Author: Denis Avetisyan
New research demonstrates how robots can learn to anticipate the consequences of their actions using advanced video prediction, enabling more complex and reliable manipulation tasks.

Dream4manip integrates high-fidelity video world models with in-context learning for fast, long-horizon robotic control and error correction.
Anticipating the consequences of action remains a core challenge in robotic manipulation, yet current systems often lack the predictive capability needed for robust performance. This limitation motivates the work presented in ‘Say, Dream, and Act: Learning Video World Models for Instruction-Driven Robot Manipulation’, which introduces a framework-Dream4manip-that integrates high-fidelity video world models with fast action learning. By predicting future states and correcting spatial inconsistencies in generated videos, the approach enables precise, long-horizon robotic manipulation. Could this integration of predictive modeling and learned correction ultimately unlock truly autonomous and adaptable robotic systems?
The Inevitable Cascade: Long-Horizon Prediction in Robotic Systems
Robotic systems designed for complex tasks frequently encounter limitations when dealing with long-horizon manipulation – scenarios demanding predictions and planning across extended timeframes. Unlike simple, immediate actions, these tasks, such as assembling intricate objects or preparing a meal, require a robot to anticipate the consequences of each movement over many steps. This presents a significant challenge because even minor inaccuracies in initial state estimation or action prediction can compound over time, leading to substantial errors and ultimately, task failure. Consequently, traditional approaches often struggle to maintain reliable performance in tasks that necessitate foresight and strategic planning beyond the immediate future, hindering the deployment of robots in more complex and dynamic environments.
The core challenge in long-horizon manipulation arises from the compounding of errors inherent in sequential prediction. As a robot attempts to anticipate the consequences of its actions over an extended timeframe, even minor inaccuracies in initial state estimation or action prediction rapidly accumulate. This is not simply a matter of adding up small errors; rather, these inaccuracies propagate and amplify through each successive predicted state, creating a diverging trajectory from reality. Consequently, the robot’s internal representation of the future becomes increasingly unreliable, hindering its ability to effectively plan and execute complex, multi-step tasks. Maintaining consistent accuracy across lengthy sequences requires exceptionally robust state estimation techniques and predictive models, a significant hurdle for current robotic systems.
The core difficulty in long-horizon manipulation arises from the inability of current robotic systems to construct sufficiently accurate internal world models. These models, crucial for predicting the consequences of actions over extended sequences, frequently falter as the complexity of the task increases. Existing methods often rely on simplified representations or struggle to account for the inherent uncertainties of the physical world, leading to compounding errors in prediction. Consequently, a robot might confidently plan a series of actions that appear logical in the immediate term, yet ultimately fail because the predicted future state diverges significantly from reality. Building a robust and reliable predictive capacity-one that can effectively simulate multiple potential outcomes-remains a significant challenge in achieving truly adaptable and intelligent robotic behavior.
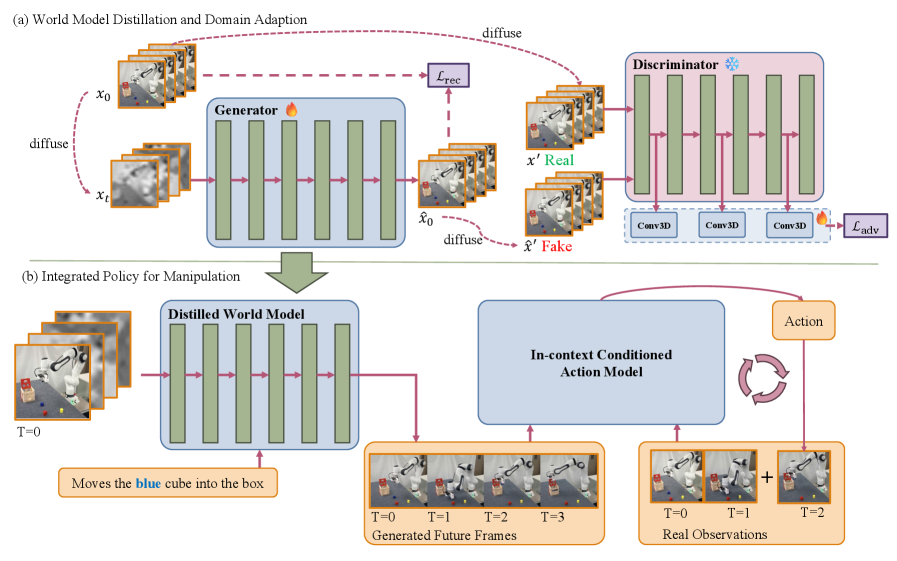
Dream4manip: Imagining Futures for Robotic Control
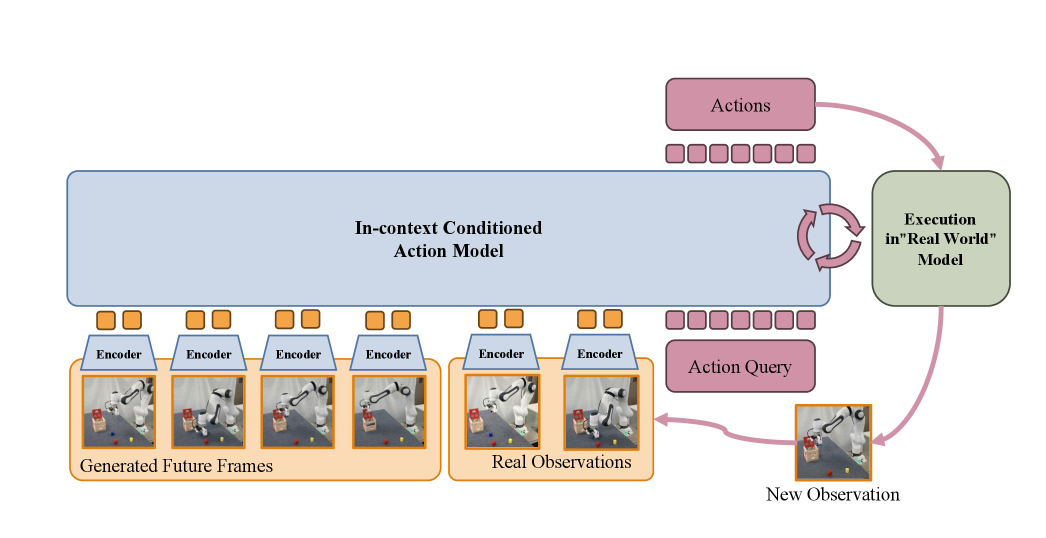
Dream4manip utilizes a combined architecture of video world models and in-context conditioned action models to facilitate predictive capabilities in robotic systems. The video world model generates simulations of potential future states based on current observations and anticipated actions. These simulated trajectories are then fed into the in-context conditioned action model, which learns to predict likely outcomes. This integration allows the robot to ‘imagine’ the consequences of its actions before execution, effectively creating an internal predictive system for improved planning and control. The action model is conditioned on the visual data generated by the world model, enabling the robot to anticipate and adapt to dynamic environments.
Dream4manip addresses spatial inaccuracies present in video world models by leveraging imagined trajectories as training examples for action prediction. The system generates multiple future states based on potential actions, and these simulated sequences are used to refine the prediction of subsequent robot movements. Specifically, the framework employs these imagined trajectories to correct for discrepancies between the predicted visual outcomes of an action and the actual observed outcomes, effectively improving the accuracy of action forecasting and allowing the robot to better anticipate and react to its environment. This approach reduces reliance on the absolute accuracy of the world model by focusing on relative changes and visual consistency within the imagined sequences.
Dream4manip improves the reliability and flexibility of robotic manipulation by utilizing simulated visual data to inform action prediction. Traditional action prediction methods are susceptible to errors caused by inaccuracies in the robot’s perception of the environment and its internal world model. By training on visually-predicted states generated through simulation, Dream4manip creates a more resilient prediction system, reducing dependence on precise real-time sensory input. This approach enables the robot to anticipate outcomes and adjust actions even when faced with noisy or incomplete data, ultimately enhancing performance in complex and dynamic environments.
Cosmos-Predict2: Sculpting Visual Futures
Cosmos-Predict2 functions as the core visual prediction engine within our world model, utilizing a diffusion-based generative approach. This methodology involves iteratively refining randomly initialized data to produce coherent video sequences. The system is designed to forecast future states based on observed inputs, generating visually plausible continuations of dynamic scenes. By leveraging the principles of diffusion modeling, Cosmos-Predict2 avoids the mode collapse issues common in other generative models, resulting in higher fidelity and more realistic video predictions. The architecture is specifically optimized for generating temporally consistent frames, crucial for simulating believable and interactive environments.
Adversarial distillation is implemented to optimize the inference speed and computational efficiency of Cosmos-Predict2. This technique involves training a smaller “student” model to replicate the sampling process-the iterative refinement from noise to image-of the larger, pre-trained “teacher” model. The student learns to mimic the teacher’s trajectory in latent space through an adversarial loss, effectively distilling the knowledge of the complex diffusion process into a more compact and readily deployable model. This allows for faster generation of predicted frames without significant loss of visual quality, reducing computational demands during inference.
The predictive capability of Cosmos-Predict2 is improved through the implementation of a latent-space adversarial loss function. This allows the model to achieve high-fidelity predictions with a reduced number of denoising steps during inference. Quantitative evaluation demonstrates performance of 238.09 on the Frechet Video Distance (FVD) metric, a Structural Similarity Index (SSIM) of 0.84, and a Peak Signal-to-Noise Ratio (PSNR) of 26.82, all achieved using only 10 denoising steps.

Validation and Performance on the LIBERO Benchmark
Dream4manip’s capabilities were subjected to a comprehensive evaluation utilizing the LIBERO benchmark, a standardized suite designed to rigorously test robotic manipulation skills across diverse scenarios. This benchmark assesses a robot’s ability to perform complex tasks, ranging from simple object retrieval to intricate assembly procedures, providing a quantifiable measure of its dexterity and adaptability. The evaluation spanned a wide spectrum of manipulation challenges, ensuring a robust and unbiased assessment of the system’s performance. Results demonstrate Dream4manip’s proficiency in handling variations in object pose, lighting conditions, and task complexity, ultimately highlighting its potential for real-world applications requiring reliable and versatile robotic manipulation.
Rigorous evaluation of Dream4manip utilizing the LIBERO benchmark reveals substantial performance gains across critical robotic manipulation metrics. Specifically, improvements were consistently observed in Task Completion Rate (TCR), which measures the robot’s ability to successfully finish a task, and Interaction Success Rate (ISR), reflecting the quality of the robot’s physical interactions with objects. Furthermore, the Referring Success Rate (RSR) – quantifying the robot’s capacity to accurately interpret and respond to language-based instructions – also showed marked enhancement. These combined advancements culminated in an overall success rate of 98.2% on the LIBERO benchmark, demonstrating a significant leap forward in robotic manipulation capabilities when compared to currently available methodologies.
A novel metric, Embodiment Consistency (EC), was developed to assess the fidelity between a robotic system’s predicted actions and the visual realism of generated video sequences. This measure goes beyond traditional task success rates by quantifying how well the robot’s anticipated physical execution-its posture, movements, and interactions-aligns with the depicted video. High EC scores indicate that the generated visuals convincingly portray the robot performing the intended manipulation, suggesting a stronger connection between the planning stage and the simulated outcome. By evaluating EC alongside metrics like Task Completion Rate and Interaction Success Rate, researchers gain a more holistic understanding of a robot’s ability to not only achieve a goal, but to do so in a physically plausible and visually coherent manner, paving the way for more robust and reliable robotic systems.
Toward Adaptable and Robust Robotic Intelligence
The Dream4manip system demonstrates a significant advancement in robotic manipulation through its capacity for frame-rate-agnostic prediction. This innovative capability allows the system to accurately anticipate the outcomes of actions regardless of how quickly or slowly they are executed, a critical feature for real-world applications where execution speeds can vary due to factors like hardware limitations or changing environmental conditions. By effectively decoupling prediction from specific frame rates, Dream4manip achieves a heightened level of robustness; the system isn’t easily thrown off by variations in speed, enabling it to generalize learned behaviors across a wider range of scenarios. This adaptability is crucial for deploying robots in dynamic and unpredictable environments, as it ensures consistent and reliable performance even when faced with unexpected changes in operational tempo.
Successfully translating predictive models from simulation to real-world robotics requires careful consideration of the discrepancies between the two environments – a process known as domain adaptation. This work addresses this challenge by integrating techniques designed to align the learned world model with the complexities of robotic manipulation. Specifically, the system employs methods to reduce the gap between simulated and real-world sensor data, accounting for factors like lighting, texture, and physical properties. By effectively bridging this ‘reality gap’, the predictive capabilities of the model become significantly more reliable when deployed on a physical robot, leading to improved performance in tasks involving object grasping, placement, and manipulation within unstructured environments. This adaptation isn’t simply about correcting errors; it’s about enabling the robot to generalize its understanding of physics and object interactions to novel, real-world situations.
The development of robotic systems capable of executing intricate, multi-step manipulation tasks represents a significant leap towards true automation. Current robotic manipulation often struggles with unforeseen variations and the need for precise timing, limiting their effectiveness in dynamic real-world settings. This research demonstrates a pathway toward overcoming these limitations, envisioning robots that can reliably plan and execute complex sequences of actions – like assembling intricate objects or preparing meals – even when faced with unexpected disturbances or changes in speed. By fostering greater adaptability and robustness, this work doesn’t simply improve existing robotic capabilities; it unlocks the potential for robots to perform previously unattainable tasks, expanding their utility across diverse fields, from manufacturing and logistics to healthcare and domestic assistance, ultimately enabling more seamless human-robot collaboration.
The pursuit of robust robotic systems, as demonstrated by Dream4manip, inherently acknowledges the inevitable decay of predictive accuracy over extended horizons. This framework’s integration of video world models and in-context learning isn’t merely about achieving impressive demonstrations of manipulation; it’s about building systems capable of gracefully handling the increasing uncertainty that time introduces. As Edsger W. Dijkstra observed, “It’s not enough to have good ideas; you must also have good implementation.” Dream4manip embodies this principle, translating theoretical advancements in video prediction and diffusion models into a tangible system capable of sustained, long-horizon control. The framework’s corrective mechanisms, continuously refining generated videos, function as a form of ‘temporal chronicle,’ ensuring the system doesn’t succumb to the accumulating errors that plague simpler predictive models.
What Lies Ahead?
The pursuit of predictive systems inevitably encounters the limits of simulation. Dream4manip, by integrating learned world models with robotic action, represents a refinement – not a transcendence – of this constraint. Every failure is a signal from time; the discrepancies between predicted and actual states are not merely errors, but echoes of the system’s incomplete understanding of the unfolding present. The elegance of diffusion models lies in their generative capacity, yet fidelity, even at high resolutions, cannot wholly compensate for the inherent unpredictability of physical systems.
Future iterations will likely focus on the distillation of knowledge – not just from video, but from the robot’s embodied experience. Refactoring is a dialogue with the past; each correction to the world model must acknowledge the history of its errors. The current framework excels at short-horizon control; the true challenge remains the extension of this capability to truly long-horizon tasks, where the cumulative effect of even minor inaccuracies can lead to catastrophic divergence.
Ultimately, the success of this line of inquiry hinges not on the creation of a perfect simulator, but on the development of systems capable of graceful degradation. A system that anticipates its own limitations, and can adapt accordingly, will age more elegantly than one striving for an unattainable perfection. The question is not whether the model can predict the future, but whether it can learn to accept – and even leverage – the inherent uncertainty of time itself.
Original article: https://arxiv.org/pdf/2602.10717.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-12 20:51