on quality metrics. This represents a 206% increase over the baseline score of 0.85, indicating significantly clearer, more informative, and more accurate data representation in the produced visuals. The assessment focused on the ability of the visualizations to effectively convey the underlying data without ambiguity or distortion.
The system’s ability to generate correct Python code for visualizations was evaluated using data from Simulation Analysis Software. This case study involved processing complex datasets originating from diverse simulation types. Results indicate a standard deviation ranging from 0.29 to 0.58 for code correctness, representing a substantial improvement over the baseline system which exhibited a standard deviation of 0.67 to 1.24. This lower standard deviation demonstrates increased consistency in generating functional and accurate code across varying simulation data complexities.
Beyond Disciplines: A Physics-Agnostic Future
This innovative system distinguishes itself through a fundamentally physics-agnostic design, a characteristic enabling its broad applicability across a remarkably diverse range of simulation domains. Unlike traditional data analysis tools tailored to specific physical phenomena, this approach functions independently of the underlying physics governing the simulation. This means the system can seamlessly process and interpret data originating from mechanical simulations-modeling stress and strain-as easily as it handles data from electromagnetic or even complex electrochemical systems. The core architecture avoids hardcoding assumptions about physics, instead focusing on the visual patterns and relationships within the data itself, thereby unlocking insight discovery in areas previously requiring highly specialized expertise and custom tooling. This adaptability promises to democratize access to complex simulation data, allowing researchers and engineers in disparate fields to leverage AI-driven visualization for novel discoveries.
The AI Agent functions as a powerful extension of human analytical capabilities by automating the often-complex process of scientific visualization. Traditionally, extracting meaningful insights from simulation data requires significant domain expertise – a deep understanding of both the physics involved and the techniques for effectively representing that data visually. This system bypasses that bottleneck, generating visualizations tailored to the data without necessitating expert intervention. Evaluators consistently rated the AI-generated visuals as highly informative, indicating a marked improvement over baseline methods and suggesting that users – even those without specialized training – can readily interpret complex phenomena and accelerate discovery. By democratizing access to data understanding, the agent effectively amplifies the potential for insight across a wider range of scientific and engineering disciplines.
The AI Agent doesn’t simply generate visualizations; it crafts them according to established visualization design principles, ensuring clarity and effective data communication. Rigorous evaluation demonstrated a significant improvement in visualization quality; human evaluators consistently assigned a mode rating of 3 – indicating strong comprehension and insight – to the AI-generated visuals. This contrasts sharply with the baseline visualizations, which received a mode rating of 0 in four out of five tested scenarios. This outcome suggests the integration of these principles isn’t merely aesthetic; it fundamentally enhances the ability of users to interpret complex data and derive meaningful conclusions, irrespective of the specific scientific domain.
The pursuit of robust AI agents, as detailed in this framework, isn’t simply about constructing tools, but cultivating ecosystems. The codification of expert knowledge, transforming tacit understanding into actionable data for LLM-based agents, reveals a profound truth: systems evolve, they aren’t built. This mirrors the inherent unpredictability of complex systems; monitoring becomes the art of fearing consciously, anticipating emergent behaviors rather than enforcing rigid control. As Tim Bern-Lee observed, “The Web is more a social creation than a technical one.” This holds equally true for these agents; their effectiveness hinges not just on the underlying technology, but on the quality and interconnectedness of the knowledge they embody-a social creation within a technological framework. true resilience, therefore, begins where certainty ends, embracing adaptation as the defining characteristic of these evolving systems.
Beyond the Scaffold
This work demonstrates a capacity to capture expertise, but it is crucial to recognize that codified knowledge isn’t knowledge itself – it’s a static approximation. The agent functions as a lens, refracting a past understanding onto a present dataset. The inevitable divergence between model and reality isn’t a bug; it’s the fundamental condition. Attempts to endlessly refine the knowledge base will discover diminishing returns, ultimately chasing an asymptote of perfect representation. A guarantee of continued accuracy is merely a contract with probability.
The true challenge lies not in building better agents, but in fostering ecosystems where agents can adapt. The framework, by its nature, invites a brittle rigidity. Future work should explore architectures that prioritize graceful degradation over absolute fidelity, and mechanisms for agents to collaboratively evolve their understanding – to learn from the chaos, rather than attempt to suppress it. Stability is merely an illusion that caches well.
This is not a path toward automation of expertise, but toward augmentation of it. The value will not be in replacing the analyst, but in freeing them from the mundane, allowing them to focus on the genuinely novel – the anomalies the system cannot explain. Chaos isn’t failure – it’s nature’s syntax. The next iteration isn’t about building a more complete map, but about cultivating a more sensitive compass.
Original article: https://arxiv.org/pdf/2601.15153.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-22 20:00