Author: Denis Avetisyan
A new framework uses artificial intelligence to automate the process of forming and testing theories, promising faster and more reliable insights in the social sciences.
![Iterative refinement of hypotheses-as demonstrated by exploration of the Congress dataset-not only identifies and rejects spurious correlations, such as the initially accepted but ultimately dataset-skewed phrase “I ask unanimous consent,” but also uncovers conditional sub-hypotheses-like the strengthened link between “Govt. accountability” and opposition party control-that significantly enhance predictive power, achieving a β of 0.48 and a p-value less than [latex]10^{-5}[/latex] for accepted hypotheses like those relating to “Civil rights mentions.”](https://arxiv.org/html/2602.07983v1/x6.png)
This paper introduces ExperiGen, a system leveraging LLM agents and iterative refinement for automated hypothesis generation, statistical validation, and Bayesian optimization from unstructured data.
Traditional social science research is often constrained by the slow, iterative cycle of observation, hypothesis generation, and experimental validation. To address this bottleneck, we present ‘Accelerating Social Science Research via Agentic Hypothesization and Experimentation’, introducing EXPERIGEN-an agentic framework leveraging large language models and Bayesian optimization to automate end-to-end scientific discovery directly from unstructured data. This approach consistently uncovers statistically significant hypotheses that are both more numerous and more predictive than prior methods, with expert review confirming their novelty and potential impact. Could this automated cycle of hypothesis and experimentation fundamentally reshape the pace and rigor of social science inquiry?
Unveiling Knowledge from the Unstructured
The modern information landscape is characterized by a deluge of unstructured data – text, images, audio, and video – representing a largely untapped reservoir of potential knowledge. While these sources often contain valuable insights, transforming them into concrete, testable hypotheses presents a considerable obstacle. Unlike neatly organized databases, unstructured data lacks pre-defined formats, requiring sophisticated analytical techniques to discern meaningful patterns and relationships. The inherent ambiguity and complexity demand methods capable of moving beyond simple keyword searches to understand context, nuance, and underlying concepts, ultimately bridging the gap between raw information and actionable scientific inquiry. This challenge fuels ongoing research into natural language processing, machine learning, and data mining, all aimed at automating the process of hypothesis generation from the vast, sprawling realm of unstructured data.
Historically, deriving meaningful insights from unstructured data has been a laborious process, demanding significant manual intervention in the form of feature engineering. This involves experts painstakingly identifying and coding relevant characteristics within the data – a task not only time-consuming and expensive, but also susceptible to subjective biases that can skew results. The reliance on domain expertise, while valuable, creates a bottleneck, limiting the speed and scope of analysis, and hindering the ability to rapidly test hypotheses across large datasets. Consequently, traditional approaches struggle with scalability and objectivity, making it difficult to consistently extract reliable and generalizable patterns from the ever-growing volume of unstructured information.
Automated Hypothesis Generation with ExperiGen
ExperiGen employs a dual-agent system comprised of the Generator Agent and the Experimenter Agent to automate scientific hypothesis generation and validation. The Generator Agent utilizes Large Language Models (LLMs) to formulate testable hypotheses from provided data, effectively minimizing the need for human-driven hypothesis creation. Subsequently, the Experimenter Agent is responsible for the rigorous validation of these hypotheses through experimentation, leveraging data analysis and statistical methods to determine their accuracy and significance. This integrated approach allows for a closed-loop system where validated findings can inform the Generator Agent, refining future hypothesis proposals and accelerating the research process.
The Generator Agent utilizes Large Language Models (LLMs) to automate the process of hypothesis creation from unstructured data sources, such as text documents and databases. This functionality bypasses the need for extensive manual data analysis and hypothesis formulation by the user. The LLM is prompted to identify potential relationships and patterns within the input data and translate those observations into testable hypotheses, expressed as statements suitable for empirical validation. This automated approach significantly reduces the time and resources required to move from raw data to a defined set of research questions, and allows for exploration of a wider range of potential hypotheses than manual methods typically permit.
Bayesian Optimization within ExperiGen’s Generator Agent functions as a probabilistic framework to navigate the hypothesis space. It employs an acquisition function, balancing the need to explore novel hypotheses with the exploitation of those already demonstrating potential. Specifically, the acquisition function calculates a score for each potential hypothesis, factoring in both the predicted performance – based on prior evaluations – and the uncertainty surrounding that prediction. This allows the Generator Agent to prioritize hypotheses that either exhibit high predicted value or substantial unexplored potential, effectively mitigating the risk of prematurely converging on suboptimal solutions and ensuring a broader search of the hypothesis landscape. The process iteratively refines the search based on experimental results, updating the probability distributions and acquisition function with each evaluation.
Rigorous Validation: Experiments Powered by LLMs
The Experimenter Agent automates validation by first defining the experimental setup, encompassing both feature extraction and the selection of appropriate statistical tests. Feature extraction involves identifying and quantifying relevant variables from the data, preparing it for analysis. The Agent then specifies statistical tests – such as t-tests, ANOVA, or [latex] \chi^2 [/latex] tests – based on the hypothesis being evaluated and the data types involved. This automated process eliminates manual intervention in setting up the validation framework, ensuring consistency and enabling large-scale experimentation. The defined setup includes parameters for each test, such as significance levels (alpha) and desired power, which are used to determine statistical significance and minimize the risk of false negatives.
Generated hypotheses are evaluated for statistical significance using methods including Multivariate Regression and Logistic Regression. Multivariate Regression assesses the relationship between multiple independent variables and one or more dependent variables, allowing for the quantification of each predictor’s unique contribution while controlling for confounding factors. Logistic Regression is employed when the dependent variable is categorical, modeling the probability of a binary outcome based on one or more independent variables; the resulting coefficients indicate the change in the log-odds of the outcome for a one-unit change in the predictor. Both methods provide quantifiable p-values and confidence intervals to determine the likelihood that observed relationships are not due to random chance, thereby supporting or refuting the generated hypotheses with statistical rigor.
The Experimenter Agent leverages a Code Interpreter to perform all computational tasks required for hypothesis validation, including data processing, feature engineering, and statistical analysis. This interpreter executes code in a controlled environment, facilitating both the execution of complex calculations and the application of statistical methods such as [latex]t[/latex]-tests, ANOVA, and regression models. Critically, the use of a Code Interpreter ensures reproducibility by providing a complete record of the computational steps and dependencies. Furthermore, this approach enables scalability, allowing the agent to efficiently process large datasets and execute experiments across numerous hypotheses without requiring manual intervention or specialized infrastructure.
![An iterative refinement cycle refines an initial hypothesis [latex]H_{i,1}[/latex] over [latex]T[/latex] steps by generating candidate hypotheses conditioned on accumulated evidence [latex]\mathcal{M}_{i,j}[/latex], operationalizing them with feature annotations, and statistically evaluating the augmented data to identify hypotheses passing a Bonferroni-corrected significance threshold ([latex]p < \alpha/T[/latex]) for inclusion in a hypothesis bank [latex]\mathcal{H}[/latex].](https://arxiv.org/html/2602.07983v1/x1.png)
Impact and Reliability: A Foundation in Statistical Rigor
The pursuit of meaningful insight from complex data necessitates rigorous statistical validation, a principle central to the design of ExperiGen. Without discerning true signals from random noise, even the most sophisticated analytical tools risk identifying spurious correlations or misleading patterns. ExperiGen inherently addresses this challenge by prioritizing statistical significance throughout its hypothesis generation process, ensuring that discovered relationships are not simply products of chance. This commitment to statistical robustness not only enhances the reliability of ExperiGen’s outputs, but also allows researchers to confidently pursue potentially groundbreaking avenues of investigation, minimizing wasted effort on false positives and maximizing the potential for impactful discoveries. The system’s architecture is fundamentally built on the premise that any proposed relationship must withstand stringent statistical scrutiny before being considered a valid insight.
The foundation of reliable discovery lies in rigorous statistical validation, particularly through assessing statistical significance and controlling the false discovery rate. Statistical significance determines whether an observed relationship is likely a genuine effect or simply due to random chance, while controlling the false discovery rate minimizes the proportion of incorrectly identified relationships amongst all declared findings. This approach is crucial because complex datasets often contain numerous spurious correlations; without careful statistical control, researchers risk pursuing leads that lack true predictive power. By prioritizing these measures, ExperiGen aims to deliver not just a large volume of hypotheses, but a curated set of insights with a high probability of being valid and actionable, reducing wasted effort and accelerating the pace of impactful discovery.
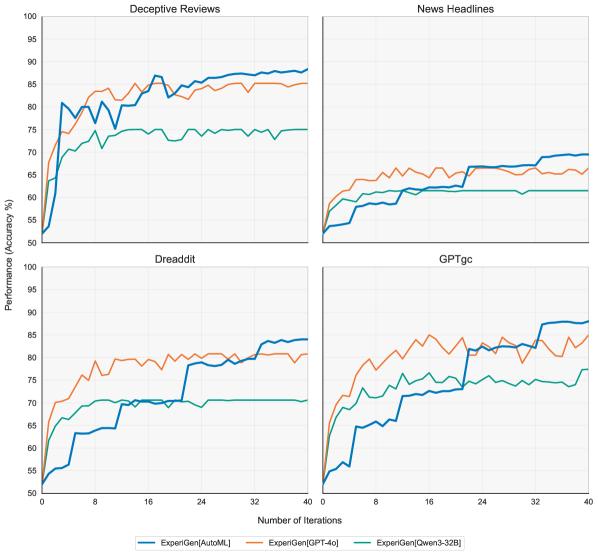
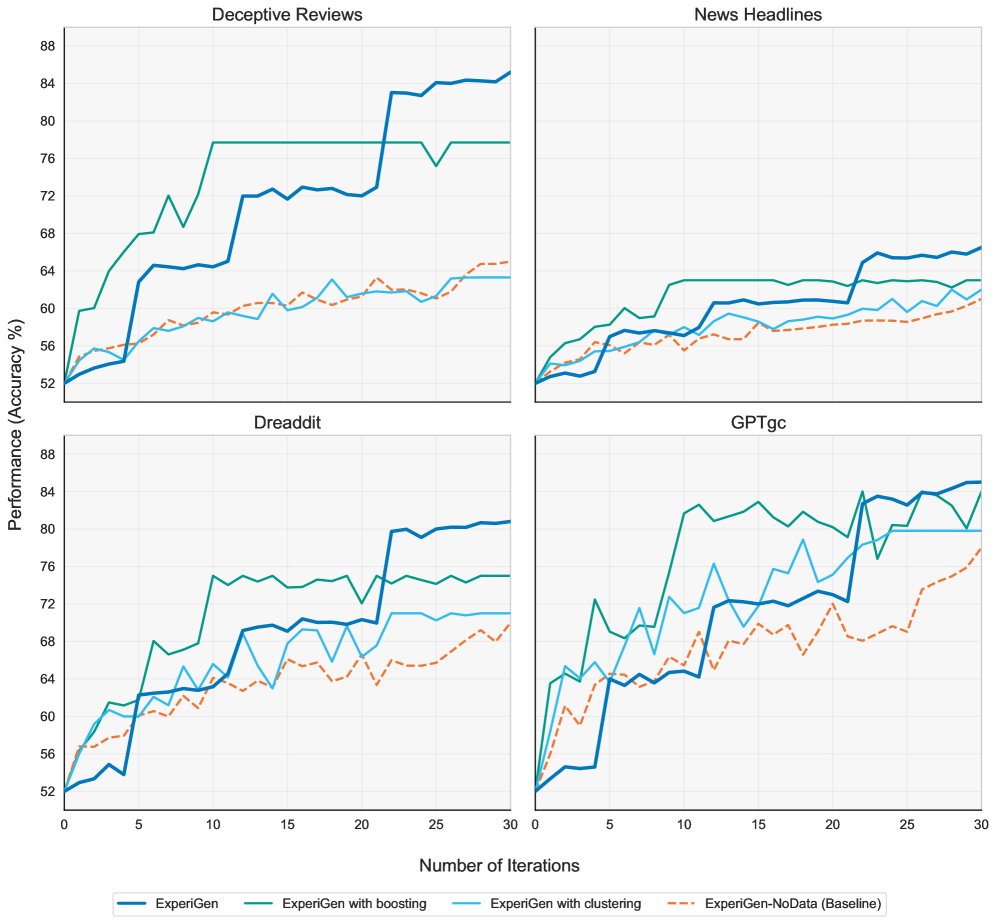
ExperiGen demonstrably advances the field of automated hypothesis generation by consistently identifying a significantly greater number of statistically sound insights. Current methodologies often struggle with the sheer volume of potential relationships within complex datasets, resulting in a limited number of actionable hypotheses. However, ExperiGen, through its innovative algorithms, achieves state-of-the-art performance, discovering between two and four times more statistically significant hypotheses compared to existing approaches. This enhanced capacity isn’t merely about quantity; it represents a substantial increase in the potential for uncovering previously hidden, yet meaningful, connections within data, ultimately accelerating the pace of discovery and informed decision-making across various domains.
Recent application of ExperiGen demonstrated a substantial impact on user engagement, achieving a remarkable +344% increase in form sign-up conversion rates. This improvement wasn’t simply a trend, but a statistically robust finding, evidenced by a p-value of less than 10-6. This exceptionally low p-value indicates an extremely low probability that the observed increase occurred due to random chance, solidifying the effect as a genuine and meaningful outcome. The results highlight ExperiGen’s ability to identify actionable insights that translate directly into measurable improvements in key performance indicators, offering a powerful tool for data-driven optimization.
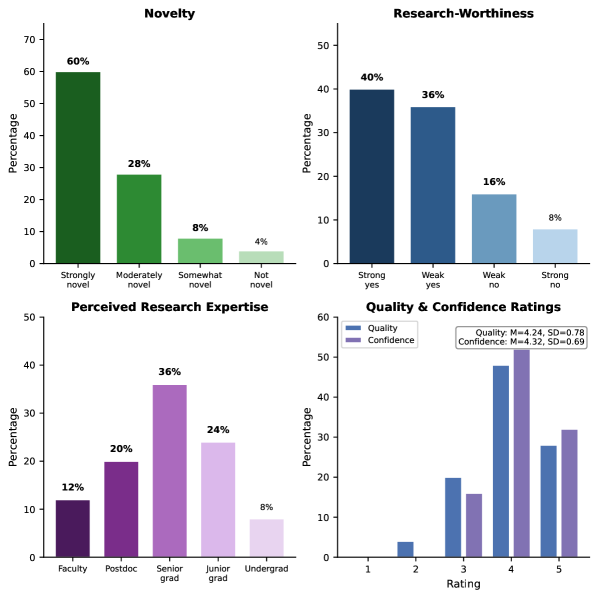
The innovative hypotheses generated by ExperiGen demonstrate a high degree of practical and theoretical value, as assessed by leading domain experts. Evaluations revealed that an impressive 88% of the proposed hypotheses were considered genuinely novel, indicating a capacity to move beyond established knowledge. Furthermore, a substantial 76% of these generated ideas were deemed research-worthy, suggesting a strong potential for driving meaningful scientific inquiry and actionable insights. This high rate of expert validation underscores ExperiGen’s ability not simply to produce a large volume of hypotheses, but to consistently generate ideas that are both original and likely to yield valuable results, offering a significant advantage over conventional approaches to knowledge discovery.
Beyond initial hypothesis generation, rigorous validation is paramount for translating discovery into impactful action, and A/B testing serves as a crucial refinement stage. This comparative approach allows for direct measurement of a hypothesis’s effect on a defined metric, moving beyond statistical significance to demonstrate practical impact. By randomly assigning users to different conditions – a control group and one or more experimental groups – researchers can isolate the effect of a specific variable with high confidence. The results aren’t simply about identifying correlations; they provide concrete, actionable evidence to support – or refute – a proposed intervention, guiding decisions with data rather than intuition and maximizing the likelihood of positive outcomes, such as the observed +344% increase in form sign-up conversion rates achieved when employing this methodology with ExperiGen-derived hypotheses.
The pursuit of scientific advancement, as demonstrated by ExperiGen, necessitates a relentless distillation of complexity. The framework’s iterative refinement process, moving from unstructured data to statistically validated hypotheses, echoes a fundamental principle of elegant problem-solving. Paul Erdős aptly stated, “A mathematician knows a lot of things, but a physicist knows a few.” This speaks to the power of focused inquiry. ExperiGen embodies this focus, automating hypothesis generation and experimentation to yield more robust discoveries, thereby prioritizing density of meaning over exhaustive, undirected exploration. The system’s agentic approach efficiently navigates the landscape of possibilities, much like a well-defined mathematical function-compact, deliberate, and oriented toward a singular, meaningful outcome.
What’s Next?
The presented framework, while demonstrating a capacity for automated hypothesis generation and validation, merely addresses the surface of a deeper challenge. The true limitation isn’t the speed of iteration, but the inherent ambiguity residing within unstructured data itself. ExperiGen efficiently navigates a landscape of noise, yet noise remains. Future work must therefore concentrate on methods for distilling meaning-not simply correlation-from data’s inherent disorder. The pursuit of ‘impactful discovery’ requires, above all, a more rigorous definition of ‘impact’.
Current validation relies heavily on statistical significance, a metric often mistaken for substantive importance. A more fruitful direction lies in incorporating mechanisms for assessing the biological plausibility-or analogous domain-specific coherence-of generated hypotheses. To claim intelligence is not to amass data, but to discard the irrelevant. The challenge is not building more complex agents, but agents capable of ruthless simplification.
Ultimately, the field should shift its focus from automating existing methods to fundamentally re-evaluating the scientific method itself. If the goal is truly accelerated discovery, then the question isn’t how to run more experiments, but how to ask better questions-and, crucially, how to determine which questions are not worth asking.
Original article: https://arxiv.org/pdf/2602.07983.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-10 21:57