Author: Denis Avetisyan
Researchers have developed a new system that allows humanoid robots to reliably navigate challenging elevated platforms using a combination of learned locomotion and full-body manipulation skills.
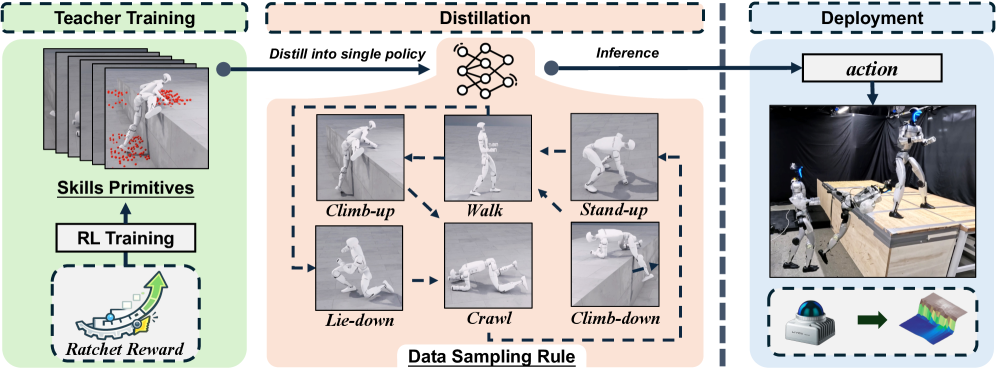
The APEX system utilizes a ‘ratchet progress’ reward function and policy distillation to enable robust and adaptable high-platform traversal for humanoid robots.
Despite advances in humanoid locomotion, traversing platforms exceeding leg length remains a significant challenge due to a tendency for deep reinforcement learning approaches to converge on high-impact, unsafe behaviors. This paper introduces APEX-Learning Adaptive High-Platform Traversal for Humanoid Robots-a system that enables robust and stable platform traversal through the composition of learned, full-body maneuvers. Central to APEX is a ‘ratchet progress’ reward that encourages contact-rich, goal-directed movement, coupled with a policy distillation strategy for seamless skill transitions. Demonstrated on a 29-DoF robot, APEX achieves zero-shot sim-to-real traversal of 0.8 meter platforms-over 114% of leg length-raising the question of how such adaptive behaviors can be further generalized to complex, real-world environments.
Navigating Complexity: The Challenge of Adaptive Locomotion
Conventional locomotion control systems frequently encounter difficulties when navigating the irregularities of real-world terrains and responding to unexpected external forces. These systems, often meticulously designed for specific, predictable environments, struggle to maintain stability and efficiency when confronted with uneven ground, slippery surfaces, or sudden impacts. The inherent rigidity of these pre-programmed responses limits their adaptability; a robot expertly traversing a flat laboratory floor may falter dramatically when introduced to a rocky, outdoor landscape. This limitation stems from the difficulty in accurately modeling the complex interactions between a robot’s actuators, its sensors, and the constantly changing environmental conditions, requiring significant computational power and often resulting in delayed or inadequate responses to disturbances. Consequently, achieving truly robust and versatile locomotion demands a paradigm shift towards more flexible and reactive control strategies.
Current robotic locomotion systems frequently encounter limitations when transitioning beyond carefully controlled laboratory settings. Many established control algorithms demand significant manual adjustments – a process of painstaking parameter tuning – to achieve even moderate performance on varied terrains. This reliance on human intervention not only proves time-consuming and costly but also severely restricts a robot’s ability to operate autonomously in unpredictable environments. More critically, these methods often demonstrate poor generalization; a controller successfully tuned for one surface may falter dramatically when faced with even slight variations, such as changes in friction or the introduction of obstacles. This lack of adaptability presents a major hurdle in deploying robots for real-world tasks, where consistent and reliable locomotion across diverse and unforeseen landscapes is paramount.
Successfully navigating challenging terrain requires robots to master high-platform traversal – effectively stepping onto surfaces as tall as 114% of their leg length – a feat demanding a departure from conventional control strategies. Existing locomotion systems frequently falter when faced with such obstacles, necessitating painstaking manual adjustments for each new environment or exhibiting limited generalization capabilities. Research indicates that a novel approach centered on learning and adaptive control is crucial, allowing robots to dynamically adjust their gait and maintain stability while traversing these elevated platforms. This necessitates algorithms capable of predicting terrain interactions, preemptively adjusting foot placement, and responding in real-time to unforeseen disturbances, ultimately enabling truly robust and agile movement across complex landscapes.

APEX: A Learned Foundation for Agile Locomotion
APEX employs Deep Reinforcement Learning (DRL) to develop control policies for robotic locomotion across elevated platforms. This approach allows the robot to learn complex traversal maneuvers through trial and error, maximizing rewards associated with successful platform negotiation. The DRL framework utilizes neural networks to approximate optimal policies, enabling the robot to generalize learned behaviors to novel terrain and platform configurations. Training is conducted in simulation, with policies then transferred to a physical robot for real-world validation. The system’s learning process is driven by a reward function designed to incentivize forward progress, stability, and efficient use of energy during platform traversal.
The APEX framework employs a two-stage process to optimize robot locomotion policies. Initially, a deep reinforcement learning agent directly learns a traversal policy through interaction with the environment. Subsequently, this complex policy is distilled into a smaller, more efficient network. This distillation process transfers knowledge from the larger network – capable of complex behaviors – to a simplified network suitable for real-time control on the robot’s onboard hardware. This two-stage approach improves both the performance, enabling successful traversal, and the computational efficiency, reducing the demands on the robot’s processing resources.
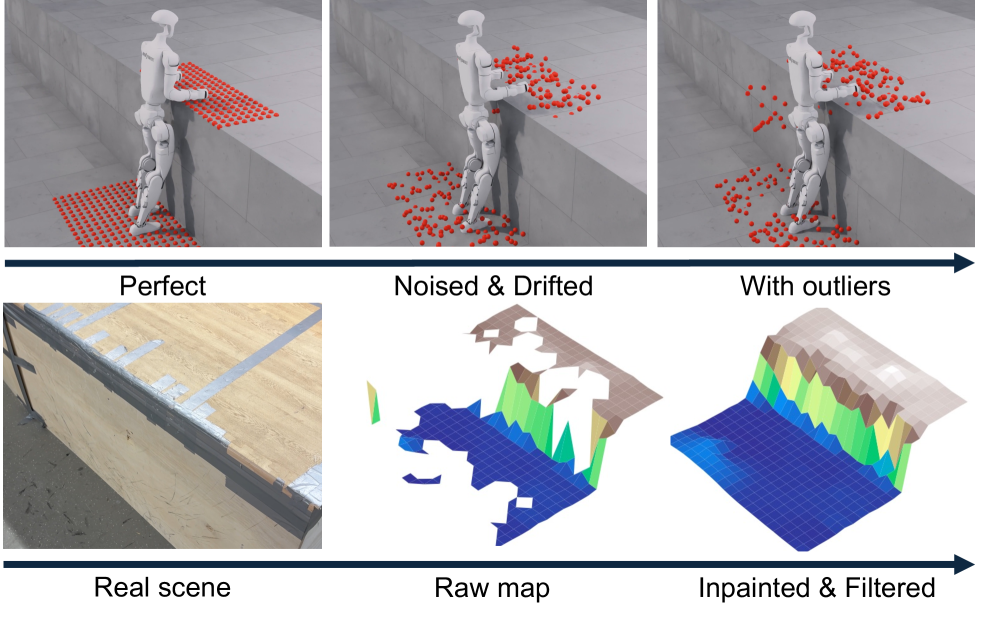
APEX employs LiDAR-based elevation mapping to create a real-time representation of the surrounding terrain, facilitating robust navigation across uneven surfaces. This system generates a heightmap of the environment, allowing the robot to accurately perceive platform edges and surface irregularities. The resulting data informs the robot’s trajectory planning, enabling successful traversal of platforms up to 0.8 meters in height and adaptation to variations in platform geometry and ground conditions. The LiDAR data is processed to identify navigable space and potential obstacles, contributing to the stability and success rate of the robot’s movements.
Dense Supervision: Guiding Learning with Incremental Progress
The Ratchet Progress Reward function operates by continuously monitoring the agent’s best achieved progress towards the task objective. This is implemented by storing the maximum task progress attained up to any given point in time. Subsequently, the reward signal is derived from the change in this best-so-far progress; specifically, the reward is positive only when the agent surpasses its previous best performance. This mechanism provides a dense reward signal, offering feedback at each step and effectively guiding the learning process by incentivizing incremental improvements beyond established benchmarks. The function’s reliance on relative progress, rather than absolute position, allows for robust learning even in scenarios with variable task completion times or stochastic environments.
The Ratchet Progress Reward function demonstrates heightened efficacy in Contact-Rich Maneuvers due to the inherent demands of these tasks. Contact-rich manipulation-such as inserting a peg into a hole, or reorienting an object within a cluttered environment-requires a high degree of positional precision and coordinated actuator control. The Ratchet Progress Reward provides dense, incremental feedback based on the best-so-far progress towards the maneuver’s goal, effectively shaping the agent’s policy towards successful contact establishment and maintenance. This is critical because sparse rewards in these scenarios often fail to provide sufficient signal for learning, while the continuous feedback from the Ratchet Progress Reward facilitates faster convergence and improved performance in complex, contact-dependent tasks.
Velocity-Free Supervision addresses instabilities commonly found in reinforcement learning algorithms reliant on velocity-dependent reward functions. Traditional methods often penalize or reward based on an agent’s velocity, which can introduce noise and oscillations during learning, particularly in continuous control tasks. By removing velocity as a factor in the reward signal, the system focuses solely on positional progress and task completion. This simplification promotes more stable learning dynamics and allows the agent to converge to optimal policies more reliably, ultimately contributing to the observed nearly 100% success rate in simulation environments when combined with the Ratchet Progress Reward function.
![Training with the proposed reward function yields more stable contact points [latex] [/latex]and lower peak forces and torques compared to a distance-based reward, as demonstrated by keyframe analysis and time-series data of contact forces and joint torques.](https://arxiv.org/html/2602.11143v1/x7.png)
Bridging Reality: From Simulation to Robust Physical Performance
Addressing the pervasive challenge of transferring skills learned in simulation to the complexities of the real world, the research leveraged Domain Randomization within the Isaac Sim platform. This technique deliberately varied simulation parameters – including textures, lighting, friction, and even the robot’s mass – during the training process. By exposing the learning algorithm to a wide spectrum of randomized environments, the resulting control policy becomes inherently more robust and less sensitive to the inevitable discrepancies between the simulated and real-world conditions. This approach effectively forces the policy to learn features that are generalizable, rather than overfitting to a specific, idealized simulation, ultimately paving the way for successful deployment on physical robots.
Domain randomization functions on the principle that a policy trained across a sufficiently varied simulation will be more adaptable to the unpredictable nuances of the real world. By systematically altering parameters within the simulated environment – such as textures, lighting, friction, and even the robot’s own mass and joint properties – the training process effectively creates a ‘distribution’ of possible realities. This forces the policy to learn features robust enough to perform well regardless of these variations, rather than overfitting to a single, idealized simulation. Consequently, the resulting control policy develops an inherent capacity for generalization, allowing it to transfer seamlessly to the physical robot despite discrepancies between the simulated and real environments, ultimately leading to more reliable and adaptable robotic systems.
Policies cultivated through simulation demonstrate a remarkable capacity for real-world application, as evidenced by successful deployment on a Unitree G1 humanoid robot. Rigorous testing, encompassing 1000 trials, yielded a 95.4% success rate, validating the effectiveness of the training methodology. Further refinement involved knowledge distillation, creating a ‘student’ policy that not only maintained comparable performance to the original ‘teacher’ policy, but also offered potential for reduced computational demands and faster execution-a crucial step towards practical, efficient robotic control.

The pursuit of robust locomotion, as demonstrated by APEX, benefits from a focus on essential elements. The system’s success hinges on distilling complex interactions – full-body manipulation combined with locomotion – into a manageable policy. This mirrors a mathematical elegance; unnecessary complexity obscures understanding. G.H. Hardy observed, “The essence of mathematics lies in its simplicity.” APEX embodies this principle; the ‘ratchet progress’ reward and policy distillation aren’t flourishes, but mechanisms to strip away extraneous variables, achieving reliable high-platform traversal through focused, essential movements. The study demonstrates that true advancement isn’t about adding more, but refining what already exists.
Where the Path Leads
The demonstration of reliable high-platform traversal, while a necessary step, merely clarifies the continuing chasm between simulated proficiency and robust real-world deployment. The current reliance on deep reinforcement learning, even with refinements like ‘ratchet progress’ rewards and policy distillation, necessitates a critical examination of sample efficiency. A system that demands extensive interaction to master a single, constrained task hints at a fundamental limitation – a lack of generalization. Future work must confront the question of how to imbue these embodied agents with something approaching intuitive physics, allowing them to extrapolate beyond the explicitly trained domain.
The emphasis on full-body manipulation, though promising, introduces a complexity that invites instability. Each additional degree of freedom demands exponentially greater control authority, and the current approach, while functional, appears brittle. A parsimonious solution – one that achieves comparable results with fewer actuated joints – would represent a significant advancement. The pursuit of ever-more-humanoid forms should not overshadow the potential of functionally equivalent, yet mechanically simpler, designs.
Ultimately, the challenge is not simply to create robots that can traverse platforms, but to create robots that understand why a particular traversal is possible, and can adapt to unforeseen obstacles without recourse to brute-force retraining. The illusion of intelligence is easily manufactured; genuine autonomy, however, demands a deeper reckoning with the principles of embodied cognition.
Original article: https://arxiv.org/pdf/2602.11143.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-13 05:21