Author: Denis Avetisyan
Researchers are developing methods to teach AI systems to understand the underlying principles of physics by learning directly from the data generated by simulations.
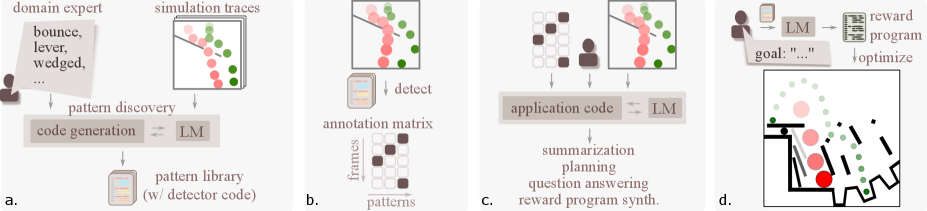
This work introduces a technique for extracting high-level patterns from simulation traces, improving language models’ ability to perform physical reasoning tasks like summarization, question answering, and reward program synthesis.
Despite advances in artificial intelligence, enabling robust physical reasoning remains a challenge for language models trained primarily on observational data. This limitation motivates the work presented in ‘Discovering High Level Patterns from Simulation Traces’, which introduces a method for distilling raw simulation logs into a concise, annotated representation of high-level patterns like collisions and stable support. By synthesizing programs to map simulation data to these activated patterns, we demonstrate improved natural language reasoning about physical systems and facilitate the generation of effective reward programs from natural language goals. Could this approach unlock more intuitive and effective human-agent interaction in complex, physics-based environments?
Bridging the Gap: Simulation as the Foundation for General Intelligence
Conventional artificial intelligence systems often falter when confronted with tasks demanding an understanding of the physical world – things like predicting how objects will behave, navigating unpredictable terrains, or manipulating tools effectively. This limitation stems from a reliance on explicitly programmed rules or datasets lacking the nuanced complexity of real-world physics and dynamics. While proficient in narrow, well-defined problems, these systems struggle with the ambiguity and constant change inherent in dynamic environments, exhibiting a brittle quality when faced with even slight deviations from their training data. The difficulty isn’t necessarily a lack of computational power, but rather a deficit in intuitive physics – the effortless, subconscious reasoning about how things move and interact that humans develop from infancy. Consequently, achieving true general intelligence requires moving beyond static datasets and embracing systems capable of learning and adapting within richly simulated, physically realistic environments.
The pursuit of artificial general intelligence (AGI) increasingly centers on the development of agents capable of learning and adapting within simulated environments. These virtual worlds provide a safe and scalable platform to train AI systems on tasks demanding complex reasoning and physical intuition-skills that prove challenging for traditional AI approaches. By iteratively interacting with a simulation, an agent can acquire knowledge about its environment, refine its decision-making processes, and generalize learned behaviors to novel situations. This process, akin to embodied learning, allows the agent to build an internal model of the world and predict the consequences of its actions, fostering the flexibility and adaptability considered hallmarks of genuine intelligence. Consequently, advancements in simulation technologies and agent-based learning are seen as pivotal steps toward bridging the gap between narrow, task-specific AI and the broader capabilities of AGI.
Successfully navigating complex simulated environments requires artificial intelligence to not only perceive its current state but also to accurately anticipate the consequences of potential actions. This demands more than simple pattern recognition; agents must develop robust predictive models of the world, effectively simulating possible futures to evaluate the efficacy of different choices. These models aren’t merely about predicting what will happen, but understanding why, factoring in physical constraints, object interactions, and the inherent uncertainty of dynamic systems. Consequently, research focuses on techniques like [latex] \text{Model Predictive Control (MPC)} [/latex] and reinforcement learning algorithms that prioritize learning these predictive capabilities, enabling agents to select actions that maximize long-term success, even when faced with unforeseen circumstances. The ability to build and utilize such predictive models represents a critical step toward creating truly adaptable and generally intelligent systems.

From Specification to Behavior: Synthesizing Reward Programs
The use of natural language to specify desired behaviors for AI agents provides a significant advantage in adaptability and usability. Traditional methods of programming agent behavior often rely on explicitly coded rules or complex mathematical functions, requiring substantial expertise and limiting ease of modification. Natural language interfaces allow users to communicate goals in a human-readable format, abstracting away the complexities of low-level implementation. This approach facilitates rapid prototyping and iterative refinement of agent behavior, as changes can be expressed intuitively without requiring recoding of underlying algorithms. Furthermore, it opens the possibility of non-expert users directly influencing and controlling AI agent actions, increasing accessibility and broadening potential applications.
Reward Program Synthesis addresses the challenge of translating abstract, natural language objectives into executable reward functions for artificial intelligence agents. This process is non-trivial as it requires decomposing high-level goals into a sequence of quantifiable sub-tasks and associated numerical rewards. Successful synthesis necessitates the formalization of desired behaviors, the identification of relevant state variables, and the assignment of appropriate reward signals based on agent performance. The complexity arises from the need to account for potential ambiguities in the natural language specification and to ensure the resulting reward function incentivizes the intended behavior without unintended consequences or reward hacking. Techniques employed within Reward Program Synthesis include formal methods, program analysis, and machine learning approaches to automate or assist in this translation process.
Employing a Domain Specific Language (DSL) for reward program creation facilitates a more efficient workflow by abstracting away low-level implementation details and allowing users to express reward structures using terminology relevant to the specific application domain. This DSL-driven approach reduces the complexity associated with manually coding reward functions. Complementing the DSL is the utilization of a Pattern Library, a curated collection of pre-defined, reusable reward program components addressing common behavioral goals. The Pattern Library serves as a knowledge repository, providing tested and validated solutions that can be readily integrated into new programs, reducing development time and enhancing the reliability of the resulting AI agent behavior. These patterns encapsulate best practices and proven techniques for incentivizing desired actions, thereby accelerating the reward program synthesis process.
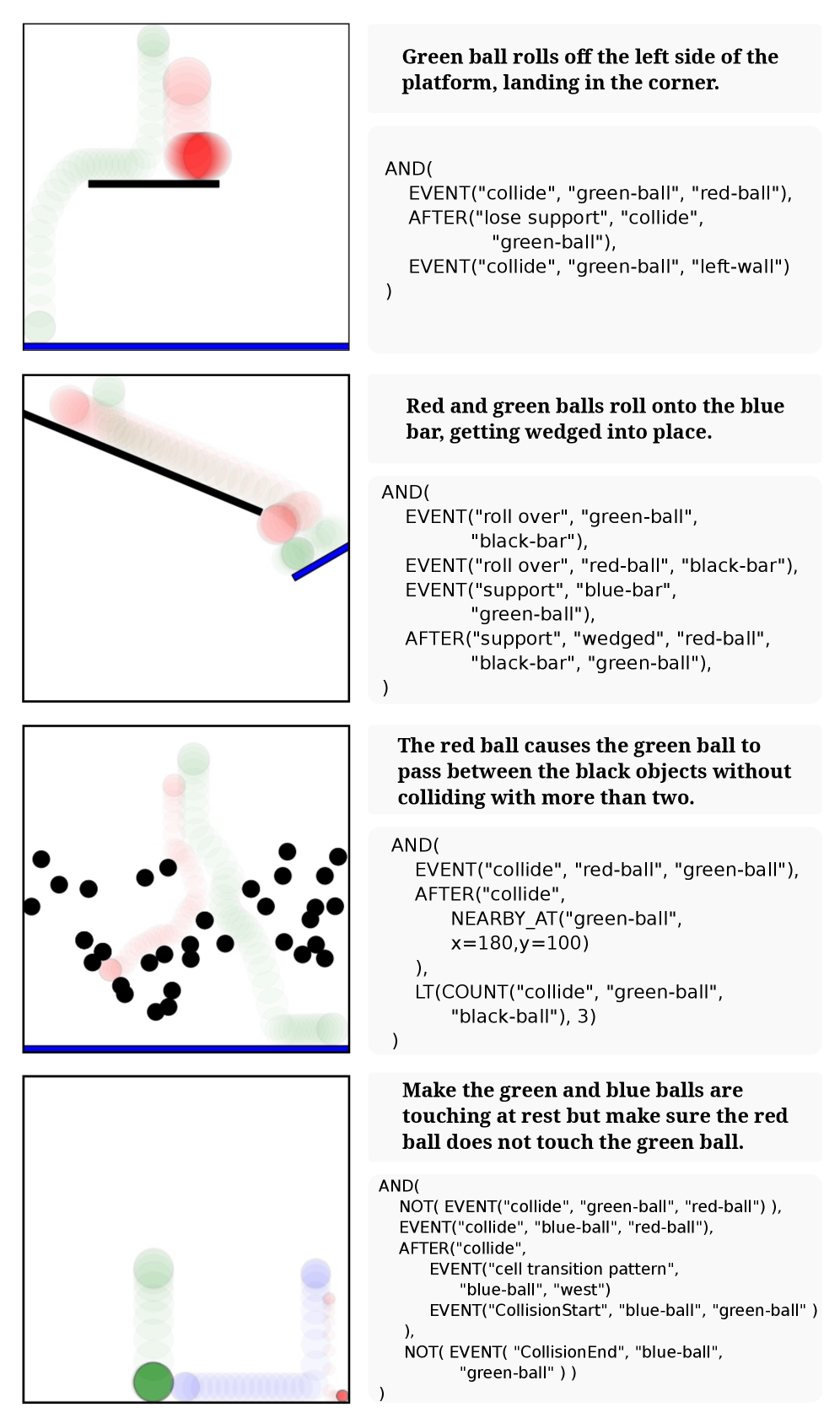
Revealing Structure: Discovering Patterns Within Complex Simulations
The conversion of raw data generated by complex simulations into actionable intelligence presents significant challenges due to the high dimensionality and noise inherent in these systems. Successfully extracting meaningful patterns is critical for enabling intelligent behavior as these patterns represent the underlying relationships and dynamics governing the simulated environment. Without effective pattern identification, the data remains largely unusable for tasks requiring prediction, generalization, or decision-making. This process often necessitates sophisticated algorithms capable of filtering noise, identifying correlations, and abstracting key features from the extensive datasets produced by simulations, ultimately facilitating the development of agents and systems that can effectively learn and adapt within these environments.
Pattern Discovery utilizes Evolutionary Programming, a computational technique where a population of candidate patterns is iteratively refined through selection and variation. Each pattern is evaluated based on its ability to accurately predict or represent recurring sequences and relationships within the simulation data. Patterns demonstrating higher predictive power are ‘selected’ for reproduction, with slight ‘mutations’ introduced to create new candidate patterns. This process, analogous to biological evolution, continues over multiple generations, driving the population towards increasingly accurate and relevant pattern identification. The resulting patterns are not pre-defined; instead, they emerge directly from the data itself, allowing for the discovery of previously unknown relationships and enabling adaptive behavior in complex systems.
Annotated Simulation Traces are enhanced through the integration of patterns identified via Evolutionary Programming, providing contextual information beyond the raw simulation data. This enrichment facilitates improved performance in downstream tasks, specifically demonstrated by gains on the Phyre benchmark. The annotations detail recurring sequences and relationships discovered within the simulation data, allowing subsequent algorithms to leverage these pre-identified structures. This reduces the computational burden of re-discovering these patterns and allows for more efficient problem-solving within the Phyre task suite, which assesses the ability to generalize learned behaviors to novel situations.
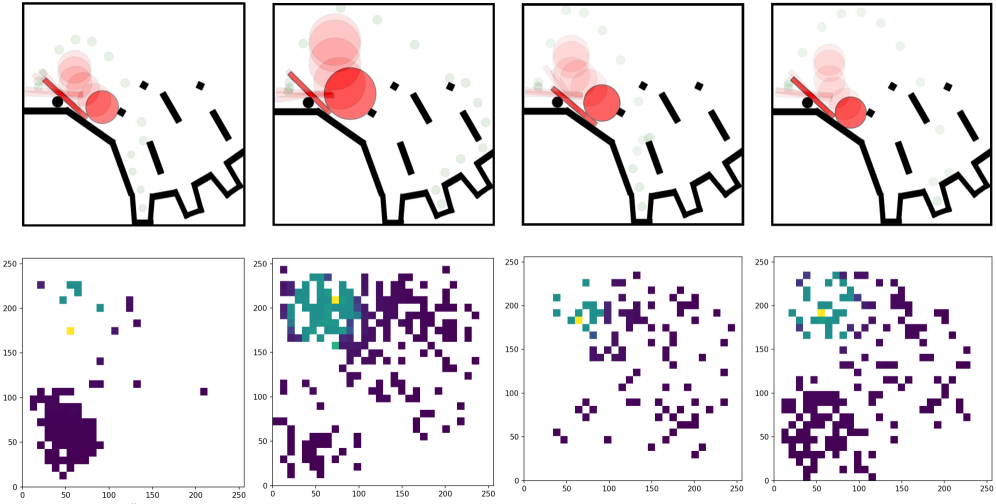
Beyond Observation: Towards Deeper Understanding of Agent Behavior
The progression from passively watching an agent’s actions to actively interpreting why those actions occur represents a significant leap in artificial intelligence research. Traditionally, behavioral observation provides data points, but remains limited in its capacity to reveal underlying cognitive processes. However, by enriching these behavioral traces with detailed annotations-identifying goals, intentions, and the rationale behind each step-researchers can move beyond description to genuine reasoning. This annotated data doesn’t merely record what happened, but constructs a narrative of how and why, enabling systems to infer the agent’s internal state and anticipate future behavior. Consequently, this shift facilitates the development of AI that doesn’t simply react to stimuli, but demonstrates a level of understanding previously unattainable through observation alone.
The advent of annotated traces unlocks the potential for sophisticated cognitive tasks beyond mere behavioral observation. Specifically, systems can now engage in meaningful question answering and summarization regarding an agent’s actions, effectively probing the underlying reasoning. Instead of simply recording what an agent did, these techniques allow researchers to ascertain why, by analyzing the trace data to answer targeted inquiries about the agent’s goals, strategies, and knowledge. Summarization capabilities, in turn, distill complex sequences of actions into concise representations of the agent’s overall behavior, revealing key patterns and insights that would otherwise remain hidden. This ability to interrogate and condense an agent’s operational history represents a significant leap towards truly understanding its internal processes and decision-making logic.
The ability to discern underlying physical principles from observed patterns significantly elevates an agent’s capacity for prediction and problem-solving. By identifying recurring relationships between actions, objects, and outcomes, systems can move beyond memorization to genuinely understand how the world operates. This enhanced ‘physical reasoning’ isn’t merely about recognizing what happened, but inferring why it happened, and crucially, anticipating what will happen next. Consequently, question answering systems, when grounded in these discovered patterns, demonstrate markedly improved accuracy; instead of retrieving information, they can logically deduce answers based on a robust internal model of physics, even when faced with novel scenarios or incomplete data. The effect is a transition from superficial responses to insightful explanations, enabling more reliable and adaptable artificial intelligence.

Automated Pattern Generation: The Future of Agent Development
The FunSearch methodology represents a novel approach to agent development by leveraging the capabilities of Large Language Models (LLMs) to automatically generate ‘pattern detectors’. Rather than relying on hand-designed reward functions or painstakingly crafted behavioral rules, FunSearch prompts an LLM to create code – these pattern detectors – that identify advantageous states within an environment. These detectors then serve as interim rewards, guiding the agent’s learning process and accelerating the discovery of effective strategies. This automation streamlines the process of prototyping different behavioral approaches, allowing for rapid experimentation and potentially unlocking solutions that might be overlooked with traditional methods. The system essentially shifts the burden of reward engineering from human designers to the generative power of the LLM, fostering a more dynamic and efficient exploration of complex problem spaces.
The capacity to swiftly generate and test diverse behavioral strategies represents a significant advancement in artificial intelligence research. Traditionally, designing agents capable of complex tasks required painstaking manual crafting of reward functions and algorithms. However, automated pattern generation streamlines this process, allowing for the creation of numerous potential strategies in a fraction of the time. This accelerated prototyping isn’t merely about speed; it unlocks the exploration of solutions that might have been overlooked through conventional methods. By rapidly iterating through a vast design space, researchers can identify unexpectedly effective behaviors and gain deeper insights into the underlying principles governing intelligent systems, ultimately fostering innovation in areas like robotics, game playing, and autonomous decision-making.
The convergence of large language models and evolutionary programming offers a powerful new approach to artificial intelligence, enabling the creation of agents capable of remarkably efficient learning and adaptation. Traditional reinforcement learning often struggles with ‘sparse reward’ scenarios – environments where feedback is infrequent – hindering progress. However, by leveraging LLMs to synthesize complex reward programs, researchers are effectively providing agents with richer, more informative guidance. This synthesized reward structure, coupled with the exploratory power of evolutionary algorithms, dramatically improves sample efficiency – the amount of experience needed to achieve a desired level of performance. Consequently, agents not only learn faster but also demonstrate a heightened ability to generalize learned behaviors to novel situations, representing a significant step towards more robust and intelligent systems.
![Performance on Q&A and Phyre benchmarks using the Qwen3-VL 8B model improves with library size up to [latex]|\mathcal{P}|=16[/latex], beyond which automatically discovered patterns are leveraged, though Phyre attempts are capped at 55 per scene.](https://arxiv.org/html/2602.10009v1/x4.png)
The pursuit of extracting high-level patterns from simulation traces, as detailed in this work, echoes a fundamental principle of system design. The method presented seeks to distill underlying rules from complex data, revealing the inherent structure governing physical phenomena. This aligns with Kolmogorov’s assertion: “The most important discoveries are those which reveal new structures in familiar things.” The ability to identify these structures – to move beyond mere observation to understanding the generative principles – is crucial for enhancing language models’ reasoning capabilities. Just as a well-designed system’s behavior stems from its underlying architecture, so too does the success of these models rely on their capacity to discern and utilize these hidden patterns. Good architecture is invisible until it breaks, and only then is the true cost of decisions visible.
Future Directions
The presented work, while demonstrating a path toward imbuing language models with improved physical intuition, merely scratches the surface of a far more fundamental challenge. Extracting patterns from simulation traces is, at its core, a problem of dimensionality reduction – an attempt to distill meaningful structure from overwhelming complexity. The current approach, however, implicitly assumes that the relevant patterns are readily apparent within the traces themselves. A more robust system will need to actively seek structure, potentially by formulating and testing hypotheses about underlying physical principles, rather than passively observing emergent behavior.
Furthermore, the reliance on simulation data introduces a critical fragility. Any model trained solely on synthetic traces will inevitably struggle with the inevitable discrepancies between simulation and reality. The true cost of this ‘freedom’ from real-world noise is a brittle understanding, susceptible to even minor deviations. A more promising avenue lies in developing methods for grounding these learned patterns in empirical observation – building a feedback loop that allows the model to refine its understanding through direct interaction with the physical world.
Ultimately, the goal isn’t simply to improve performance on benchmark tasks, but to create systems that can reason about the world with a degree of flexibility and adaptability that rivals, or even surpasses, human intuition. This requires a shift in focus – from optimizing for accuracy on specific problems, to building architectures that prioritize simplicity, scalability, and, crucially, the ability to learn from their own mistakes. Good architecture, after all, is invisible until it breaks.
Original article: https://arxiv.org/pdf/2602.10009.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-11 18:02