Author: Denis Avetisyan
A new framework breaks down human demonstrations into manageable steps, paving the way for more intuitive robot collaboration.
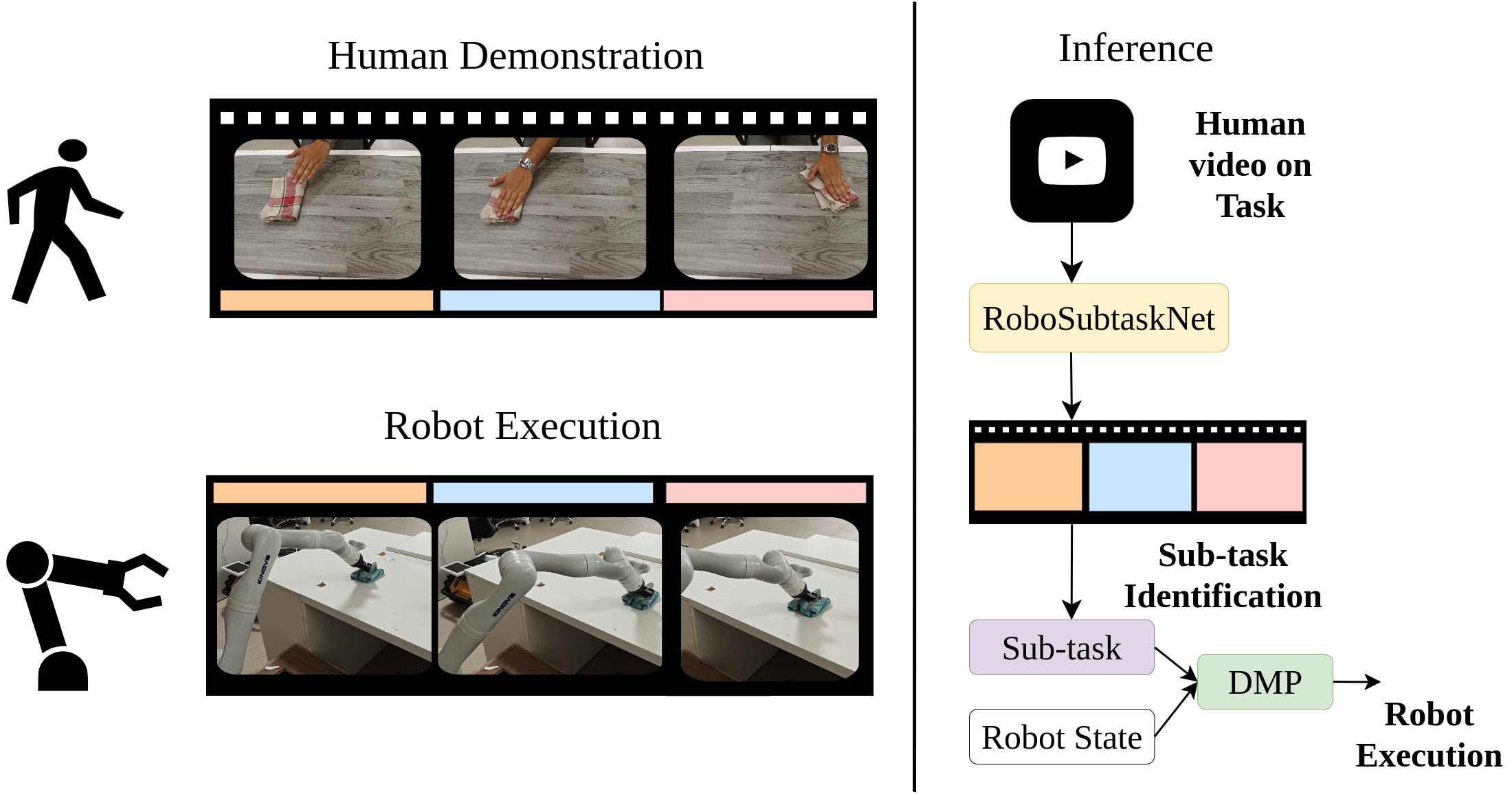
This work introduces RoboSubtaskNet, a deep learning approach to temporal sub-task segmentation for improved human-to-robot skill transfer in real-world manipulation tasks.
Achieving safe and intuitive human-robot collaboration requires bridging the gap between high-level human demonstrations and precise robot control. This is addressed in ‘RoboSubtaskNet: Temporal Sub-task Segmentation for Human-to-Robot Skill Transfer in Real-World Environments’, which introduces a novel framework for temporally segmenting and classifying fine-grained sub-tasks from untrimmed video, directly enabling robot execution. By coupling attention-enhanced spatio-temporal features with a modified MS-TCN and a new dataset-RoboSubtask-the authors demonstrate superior performance on both existing benchmarks and real-world robotic manipulation tasks, achieving approximately 91.25% task success. Could this approach unlock more adaptable and collaborative robots capable of learning directly from human expertise in complex, real-world environments?
The Illusion of Understanding: Beyond Activity Labels
Current approaches to activity recognition frequently categorize actions into broad classes – for example, ‘cooking’ or ‘cleaning’ – which proves insufficient for directing the nuanced movements of a robot. This reliance on coarse-grained temporal segmentation overlooks the critical details of how an activity unfolds. A robot needing to assist with cooking doesn’t just require the knowledge that someone is cooking; it needs to understand specific sub-actions like ‘chopping vegetables’ or ‘stirring the pot’, and the precise sequence and manner in which these are performed. Without this granular understanding, robots remain limited in their ability to provide truly helpful and adaptive assistance, struggling to synchronize with human actions or respond effectively to variations in task execution. Bridging this gap requires a shift towards methods that can dissect activities into their constituent parts, offering a more detailed and actionable representation for robotic control.
Effective human-robot collaboration hinges on a nuanced understanding of action, extending beyond simple activity recognition. Current systems often categorize actions – identifying what a person is doing, such as “making coffee” – but lack the ability to discern how that action is executed. This finer-grained analysis, encompassing the specific techniques, speed, and precision employed, is crucial for robots to translate observed human behavior into executable sub-tasks. For instance, differentiating between a careful, deliberate pour versus a quick, casual one allows a robotic assistant to anticipate needs and adjust its actions accordingly – perhaps offering a spill-proof lid or preparing a larger cup. Ultimately, robots must interpret not just the goal of an action, but the method used to achieve it, enabling truly adaptive and collaborative interactions.
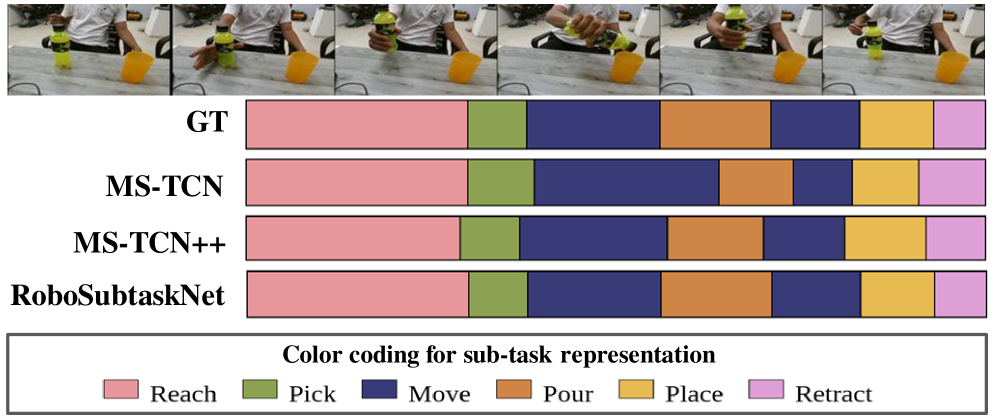
Deconstructing Complexity: The Architecture of Anticipation
RoboSubtaskNet addresses the challenge of translating human actions into robot-executable commands by decomposing complex activities into a hierarchical structure of sub-tasks. This decomposition allows for a more granular mapping between human demonstrations and robot control, enabling the robot to understand and replicate actions at a detailed level. The framework doesn’t simply map entire actions; instead, it identifies constituent sub-tasks – such as grasping, moving, or placing – which are then individually learned and executed. This hierarchical representation improves the robot’s ability to generalize to novel situations and adapt to variations in human performance, as it can recombine known sub-tasks to achieve new goals. The resulting structure facilitates a more robust and flexible human-robot interface compared to methods that treat actions as monolithic units.
Inflated 3D ConvNets (I3D) are utilized within RoboSubtaskNet to extract spatiotemporal features from human action sequences. I3D networks are 2D convolutional neural networks inflated to 3D, enabling them to directly process video data and capture both spatial and temporal information. This approach avoids the need for manual feature engineering or the use of optical flow, which can be computationally expensive and prone to errors. By learning features directly from raw video frames, I3D provides a robust and efficient representation of human actions, improving the accuracy and generalization capability of the RoboSubtaskNet framework. The network architecture allows for the capture of motion patterns and subtle cues critical for understanding complex activities.
The modified Temporal Convolutional Network (MS-TCN) employed within RoboSubtaskNet addresses the limitations of standard TCNs in capturing long-range dependencies crucial for segmenting complex human activities. This MS-TCN utilizes dilated convolutions with varying dilation rates across multiple parallel branches. These branches process the input sequence at different temporal resolutions, enabling the network to effectively aggregate information from distant frames without the vanishing gradient problems common in recurrent networks. The outputs of these branches are then fused to produce a refined segmentation, allowing the system to accurately identify sub-task boundaries even within prolonged and intricate action sequences.

Refining the Signal: Attention and the Art of Prediction
Attention Fusion integrates RGB image data with optical flow features to enhance sub-task recognition capabilities. This process dynamically weights the contribution of each feature type based on its relevance to the current frame and predicted task. Specifically, the model learns to attend to regions in the RGB input that contain key objects or visual cues, while simultaneously leveraging the motion information provided by the optical flow to understand object interactions and predict future states. This adaptive weighting scheme allows the model to prioritize the most informative visual cues, improving performance in dynamic environments and enabling more accurate identification of robotic sub-tasks.
The training process employs a composite loss function consisting of Cross-Entropy Loss, Temporal Smoothing Loss, and Transition-Aware Loss to refine sub-task sequence prediction. Cross-Entropy Loss minimizes the difference between predicted and ground truth sub-task labels. Temporal Smoothing Loss regularizes the predicted sequence, encouraging consistency between adjacent frames and reducing erratic transitions. Transition-Aware Loss specifically penalizes implausible state transitions based on a learned transition matrix derived from the training data; this ensures the predicted sequence adheres to realistic robotic action patterns and improves overall sequence plausibility. The combined effect of these losses results in both accurate sub-task classification and coherent, feasible action sequences.
The Multi-Scale Temporal Convolutional Network (MS-TCN) architecture incorporates Fibonacci dilation to enhance the modeling of short-horizon transitions in robotic execution. This dilation scheme utilizes a sequence of dilation rates based on the Fibonacci sequence (1, 2, 3, 5, 8…), allowing the network to capture temporal dependencies at exponentially increasing scales. Specifically, this approach enables the model to effectively process information from recent time steps – critical for tasks requiring precise timing and quick reactions. By incorporating this varying receptive field, the MS-TCN can better predict immediate future states and improve the accuracy of robotic control, especially during complex sequential actions.
Evaluation on the RoboSubtask dataset yielded an F1@50 score of 94.2%, indicating a high degree of accuracy in recognizing and sequencing robotic sub-tasks. The F1@50 metric specifically measures the harmonic mean of precision and recall at a temporal granularity of 50 frames, prioritizing accurate predictions within a short-horizon timeframe relevant to real-time robotic control. This performance level demonstrates the effectiveness of the combined optimizations – including attention fusion, the multi-scale temporal convolutional network (MS-TCN) architecture with Fibonacci dilation, and the tailored loss functions – in addressing the challenges of robotic sub-task recognition and sequential planning.
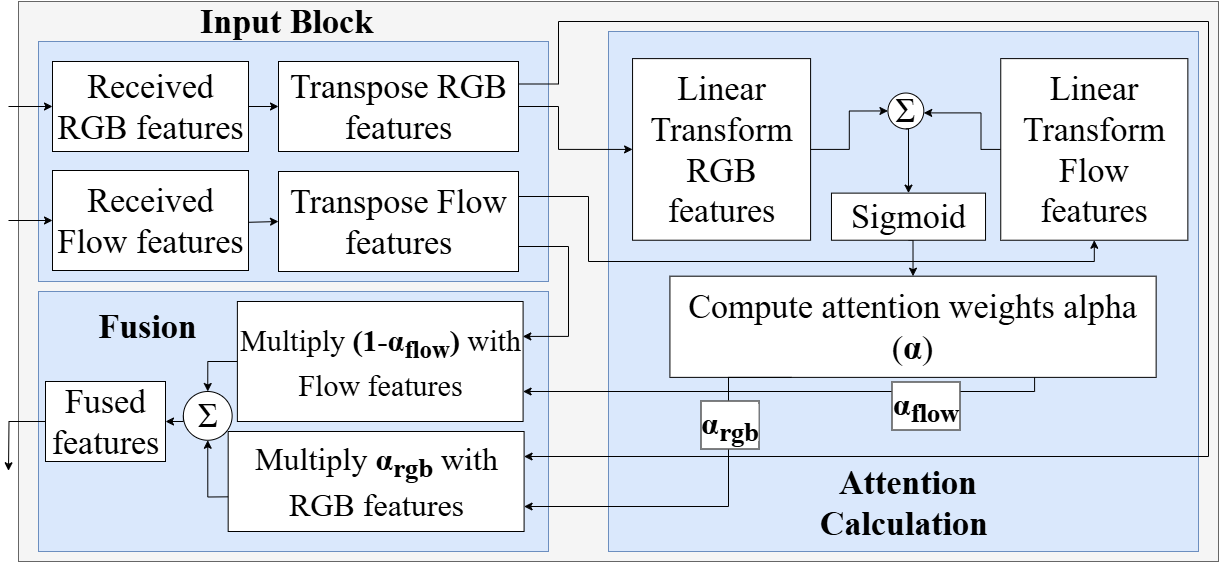
Beyond Mimicry: The Illusion of Collaborative Intelligence
To enable fluid human-robot interaction, the system leverages Dynamic Movement Primitives (DMPs) to convert complex, segmented tasks into seamlessly executed robotic motions. Rather than relying on rigid, pre-programmed sequences, DMPs allow the robot to learn and generalize movements, resulting in trajectories that appear more natural and adaptable. These primitives encode the desired motion in terms of a few key parameters, enabling the robot to modify its actions based on real-time feedback and changing circumstances. This approach moves beyond simple point-to-point control, producing smooth accelerations and decelerations that mimic human movement, ultimately fostering a more intuitive and collaborative experience. The resulting robot actions aren’t simply correct; they are executed with a fluidity that is essential for effective teamwork with a human partner.
The robotic system leverages a Cartesian coordinate space to govern the movements of the Kinova Gen3 manipulator, enabling a level of precision crucial for complex tasks. By defining trajectories in terms of x, y, and z coordinates, rather than joint angles, the system simplifies motion planning and enhances accuracy. This approach bypasses the intricacies of inverse kinematics, allowing for direct specification of desired end-effector positions and orientations. Consequently, the Kinova Gen3 can execute intricate manipulations – such as precise pick-and-place operations or controlled pouring – with minimal error and a fluid, natural quality. The utilization of Cartesian space not only streamlines control but also facilitates intuitive programming and real-time adjustments, making the system highly adaptable to dynamic environments and varied task requirements.
The robotic system’s consistent performance relies heavily on the implementation of proportional control, a feedback mechanism that continuously adjusts the robot’s movements to reduce the difference between its intended and actual position. This technique doesn’t simply aim for a target; it actively corrects for deviations, much like a driver subtly steering to stay within a lane. By proportionally responding to even minor errors, the system minimizes overshoot and oscillation, resulting in smooth, precise, and remarkably stable execution of tasks. This continuous refinement not only enhances accuracy but also creates a responsive feel, allowing the robot to adapt to subtle changes in its environment or unexpected disturbances, ultimately building a reliable foundation for effective human-robot collaboration.
The system’s capacity for accurate action reconstruction is demonstrably high, as evidenced by its 98.5% Edit Score on the challenging RoboSubtask dataset. This metric quantifies the system’s ability to correctly identify and sequence the individual steps within a complex task, effectively mirroring human performance in interpreting and replicating robotic actions. A score nearing perfection suggests a robust understanding of task semantics and a reliable method for translating observed movements into a structured, actionable representation – a critical capability for truly seamless human-robot collaboration and adaptable robotic assistance. The result indicates the framework doesn’t merely register motions, but comprehends the intent behind them, enabling it to anticipate and respond effectively to nuanced human direction.
Demonstrating a move beyond theoretical robotics, the developed system achieved notable success in practical, everyday tasks. Specifically, experiments revealed a 95% success rate for table cleaning and pick & place operations, indicating a high degree of reliability in object manipulation and workspace organization. Performance remained strong with pick & pour tasks, attaining a 90% success rate, and even extended to the more complex pick & give scenario, achieving 85% success. These results collectively underscore the system’s potential for real-world application, suggesting its viability as a collaborative partner in household or industrial settings where adaptable and dependable robotic assistance is required.
The pursuit of seamless human-robot collaboration, as detailed in this work on temporal sub-task segmentation, feels less like construction and more like tending a garden. The system doesn’t build understanding; it cultivates it from the raw data of human action. Each segmented sub-task represents a carefully pruned branch, allowing the robot to grasp the essential flow of manipulation. As Vinton Cerf observed, “Any sufficiently advanced technology is indistinguishable from magic.” This rings true; the ability to distill complex human demonstrations into executable robot actions appears magical, yet it’s rooted in the patient observation and algorithmic refinement of each temporal segment. The inherent fragility of such systems – the inevitable ‘cache’ of failures – underscores the need for continual learning and adaptation, mirroring the unpredictable nature of any living ecosystem.
What Lies Ahead?
The segmentation presented here, while a step towards more fluid human-robot collaboration, merely reframes the central difficulty. It does not solve the problem of skill transfer, but rather displaces it. The system now requires a robust interpreter for these segmented sub-tasks – a demand that introduces a new class of failure modes, predictably. Monitoring these interfaces becomes the art of fearing consciously; each successful handoff is a temporary reprieve, not a lasting solution.
Future work will undoubtedly focus on expanding the scope of recognized actions. However, a more pressing question lies in the system’s capacity to misinterpret. That is not a bug – it’s a revelation. True resilience begins where certainty ends. The framework should not strive for perfect action recognition, but for graceful degradation, for the ability to infer human intent even amidst ambiguity, and crucially, to signal its own uncertainty.
Ultimately, the goal isn’t to build a system that flawlessly mimics human skill, but one that anticipates, and even expects, its own limitations. The true measure of progress won’t be the number of tasks completed, but the elegance with which the system navigates its inevitable failures, and the insights those failures reveal about the complex ecosystem of human-robot interaction.
Original article: https://arxiv.org/pdf/2602.10015.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-12 05:46