Author: Denis Avetisyan
A new framework harnesses the power of AI to streamline complex data analysis in high-energy physics, opening the field to a wider range of researchers.
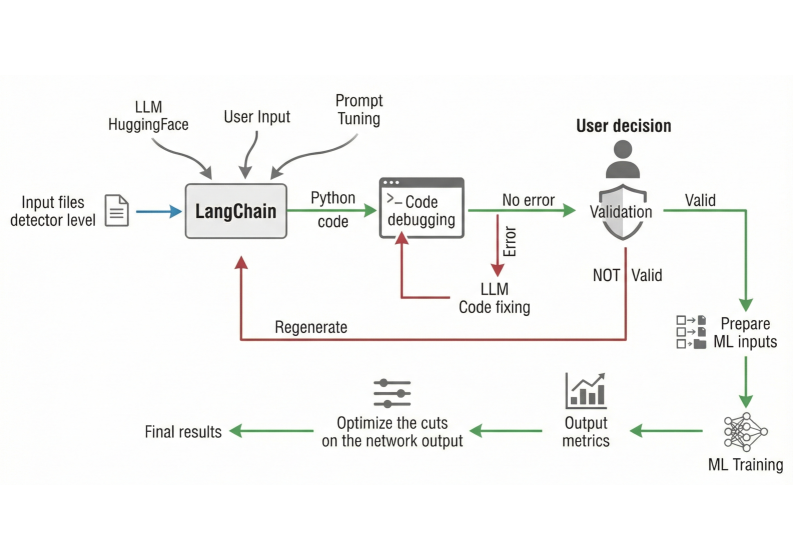
CoLLM leverages large language models to build end-to-end deep learning pipelines for collider physics, improving reproducibility and reducing the need for specialized expertise.
The increasing complexity of collider physics analyses often demands substantial programming and deep learning expertise, creating a barrier to entry for many researchers. To address this challenge, we introduce \textit{CoLLM: AI engineering toolbox for end-to-end deep learning in collider analyses}, a framework leveraging large language models to automate workflows from event selection to deep learning analysis. CoLLM generates physically consistent code and streamlines subsequent analyses through an intuitive graphical user interface, thereby reducing the reliance on specialized technical skills and enhancing reproducibility. Could this approach fundamentally alter the landscape of data analysis in high-energy physics and beyond?
The Rising Tide of Data: A Challenge to Discovery
The sheer scale of data generated by modern collider experiments, such as those at the Large Hadron Collider, presents a formidable computational challenge. Each collision produces a cascade of particles, requiring intensive processing to reconstruct events and identify potentially new phenomena. This analysis isn’t simply a matter of increased computing power; it demands highly specialized expertise in areas like detector physics, particle identification algorithms, and statistical data analysis. Physicists must develop and refine complex software to filter noise, calibrate instruments, and accurately model the underlying physics. Furthermore, the computational cost scales rapidly with the luminosity of the collider and the desired precision of the measurements, often requiring distributed computing resources and innovative algorithmic approaches to manage the data deluge and extract meaningful insights.
Historically, high-energy physics data analysis has been deeply rooted in manually crafted code, a process demanding substantial time and specialized programming skills. Physicists would often build custom software routines to filter, process, and interpret the outputs of complex collider experiments – a task prone to human error, especially given the intricate algorithms and vast datasets involved. This approach, while offering flexibility, suffers from scalability issues; each new experiment or detector configuration frequently necessitates extensive code revisions and re-validation. Consequently, the reliance on manual coding creates a bottleneck in the research pipeline, slowing down discovery and increasing the potential for subtle, yet critical, bugs to propagate through the analysis – ultimately impacting the reliability of scientific findings.
The sheer scale of data generated by modern particle colliders demands a shift towards automated analysis techniques. Each experiment produces petabytes of information – equivalent to years of high-definition video – containing fleeting glimpses of potentially groundbreaking physics. Manually sifting through this deluge is simply impractical; therefore, researchers are increasingly reliant on algorithms and machine learning to identify meaningful signals amidst the noise. These automated systems not only accelerate the discovery process but also enhance the precision of measurements, allowing scientists to probe the fundamental laws of nature with unprecedented detail. The complexity arises not just from the volume of data, but also its multi-dimensional nature – involving thousands of variables per event – requiring sophisticated analytical tools to effectively extract relevant insights and validate theoretical predictions.
CoLLM: A Language for Analysis
The CoLLM framework facilitates automated data analysis by establishing a direct link between natural language requests and the execution of deep learning pipelines. This connection is achieved through a system that accepts analysis specifications expressed in plain language, which are then translated into a series of automated steps including data loading, preprocessing, model selection, training, and evaluation. By removing the need for manual coding of these steps, CoLLM significantly reduces the time and expertise required to perform complex data analysis tasks, enabling faster iteration and broader accessibility to advanced analytical techniques. The framework is designed to support a variety of deep learning models and data formats, providing a flexible platform for diverse analytical needs.
The CoLLM framework employs Large Language Model (LLM) code generation to automate the translation of user-defined analysis requests into functional code. This process minimizes the need for manual scripting and implementation, significantly reducing the effort required to perform data analysis tasks. Specifically, natural language descriptions of desired analyses are processed by the LLM to produce code, currently supporting Python, which can then be directly executed within the CoLLM pipeline. This automated code generation capability accelerates the analytical workflow and allows users to focus on interpreting results rather than code development.
Deterministic decoding within the CoLLM framework enforces consistent code generation from natural language specifications by utilizing a fixed sampling strategy during the LLM’s output token selection process. Unlike probabilistic decoding methods which introduce variability, deterministic decoding – specifically utilizing techniques like greedy decoding or beam search with a fixed beam width – ensures that identical input prompts consistently yield the same code output. Evaluations demonstrate this approach achieves a high degree of reproducibility, critical for scientific rigor and reliable automated analysis pipelines, as variations in code generation are eliminated as a confounding factor in experimental results.
Validating the Pipeline: Ensuring Analytical Integrity
The automated pipeline incorporates the PyFixer module to address potential errors within the generated code. PyFixer functions as an error correction tool, automatically identifying syntactical and logical bugs. Upon detection, PyFixer attempts to rectify these issues through automated code modification, aiming to produce executable and functionally correct code without manual intervention. This integration is intended to improve the robustness and reliability of the automated analysis workflow by mitigating the impact of code-level errors that might otherwise halt or corrupt the analysis process.
Validation plots and cutflow tables are critical components in verifying the accuracy of analysis results generated by the automated pipeline. Validation plots visually assess the distribution of key variables after each processing stage, allowing for identification of unexpected shifts or anomalies that may indicate errors. Cutflow tables provide a quantitative breakdown of event yields at each selection cut, enabling a precise comparison between the automated analysis and established results or expected theoretical predictions. Discrepancies observed in either the plots or tables necessitate investigation of the pipeline’s configuration or the underlying data processing steps to ensure the reliability and correctness of the final analysis outcome.
The automated deep learning pipeline utilizes a multi-model classification approach, integrating an MLP Classifier, a GNN Classifier, and a Transformer Classifier to enhance the robustness and generalization capability of the analysis. This architecture was successfully demonstrated through the complete automation of five benchmark analyses using CoLLM, which generated fully executable code for each. This achievement confirms the pipeline’s ability to autonomously perform complex tasks from code generation to analysis execution, representing a significant step towards end-to-end automation in the field.
Beyond Automation: Towards a New Era of Discovery
The advent of CoLLM represents a significant shift in high-energy physics data analysis, effectively lowering the barrier to entry for complex investigations. Historically, physicists have devoted substantial time and resources to developing and maintaining custom software for data processing and interpretation; CoLLM streamlines this process by offering an intuitive, language-based interface. This simplification isn’t merely about convenience; it allows researchers to dedicate greater cognitive energy to the scientific questions themselves – formulating hypotheses, exploring nuanced data patterns, and ultimately, accelerating the pace of discovery. By abstracting away the complexities of coding and data manipulation, CoLLM empowers physicists to concentrate on the core intellectual challenge of unraveling the universe’s fundamental laws, rather than being constrained by the technical demands of data analysis.
The CoLLM framework distinguishes itself through a highly modular architecture, intentionally designed to facilitate the seamless incorporation of evolving physics models and analytical techniques. This adaptability stems from a separation of core functionalities – data handling, model implementation, and analysis execution – allowing researchers to readily exchange or upgrade individual components without disrupting the entire system. Consequently, as new theoretical advancements emerge or more sophisticated data processing methods are developed, they can be integrated with minimal effort, fostering a dynamic and responsive analytical environment. This plug-and-play approach not only accelerates the pace of scientific inquiry but also promotes collaboration, enabling researchers to easily share and test custom models within a standardized framework, ultimately broadening the scope and impact of their investigations.
The continued development of this framework centers on creating a fully autonomous data analysis pipeline for high-energy physics. This involves not only broadening the system’s existing knowledge of physics concepts and analytical methods, but also incorporating robust data quality assessment protocols. The intention is to move beyond simply executing analyses to having the system intelligently evaluate data integrity, flag potential issues, and even suggest alternative analysis strategies when encountering anomalies. Ultimately, this will culminate in automated result interpretation, allowing the system to synthesize findings and present them in a coherent, physically meaningful way, thereby accelerating the pace of scientific discovery by minimizing manual intervention and maximizing analytical throughput.
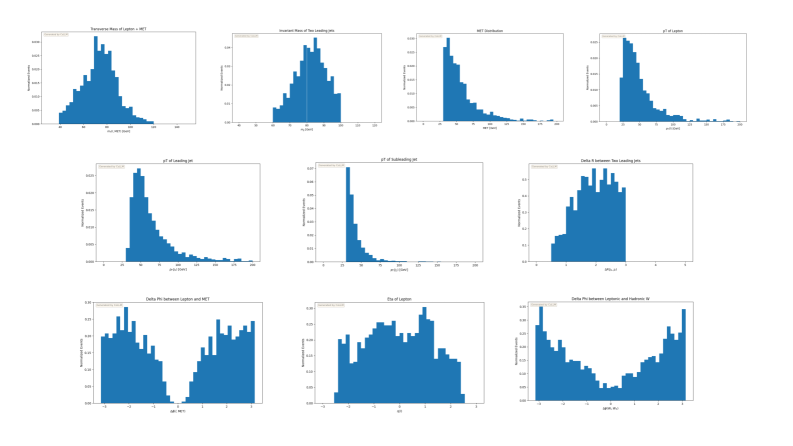
![CoLLM successfully validates the semi-leptonic [latex]t\bar{t}[/latex] analysis by generating normalized histograms for key kinematic variables including jet multiplicity, [latex]H_T[/latex], missing transverse energy, transverse mass, and the masses of W and top hadronic candidates, as well as distributions of [latex]p_T[/latex] and η for leading and subleading b-jets and the [latex]\Delta R[/latex] between leptons and b-jets.](https://arxiv.org/html/2602.06496v1/x3.png)
The framework detailed in this paper embodies a philosophy akin to emergent order. CoLLM doesn’t dictate analysis from a central authority, but rather establishes local rules – automated code generation and pipeline construction – that collectively produce global patterns of insight from collider data. This aligns with Epicurus’ observation: “It is not possible to live pleasantly without living prudently and honorably and justly.” Similarly, CoLLM promotes a ‘just’ and ‘honorable’ use of data, ensuring reproducibility and reducing reliance on singular expertise, fostering a more robust and ethically sound approach to scientific discovery. The system facilitates influence – enabling wider participation in complex analyses – rather than attempting control over the entire analytical process.
Where the Current Takes Us
The automation offered by frameworks like CoLLM isn’t about control-collider physics, like any complex system, resists being dictated to. Instead, it’s about sculpting the possible. Reducing the barrier to entry for sophisticated analysis doesn’t suddenly reveal hidden truths; it expands the search space, allowing more minds to explore the landscape. One anticipates a proliferation of specialized tools, each a local adaptation to a particular corner of the data, much like barnacles colonizing a rock face.
A true test will be how these systems handle ambiguity-the messy, ill-defined signals that often hint at the most interesting phenomena. Current approaches, focused on code generation, risk simply formalizing existing biases. The next evolution must incorporate methods for actively questioning the data, for suggesting alternative interpretations, and for exposing the inherent uncertainties. This requires moving beyond pattern recognition toward something resembling inductive reasoning-a subtle but critical distinction.
Ultimately, the success of such endeavors isn’t measured by the speed of discovery, but by the resilience of the analytical ecosystem. Like a coral reef, it must be diverse, adaptable, and capable of withstanding unforeseen pressures. The tools themselves are merely scaffolding; the real innovation will emerge from the interactions between them and the increasingly broad community of researchers they empower.
Original article: https://arxiv.org/pdf/2602.06496.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-09 18:47