Author: Denis Avetisyan
Researchers are tackling the data scarcity problem in home robotics with a new framework for generating comprehensive, behavior-driven synthetic household environments.
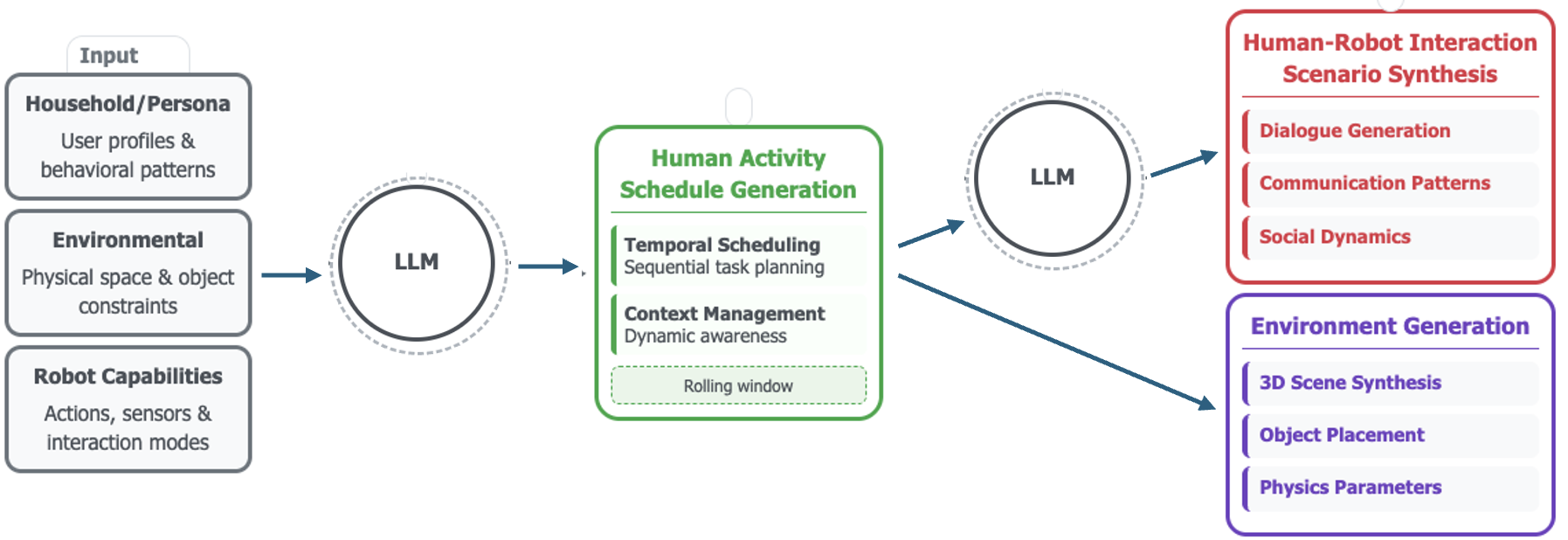
This work introduces a bidirectional coupling approach for generating temporally consistent synthetic data, leveraging environment schematics and persona-driven behavioral models.
Despite advancements in Embodied AI, obtaining sufficiently diverse and large-scale datasets for training interactive agents remains a significant challenge. This paper introduces a novel framework for ‘Realistic Synthetic Household Data Generation at Scale’ that addresses this limitation by bidirectionally coupling human behavioral patterns with detailed environment configurations. Through persona-driven generation and temporal consistency, our approach creates rich, scalable 3D datasets demonstrating strong alignment with real-world data-achieving a cosine similarity of 0.60 with the HOMER dataset-and statistically significant effects from intervention analysis ([latex]p < 0.001[/latex]). Could this framework unlock a new era of robust and efficient development for household smart devices and human-robot interaction?
Deconstructing Reality: The Data Deficit in Robotics
The advancement of robotics, particularly within the complexities of household environments, is fundamentally constrained by a deficit of realistic training data. Robots require vast quantities of information to learn how to navigate, manipulate objects, and interact with surroundings effectively; however, acquiring this data presents a significant challenge. Current datasets often fail to capture the nuanced variations inherent in real-world human behavior and the unpredictable nature of domestic spaces. This limitation hinders a robot’s ability to generalize learned skills, leading to brittle performance when confronted with situations not explicitly represented in its training. Consequently, progress toward truly autonomous and reliable household robots is stalled, as the systems struggle to bridge the gap between controlled laboratory settings and the messy, dynamic reality of everyday life.
Gathering sufficient data to train robots for realistic home environments presents a significant challenge due to the inherent costs and logistical hurdles of traditional methods. Existing approaches often require extensive manual annotation of images and videos, a process that is not only financially demanding but also remarkably slow. More critically, these datasets frequently fail to adequately represent the sheer variety of human actions and interactions within a home – the subtle differences in how individuals prepare a meal, tidy a room, or respond to unexpected events. Capturing this natural behavioral diversity necessitates a scale of data collection that is simply impractical using conventional techniques, ultimately limiting a robot’s ability to adapt and perform reliably in dynamic, unpredictable real-world settings.
The limited availability of comprehensive training data significantly restricts a robot’s capacity to adapt to the unpredictable nature of real-world environments. Without sufficient exposure to the vast spectrum of objects, layouts, and human interactions present in a typical home, robotic systems struggle to generalize learned behaviors beyond carefully controlled laboratory settings. This deficiency manifests as brittle performance – a robot might successfully complete a task in one specific configuration but fail dramatically when presented with even minor variations. Consequently, the ability to reliably perform everyday tasks – such as grasping novel objects, navigating cluttered spaces, or responding to unexpected human requests – remains a substantial challenge, hindering the widespread adoption of household robots.
Addressing the current stagnation in household robotics requires a paradigm shift in data acquisition. Researchers are actively developing synthetic data generation techniques, leveraging advanced simulation and generative modeling to create vast datasets mirroring the complexities of real-world homes and human interactions. These methods move beyond manually collected data by algorithmically producing diverse scenarios – varying object arrangements, lighting conditions, and human behaviors – at a fraction of the cost and time. This artificially generated data is then used to train robotic systems, improving their ability to perceive, reason, and act effectively in unstructured environments. The promise lies in creating robots that can generalize beyond the limitations of narrow training, ultimately achieving seamless integration into daily life and unlocking the full potential of assistive and collaborative robotics.
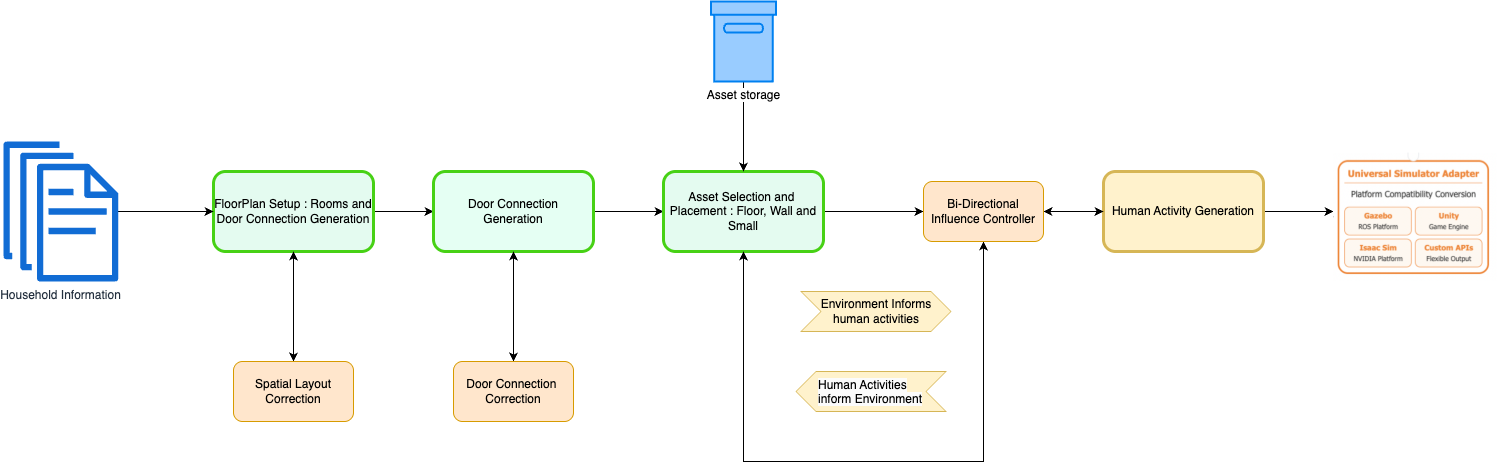
The Dance of Simulation: A Bidirectional Framework
The proposed framework operates by concurrently generating both 3D environments and associated human activity sequences through an iterative refinement process. This simultaneous generation is not sequential; the system does not first create an environment and then populate it. Instead, environment and activity modules operate in parallel, with each informing the development of the other. This parallel processing allows for the creation of complex, internally consistent datasets where the environment plausibly supports and is shaped by the actions of the simulated human agents, and vice versa. The iterative aspect involves repeated cycles of generation, evaluation, and modification of both environment and activity components to improve realism and coherence.
Semantic consistency between simulated environments and agent behavior is critical for successful robot training because discrepancies can lead to negative transfer and reduced performance in real-world deployments. A bidirectional framework addresses this by establishing a feedback loop where generated behaviors influence environmental modifications, and altered environments necessitate behavioral adjustments. This ensures that actions are logically grounded within the scene and that the environment appropriately reacts to those actions, fostering a realistic and coherent simulation. Without this consistency, robots may learn policies that exploit unrealistic simulation artifacts or fail to generalize to situations where the environment deviates from the training data, thus hindering the development of robust and reliable autonomous systems.
The scenario generation process utilizes Large Language Models (LLMs) to produce a wide range of environments and associated human activities. LLMs are prompted with initial conditions and high-level goals, enabling them to output detailed descriptions of scenes, object arrangements, and agent behaviors. This approach allows for the automatic creation of diverse scenarios, varying factors such as time of day, weather conditions, and the number of agents present. The LLM’s capacity for natural language understanding and generation ensures the plausibility of the created scenarios by adhering to real-world constraints and common sense reasoning, thereby reducing the need for manual intervention and increasing the scale of data generation.
The Bidirectional Influence Controller (BIC) operates as a central component facilitating iterative refinement between the environment and activity generation modules. The BIC does not simply pass data unidirectionally; instead, it establishes a feedback loop where changes in the generated environment directly influence subsequent activity planning, and conversely, activity requirements drive modifications to the environment. This is achieved through a series of influence weights assigned to specific features within each module; for example, the presence of an obstacle detected in the environment module can increase the weighting of obstacle avoidance behaviors in the activity planning module. These weights are dynamically adjusted based on validation metrics – such as collision rates or task completion success – to ensure semantic consistency and plausibility between the virtual world and the simulated agent actions.
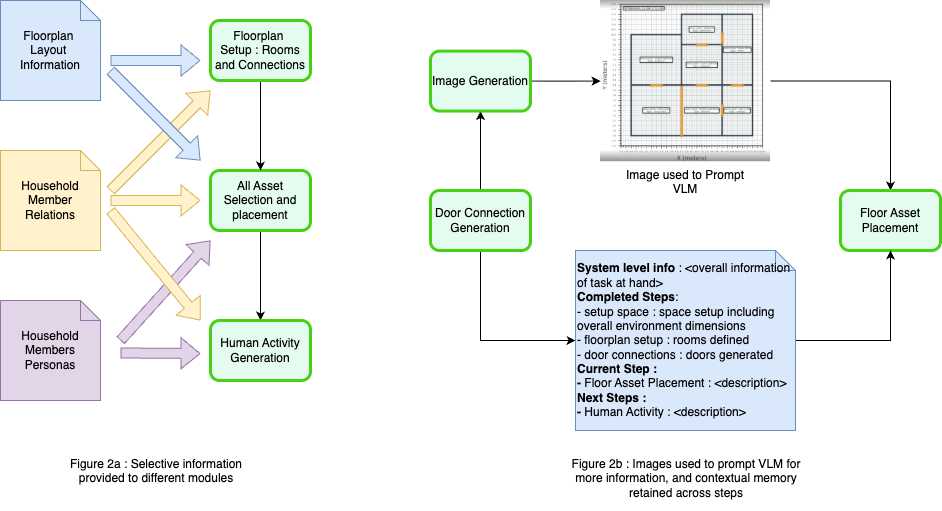
Validating the Illusion: Semantic and Temporal Coherence
Performance of the generative framework was validated by quantifying the Mutual Information between generated 3D environments and the corresponding activity sequences. An initial implementation yielded a Mutual Information score, which was then iteratively refined through parameter adjustments and architectural improvements. The final, refined framework achieved a Mutual Information score of 0.85, indicating a strong statistical dependence between the generated environmental layouts and the plausibility of the actions performed within them. This high score validates the framework’s capacity to generate semantically coherent scenarios where environment and behavior are intrinsically linked.
The Environment Schematic Generator leverages Sentence-BERT (SBERT) embeddings to encode semantic information from Persona Data and Environmental Constraints, creating a vector representation used to guide 3D layout generation. This is coupled with the Contrastive Language-Image Pre-training (CLIP) model, which aligns visual features with the encoded semantic data, ensuring generated environments are both visually realistic and contextually appropriate. Specifically, CLIP facilitates the creation of 3D scenes that correspond to the described persona and adhere to the specified environmental limitations, resulting in coherent and plausible virtual spaces.
The Human Activity Generator functions by producing sequences of actions that adhere to temporal constraints, resulting in plausible behavioral patterns within the simulated environments. This is achieved through algorithmic modeling of action dependencies and durations, preventing physically impossible transitions or actions occurring out of sequence. The generator doesn’t simply produce a random series of actions; instead, it builds coherent activity plans, considering factors such as object manipulation, locomotion, and social interaction-all within the established environmental context. These generated sequences are crucial for evaluating the realism of the overall simulation, ensuring the actions of the simulated agents align with expected human behavior.
Sim-to-Real Validation procedures demonstrate a strong correlation between generated behavioral data and real-world human activity. Specifically, cosine similarity measurements between generated datasets and the Homer-HumanAI dataset yielded a score of 0.603. This metric assesses the alignment of data distributions, indicating the generated activities exhibit characteristics statistically similar to observed human behavior. The validation process confirms the framework’s ability to produce datasets suitable for training and evaluating AI models in scenarios requiring realistic human-environment interaction.
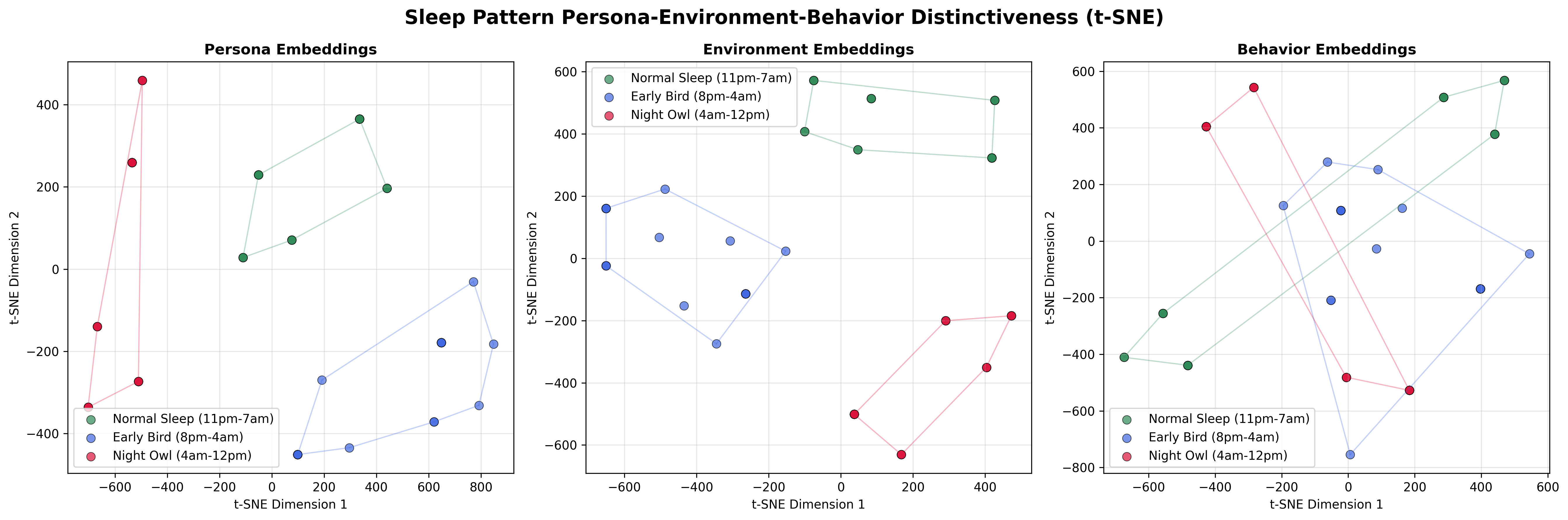
Beyond Simulation: Expanding the Reach of Synthetic Realities
The development of a ‘Universal Simulator Adapter’ represents a significant step towards overcoming limitations in robotic training by facilitating the effortless transfer of data between various simulated environments. This adapter functions as a bridge, allowing synthetic data generated in one simulation to be readily utilized in another, effectively multiplying its value and reducing the need for repetitive data creation. Consequently, robotics applications, ranging from industrial automation to domestic assistance, benefit from a greatly expanded dataset for training and validation, enhancing the robot’s ability to generalize its skills across different scenarios. The adapter’s design prioritizes compatibility and scalability, ensuring it can integrate with both existing and future simulation platforms, thereby maximizing its long-term utility and fostering innovation in the field of robotics.
A significant impediment to creating truly intelligent household robots has long been the limited availability of comprehensive, real-world data needed for effective training. This framework directly tackles this data scarcity problem by providing a means to generate synthetic datasets, effectively augmenting existing information and allowing for the creation of more robust and adaptable robotic systems. By simulating a wider range of scenarios and edge cases than would be practically attainable through real-world data collection alone, the framework enables robots to learn more effectively and generalize their skills to unfamiliar situations. This accelerated learning process promises to drastically reduce the time and resources required to develop robots capable of navigating and interacting with complex, dynamic home environments, ultimately leading to more reliable and helpful robotic assistants.
The capacity to train robots in realistically unpredictable settings represents a significant leap forward in robotics development. Traditionally, robots learned through carefully curated datasets or in rigidly controlled simulations, limiting their ability to adapt to the nuances of real-world environments. This new approach circumvents those limitations by generating synthetic data that captures the inherent variability found in everyday life – changing lighting conditions, cluttered spaces, and unexpected object interactions. Consequently, robots can now be exposed to a far wider range of scenarios during training, fostering the development of robust algorithms capable of handling unforeseen circumstances and executing complex tasks with greater reliability, even when faced with the inherent chaos of a dynamic environment.
The performance of this synthetic data framework is characterized by a robust connection between simulated environments and resulting robotic behaviors, as evidenced by a cosine similarity of 0.72 – a metric indicating strong alignment between the virtual and real-world outcomes. Statistical analysis further confirms the framework’s efficacy; interventions, specifically those related to simulated robot ‘age’, yielded statistically significant effects – with a p-value of less than 0.001. These effects are substantial, reflected in Cohen’s d values ranging from 0.51 to 1.12, indicating a large impact on robotic performance. Consequently, this framework doesn’t simply generate data; it creates a demonstrably effective training ground, poised to accelerate advancements not only in household robotics, but also across a broad spectrum of applications requiring adaptable and intelligent robotic systems.
The pursuit of realistic synthetic data, as detailed in this framework, isn’t merely about mimicking reality-it’s about dissecting it. This work champions a bidirectional coupling of environment and behavior, effectively building a digital twin ripe for manipulation and analysis. Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” This resonates deeply; the system doesn’t create households, it meticulously executes the defined rules governing them, allowing researchers to test the boundaries of those rules and, crucially, understand why they function as they do. The framework’s emphasis on temporal consistency is not about preserving a perfect illusion, but about creating a predictable system for controlled experimentation – a digital reality built for rigorous reverse-engineering.
Beyond the Simulated Home
The generation of synthetic household data, as demonstrated, sidesteps the immediate problem of data acquisition. However, it merely relocates the challenge – from capturing the world to accurately modeling it. Current approaches, even those employing bidirectional coupling, fundamentally rely on pre-defined schematics and persona constraints. The system operates within the bounds of what is already known, however imperfectly. The true test lies in generating genuinely novel behaviors, those not explicitly encoded in the training data or implicit in the underlying assumptions about human interaction.
A natural progression involves loosening those constraints – introducing controlled chaos, allowing for emergent behavior within the synthetic environment. This demands a shift from rule-based systems to those capable of genuine learning and adaptation, mirroring the unpredictability of real-world human actions. The system’s current reliance on explicit persona definitions also presents a limitation; true generality requires the capacity to synthesize individuals from minimal input, inferring behaviors based on contextual cues rather than pre-programmed archetypes.
Ultimately, the best hack is understanding why it worked, and this framework will undoubtedly reveal the subtle biases and simplifying assumptions embedded within its design. Every patch is a philosophical confession of imperfection. The next iteration isn’t about generating more data, but about generating data that actively challenges the model’s own understanding of ‘realistic’ behavior, forcing it to confront the inherent messiness of the world it attempts to simulate.
Original article: https://arxiv.org/pdf/2602.07243.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-10 20:08